Migration Hadoop vers Azure
Apache Hadoop fournit un système de fichiers distribué et une infrastructure permettant d’utiliser des techniques MapReduce pour analyser et transformer des jeux de données très volumineux. Une caractéristique importante de Hadoop est le partitionnement des données et du calcul sur plusieurs (milliers) d’hôtes. Les calculs sont effectués en parallèle à proximité des données. Un cluster Hadoop met à l’échelle la capacité de calcul, la capacité de stockage et la bande passante d’E/S simplement en ajoutant du matériel de base.
Cet article est une vue d’ensemble de la migration de Hadoop vers Azure. Les autres articles de cette section fournissent des conseils de migration pour des composants Hadoop spécifiques. Il s'agit des éléments suivants :
- Migration Apache HDFS vers Azure
- Migration Apache HBase vers Azure
- Migration Apache Kafka vers Azure
- Migration Apache Sqoop vers Azure
Hadoop fournit un vaste écosystème de services et d’infrastructures. Ces articles ne décrivent pas en détail les composants Hadoop et les implémentations Azure. Au lieu de cela, ils fournissent des conseils et des considérations de haut niveau pour servir de point de départ pour vous permettre de migrer vos applications Hadoop locales et cloud vers Azure.
Apache®, Apache Spark®, Apache Hadoop®, Apache HBase, Apache Hive, Apache Ranger®, Apache Sentry®, Apache ZooKeeper®, Apache Storm®, Apache Sqoop®, Apache Flink®, Apache Kafka® et le logo de flamme sont des marques déposées ou des marques de l’Apache Software Foundation aux États-Unis et/ou dans d’autres pays. L’utilisation de ces marques n’implique aucune approbation de l’Apache Software Foundation.
Composants Hadoop
Les principaux composants d’un système Hadoop sont répertoriés dans le tableau suivant. Pour chaque composant, il existe une brève description et des informations de migration telles que :
- Liens vers des organigrammes de décision pour décider des stratégies de migration
- Liste des services cibles Azure possibles
| Composant | Description | Organigrammes de décisions | Services Azure ciblés |
|---|---|---|---|
| Apache HDFS | Système de fichiers DFS | Planification de la migration des données, Vérifications préalables avant la migration des données | Azure Data Lake Storage |
| Apache HBase | Service de table orienté colonne | Choix de la cible d’atterrissage pour Apache HBase, Choix du stockage pour Apache HBase sur Azure | HBase sur une machine virtuelle, HBase dans Azure HDInsight, Azure Cosmos DB |
| Apache Spark | Infrastructure de traitement des données | Choix de la cible d’atterrissage pour Apache Spark sur Azure | Spark dans HDInsight, Azure Synapse Analytics, Azure Databricks |
| Apache Hive | Infrastructure de l’entrepôt de données | Choix de la cible d’atterrissage pour Hive, Sélection de la base de données cible pour les métadonnées Hive | Hive sur une machine virtuelle, Hive dans HDInsight, Azure Synapse Analytics |
| Apache Ranger | Infrastructure pour la surveillance et la gestion de la sécurité des données | Pack Sécurité Entreprise pour HDInsight, Microsoft Entra ID, Ranger sur une machine virtuelle | |
| Apache Sentry | Infrastructure pour la surveillance et la gestion de la sécurité des données | Choix des cibles d’atterrissage pour Apache Sentry sur Azure | Sentry et Ranger sur une machine virtuelle, Pack Sécurité Entreprise pour HDInsight, Microsoft Entra ID |
| Apache MapReduce | Infrastructure de calcul distribué | MapReduce, Spark | |
| Apache Zookeeper | Service de coordination distribuée | ZooKeeper sur une machine virtuelle, solution intégrée dans platform as a service (PaaS) | |
| Apache YARN | Gestionnaire de ressources pour l’écosystème Hadoop | YARN sur une machine virtuelle, solution intégrée dans PaaS | |
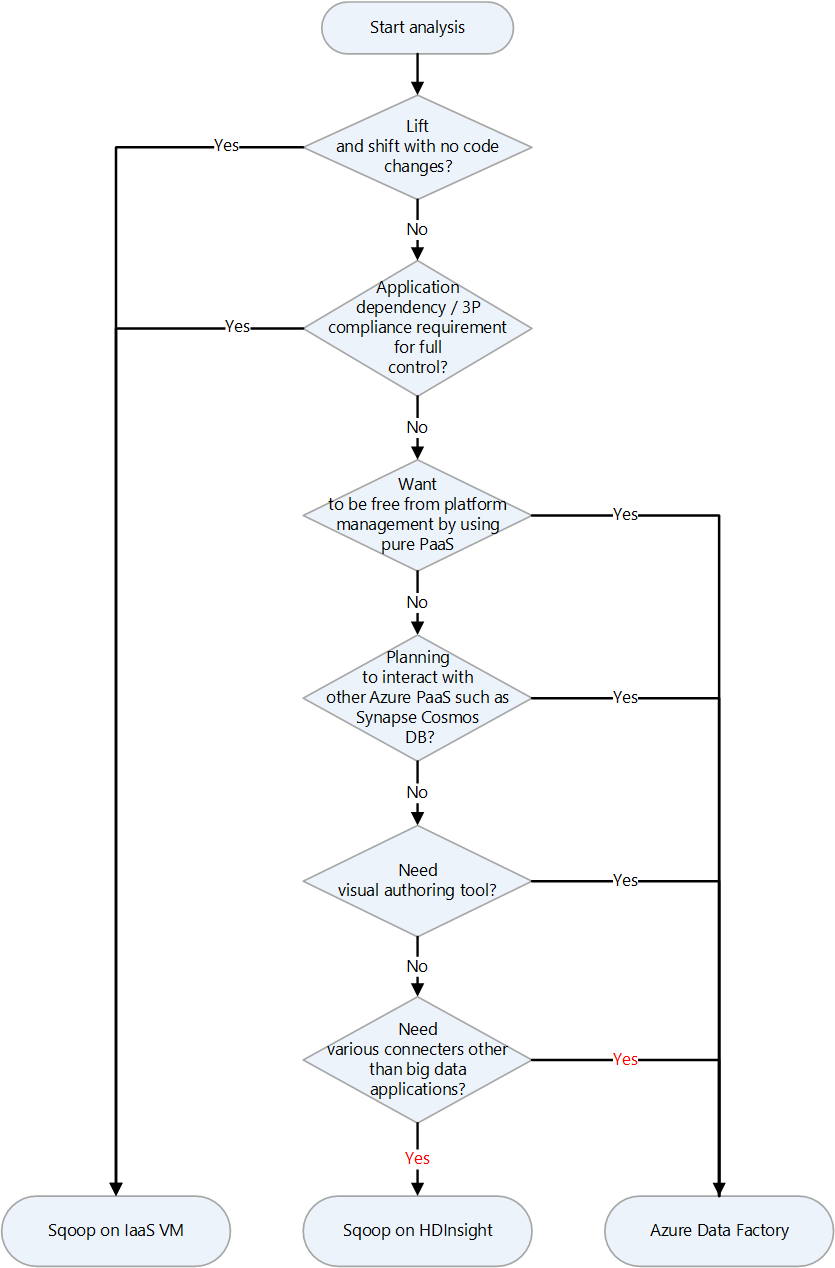
| Apache Sqoop | Outil d’interface de ligne de commande pour transférer des données entre des clusters Apache Hadoop et des bases de données relationnelles | Choix des cibles d’atterrissage pour Apache Sqoop sur Azure | Sqoop sur une machine virtuelle, Sqoop dans HDInsight, Azure Data Factory |
| Apache Kafka | Système de messagerie distribuée à tolérance de panne hautement évolutif | Choix des cibles d’atterrissage pour Apache Kafka sur Azure | Kafka sur une machine virtuelle, Event Hubs pour Kafka, Kafka sur HDInsight |
| Apache Atlas | Infrastructure open source pour la gouvernance des données et la gestion des métadonnées | Azure Purview |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Approches de migration
Le diagramme suivant montre trois approches pour migrer des applications Hadoop :

Téléchargez un fichier Visio de cette architecture.
Les approches sont les suivantes :
- Création d’une nouvelle plateforme à l’aide d’Azure PaaS : Pour plus d’informations, consultez Moderniser à l’aide d’Azure Synapse Analytics et Databricks.
- Lift-and-shift vers HDInsight : Pour plus d’informations, consultez Lift-and-Shift vers HDInsight.
- Lift-and-shift vers IaaS : Pour plus d’informations, consultez Lift-and-Shift vers Azure Infrastructure as a service (IaaS).
Moderniser à l’aide d’Azure Synapse Analytics et Databricks
Le diagramme qui suit montre cette approche :

Téléchargez un fichier Visio de cette architecture.
Lift-and-shift vers HDInsight
Le diagramme qui suit montre cette approche :

Téléchargez un fichier Visio de cette architecture.
Pour plus d’informations, veuillez consulter la section Migrer des clusters Apache Hadoop locaux vers Azure HDInsight.
Lift-and-shift vers Azure Infrastructure as a service (IaaS)
Le modèle suivant présente un point de vue sur la façon de déployer OSS sur Azure IaaS avec une intégration étroite aux systèmes locaux, tels qu’Active Directory, un contrôleur de domaine et DNS. Le déploiement suit les instructions de zone d’atterrissage à l’échelle de l’entreprise de Microsoft. Les fonctionnalités de gestion, telles que la surveillance, la sécurité, la gouvernance et la mise en réseau, sont hébergées dans un abonnement de gestion. Les charges de travail, basées sur IaaS, sont hébergées dans un abonnement distinct. Pour plus d’informations sur les zones d’atterrissage à l’échelle de l’entreprise, consultez Qu’est-ce qu’une zone d’atterrissage Azure ?

Téléchargez un fichier Visio de cette architecture.
- Active Directory local se synchronise avec Microsoft Entra ID à l’aide de Microsoft Entra Connect hébergé localement.
- Azure ExpressRoute fournit une connectivité réseau sécurisée et privée entre les services locaux et Azure.
- L’abonnement de gestion (ou hub) fournit des fonctionnalités de mise en réseau et de gestion pour le déploiement. Ce modèle est conforme aux conseils de zone d’atterrissage à l’échelle de l’entreprise de Microsoft.
- Les services hébergés à l’intérieur de l’abonnement hub fournissent des fonctionnalités de connectivité et de gestion réseau.
- NTP (hébergé sur une machine virtuelle Azure) est nécessaire pour que les horloges soient synchronisées sur toutes les machines virtuelles. Lorsque vous exécutez plusieurs applications, telles que HBase et ZooKeeper, vous devez exécuter un service NTP (Network Time Protocol) ou un autre mécanisme de synchronisation temporelle sur votre cluster. Tous les nœuds doivent utiliser le même service pour la synchronisation temporelle. Pour obtenir des instructions sur la configuration de NTP sur Linux, consultez la configuration NTP de base 14.6.
- Azure Network Watcher fournit des outils permettant de superviser, diagnostiquer et gérer les ressources dans un réseau virtuel Azure. Network Watcher est conçu pour superviser et réparer l’intégrité réseau des produits IaaS, y compris les machines virtuelles, les réseaux virtuels, les passerelles d’application et les équilibreurs de charge.
- Azure Advisor analyse votre télémétrie de configuration et d’utilisation des ressources, puis recommande des solutions pour améliorer la rentabilité, les performances, la fiabilité et la sécurité de vos ressources Azure.
- Azure Monitor offre une solution complète pour collecter, analyser et exploiter les données de télémétrie de vos environnements cloud et locaux. Il vous aide à comprendre le fonctionnement de vos applications afin que vous puissiez identifier de façon proactive les problèmes qui les affectent et les ressources dont elles dépendent.
- Un espace de travail Log Analytics est un environnement unique pour les données de journal Azure Monitor. Chaque espace de travail a son propre dépôt de données et sa propre configuration. Les solutions et sources de données sont configurées pour stocker leurs données dans un espace de travail particulier. Vous devez avoir un espace de travail Log Analytics si vous comptez collecter des données à partir des sources suivantes :
- Ressources Azure dans votre abonnement
- Ordinateurs locaux surveillés par System Center Operations Manager
- Collections d’appareils de System Center Configuration Manager
- Données de diagnostics ou de journaux du Stockage Azure
- L’agent autohébergé Azure DevOps hébergé sur des groupes de machines virtuelles identiques Azure vous offre une flexibilité sur la taille et l’image des machines sur lesquelles les agents s’exécutent. Vous spécifiez un groupe de machines virtuelles identiques, un certain nombre d’agents à conserver en veille, un nombre maximal de machines virtuelles dans le groupe identique. Azure Pipelines gère la mise à l’échelle de vos agents pour vous.
- Le locataire Microsoft Entra ID est synchronisé avec Active Directory local via les services de synchronisation Microsoft Entra Connect. Pour plus d'informations, consultez Microsoft Entra Connect Sync : Comprendre et personnaliser la synchronisation.
- Microsoft Entra Domain Services (Microsoft Entra Domain Services) fournit des fonctionnalités LDAP et Kerberos sur Azure. Lorsque vous déployez Microsoft Entra Domain Services pour la première fois, une synchronisation unidirectionnelle automatique est configurée et démarrée pour répliquer les objets à partir de Microsoft Entra ID. Cette synchronisation unidirectionnelle continue à s’exécuter en arrière-plan pour maintenir à jour le domaine managé Microsoft Entra Domain Services avec les modifications apportées par Microsoft Entra ID. Aucune synchronisation n’est effectuée entre Microsoft Entra Domain Services et Microsoft Entra ID.
- Les services, tels qu’Azure DNS, Microsoft Defender pour le cloud et Azure Key Vault, sont intégrés à l’abonnement de gestion et fournissent une résolution d’adresses IP/de service, une gestion unifiée de la sécurité de l’infrastructure et des fonctionnalités de gestion des certificats et des clés, respectivement.
- L’appairage de réseaux virtuels fournit une connectivité entre les réseaux virtuels déployés dans deux abonnements : gestion (hub) et charge de travail (spoke).
- Conformément aux zones d’atterrissage à l’échelle de l’entreprise, les abonnements de charge de travail sont utilisés pour héberger des charges de travail d’application.
- Azure Data Lake Storage est un ensemble de fonctionnalités s’appuyant sur le stockage Blob Azure pour effectuer l’analytique données du Big Data. Dans le contexte des charges de travail Big Data, Data Lake Storage peut être utilisé comme stockage secondaire pour Hadoop. Les données écrites dans Data Lake Storage peuvent être consommées par d’autres services Azure qui sont en dehors de l’infrastructure Hadoop.
- Les charges de travail Big Data sont hébergées sur un ensemble de machines virtuelles Azure indépendantes. Pour plus d’informations, consultez l’aide relative à HDFS, HBase, Hive, Ranger et Spark sur Azure IaaS.
- Azure DevOps est une offre SaaS (Software as a Service) qui fournit un ensemble intégré de services et d’outils pour gérer vos projets logiciels, de la planification et du développement, en passant par les tests et le déploiement.
État final de l’architecture de référence
L’un des défis liés à la migration des charges de travail depuis Hadoop local vers Azure est le déploiement pour atteindre l’état final souhaité pour l’architecture et l’application. Le projet décrit dans Migration Hadoop sur Azure PaaS est destiné à réduire l’effort important qui est généralement nécessaire pour déployer les services PaaS et l’application.
Dans ce projet, nous examinons l’état final de l’architecture pour les charges de travail Big Data sur Azure et répertorions les composants utilisés dans un déploiement de modèle Bicep. Avec Bicep, nous déployons uniquement les modules dont nous avons besoin pour déployer l’architecture. Nous aborderons les conditions préalables pour le modèle et les différentes méthodes de déploiement des ressources sur Azure, telles que One-click, Azure CLI, GitHub Actions et Azure DevOps Pipeline.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteurs principaux :
- Namrata Maheshwary | Architecte de solutions cloud senior
- Raja N | Directeur, Réussite des clients
- Hideo Takagi | Architecte de solutions cloud
- Ram Yerrabotu | Architecte de solutions cloud senior
Autres contributeurs :
- Ram Baskaran | Architecte de solutions cloud senior
- Jason Bouska | Ingénieur logiciel senior
- Eugene Chung | Architecte de solutions cloud senior
- Pawan Hosatti | Architecte de solutions cloud senior - Ingénierie
- Daman Kaur | Architecte de solutions cloud
- Danny Liu | Architecte de solutions cloud senior - Ingénierie
- Jose Mendez | Architecte de solutions cloud senior
- Ben Sadeghi | Spécialiste senior
- Sunil Sattiraju | Architecte de solutions cloud senior
- Amanjeet Singh | Responsable principal du programme
- Nagaraj Seeplapudur Venkatesan | Architecte de solutions cloud senior - Ingénierie
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
Présentations des produits Azure
- Introduction à Azure Data Lake Storage Gen2
- Présentation d’Apache Spark dans Azure HDInsight
- Qu’est-ce qu’Apache Hadoop dans Azure HDInsight ?
- Qu’est-ce qu’Apache HBase dans Azure HDInsight
- Présentation d’Apache Kafka dans Azure HDInsight
- Vue d’ensemble de la sécurité d’entreprise dans Azure HDInsight
Informations de référence sur les produits Azure
- Documentation Microsoft Entra
- Documentation Azure Cosmos DB
- Documentation Azure Data Factory
- Documentation Azure Databricks
- Documentation Azure Event Hubs
- Documentation Azure Functions
- Documentation Azure HDInsight
- Documentation sur la gouvernance des données Microsoft Purview
- Documentation d’Azure Stream Analytics
- Azure Synapse Analytics
Autres
- Pack Sécurité Entreprise pour Azure HDInsight
- Développer des programmes MapReduce Java pour Apache Hadoop sur HDInsight
- Utiliser Apache Sqoop avec Hadoop dans HDInsight
- Vue d’ensemble d’Apache Spark Streaming
- Tutoriel sur Structured Streaming
- Utiliser Azure Event Hubs à partir d’applications Apache Kafka