Le système de fichiers distribués Hadoop (HDFS) est un système de fichiers distribué basé sur Java qui fournit un stockage de données fiable et évolutif qui peut s’étendre sur de grands clusters de serveurs standard. Cet article fournit une vue d’ensemble de HDFS et un guide pour migrer de ce système vers Azure.
Apache®, Apache Spark®, Apache Hadoop®, Apache Hive et le logo représentant une flamme sont soit des marques déposées, soit des marques commerciales d’Apache Software Foundation aux États-Unis et/ou dans d’autres pays. L’utilisation de ces marques n’implique aucune approbation de l’Apache Software Foundation.
Architecture et composants HDFS
HDFS a une conception à base de composants principal/secondaires. Dans le diagramme suivant, NameNode est le composant principal et les DataNodes sont les composants secondaires.
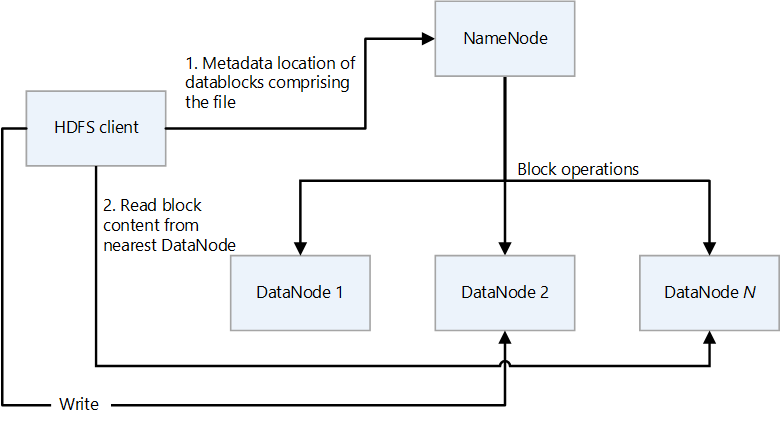
- NameNode gère l’accès aux fichiers et à l’espace de noms du système de fichiers, qui est une hiérarchie de répertoires.
- Les fichiers et répertoires sont des nœuds sur NameNode. Ils ont des attributs tels que les autorisations, la modification et les temps d’accès, ainsi que des quotas de taille pour l’espace de noms et l’espace disque.
- Un fichier inclut plusieurs blocs. La taille de bloc par défaut est de 128 mégaoctets. Une taille de bloc qui n’est pas celle par défaut peut être définie pour un cluster en modifiant le fichier hdfs-site.xml.
- Chaque bloc du fichier est répliqué indépendamment sur plusieurs DataNodes. La valeur par défaut du facteur de réplication est trois, mais chaque cluster peut avoir sa propre valeur non définie par défaut. Le facteur de réplication peut être modifié à tout moment. Une modification entraîne un rééquilibrage du cluster.
- NameNode gère l’arborescence d’espaces de noms et le mappage des blocs de fichiers aux DataNodes (emplacements physiques des données de fichier).
- Lorsqu’un client HDFS lit un fichier :
- Il contacte le NameNode pour les emplacements des blocs de données du fichier.
- Il lit le contenu de bloc du DataNode le plus proche.
- HDFS conserve l’espace de noms entier dans la mémoire RAM.
- Les DataNodes sont les nœuds secondaires qui effectuent des opérations de lecture et d’écriture sur le système de fichiers et effectuent des opérations de bloc telles que la création, la réplication et la suppression.
- Un DataNode contient des fichiers de métadonnées qui incluent les sommes de contrôle des fichiers stockés. Pour chaque réplica de bloc hébergé par un DataNode, il existe un fichier de métadonnées correspondant qui contient des métadonnées sur le réplica, y compris les informations de somme de contrôle correspondantes. Le fichier de métadonnées a le même nom de base que le fichier de bloc et l’extension .meta.
- DataNode contient le fichier de données qui contient les données du bloc.
- Lorsqu’un DataNode lit un fichier, il extrait les emplacements de bloc et les emplacements de réplica à partir du NameNode et tente de lire à partir de l’emplacement le plus proche.
- Un cluster HDFS peut avoir des milliers de DataNodes et des dizaines de milliers de clients HDFS par cluster. Chaque DataNode peut exécuter plusieurs tâches d’application simultanément.
- Un calcul de somme de contrôle de bout en bout est effectué dans le cadre du pipeline d’écriture HDFS lorsqu’un bloc est écrit dans des DataNodes.
- Le client HDFS est le client que les applications utilisent pour accéder aux fichiers.
- Il s’agit d’une bibliothèque de codes qui exporte l’interface du système de fichiers HDFS.
- Il prend en charge les opérations de lecture, d’écriture et de suppression de fichiers et d’opérations pour créer et supprimer des répertoires.
- Il effectue les étapes suivantes lorsqu’une application lit un fichier :
- Il obtient à partir du NameNode une liste de DataNodes et d’emplacements qui contiennent les blocs de fichiers. La liste inclut les réplicas.
- Il utilise la liste pour obtenir les blocs demandés à partir des DataNodes.
- HDFS fournit une API qui expose les emplacements des blocs de fichiers. Cela permet aux applications telles que l’infrastructure MapReduce de planifier une tâche à exécuter là où se trouvent les données, afin d’optimiser les performances de lecture.
Tableau des fonctionnalités
Le pilote ABFS (Azure Blob Filesystem) fournit une interface qui permet à Azure Data Lake Storage d’agir en tant que système de fichiers HDFS. Le tableau suivant compare les fonctionnalités principales du pilote ABFS et de Data Lake Storage à celles de HDFS.
| Fonctionnalité | Pilote ABFS et Data Lake Storage | HDFS |
|---|---|---|
| Accès compatible avec Hadoop | Vous pouvez gérer et consulter les données comme vous le feriez avec HDFS. Le pilote ABFS est disponible dans tous les environnements Apache Hadoop, notamment Azure HDInsight et Azure Databricks. | Un cluster MapR peut accéder à un cluster HDFS externe avec les protocoles hdfs:// ou webhdfs://. |
| Autorisations POSIX | Le modèle de sécurité pour Data Lake Gen2 prend en charge les autorisations de liste de contrôle d’accès (ACL) et POSIX, ainsi que certaines granularités supplémentaires spécifiques à Data Lake Storage Gen2. Les paramètres peuvent être configurés en utilisant des outils d’administration ou des frameworks comme Apache Hive et Apache Spark. | Les travaux qui nécessitent des fonctionnalités de système de fichiers telles que des renommages de répertoires atomiques, des autorisations HDFS affinées ou des liens symboliques HDFS ne peuvent fonctionner que sur HDFS. |
| Rentabilité | Data Lake Storage offre une capacité de stockage et des transactions à bas coût. Les cycles de vie de Stockage Blob Azure vous aident à réduire les coûts en adaptant les frais facturés au fil du cheminement des données dans leur cycle de vie. | |
| Pilote optimisé | Le pilote ABFS est optimisé pour l’analytique Big Data. Les API REST correspondantes sont fournies par le biais du point de terminaison DFS (Distributed File System), dfs.core.windows.net. |
|
| Taille des blocs | Les blocs sont équivalents à un appel d’API Append unique (l’API Append crée un bloc) et sont limités à 100 Mo par appel. Toutefois, le modèle d’écriture prend en charge l’appel d’Append plusieurs fois par fichier (même en parallèle) jusqu’à un maximum de 50 000, puis l’appel de Flush (équivalent à PutBlockList). Il s’agit de la façon dont la taille de fichiers maximale de 4,75 To est atteinte. | HDFS stocke les données dans un bloc de données. Vous configurez la taille du bloc en définissant une valeur dans le fichier hdfs-site.xml dans le répertoire Hadoop. La taille par défaut est de 128 Mo. |
| ACL par défaut | Les fichiers n’ont pas de listes de contrôle d’accès par défaut et ne sont pas activés par défaut. | Les fichiers n’ont pas de listes de contrôle d’accès par défaut. |
| Fichiers binaires | Les fichiers binaires peuvent être déplacés vers Stockage Blob Azure dans un espace de noms non hiérarchique. Les objets du Stockage Blob sont accessibles via l’API REST Stockage Azure, Azure PowerShell, Azure CLI ou une bibliothèque de client Stockage Azure. Les bibliothèques de client sont disponibles pour différents langages, notamment .NET, Java, Node.js, Python, Go, PHP et Ruby. | Hadoop permet de lire et d’écrire des fichiers binaires. SequenceFile est un fichier plat qui se compose d’une paire clé-valeur binaire. SequenceFile fournit des classes Writer, Reader et Sorter pour l’écriture, la lecture et le tri. Convertissez le fichier image ou vidéo en sequenceFile et stockez-le dans HDFS. Utilisez ensuite les méthodes SequenceFileReader/Writer HDFS ou la commande put : bin/hadoop fs -put /src_image_file /dst_image_file |
| Héritage d'autorisations | Data Lake Storage utilise le modèle de style POSIX et se comporte comme Hadoop si les listes de contrôle d’accès contrôlent l’accès à un objet. Pour plus d’informations, consultez Listes de contrôle d’accès (ACL) dans Data Lake Storage Gen2. | Les autorisations d’un élément sont stockées sur l’élément lui-même, et non héritées après l’existence de l’élément. Les autorisations sont héritées uniquement si les autorisations par défaut sont définies sur les éléments parents avant la création des éléments enfants. |
| Réplication des données | Les données d’un compte de stockage Azure sont répliquées trois fois dans la région primaire. Le stockage redondant interzone est l’option de réplication recommandée. Il réplique les données de façon synchrone sur trois zones de disponibilité Azure dans la région primaire. | Par défaut, le facteur de réplication d’un fichier est de trois. Pour les fichiers critiques ou les fichiers souvent accessibles, un facteur de réplication plus élevé améliore la tolérance de panne et augmente la bande passante de lecture. |
| Sticky bit | Dans le contexte de Data Lake Store, il est peu probable que le sticky bit soit nécessaire. En résumé, si le sticky bit est activé sur un répertoire, un élément enfant peut uniquement être supprimé ou renommé par l’utilisateur propriétaire de l’élément enfant. Le sticky bit n’est pas affiché dans le Portail Azure. | Le sticky bit peut être défini sur les répertoires pour empêcher quiconque sauf le superutilisateur, le propriétaire du répertoire ou le propriétaire du fichier de supprimer ou de déplacer des fichiers dans le répertoire. La définition du sticky bit pour un fichier n’a aucun effet. |
Défis courants d’un HDFS local

Les nombreux défis présentés par une implémentation HDFS locale peuvent être une motivation pour prendre en compte les avantages de la migration vers le cloud :
- Mises à niveau fréquentes de version HDFS
- Augmentation des quantités de données
- Disposer de nombreux petits fichiers qui augmentent la pression sur le NameNode, qui contrôle les métadonnées de tous les fichiers du cluster. Plus les fichiers sont nombreux, plus le trafic de lecture sur le NameNode est élevé lorsque les clients lisent les fichiers, et plus le nombre d’appels est élevé lorsque les clients écrivent.
- Si plusieurs équipes de l’organisation nécessitent différents jeux de données, le fractionnement des clusters HDFS par cas d’usage ou organisation n’est pas possible. Le résultat est que la duplication des données augmente, ce qui augmente les coûts et réduit l’efficacité.
- Le NameNode peut devenir un goulot d’étranglement en termes de performances car le cluster HDFS fait l’objet d’un scale-up ou d’un scale-out.
- Avant Hadoop 2.0, toutes les requêtes clientes adressées à un cluster HDFS passent d’abord par le NameNode, car toutes les métadonnées sont stockées dans un seul NameNode. Cette conception fait que le NameNode est un goulot d’étranglement possible et un point de défaillance unique. Si NameNode échoue, le cluster n’est pas disponible.
Considérations relatives à la migration
Voici quelques éléments importants à prendre en compte lorsque vous planifiez une migration de HDFS vers Data Lake Storage :
- Envisagez d’agréger les données qui se trouvent dans de petits fichiers dans un seul fichier sur Data Lake Storage.
- Répertoriez toutes les structures de répertoire dans HDFS et répliquez le zonage similaire dans Data Lake Storage. Vous pouvez obtenir la structure de répertoires de HDFS à l’aide de la commande
hdfs -ls. - Répertoriez tous les rôles définis dans le cluster HDFS afin de pouvoir les répliquer dans l’environnement cible.
- Notez la stratégie de cycle de vie des données des fichiers stockés dans HDFS.
- N’oubliez pas que certaines fonctionnalités système de HDFS ne sont pas disponibles sur Data Lake Storage, notamment :
- Nommage strictement atomique des répertoires
- Autorisations HDFS affinées
- Liens symboliques HDFS
- Stockage Azure a une réplication géoredondante, mais il n’est pas toujours judicieux de l’utiliser. Il fournit une redondance des données et une récupération géographique, mais un basculement vers un emplacement plus distant peut dégrader sérieusement les performances et entraîner des coûts supplémentaires. Déterminez si la plus grande disponibilité des données en vaut vraiment la peine.
- Si les fichiers ont des noms avec les mêmes préfixes, HDFS les traite comme une seule partition. Par conséquent, si vous utilisez Azure Data Factory, toutes les unités de déplacement de données écrivent dans une seule partition.

- Si vous utilisez Data Factory pour le transfert de données, analysez chaque répertoire, à l’exclusion des instantanés et vérifiez la taille du répertoire à l’aide de la commande
hdfs du. S’il existe plusieurs sous-répertoires et de grandes quantités de données, lancez plusieurs activités de copie dans Data Factory. Par exemple, utilisez une copie par sous-répertoire plutôt que de transférer l’ensemble du répertoire à l’aide d’une seule activité de copie.

- Les plateformes de données sont souvent utilisées pour la conservation à long terme d’informations qui peuvent avoir été supprimées des systèmes d’enregistrement. Vous devez planifier la création de sauvegardes sur bande ou d’instantanés des données archivées. Envisagez de répliquer les informations sur un site de récupération. En règle générale, les données sont archivées à des fins de conformité ou à des fins de données historiques. Avant d’archiver les données, vous devez avoir une raison claire de les conserver. De plus, décidez à quel moment les données archivées doivent être supprimées et établissez des processus pour les supprimer à ce moment-là.
- Le faible coût du niveau d’accès Archive de Data Lake Storage permet d’optimiser l’archivage des données. Pour plus d’informations, voir Niveau d’accès archive.
- Lorsqu’un client HDFS utilise le pilote ABFS pour accéder au Stockage Blob, il peut y avoir des instances où la méthode utilisée par le client n’est pas prise en charge et AzureNativeFileSystem lève une exception UnsupportedOperationException (opération non prise en charge). Par exemple,
append(Path f, int bufferSize, Progressable progress)n’est pas pris en charge actuellement. Pour vérifier les problèmes liés au pilote ABFS, consultez Fonctionnalités et correctifs Hadoop. - Il existe une version rétroportée du pilote ABFS à utiliser sur des clusters Hadoop plus anciens. Pour plus d’informations, consultez Rétroporter pour le pilote ABFS.
- Dans un environnement de réseaux virtuels Azure, l’outil DistCp ne prend pas en charge le peering privé Azure ExpressRoute avec un point de terminaison de réseau virtuel Stockage Azure. Pour plus d’informations, consultez Utiliser Azure Data Factory pour migrer des données d’un cluster Hadoop local vers le service Stockage Azure.
Approche de migration
L’approche classique de la migration de HDFS vers Data Lake Storage utilise les étapes suivantes :

Évaluation HDFS
Les scripts d’évaluation locaux fournissent des informations qui vous aident à déterminer quelles charges de travail peuvent être migrées vers Azure et si les données doivent être migrées en une seule fois ou une à la fois. Les outils tiers comme Unravel peuvent fournir des métriques et prendre en charge l’évaluation automatique de HDFS local. Voici quelques facteurs importants à prendre en compte lors de la planification :
- Volume de données
- Impact commercial
- Propriété des données
- Complexité du traitement
- Complexité des opérations Extraire, transférer et charger (ETL)
- Informations d’identification personnelle et autres données sensibles
En fonction de ces facteurs, vous pouvez formuler un plan de déplacement des données vers Azure qui réduit au maximum les temps d’arrêt et les interruptions d’activité. Peut-être que les données sensibles peuvent rester locales. Les données historiques peuvent être déplacées et testées avant de déplacer une charge incrémentielle.
Le flux de décision suivant permet de décider des critères et des commandes à exécuter pour obtenir les informations appropriées.

Les commandes HDFS pour obtenir des métriques d’évaluation à partir de HDFS incluent :
Répertorier tous les répertoires dans un emplacement :
hdfs dfs -ls booksRépertorier de manière récursive tous les fichiers dans un emplacement :
hdfs dfs -ls -R booksObtenir la taille des fichiers et du répertoire HDFS :
hadoop fs -du -s -h commandLa commande
hadoop fs -du -s -haffiche la taille des fichiers et répertoires HDFS. Étant donné que le système de fichiers Hadoop réplique chaque fichier, la taille physique réelle du fichier correspond au nombre de réplicas de fichiers multiplié par la taille d’un réplica.Déterminez si les listes de contrôle d’accès sont activées. Pour ce faire, obtenez la valeur de
dfs.namenode.acls.enableddans le fichier Hdfs-site.xml. La connaissance de la valeur permet de planifier le contrôle d’accès sur le compte de stockage Azure. Pour plus d’informations sur le contenu de ce fichier, consultez Paramètres de fichier par défaut.
Les outils partenaires tels que Unravel fournissent des rapports d’évaluation pour la planification de la migration des données. Les outils doivent s’exécuter dans l’environnement local ou se connecter au cluster Hadoop pour générer des rapports.
Le rapport Unravel suivant fournit des statistiques, par répertoire, sur les petits fichiers du répertoire :

Le rapport suivant fournit des statistiques, par répertoire, sur les fichiers du répertoire :

Transfert de données
Les données doivent être transférées vers Azure comme indiqué dans votre plan de migration. Le transfert nécessite les activités suivantes :
Identifiez tous les points d’ingestion.
Si, en raison des exigences de sécurité, les données ne peuvent pas être amenées directement dans le cloud, l’environnement local peut servir de zone d’atterrissage intermédiaire. Vous pouvez créer des pipelines de build dans Data Factory pour extraire les données à partir de systèmes locaux ou utiliser des scripts AZCopy pour envoyer les données au compte de stockage Azure.
Voici les sources d’ingestion courantes :
- Serveur SFTP
- Ingestion de fichiers
- Ingestion de base de données
- Vidage de base de données
- Capture des données modifiées
- Ingestion de streaming
Planifiez le nombre de comptes de stockage requis.
Pour planifier le nombre de comptes de stockage requis, comprenez la charge totale sur l’instance HDFS actuelle. Vous pouvez utiliser la métrique TotalLoad, qui est le nombre actuel d’accès aux fichiers simultanés sur tous les DataNodes. Définissez la limite du compte de stockage dans la région en fonction de la valeur TotalLoad locale et de la croissance attendue sur Azure. S’il est possible d’augmenter la limite, un seul compte de stockage peut suffire. Toutefois, pour un lac de données, il est préférable de conserver un compte de stockage distinct pour chaque zone, afin de préparer la croissance future du volume de données. Voici d’autres raisons pour conserver un compte de stockage distinct :
- Contrôle d’accès
- Exigences en matière de résilience
- Conditions requises de la réplication de données
- Exposition des données pour une utilisation publique
Lorsque vous activez un espace de noms hiérarchique sur un compte de stockage, vous ne pouvez pas le convertir en espace de noms plat. Les charges de travail telles que les sauvegardes et les fichiers d’images de machine virtuelle ne tirent pas avantage d’un espace de noms hiérarchique.

Pour plus d’informations sur la sécurisation du trafic entre votre réseau virtuel et le compte de stockage via une liaison privée, consultez Sécurisation des comptes de stockage.
Pour plus d’informations sur les limites par défaut des comptes de stockage Azure, consultez Cibles de scalabilité et de performances pour les comptes de stockage standard. La limite d’entrée s’applique aux données envoyées à un compte de stockage. La limite de sortie s’applique aux données reçues d’un compte de stockage.
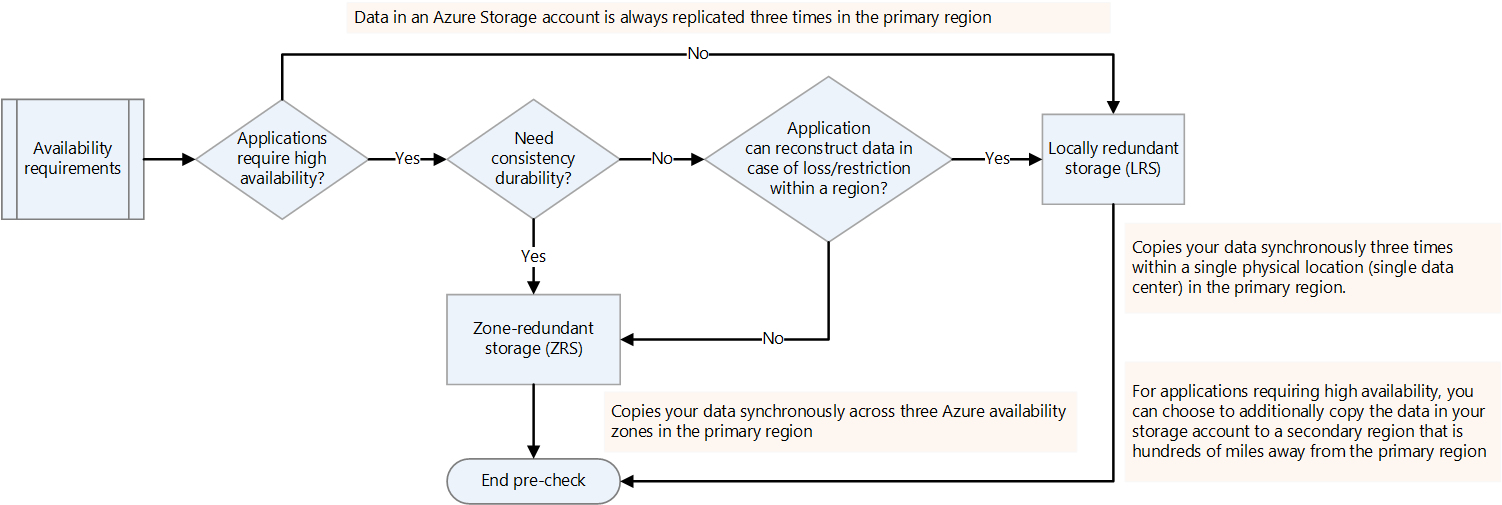
Déterminez les exigences en matière de disponibilité.
Vous pouvez spécifier le facteur de réplication pour les plateformes Hadoop dans hdfs-site.xml ou le spécifier par fichier. Vous pouvez configurer la réplication sur Data Lake Storage en fonction de la nature des données. Si une application nécessite que les données soient reconstruites en cas de perte, le stockage redondant interzone (ZRS) est une option. Dans le stockage redondant interzone (ZRS) Data Lake Storage, les données sont copiées de façon synchrone sur trois zones de disponibilité dans la région primaire. Pour les applications nécessitant une haute disponibilité et qui peuvent s’exécuter dans plusieurs régions, copiez les données dans une région secondaire. Il s’agit de la réplication géoredondante.
Vérifiez les blocs endommagés ou manquants.
Vérifiez le rapport du scanneur de blocs pour repérer les blocs endommagés ou manquants. S’il y en a, attendez que le fichier soit restauré avant de le transférer.

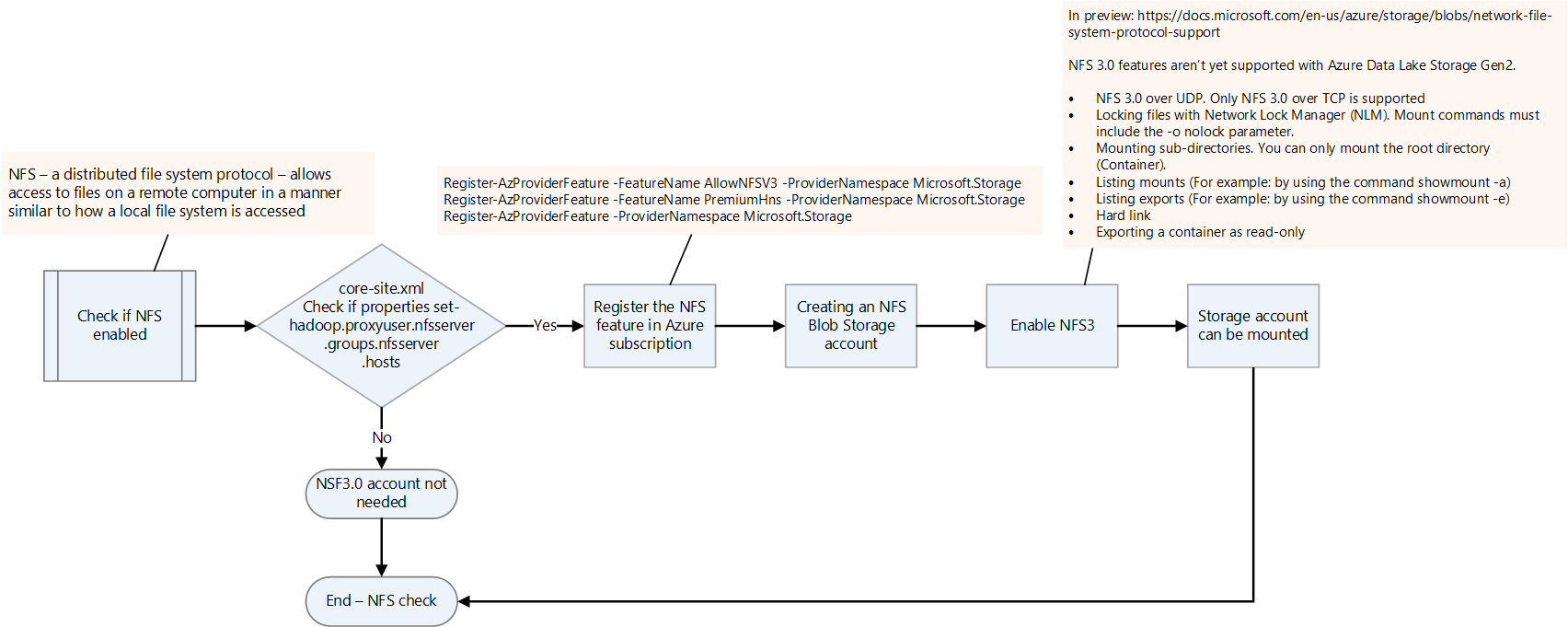
Vérifiez si NFS est activé.
Vérifiez si NFS est activé sur la plateforme Hadoop locale en vérifiant le fichier core-site.xml. Il possède les propriétés nfsserver.groups et nfsserver.hosts.
La fonctionnalité NFS 3.0 est en préversion dans Data Lake Storage. Certaines fonctionnalités peuvent ne pas encore être prises en charge. Pour plus d’informations, consultez Prise en charge du protocole NFS (Network File System) 3.0 dans Stockage Blob Azure.
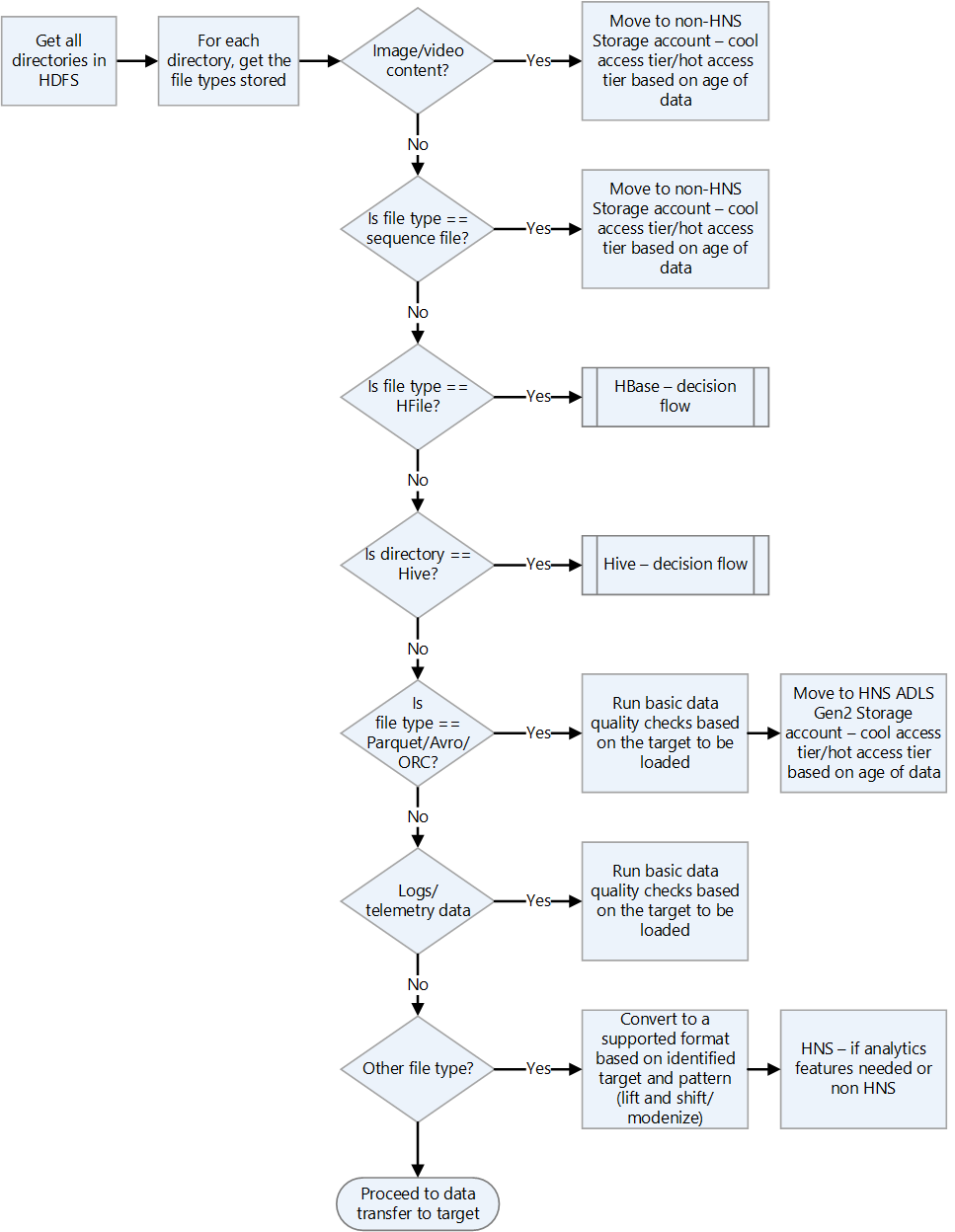
Vérifiez les formats de fichier Hadoop.
Utilisez le graphique de flux de décision suivant pour obtenir des conseils sur la façon de gérer les formats de fichiers.
Choisissez une solution Azure pour transférer des données.
Le transfert de données peut être en ligne sur le réseau ou hors ligne à l’aide d’appareils physiques. La méthode à utiliser dépend du volume de données, de la bande passante réseau et de la fréquence du transfert de données. Les données historiques doivent être transférées une seule fois. Les charges incrémentielles nécessitent des transferts continus répétés.
Les méthodes de transfert de données sont décrites dans la liste qui suit. Pour plus d’informations sur le choix des types de transfert de données, consultez Choisir une solution Azure pour le transfert de données.
Azcopy
AzCopy est un utilitaire en ligne de commande qui peut copier des fichiers de HDFS vers un compte de stockage. Il s’agit d’une option pour les transferts à bande passante élevée (plus de 1 Gbits/s).
Voici un exemple de commande pour déplacer un répertoire HDFS :
*azcopy copy "C:\local\path" "https://account.blob.core.windows.net/mycontainer1/?sv=2018-03-28&ss=bjqt&srt=sco&sp=rwddgcup&se=2019-05-01T05:01:17Z&st=2019-04-30T21:01:17Z&spr=https&sig=MGCXiyEzbtttkr3ewJIh2AR8KrghSy1DGM9ovN734bQF4%3D" --recursive=true*DistCp
DistCp est un utilitaire en ligne de commande dans Hadoop qui peut effectuer des opérations de copie distribuée dans un cluster Hadoop. DistCp crée plusieurs tâches de mappage dans le cluster Hadoop pour copier des données de la source vers le récepteur. Cette approche de transmission est adaptée lorsqu’il existe une bande passante réseau adéquate et qu’elle ne nécessite pas de ressources de calcul supplémentaires pour la migration des données. Toutefois, si le cluster HDFS source est déjà en manque de capacité et que du calcul supplémentaire ne peut pas être ajouté, envisagez d’utiliser Data Factory avec l’activité de copie DistCp pour extraire plutôt que de transmettre les fichiers.
*hadoop distcp -D fs.azure.account.key.<account name>.blob.core.windows.net=<Key> wasb://<container>@<account>.blob.core.windows.net<path to wasb file> hdfs://<hdfs path>*Azure Data Box pour les transferts de données volumineux
Azure Data Box est un appareil physique commandé à Microsoft. Il fournit des transferts de données à grande échelle, et il s’agit d’une option de transfert de données hors connexion lorsque la bande passante réseau est limitée et que le volume de données est élevé (par exemple, lorsque le volume est compris entre plusieurs téraoctets et un pétaoctet).
Vous connectez un disque Data Box au réseau local pour transférer des données vers celui-ci. Vous l’envoyez ensuite au centre de données Microsoft, où les données sont transférées par les ingénieurs Microsoft vers le compte de stockage configuré.
Il existe plusieurs options Data Box permettant de gérer différents volumes de données. Pour plus d’informations sur l’approche Data Box, consultez la documentation Azure Data Box - Transfert hors connexion.
Data Factory
Data Factory est un service d’intégration de données qui permet de créer des flux de travail pilotés par les données qui orchestrent et automatisent le déplacement des données et la transformation des données. Vous pouvez l’utiliser lorsqu’il existe suffisamment de bande passante réseau disponible et qu’il est nécessaire d’orchestrer et de surveiller la migration des données. Vous pouvez utiliser Data Factory pour les chargements incrémentiels réguliers de données lorsque les données incrémentielles arrivent sur le système local en tant que premier tronçon et ne peuvent pas être directement transférées vers le compte de stockage Azure en raison de restrictions de sécurité.
Pour plus d’informations sur les différentes approches de transfert, consultez Transfert de données pour les jeux de données volumineux avec une bande passante réseau modérée à élevée.
Pour plus d’informations sur l’utilisation de Data Factory pour copier des données à partir de HDFS, consultez Copier des données à partir du serveur HDFS à l’aide d’Azure Data Factory ou de Synapse Analytics.
Solutions partenaires telles que la migration WANdisco LiveData
WaNdisco LiveData Platform for Azure est l’une des solutions préférées de Microsoft pour les migrations de Hadoop vers Azure. Vous accédez à ses fonctionnalités à l’aide du Portail Azure et de l’interface Azure CLI. Pour plus d’informations, consultez Migrer vos lacs de données Hadoop avec WANDisco LiveData Platform for Azure.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteurs principaux :
- Namrata Maheshwary | Architecte de solutions cloud senior
- Raja N | Directeur, Réussite des clients
- Hideo Takagi | Architecte de solutions cloud
- Ram Yerrabotu | Architecte de solutions cloud senior
Autres contributeurs :
- Ram Baskaran | Architecte de solutions cloud senior
- Jason Bouska | Ingénieur logiciel senior
- Eugene Chung | Architecte de solutions cloud senior
- Pawan Hosatti | Architecte de solutions cloud senior - Ingénierie
- Daman Kaur | Architecte de solutions cloud
- Danny Liu | Architecte de solutions cloud senior - Ingénierie
- Jose Mendez | Architecte de solutions cloud senior
- Ben Sadeghi | Spécialiste senior
- Sunil Sattiraju | Architecte de solutions cloud senior
- Amanjeet Singh | Responsable principal du programme
- Nagaraj Seeplapudur Venkatesan | Architecte de solutions cloud senior - Ingénierie
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
Présentations des produits Azure
- Introduction à Azure Data Lake Storage Gen2
- Présentation d’Apache Spark dans Azure HDInsight
- Qu’est-ce qu’Apache Hadoop dans Azure HDInsight ?
- Qu’est-ce qu’Apache HDBase dans Azure HDInsight
- Présentation d’Apache Kafka dans Azure HDInsight
Informations de référence sur les produits Azure
- Documentation Microsoft Entra
- Documentation Azure Cosmos DB
- Documentation Azure Data Factory
- Documentation Azure Databricks
- Documentation Azure Event Hubs
- Documentation Azure Functions
- Documentation Azure HDInsight
- Documentation sur la gouvernance des données Microsoft Purview
- Documentation d’Azure Stream Analytics
- Azure Synapse Analytics
Autres
- Pack Sécurité Entreprise pour Azure HDInsight
- Développer des programmes MapReduce Java pour Apache Hadoop sur HDInsight
- Utiliser Apache Sqoop avec Hadoop dans HDInsight
- Vue d’ensemble d’Apache Spark Streaming
- Tutoriel sur Structured Streaming
- Utiliser Azure Event Hubs à partir d’applications Apache Kafka