Redondance du routage global pour les applications web stratégiques
Important
La conception d’implémentations de redondance qui traitent les pannes de plateforme globales pour une architecture stratégique peut être complexe et coûteuse. En raison des problèmes potentiels qui peuvent survenir avec cette conception, réfléchissez soigneusement aux compromis.
Dans la plupart des cas, vous n’aurez pas besoin de l’architecture décrite dans cet article.
Les systèmes stratégiques s’efforcent de minimiser les points de défaillance uniques en créant autant que possible des fonctionnalités de redondance et d’autoréparation dans la solution. Tout point d’entrée unifié du système peut être considéré comme un point de défaillance. Si ce composant rencontre une panne, l’ensemble du système est hors connexion pour l’utilisateur. Lors du choix d’un service de routage, il est important de prendre en compte la fiabilité du service lui-même.
Dans l’architecture de base pour une application stratégique, Azure Front Door a été choisi en raison des contrats de niveau de service (SLA) offrant une durée de fonctionnement élevée et d’un ensemble de fonctionnalités riche :
- Acheminer le trafic vers plusieurs régions dans un modèle actif-actif
- Basculement transparent à l’aide de TCP anycast
- Distribuer du contenu statique à partir de nœuds de périphérie à l’aide de réseaux de distribution de contenu intégrés (CDN)
- Bloquer l’accès non autorisé avec le pare-feu d’applications web intégré
Front Door est conçu pour fournir la plus grande résilience et disponibilité non seulement à nos clients externes, mais également à plusieurs propriétés dans Microsoft. Pour plus d’informations sur les fonctionnalités de Front Door, consultez Accélérer et sécuriser votre application web avec Azure Front Door.
Les fonctionnalités de Front Door sont plus que suffisantes pour répondre à la plupart des besoins des entreprises, mais, avec n’importe quel système distribué, attendez-vous à une défaillance. Si les besoins de l’entreprise exigent un contrat SLA composite plus élevé ou aucun temps d’arrêt en cas de panne, vous devez vous appuyer sur un autre chemin d’entrée de trafic. Toutefois, la poursuite d’un contrat SLA plus élevé entraîne des coûts importants, une surcharge opérationnelle et peut réduire votre fiabilité globale. Examinez attentivement les compromis et les problèmes potentiels que l’autre chemin peut introduire dans d’autres composants qui se trouvent sur le chemin critique. Même lorsque l’impact de l’indisponibilité est important, la complexité peut l’emporter sur l’avantage.
Une approche consiste à définir un chemin d’accès secondaire, avec un ou plusieurs services de remplacement, qui devient actif uniquement lorsqu’Azure Front Door n’est pas disponible. La parité des fonctionnalités avec Front Door ne doit pas être traitée comme une exigence stricte. Hiérarchiser les fonctionnalités dont vous avez absolument besoin à des fins de continuité d’activité, même potentiellement exécutées dans une capacité limitée.
Une autre approche consiste à utiliser une technologie tierce pour le routage global. Cette approche nécessite un déploiement multicloud actif-actif avec des empreintes hébergées sur au moins deux fournisseurs de cloud. Même si Azure peut être intégré efficacement à d’autres plateformes cloud, cette approche n’est pas recommandée en raison de la complexité opérationnelle sur les différentes plateformes cloud.
Cet article décrit certaines stratégies de routage global à l’aide d’Azure Traffic Manager comme routeur secondaire dans les situations où Azure Front Door n’est pas disponible.
Approche
Ce diagramme d’architecture montre une approche générale avec plusieurs chemins de trafic redondants.
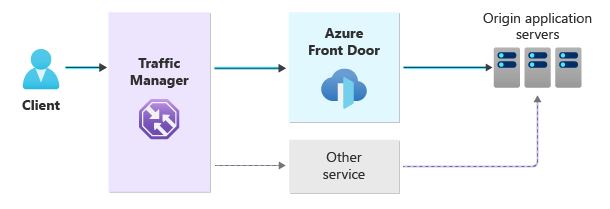
Avec cette approche, nous allons introduire plusieurs composants et fournir des conseils qui apporteront des modifications significatives associées à la livraison de vos applications web :
Azure Traffic Manager dirige le trafic vers Azure Front Door ou vers l’autre service que vous avez sélectionné.
Azure Traffic Manager est un équilibreur de charge global DNS. L’enregistrement CNAME de votre domaine pointe vers Traffic Manager, qui détermine la destination en fonction de la façon dont vous configurez sa méthode de routage. L’utilisation du routage prioritaire permet au trafic de transiter par Azure Front Door par défaut. Traffic Manager peut basculer automatiquement le trafic vers votre autre chemin si Azure Front Door n’est pas disponible.
Important
Cette solution atténue les risques associés aux pannes Azure Front Door, mais elle est vulnérable aux pannes d’Azure Traffic Manager en tant que point de défaillance global.
Vous pouvez également envisager d’utiliser un autre système de routage du trafic global, tel qu’un équilibreur de charge global. Toutefois, Traffic Manager fonctionne bien pour de nombreuses situations.
Vous avez deux chemins d’entrée :
Azure Front Door fournit le chemin principal et traite et achemine tout le trafic de votre application.
Un autre routeur est utilisé comme solution de secours pour Azure Front Door. Le trafic passe uniquement par ce chemin secondaire si Front Door n’est pas disponible.
Le service spécifique que vous sélectionnez pour le routeur secondaire dépend de nombreux facteurs. Vous pouvez choisir d’utiliser des services natifs Azure ou des services tiers. Dans ces articles, nous fournissons des options natives Azure pour éviter d’ajouter une complexité opérationnelle supplémentaire à la solution. Si vous utilisez des services tiers, vous devez utiliser plusieurs plans de contrôle pour gérer votre solution.
Vos serveurs d’applications d’origine doivent être prêts à accepter le trafic de l’un ou l’autre des services. Réfléchissez à la façon dont vous sécurisez le trafic vers votre origine et aux responsabilités de Front Door et d’autres services en amont. Assurez-vous que votre application peut gérer le trafic à partir du chemin par lequel il transite.
Compromis
Bien que cette stratégie d’atténuation puisse rendre l’application disponible pendant les pannes de plateforme, elle présente d’importants compromis. Vous devez évaluer les avantages potentiels par rapport aux coûts connus et prendre une décision éclairée quant à la valeur de ces avantages.
Coût financier : lorsque vous déployez plusieurs chemins redondants sur votre application, vous devez prendre en compte le coût de déploiement et d’exécution des ressources. Nous fournissons deux exemples de scénarios pour différents cas d’usage, chacun ayant un profil de coût différent.
Complexité opérationnelle : chaque fois que vous ajoutez des composants supplémentaires à votre solution, vous augmentez votre charge de gestion. Toute modification apportée à un composant peut avoir un impact sur d’autres composants.
Supposons que vous décidiez d’utiliser les nouvelles fonctionnalités d’Azure Front Door. Vous devez vérifier si votre autre chemin de trafic fournit également une fonctionnalité équivalente, et si ce n’est pas le cas, vous devez décider comment gérer la différence de comportement entre les deux chemins de trafic. Dans les applications réelles, ces complexités peuvent avoir un coût élevé et peuvent présenter un risque majeur pour la stabilité de votre système.
Performances : cette conception nécessite des recherches CNAME supplémentaires pendant la résolution de noms. Dans la plupart des applications, ce n’est pas un problème important, mais vous devez évaluer si les performances de votre application sont affectées par l’introduction de couches supplémentaires dans votre chemin d’entrée.
Coût d’opportunité : la conception et l’implémentation de chemins d’entrée redondants nécessitent un investissement d’ingénierie important, qui a finalement un coût d’opportunité pour le développement de fonctionnalités et d’autres améliorations de la plateforme.
Avertissement
Si vous n’êtes pas prudent dans la façon dont vous concevez et implémentez une solution de haute disponibilité complexe, vous pouvez réduire davantage la disponibilité. L’augmentation du nombre de composants dans votre architecture augmente le nombre de points de défaillance. Cela signifie également que vous avez un niveau plus élevé de complexité opérationnelle. Lorsque vous ajoutez des composants supplémentaires, chaque modification que vous apportez doit être soigneusement examinée pour comprendre comment elle affecte votre solution globale.
Disponibilité d’Azure Traffic Manager
Azure Traffic Manager est un service fiable, mais le contrat de niveau de service ne garantit pas une disponibilité à 100 %. Si Traffic Manager n’est pas disponible, vos utilisateurs risquent de ne pas pouvoir accéder à votre application, même si Azure Front Door et votre autre service sont tous deux disponibles. Il est important de planifier la façon dont votre solution continuera de fonctionner dans ces circonstances.
Traffic Manager retourne des réponses DNS pouvant être mises en cache. Si la durée de vie (TTL) sur vos enregistrements DNS permet la mise en cache, les courtes pannes de Traffic Manager peuvent ne pas être un problème. En effet, les résolveurs DNS en aval peuvent avoir mis en cache une réponse précédente. Vous devez vous préparer pour les pannes prolongées. Vous pouvez choisir de reconfigurer manuellement vos serveurs DNS pour diriger les utilisateurs vers Azure Front Door si Traffic Manager n’est pas disponible.
Cohérence du routage du trafic
Il est important de comprendre les fonctionnalités d’Azure Front Door que vous utilisez et sur lesquelles vous vous appuyez. Lorsque vous choisissez l’autre service, choisissez les fonctionnalités minimales dont vous avez besoin et omettez d’autres fonctionnalités lorsque votre solution est en mode dégradé.
Lors de la planification d’un autre chemin de trafic, voici quelques questions clés à prendre en compte :
- Utilisez-vous les fonctionnalités de mise en cache d’Azure Front Door ? Si la mise en cache n’est pas disponible, vos serveurs d’origine peuvent-ils suivre votre trafic ?
- Utilisez-vous le moteur de règles Azure Front Door pour effectuer une logique de routage personnalisée ou pour réécrire des demandes ?
- Utilisez-vous le pare-feu d’applications web (WAF) Azure Front Door pour sécuriser vos applications ?
- Limitez-vous le trafic en fonction de l’adresse IP ou de la zone géographique ?
- Qui émet et gère vos certificats TLS ?
- Comment restreindre l’accès à vos serveurs d’applications d’origine pour vous assurer qu’il passe par Azure Front Door ? Utilisez-vous Private Link ou des adresses IP publiques avec des balises de service et des en-têtes d’identificateur ?
- Vos serveurs d’applications acceptent-ils le trafic provenant d’un emplacement autre qu’Azure Front Door ? Si c’est le cas, quels protocoles acceptent-ils ?
- Vos clients utilisent-ils la prise en charge HTTP/2 d’Azure Front Door ?
Pare-feu d’applications web (WAF)
Si vous utilisez le WAF d’Azure Front Door pour protéger votre application, réfléchissez à ce qui se passe si le trafic ne passe pas par Azure Front Door.
Si votre chemin d’accès alternatif fournit également un WAF, tenez compte des questions suivantes :
- Peut-il être configuré de la même façon que votre WAF Azure Front Door ?
- Doit-il être paramétré et testé indépendamment pour réduire la probabilité de détection de faux positifs ?
Avertissement
Vous pouvez choisir de ne pas utiliser de WAF pour votre autre chemin d’entrée. Cette approche peut être envisagée pour prendre en charge la cible de fiabilité de l’application. Toutefois, ce n’est pas une bonne pratique et nous ne la recommandons pas.
Considérez l’inconvénient d’accepter le trafic en provenance d’Internet sans aucune vérification. Si un attaquant découvre un chemin de trafic secondaire non protégé vers votre application, il peut envoyer du trafic malveillant via votre chemin d’accès secondaire, même lorsque le chemin d’accès principal inclut un WAF.
Il est préférable de sécuriser tous les chemins d’accès à vos serveurs d’applications.
Noms de domaine et DNS
Votre application stratégique doit utiliser un nom de domaine personnalisé. Vous contrôlez la façon dont le trafic transite vers votre application et vous réduisez les dépendances sur un seul fournisseur.
Il est également recommandé d’utiliser un service DNS de haute qualité et résilient pour votre nom de domaine, tel qu’Azure DNS. Si les serveurs DNS de votre nom de domaine ne sont pas disponibles, les utilisateurs ne peuvent pas atteindre votre service.
Il est recommandé d’utiliser plusieurs résolveurs DNS pour augmenter encore plus la résilience globale.
Chaînage CNAME
Les solutions qui combinent Traffic Manager, Azure Front Door et d’autres services utilisent un processus de résolution CNAME DNS multicouche, également appelé chaînage CNAME. Par exemple, lorsque vous résolvez votre propre domaine personnalisé, vous pouvez voir cinq enregistrements CNAME ou plus avant qu’une adresse IP ne soit retournée.
L’ajout de liens supplémentaires à une chaîne CNAME peut affecter les performances de résolution de noms DNS. Toutefois, les réponses DNS sont généralement mises en cache, ce qui réduit l’impact sur les performances.
Certificats TLS
Pour une application stratégique, il est recommandé d’approvisionner et d’utiliser vos propres certificats TLS au lieu des certificats managés fournis par Azure Front Door. Vous réduirez le nombre de problèmes potentiels liés à cette architecture complexe.
Voici quelques avantages :
Pour émettre et renouveler des certificats TLS managés, Azure Front Door vérifie que vous êtes propriétaire du domaine. Le processus de vérification du domaine suppose que les enregistrements CNAME de votre domaine pointent directement vers Azure Front Door. Mais cette hypothèse n’est souvent pas correcte. L’émission et le renouvellement de certificats TLS managés sur Azure Front Door peuvent ne pas fonctionner correctement et vous augmentez le risque de pannes en raison de problèmes de certificat TLS.
Même si vos autres services fournissent des certificats TLS managés, ils peuvent ne pas être en mesure de vérifier la propriété du domaine.
Si chaque service obtient ses propres certificats TLS managés indépendamment, il peut y avoir des problèmes. Par exemple, les utilisateurs peuvent ne pas s’attendre à voir différents certificats TLS émis par différentes autorités, ou avec des dates d’expiration ou des empreintes numériques différentes.
Toutefois, des opérations supplémentaires seront liées au renouvellement et à la mise à jour de vos certificats avant leur expiration.
Sécurité de l’origine
Lorsque vous configurez votre origine pour accepter uniquement le trafic via Azure Front Door, vous bénéficiez d’une protection contre les attaques DDoS de couche 3 et de couche 4. Étant donné qu’Azure Front Door répond uniquement au trafic HTTP valide, il vous permet également de réduire votre exposition à de nombreuses menaces basées sur le protocole. Si vous modifiez votre architecture pour autoriser d’autres chemins d’entrée, vous devez évaluer si vous avez accidentellement augmenté l’exposition de votre origine aux menaces.
Si vous utilisez Private Link pour vous connecter à votre serveur d’origine à partir d’Azure Front Door, comment le trafic transite-t-il par votre autre chemin ? Pouvez-vous utiliser des adresses IP privées pour accéder à vos origines, ou devez-vous utiliser des adresses IP publiques ?
Si votre origine utilise l’étiquette de service Azure Front Door et l’en-tête X-Azure-FDID pour vérifier que le trafic a transité par Azure Front Door, réfléchissez à la façon dont vos origines peuvent être reconfigurées pour vérifier que le trafic a transité par l’un de vos chemins valides. Vous devez vérifier que vous n’avez pas ouvert accidentellement votre origine au trafic via d’autres chemins, y compris à partir des profils Azure Front Door d’autres clients.
Lorsque vous planifiez votre sécurité d’origine, vérifiez si le chemin de trafic alternatif repose sur l’approvisionnement d’adresses IP publiques dédiées. Cela peut nécessiter un processus déclenché manuellement pour mettre le chemin de secours en ligne.
S’il existe des adresses IP publiques dédiées, déterminez si vous devez implémenter Azure DDoS Protection pour réduire le risque d’attaques par déni de service contre vos origines. Déterminez également si vous devez implémenter le Pare-feu Azure ou un autre pare-feu capable de vous protéger contre diverses menaces réseau. Vous aurez peut-être également besoin d’autres stratégies de détection des intrusions. Ces contrôles peuvent être des éléments importants dans une architecture à plusieurs chemins plus complexe.
Modélisation de l’intégrité
La méthodologie de conception stratégique nécessite un modèle d’intégrité du système qui vous donne une observabilité globale de la solution et de ses composants. Lorsque vous utilisez plusieurs chemins d’entrée de trafic, vous devez superviser l’intégrité de chaque chemin. Si votre trafic est redirigé vers le chemin d’entrée secondaire, votre modèle d’intégrité doit refléter le fait que le système est toujours opérationnel, mais qu’il s’exécute dans un état dégradé.
Incluez ces questions dans la conception de votre modèle d’intégrité :
- Comment les différents composants de votre solution supervisent-ils l’intégrité des composants en aval ?
- Quand les moniteurs d’intégrité doivent-ils considérer les composants en aval comme non sains ?
- Combien de temps faut-il pour détecter une panne ?
- Une fois qu’une panne est détectée, combien de temps faut-il pour acheminer le trafic via un autre chemin ?
Il existe plusieurs solutions d’équilibrage de charge globales qui vous permettent de superviser l’intégrité d’Azure Front Door et de déclencher un basculement automatique vers une plateforme de sauvegarde en cas de panne. Azure Traffic Manager convient dans la plupart des cas. Avec Traffic Manager, vous configurez la supervision des points de terminaison pour superviser les services en aval en spécifiant l’URL à vérifier, la fréquence à laquelle cette URL est vérifiée et quand considérer le service en aval non sain en fonction des réponses de sonde. En général, plus l’intervalle entre les vérifications est court, moins il faut de temps à Traffic Manager pour diriger le trafic via un autre chemin d’accès pour atteindre votre serveur d’origine.
Si Front Door n’est pas disponible, plusieurs facteurs influencent la durée pendant laquelle la panne affecte votre trafic, notamment :
- Durée de vie (TTL) sur vos enregistrements DNS.
- Fréquence à laquelle Traffic Manager exécute ses contrôles d’intégrité.
- Nombre de sondes ayant échoué que Traffic Manager est configuré pour voir avant de rediriger le trafic.
- Durée pendant laquelle les clients et les serveurs DNS en amont mettent en cache les réponses DNS de Traffic Manager.
Vous devez également déterminer quels facteurs sont sous votre contrôle et si les services en amont en dehors de votre contrôle peuvent affecter l’expérience utilisateur. Par exemple, même si vous utilisez une durée de vie faible sur vos enregistrements DNS, les caches DNS en amont peuvent toujours servir des réponses obsolètes plus longtemps qu’ils ne le devraient. Ce comportement peut aggraver les effets d’une panne ou donner l’impression que votre application n’est pas disponible, même si Traffic Manager a déjà basculé l’envoi de requêtes vers l’autre chemin de trafic.
Conseil
Les solutions stratégiques nécessitent des approches de basculement automatisées dans la mesure du possible. Les processus de basculement manuel sont considérés comme lents pour que l’application reste réactive.
Reportez-vous à : Domaine de conception stratégique : modélisation de l’intégrité
Déploiement sans temps d’arrêt
Lorsque vous planifiez l’utilisation d’une solution avec un chemin d’entrée redondant, vous devez également planifier la façon dont vous déployez ou configurez vos services lorsqu’ils sont détériorés. Pour la plupart des services Azure, les contrats SLA s’appliquent à la durée de bon fonctionnement du service lui-même, et non aux opérations ou déploiements de gestion. Déterminez si vos processus de déploiement et de configuration doivent être résilients aux pannes de service.
Vous devez également prendre en compte le nombre de plans de contrôle indépendants avec lesquels vous devez interagir pour gérer votre solution. Lorsque vous utilisez des services Azure, Azure Resource Manager fournit un plan de contrôle unifié et cohérent. Toutefois, si vous utilisez un service tiers pour acheminer le trafic, vous devrez peut-être utiliser un plan de contrôle distinct pour configurer le service, ce qui introduit une complexité opérationnelle supplémentaire.
Avertissement
L’utilisation de plusieurs plans de contrôle introduit de la complexité et des risques pour votre solution. Chaque point de différence augmente la probabilité qu’une personne manque accidentellement un paramètre de configuration ou applique des configurations différentes à des composants redondants. Assurez-vous que vos procédures opérationnelles atténuent ce risque.
Reportez-vous à : Domaine de conception stratégique : déploiement sans temps d’arrêt
Validation continue
Pour une solution stratégique, vos pratiques de test doivent vérifier que votre solution répond à vos besoins, quel que soit le chemin par lequel transite le trafic de votre application. Tenez compte de chaque partie de la solution et de la façon dont vous la testez pour chaque type de panne.
Assurez-vous que vos processus de test incluent les éléments suivants :
- Pouvez-vous vérifier que le trafic est correctement redirigé via le chemin alternatif lorsque le chemin principal n’est pas disponible ?
- Les deux chemins peuvent-ils prendre en charge le niveau de trafic de production que vous prévoyez de recevoir ?
- Les deux chemins sont-ils correctement sécurisés pour éviter d’ouvrir ou d’exposer des vulnérabilités lorsque vous êtes dans un état dégradé ?
Reportez-vous à : Domaine de conception stratégique : validation continue
Scénarios courants
Voici des scénarios courants dans lesquels cette conception peut être utilisée :
La distribution de contenu global s’applique généralement à la distribution de contenu statique, aux médias et aux applications de commerce électronique à grande échelle. Dans ce scénario, la mise en cache est un aspect critique de l’architecture de la solution, et les échecs de mise en cache peuvent entraîner une dégradation significative des performances ou de la fiabilité.
L’entrée HTTP globale s’applique généralement aux applications et API dynamiques stratégiques. Dans ce scénario, l’exigence principale est d’acheminer le trafic vers le serveur d’origine de manière fiable et efficace. Souvent, un WAF est un contrôle de sécurité important utilisé dans ces solutions.
Avertissement
Si vous n’êtes pas prudent dans la façon dont vous concevez et implémentez une solution multi-entrée complexe, vous pouvez réduire davantage la disponibilité. L’augmentation du nombre de composants dans votre architecture augmente le nombre de points de défaillance. Cela signifie également que vous avez un niveau plus élevé de complexité opérationnelle. Lorsque vous ajoutez des composants supplémentaires, chaque modification que vous apportez doit être soigneusement examinée pour comprendre comment elle affecte votre solution globale.
Étapes suivantes
Passez en revue les scénarios d’entrée HTTP global et de distribution de contenu global pour déterminer s’ils s’appliquent à votre solution.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour