Disponibilité via la redondance de zone locale et interzone - Azure SQL Managed Instance
S’applique à : ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Cet article décrit l’architecture d’Azure SQL Managed Instance qui assure la disponibilité par le biais de la redondance locale et de la haute disponibilité par le biais de la redondance de zone.
Important
La configuration redondante interzone est disponible en préversion publique pour le niveau de service Usage général et disponible de manière générale pour le niveau de service Critique pour l’entreprise.
Vue d’ensemble
SQL Managed Instance s’exécute sur la dernière version stable du moteur de base de données SQL Server sur le système d'exploitation Windows avec tous les patchs applicables. SQL Managed Instance gère automatiquement les tâches de maintenance critiques, comme les mises à jour correctives, les sauvegardes, les mises à niveau de Windows et du moteur de base de données SQL, ainsi que les événements non planifiés, comme les défaillances sous-jacentes de type matériel, logiciel ou réseau. Quand une instance est corrigée ou bascule, le temps d’arrêt n’a aucun impact si vous utilisez une logique de nouvelle tentative dans votre application. Pour assurer la disponibilité de vos données, SQL Managed Instance bénéficie de fonctionnalités de récupération rapide, même dans les situations les plus critiques. La plupart des utilisateurs ne remarquent pas que les mises à niveau sont effectuées en continu.
Par défaut, Azure SQL Managed Instance obtient la disponibilité par le biais de la redondance locale, ce qui rend votre instance disponible pendant :
- Opérations de gestion initiées par le client qui entraînent un bref temps d’arrêt
- Opérations de maintenance de service
- Problèmes et pannes du centre de données avec :
- au rack où les machines qui alimentent votre service sont en cours d’exécution
- la machine physique qui héberge la machine virtuelle qui exécute le moteur de base de données SQL
- la machine virtuelle qui exécute le moteur de base de données SQL
- Autres problèmes liés au moteur de base de données SQL
- Autres pannes locales non planifiées potentielles
La solution de disponibilité par défaut permet de s’assurer que les données validées ne sont jamais perdues en raison de défaillances, que les opérations de maintenance n’affectent pas votre charge de travail et que l’instance n’est pas un point de défaillance unique dans votre architecture logicielle.
Toutefois, pour réduire l’impact sur vos données en cas de panne dans une zone entière, vous pouvez obtenir une haute disponibilité en activant la redondance de zone. Sans redondance de zone, les basculements se produisent localement au sein du même centre de données, ce qui peut entraîner l’indisponibilité de votre instance jusqu’à ce que la panne soit résolue. La seule façon de récupérer est via une solution de récupération d'urgence, telle qu’un groupe de basculement ou une géorestauration d’une sauvegarde géo-redondante. Pour plus d’informations, passez en revue la vue d'ensemble de la continuité d'activité.
La haute disponibilité augmente la fiabilité de votre service en vous protégeant de l’impact sur :
- la zone de disponibilité qui forme le centre de données
Il existe deux modèles architecturaux différents de disponibilité en fonction du niveau de service :
- Le modèle de stockage de dépôt distant se base sur une séparation du calcul et du stockage dans le niveau de service Usage général et Usage général nouvelle génération qui repose sur la disponibilité et la fiabilité du stockage de dépôt distant et sur la disponibilité des clusters de calcul managés par Azure Service Fabric. Ce modèle de disponibilité cible les applications de gestion des informations professionnelles à budget limité qui peuvent tolérer une certaine détérioration des performances pendant les activités de maintenance.
- Le modèle de stockage local est basé sur un cluster de processus de moteur de base de données qui repose sur un quorum de nœuds de moteur de base de données disponibles dans le niveau de service critique pour l'entreprise qui disposent d'un stockage local. Ce modèle de stockage local cible des applications stratégiques qui ont un taux de transaction élevé et nécessitent des performances d'E/S élevées. L'architecture de haute disponibilité garantit un impact minimal sur les performances de votre charge de travail pendant les activités de maintenance.
Pour plus d’informations sur les contrats SLA spécifiques des différents niveaux de service, consultez SLA pour Azure SQL Managed Instance.
la disponibilité par le biais de la redondance locale
La disponibilité localement redondante est basée sur le stockage de vos nœuds de calcul et les données dans un centre de données unique de la région primaire et protège vos données en cas de défaillance locale, comme une panne de l'alimentation ou du réseau à petite échelle. Si un sinistre de grande ampleur, comme un incendie ou une inondation, se produit dans une région, tous les réplicas d'un compte de stockage ou des données sur les nœuds de calcul peuvent être perdus ou irrécupérables. Par conséquent, envisagez une option de stockage plus résiliente pour vos sauvegardes de base de données afin de mieux protéger vos données si vous utilisez l'option de disponibilité localement redondante.
Niveau de service Usage général
Le niveau de service Usage général utilise l’architecture de disponibilité du stockage étendu. L’illustration suivante montre quatre nœuds distincts, avec les couches de calcul et de stockage séparées.
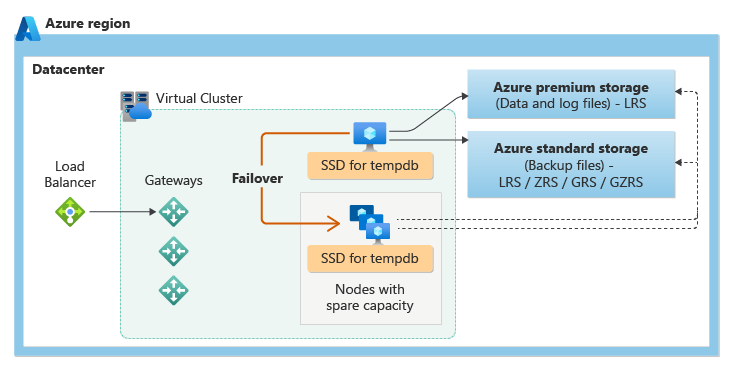
Le modèle de disponibilité du stockage étendu comprend deux couches :
- Une couche de calcul sans état, qui exécute le processus du moteur de base de données et contient uniquement des données transitoires et mises en cache comme les bases de données
tempdbetmodelsur le SSD attaché, ainsi que le cache du plan, le pool de mémoires tampons et le pool columnstore en mémoire. Ce nœud sans état est géré par Azure Service Fabric qui initialise le moteur de base de données, contrôle l'intégrité du nœud et effectue le basculement vers un autre nœud si nécessaire. - Une couche de données avec état, comprenant les fichiers de base de données (
.mdfet.ldf) stockés dans le service Stockage Blob Azure. Les fonctionnalités de disponibilité et de redondance des données sont intégrées au Stockage Blob Azure. La disponibilité localement redondante est basée sur le stockage de vos données sur un stockage localement redondant (LRS) qui copie vos données trois fois dans un centre de données unique de la région primaire. Celle-ci garantit la conservation de chaque enregistrement du fichier journal ou de chaque page du fichier de données, même si le moteur de base de données se bloque.
En cas de mise à niveau du moteur de base de données ou du système d’exploitation, ou si une défaillance est détectée, Azure Service Fabric déplace le moteur de base de données sans état vers un autre nœud de calcul sans état disposant d’une capacité disponible suffisante. Les données conservées dans le Stockage Blob Azure ne sont pas affectées par le déplacement. Les fichiers de données et de journaux sont joints au moteur de base de données qui vient d’être initialisé. Ce processus garantit une haute disponibilité. Toutefois, une charge de travail importante peut subir une détérioration des performances pendant la transition, car le nouveau processus de moteur de base de données démarre avec un cache froid.
Niveau de service Usage général nouvelle génération
Remarque
La mise à niveau vers le niveau de service Usage général nouvelle génération est actuellement en aperçu.
Usage général nouvelle génération est une mise à niveau architecturale du niveau de service Usage général existant. Elle utilise une couche de stockage à distance mise à niveau qui stocke les données d’instance et les fichiers journaux sur les disques managés au lieu des objets blob de pages.
Niveau de service Critique pour l’entreprise
Le niveau de service Critique pour l’entreprise utilise le modèle de disponibilité de stockage local, qui intègre des ressources de calcul (processus de moteur de base de données) et du stockage (SSD attaché localement) sur un nœud unique. La haute disponibilité est obtenue en répliquant le calcul et le stockage sur des nœuds supplémentaires.
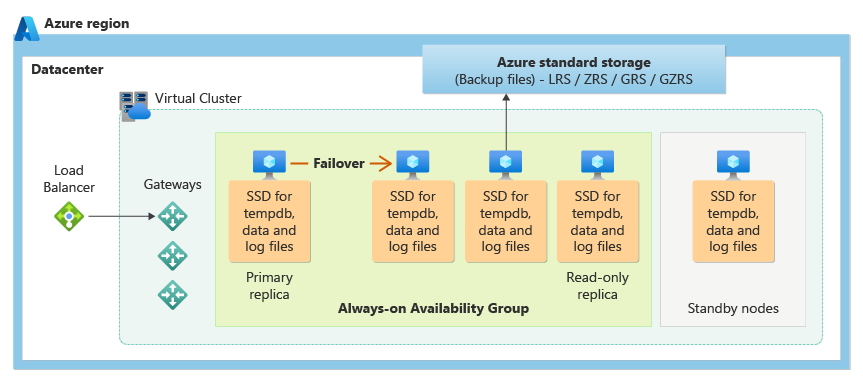
Les fichiers de base de données sous-jacents (.mdf/.ldf) sont placés sur un stockage SSD attaché pour fournir une E/S à très faible latence pour votre charge de travail. La haute disponibilité est implémentée au moyen d'une technologie semblable à celles des groupes de disponibilité AlwaysOn de SQL Server. Le cluster comprend un réplica principal unique qui est accessible pour les charges de travail de clients en lecture et en écriture, et jusqu'à trois réplicas secondaires (calcul et stockage) qui contiennent des copies de données. Le réplica principal envoie constamment des modifications aux réplicas secondaires de manière séquentielle afin de s'assurer que les données sont conservées sur un nombre suffisant de réplicas secondaires avant de valider chaque transaction. Ce processus garantit que, si le réplica principal ou un réplica secondaire accessible en lecture devient indisponible pour une raison quelconque, un réplica entièrement synchronisé est toujours disponible pour effectuer un basculement. Le basculement est initié par Azure Service Fabric. Quand un réplica secondaire devient le nouveau réplica principal, un autre réplica secondaire est créé afin de s’assurer que le cluster dispose d’un nombre suffisant de réplicas pour maintenir le quorum. Une fois le basculement terminé, les connexions Azure SQL sont automatiquement redirigées vers le nouveau réplica principal (ou le réplica secondaire accessible en lecture en fonction de la chaîne de connexion).
Le modèle de disponibilité de stockage local offre un avantage supplémentaire : il permet de rediriger les connexions Azure SQL en lecture seule vers l’un des réplicas secondaires. Cette fonctionnalité est appelée Scale-out en lecture. Elle fournit 100 % de capacité de calcul, sans frais supplémentaires, pour décharger depuis le réplica principal des opérations en lecture seule, telles que les charges de travail analytiques.
la haute disponibilité via la redondance de zone
La disponibilité redondante interzone est basée sur le placement de réplicas dans trois zones de disponibilité Azure dans la région primaire. Chaque zone de disponibilité est un emplacement physique distinct avec une alimentation, un refroidissement et une mise en réseau indépendants.
Par défaut, le cluster de nœuds pour le modèle de disponibilité de stockage local sont créés dans le même centre de données. Avec l’introduction des Zones de disponibilité Azure, SQL Managed Instance place différents réplicas dans différentes zones de disponibilité au sein de la même région. Pour éliminer un point de défaillance unique, l’anneau de contrôle est également dupliqué sur plusieurs zones. Le trafic du plan de contrôle est ensuite acheminé vers un équilibreur de charge qui est également déployé dans les zones de disponibilité. Le routage du trafic du plan de contrôle vers l’équilibreur de charge est contrôlé par Azure Traffic Manager (ATM).
En utilisant une configuration redondante interzone, vous rendez vos instances de niveau Critique pour l’entreprise ou à Usage général résilientes face à un nombre de défaillances beaucoup plus important, notamment aux interruptions graves du centre de données, sans aucune modification à la logique d’application. Vous pouvez convertir les instances de niveau Critique pour l’entreprise à Usage général existantes en configuration redondante interzone.
Les instances redondantes interzones disposent de réplicas dans différents centres de données avec une certaine distance de séparation. Par conséquent, le temps de réponse du réseau peut augmenter le temps de validation de la transaction et donc avoir un impact sur les performances de certaines charges de travail OLTP. Vous pourrez toujours revenir à la configuration de zone unique en désactivant le paramètre de redondance interzone. Ce processus est une opération en ligne qui ressemble à la mise à niveau de l’objectif des niveaux de service ordinaire. À la fin du processus, l’instance migre d’un anneau redondant interzone vers un anneau de zone unique, ou inversement.
Pour commencer à utiliser la redondance de zone pour votre SQL managed instance, passez en revue Configurer la redondance de zone.
Niveau de service Usage général
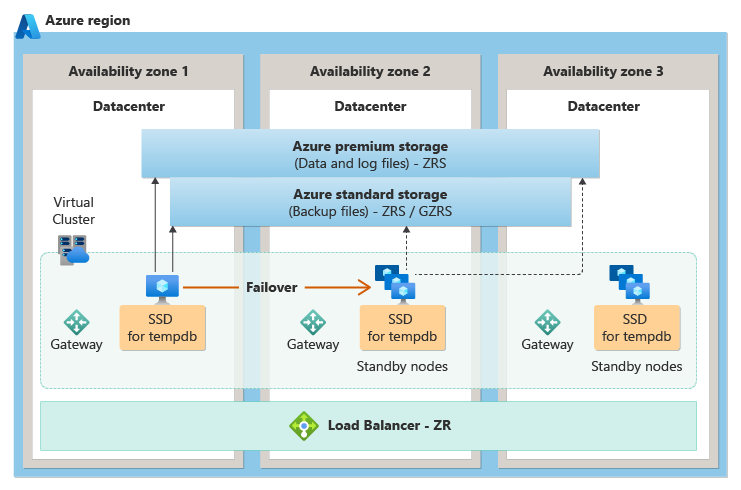
Dans le niveau de service Usage général, la redondance de zone est obtenue en plaçant des nœuds de calcul sans état dans différentes zones de disponibilité, puis s’appuie sur un stockage redondant interzone avec état (ZRS) attaché à quel nœud contient actuellement le processus SQL Moteur de base de données actif. En cas de panne, le processus SQL Moteur de base de données devient actif sur l’un des nœuds sans état, qui accède ensuite aux données dans le stockage avec état.
Le diagramme suivant illustre l’architecture de redondance de zone pour le niveau de service Usage général :
Remarque
La redondance de zone est actuellement prévue pour le niveau de service usage général.
Niveau de service Critique pour l’entreprise
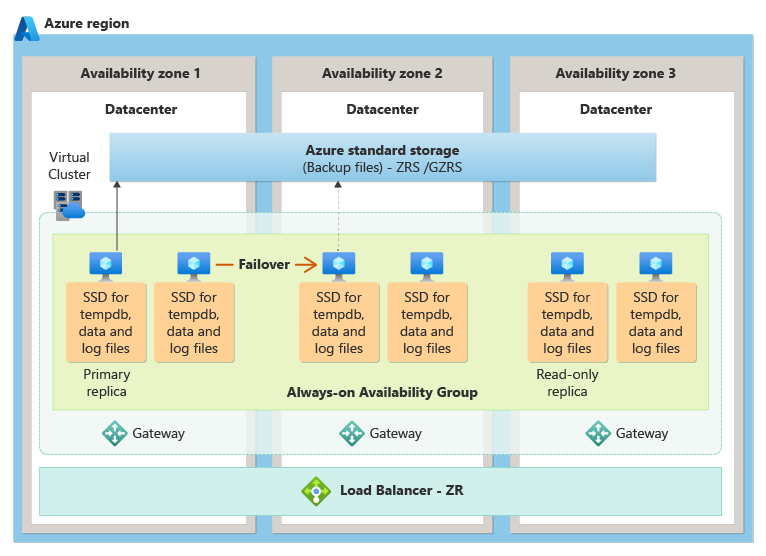
Dans le niveau de service Critique pour l'entreprise, la redondance de zone est obtenue en plaçant des réplicas de calcul et de stockage dans différentes zones de disponibilité, puis en utilisant la technologie de groupe de disponibilité Always On sous-jacente pour répliquer les modifications des données de l’instance principale vers les réplicas de secours dans d’autres zones de disponibilité. En cas de panne, il existe un basculement automatique qui fait passer en toute transparence l’un des réplicas de secours pour être principaux.
Le diagramme suivant illustre l’architecture de redondance de zone pour le niveau de service Critique pour l'entreprise :
Test de résilience aux erreurs de l’application
La disponibilité est un élément fondamental de la plateforme SQL Managed Instance qui fonctionne de manière transparente pour votre application de base de données. Cependant, nous sommes conscients que vous pourriez vouloir tester l'impact, sur une application, des opérations de basculement automatique lancées lors d'événements planifiés ou non planifiés avant de déployer l'application en production. Vous pouvez déclencher manuellement un basculement en appelant une API spéciale pour redémarrer une instance managée. Sachant que l’opération de redémarrage est intrusive et qu’un grand nombre de redémarrages pourrait peser sur la plateforme, un seul appel de basculement est autorisé toutes les 15 minutes pour chaque instance gérée.
Lors d’un vrai basculement, les connexions à l’instance échouent alors que le service SQL devient principal sur un autre nœud. Pour simuler un basculement, appelez la commande qui redémarre le processus SQL pour simuler le démarrage du service comme s’il y avait un basculement. Toutefois, les connexions peuvent échouer pendant une période plus longue pendant un basculement réel par rapport à un basculement simulé, car pendant un véritable basculement, le processus SQL devient le principal sur une autre machine virtuelle au sein du cluster (localement ou dans une autre zone si la redondance de zone est activée) et pendant un basculement simulé, le processus SQL est redémarré sur la machine virtuelle existante.
La commande de basculement manuel de cette section se comporte de la même façon que dans les configurations localement redondantes et redondantes interzone. Elle redémarre uniquement le processus SQL localement et ne lance pas de basculement vers un autre nœud. Ce basculement local est différent d’un basculement qui se produit pour un groupe de basculement.
Un basculement local peut être initié à l’aide de PowerShell, de l’API REST ou d’Azure CLI :
| PowerShell | API REST | Azure CLI |
|---|---|---|
| Invoke-AzSqlInstanceFailover | SQL Managed Instance – Basculement | Le basculement az sql mi peut être utilisé pour invoquer un appel d'API REST à partir d'Azure CLI |
Conclusion
Azure SQL Managed Instance offre une solution de haute disponibilité intégrée en profondeur à la plateforme Azure. Le service dépend de Service Fabric pour détecter les défaillances et les rétablir, du stockage Blob Azure pour protéger les données et des zones de disponibilité pour une plus grande tolérance de panne. Pour le niveau de service critique pour l'entreprise, SQL Managed Instance utilise la technologie de groupe de disponibilité SQL Server Always On pour la réplication de la base de données et le basculement. La combinaison de ces technologies permet aux applications de bénéficier pleinement des avantages d’un modèle de stockage mixte et prend en charge les contrats de niveau de service les plus exigeants.
Étapes suivantes
- Activez la redondance de zone pour Azure SQL Managed Instance.
- En savoir plus sur les Zones de disponibilité Azure
- En savoir plus sur Service Fabric
- En savoir plus sur Azure Traffic Manager.
- Découvrir Comment lancer un basculement manuel sur SQL Managed Instance
- Pour découvrir plus d’options concernant la haute disponibilité et la reprise d’activité après sinistre, consultez Continuité d’activité.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour