Résolution des problèmes de goulot d’étranglement de performances dans Azure Databricks
Notes
Cet article s’appuie sur une bibliothèque open source hébergée sur GitHub sur : https://github.com/mspnp/spark-monitoring.
La bibliothèque d’origine prend en charge Azure Databricks Runtime 10.x (Spark 3.2.x) et versions antérieures.
Databricks a fourni une version mise à jour pour prendre en charge Azure Databricks Runtime 11.0 (Spark 3.3.x) et versions ultérieures sur la branche l4jv2 à l’adresse : https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Notez que la version 11.0 n’est pas rétrocompatible, en raison des différents systèmes de journalisation utilisés dans les runtimes Databricks. Veillez à utiliser la build appropriée pour votre runtime Databricks. La bibliothèque et le dépôt GitHub sont en mode maintenance. Il n’est pas prévu d’autres versions, et la prise en charge des problèmes sera uniquement fournie sur la base du meilleur effort. Pour toute question supplémentaire sur la bibliothèque ou sur la feuille de route pour le monitoring et la journalisation de vos environnements Azure Databricks, contactez azure-spark-monitoring-help@databricks.com.
Cet article décrit comment utiliser les tableaux de bord d’analyse pour identifier les goulots d’étranglement de performances dans des travaux Spark sur Azure Databricks.
Azure Databricks est un service d’analytique basé sur Apache Spark qui facilite le développement et le déploiement rapides d’analytique de Big Data. L’analyse et le dépannage des problèmes de performances sont essentiels lors de l’exploitation des charges de travail de production Azure Databricks. Pour identifier des problèmes de performances courants, l’utilisation des visualisations d’analyse basées sur les données de télémétrie s’avère être utile.
Prérequis
Pour configurer les tableaux de bord Grafana présentés dans cet article :
Configurez votre cluster Databricks pour envoyer des données de télémétrie à un espace de travail Log Analytics à l’aide de la bibliothèque d’analyse Azure Databricks. Pour en savoir plus, consultez le fichier readme de GitHub.
Déployer Grafana dans une machine virtuelle. Consultez Utiliser des tableaux de bord pour visualiser les métriques Azure Databricks.
Le tableau de bord Grafana déployé comprend un jeu de visualisations de séries chronologiques. Chaque graphique correspond à un tracé de séries chronologiques de métriques relatives à un travail Apache Spark, aux étapes du travail et aux tâches qui composent chaque étape.
Vue d’ensemble des performances Azure Databricks
Azure Databricks est basé sur Apache Spark, un système informatique distribué et à usage général. Le code d’application, appelé travail, s’exécute dans un cluster Apache Spark, coordonné par un gestionnaire de cluster. En général, un travail est l’unité de calcul la plus élevée. Un travail représente l’opération complète effectuée par l’application Spark. Une opération classique consiste à lire des données à partir d’une source, à appliquer des transformations de données ainsi qu’à écrire les résultats dans le stockage ou dans une autre destination.
Les travaux sont décomposés en étapes. Le travail progresse dans les étapes de manière séquentielle, ce qui signifie que les étapes ultérieures doivent attendre la fin des étapes qui les précèdent. Les étapes contiennent des groupes de tâches identiques qui peuvent être exécutées en parallèle sur plusieurs nœuds du cluster Spark. Les tâches sont l’unité d’exécution la plus granulaire d’un sous-ensemble des données.
Les sections suivantes décrivent certaines visualisations de tableau de bord utiles pour la résolution des problèmes de performances.
Latence des étapes et des travaux
La latence du travail est la durée d’exécution d’un travail du début à la fin. Il s’affiche comme centiles d’une exécution de travail par cluster et ID d’application afin de permettre la visualisation des valeurs hors norme. Le graphique suivant montre un historique des travaux dans lequel le 90e centile a atteint 50 secondes, même si le 50e centile restait autour de 10 secondes.
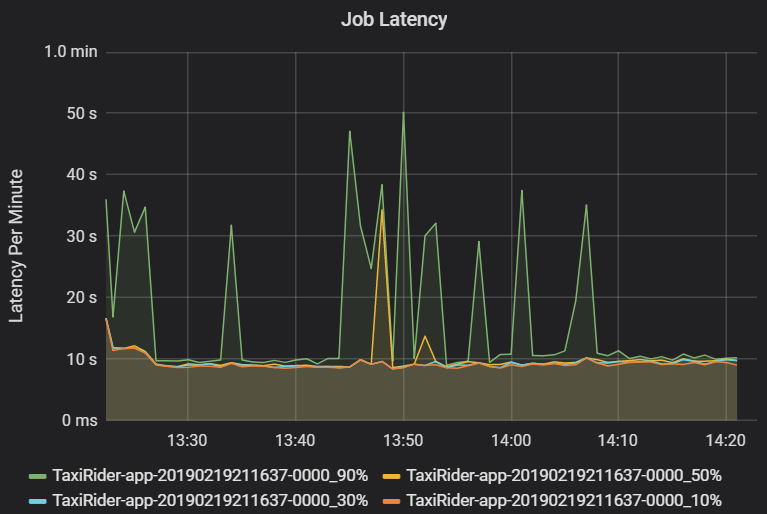
Examinez l’exécution des travaux par cluster et par application en recherchant des pics de latence. Une fois que les clusters et les applications avec une latence élevée sont identifiés, passez à l’examen de la latence des étapes
La latence des étapes est également exprimée en centiles pour permettre de visualiser les valeurs hors norme. La latence des étapes est répartie par cluster, application et nom d’étape. Identifiez les pics de la latence des tâches dans le graphique pour identifier les tâches qui empêchent l’étape de se terminer.
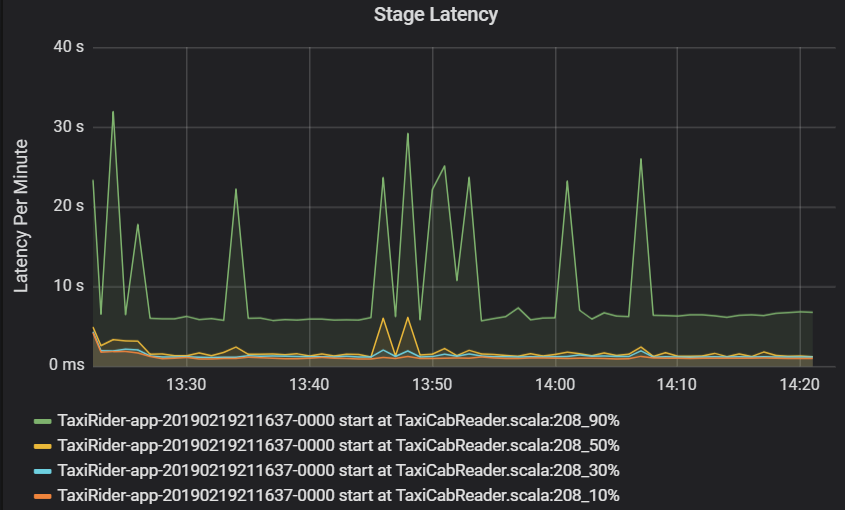
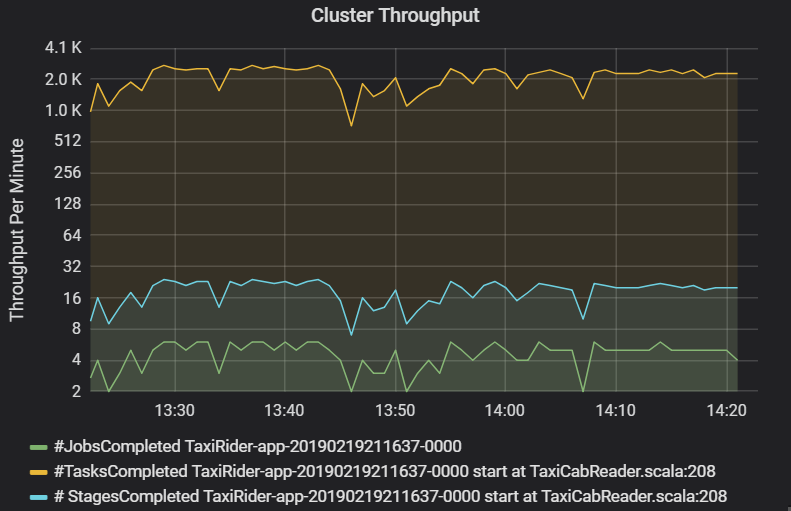
Le graphique du débit du cluster montre le nombre de travaux, d’étapes et de tâches terminés par minute. Cela vous aide à comprendre la charge de travail en termes de nombre relatif d’étapes et de tâches par travail. Ici, vous pouvez voir que le nombre de travaux par minute est compris entre 2 et 6, tandis que le nombre d’étapes par minute est d’environ 12 à 24.
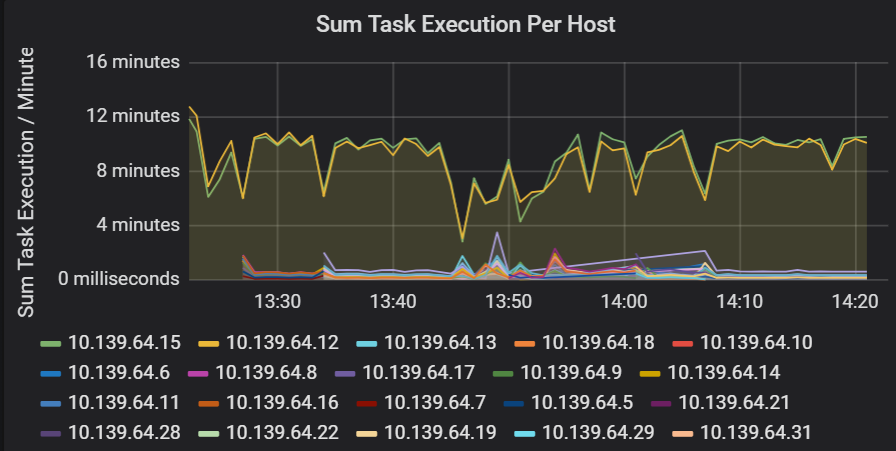
Somme de la latence d’exécution de la tâche
Cette visualisation affiche la somme d’exécution des travaux par hôte s’exécutant sur un cluster. Utilisez ce graphique pour détecter les tâches qui s’exécutent lentement en raison du ralentissement de l’hôte sur un cluster ou d’une mauvaise répartition des tâches par exécuteur. Dans le graphique suivant, la plupart des hôtes ont une somme d’environ 30 secondes. Toutefois, deux des hôtes ont des sommes qui avoisinent les 10 minutes. Soit les hôtes s’exécutent lentement ou alors, le nombre de tâches par exécuteur est mal réparti.
Le nombre de tâches par exécuteur montre qu’un nombre disproportionné de tâches est attribué à deux exécuteurs, créant ainsi un goulot d'étranglement.
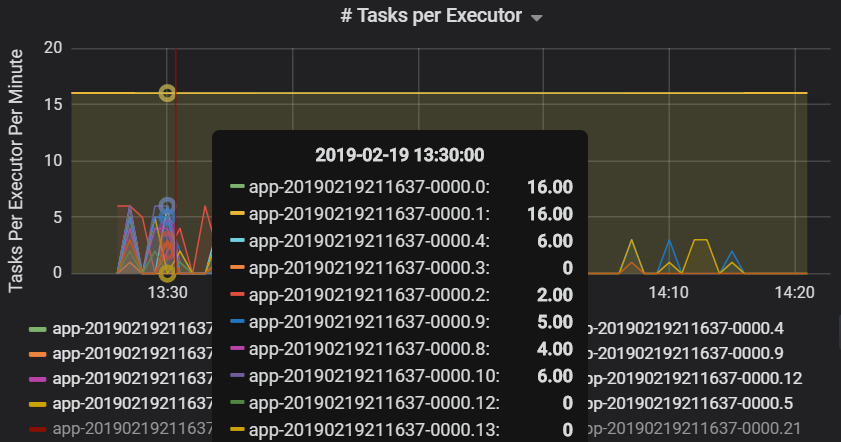
Métriques de tâche par étape
La visualisation des métriques de tâche montre la décomposition des coûts pour une exécution de tâche. Vous pouvez l’utiliser pour voir le temps relatif passé sur des tâches, telles que la sérialisation et la désérialisation. Ces données peuvent présenter des opportunités d’optimisation, par exemple, à l’aide de variables de diffusion de manière à éviter la transaction des données. Les métriques de tâche affichent également la taille des données en lecture aléatoire pour une tâche, ainsi que les temps de lecture et d’écriture aléatoires. Si ces valeurs sont élevées, cela signifie qu’une grande quantité de données est déplacée sur le réseau.
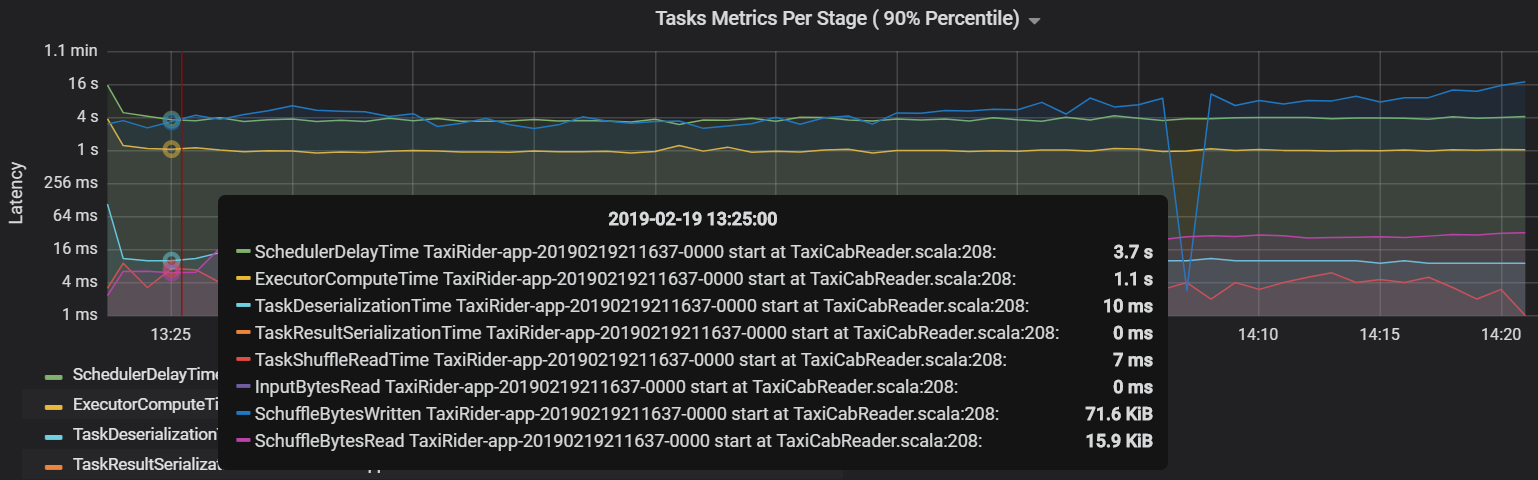
Le retard du planificateur est une autre métrique de tâche qui mesure le temps que prend la planification d’une tâche. Dans l’idéal, cette valeur doit être basse par rapport au temps de calcul de l’exécuteur, ce qui représente le temps passé à exécuter la tâche.
Le graphique suivant montre un délai du planificateur (3.7 s) qui dépasse le temps de calcul de l’exécuteur (1.1 s). Cela signifie le temps d’attente pour la planification des tâches est plus long que la durée d’exécution du travail.
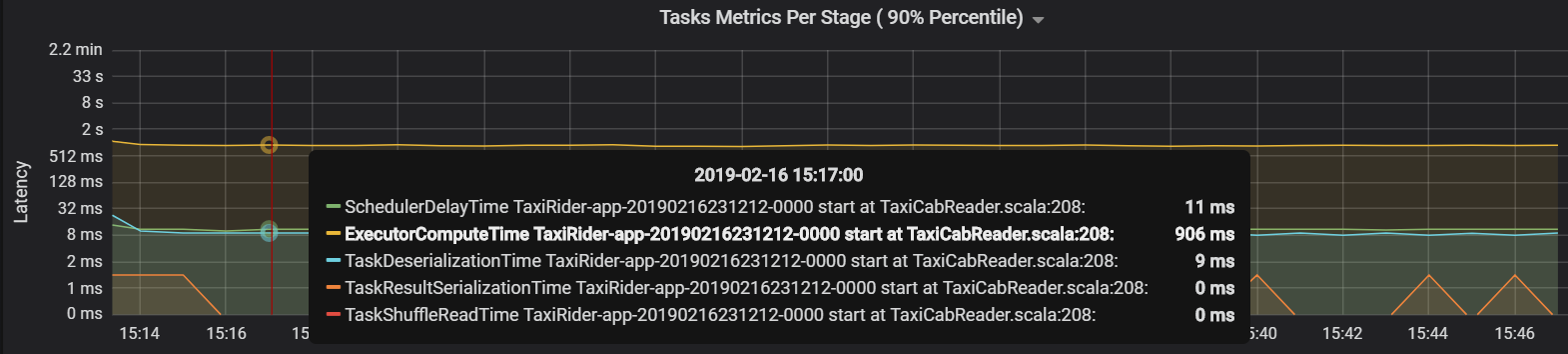
Dans le cas présent, le problème est dû à un trop grand nombre de partitions, ce qui a provoqué une surcharge importante. La réduction du nombre de partitions a raccourci le délai du planificateur. Le graphique suivant montre que l’exécution de la tâche occupe la majorité du temps.
Débit et latence de la diffusion en continu
Le débit de diffusion en continu est directement lié à la diffusion en continu structurée. Il existe deux métriques importantes associées au débit de diffusion en continu : Les lignes d’entrée par seconde et les lignes traitées par seconde. Si les lignes d’entrée par seconde devancent les lignes traitées par seconde, cela signifie que le système de traitement des flux est en retard. En outre, si les données d’entrée proviennent des Event Hubs ou Kafka, alors le nombre de lignes d’entrée par seconde doit suivre le taux d’ingestion des données au niveau du serveur frontal.
Deux travaux peuvent avoir un débit de cluster similaire, mais des métriques de diffusion en continu très différentes. La capture d’écran suivante montre deux charges de travail différentes. Elles sont semblables en termes de débit de cluster (travaux, étapes, tâches par minutes). Mais la deuxième exécution traite 12 000 lignes/s contre 4 000 lignes/s.
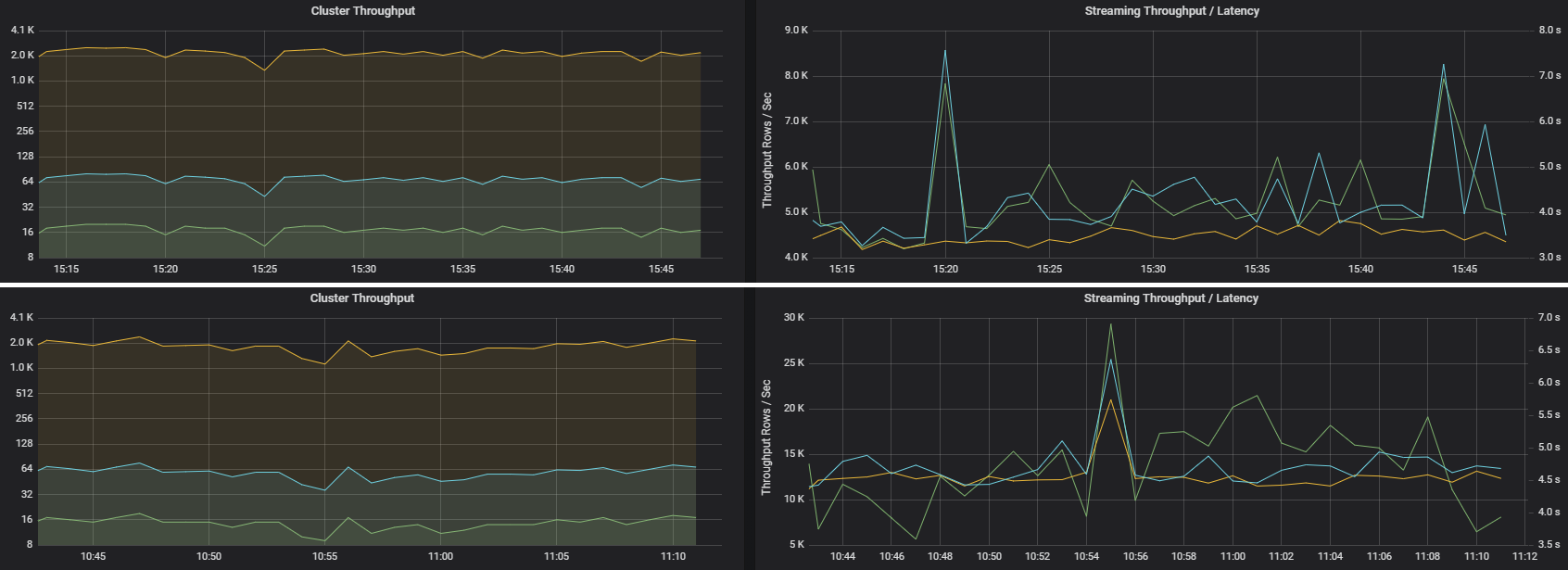
Le débit de diffusion en continu est souvent une meilleure métrique métier que le débit du cluster, car il mesure le nombre d’enregistrements de données traitées.
Consommation de ressources par exécuteur
Ces métriques permettent de comprendre le travail effectué par chaque exécuteur.
Les métriques de pourcentage mesurent le temps passé par un exécuteur sur divers éléments, exprimés sous forme de rapport entre le temps passé et le temps de calcul général de l’exécuteur. Voici les métriques disponibles :
- % Temps de sérialisation
- % Temps de désérialisation
- % Temps de l’exécuteur de processeur
- % Temps de JVM
Ces visualisations indiquent la quantité de ces métriques qui contribue au traitement général de l’exécuteur.
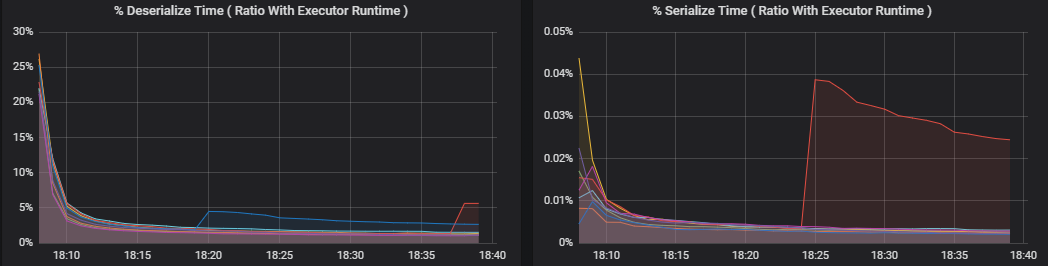
La lecture aléatoire des métriques sont des métriques liées à la lecture aléatoire de données sur les exécuteurs.
- Lecture aléatoire de E/S
- Lecture aléatoire de la mémoire
- Utilisation de systèmes de fichiers
- Utilisation du disque :
Goulots d'étranglement des performances courants
Les ralentisseurs de tâche et un nombre non optimal de partitions en lecture aléatoire sont deux goulots d'étranglement de performances courants dans Spark.
Ralentisseurs de tâche
Les étapes d’un travail sont exécutées de manière séquentielle : les premières étapes bloquent suivantes. Si une tâche exécute une partition en lecture aléatoire plus lentement que les autres tâches, toutes les tâches dans le cluster doivent alors attendre que la tâche lente rattrape son retard avant de finir l’étape. Ceci peut se produire pour les raisons suivantes :
Un hôte ou un groupe d’hôtes s’exécute lentement. Symptômes : Latence élevée des tâches, des étapes ou des travaux et faible débit du cluster. La somme des latences de tâches par hôte n’est pas distribuée de manière uniforme. Toutefois, la consommation des ressources est uniformément répartie entre les exécuteurs.
Les tâches ont une agrégation coûteuse à exécuter (inclinaison des données). Symptômes : Latence élevée des tâches, des étapes ou des travaux ou débit de cluster faible, mais la somme des latences par hôte est distribuée uniformément. La consommation des ressources est uniformément répartie entre les exécuteurs.
Si les partitions sont de taille inégale, une partition plus importante peut entraîner un déséquilibre au niveau de l’exécution des tâches (inclinaison de partition). Symptômes : La consommation des ressources de l’exécuteur est élevée par rapport à celle d’autres exécuteurs exécutés sur le cluster. Toutes les tâches en cours d’exécution sur cet exécuteur sont lentes et retiennent l’exécution de l’étape dans le pipeline. Ces étapes sont appelées barrières d’étape.
Nombre non optimal de partitions en lecture aléatoire
Au cours d’une requête de diffusion en continu structurée, l’affectation d’une tâche à un exécuteur est une opération gourmande en ressources pour le cluster. Si la taille des données en lecture aléatoire n’est pas optimale, la durée du retard d’une tâche aura un impact négatif sur le débit et la latence. Si le nombre de partitions est insuffisant, les cœurs du cluster sont sous-exploités, ce qui peut rendre le traitement inefficace. À l’inverse, s’il y a trop de partitions, la surcharge de gestion est importante pour un petit nombre de tâches.
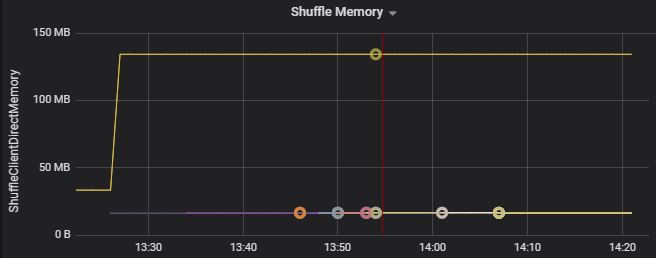
Utilisez les métriques de consommation des ressources pour résoudre les problèmes d’inclinaison des partitions et de mauvaise répartition des exécuteurs sur le cluster. Si une partition est inclinée, les ressources de l’exécuteur seront élevées par rapport aux autres exécuteurs exécutés sur le cluster.
Par exemple, le graphique suivant montre que la mémoire utilisée par la réutilisation aléatoire sur les deux premiers exécuteurs est 90 fois plus importante que sur les autres exécuteurs :
Étapes suivantes
- Monitoring d’Azure Databricks dans un espace de travail Azure Log Analytics
- Parcours d’apprentissage : Créer et exploiter des solutions Machine Learning avec Azure Databricks
- Documentation Azure Databricks
- Vue d’ensemble d’Azure Monitor
Ressources associées
- Supervision d’Azure Databricks
- Envoyer les journaux des applications Azure Databricks à Azure Monitor
- Utiliser des tableaux de bord pour visualiser les métriques Azure Databricks
- Architecture d’analytique moderne avec Azure Databricks
- Pipelines d’ingestion, ETL et de traitement de flux avec Azure Databricks
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour