Utiliser Resource Health pour résoudre un problème de connectivité avec Azure SQL Managed Instance
S’applique à :![]() Azure SQL Managed Instance
Azure SQL Managed Instance
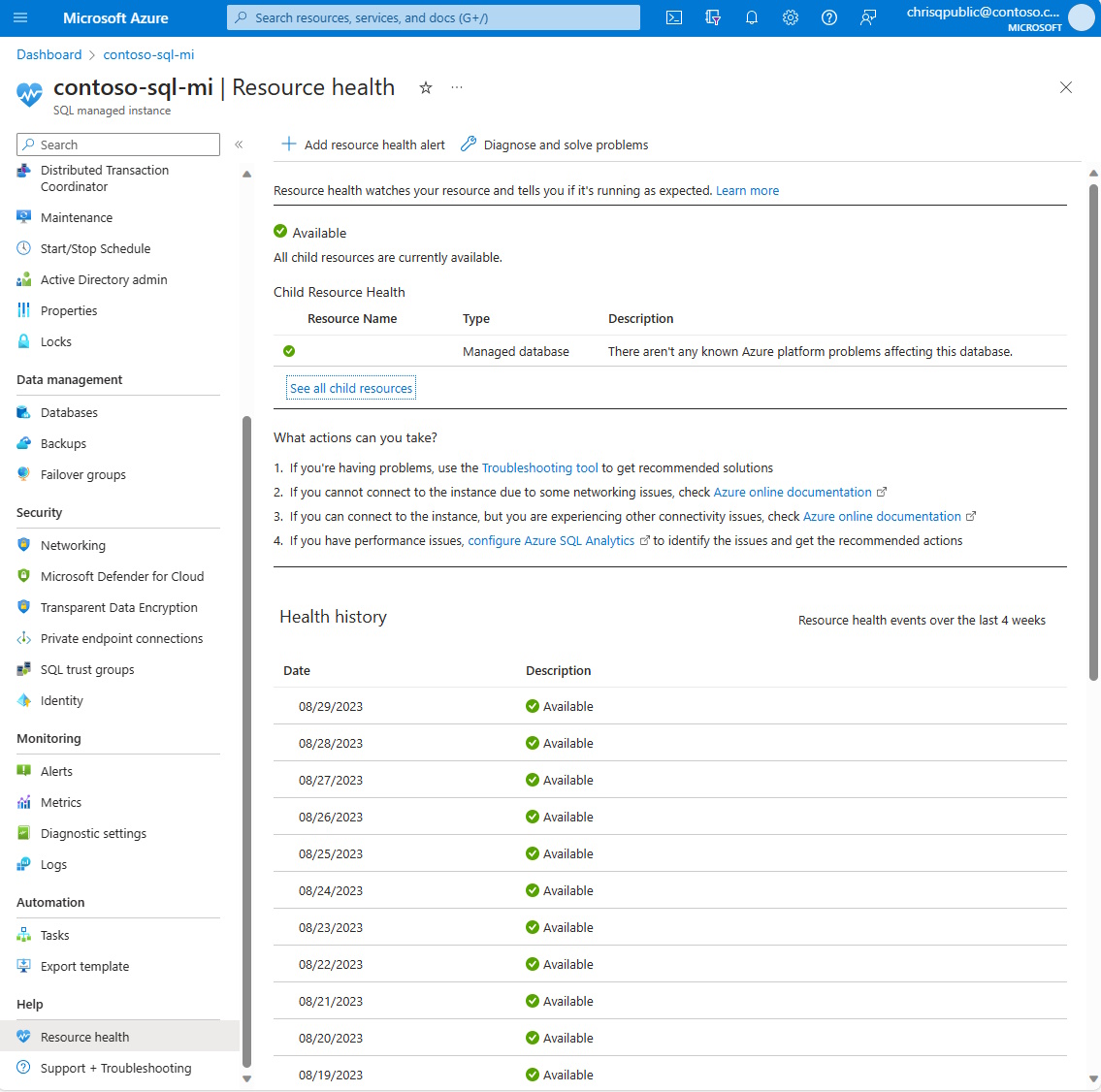
Resource Health pour Azure SQL Managed Instance vous aide à diagnostiquer les problèmes et à accéder au support quand un problème Azure a une incidence sur vos ressources. Il vous informe de l’intégrité (actuelle et passée) de vos ressources et vous aide à atténuer les problèmes. La page Resource Health propose un support technique dès lors que vous êtes confronté à des problèmes de service Azure et que vous avez besoin d’aide.
Contrôles d'intégrité
Resource Health détermine l’intégrité de votre SQL Managed Instance en examinant la réussite et échec des connexions à la ressource. Actuellement, Resource Health pour votre SQL Managed Instance examine uniquement les échecs de connexion dus à une erreur système et non à une erreur utilisateur. L’état d’intégrité est mis à jour toutes les une à deux minutes.
États d'intégrité
Disponible
Un état Disponible signifie que Resource Health n’a pas détecté d’échecs de connexion dus à des erreurs système sur votre SQL Managed Instance.
Détérioré
Un état Détérioré signifie que Resource Health a détecté une majorité de connexions établies, mais également des échecs. Il s’agit probables erreurs de connexion temporaires. Pour réduire l’impact des problèmes de connexion dus à des erreurs de connexion temporaires, implémentez une logique de nouvelle tentative dans votre code.
Non disponible
Un état Indisponible signifie que Resource Health a détecté des échecs de connexion constants dans votre SQL Managed Instance. Si votre ressource reste dans cet état pendant une période prolongée, contactez le support technique.
Inconnu
L’état d’intégrité Inconnu indique que Resource Health n’a reçu aucune information sur cette ressource depuis plus de 10 minutes. Même si cet état n’est pas une indication définitive de l’état de la ressource, il s’agit d’un point de données important dans le processus de dépannage. Si la ressource fonctionne comme prévu, son état devient Disponible après quelques minutes. Si vous rencontrez des problèmes avec la ressource, l’état d’intégrité Inconnu peut suggérer qu’un événement de la plateforme influe sur la ressource.
Informations d’historique
Vous pouvez accéder à 30 jours maximum d’historique de l’intégrité dans la section Historique de l’intégrité de Resource Health. La section contient également la raison de l’arrêt (le cas échéant). Actuellement, Azure indique le temps d’arrêt de votre ressource avec une granularité de deux minutes. Le temps d’arrêt réel est probablement inférieur à une minute. La moyenne est de huit secondes.
Raisons des temps d’arrêt
Lorsque votre SQL Managed Instance est arrêtée, une analyse est effectuée pour en déterminer la cause. Lorsqu’elle est disponible, la raison du temps d’arrêt est signalée dans la section Historique de l’intégrité de Resource Health. Les raisons des temps d’arrêt sont généralement publiées 45 minutes après un événement.
Sélectionner une fenêtre de maintenance
Vous pouvez configurer votre fenêtre de maintenance pour rendre les événements de maintenance importants prévisibles et moins perturbants pour votre charge de travail. La fonctionnalité de fenêtre de maintenance vous aide à planifier les mises à niveau prévisibles ou la maintenance planifiée. Les notifications préalables sont disponibles pour toutes les SQL Managed Instances. Les notifications préalables permettent aux clients de configurer des notifications à envoyer jusqu’à 24 heures à l’avance de tout événement planifié.
Maintenance planifiée
L’infrastructure Azure effectue régulièrement une maintenance planifiée (mise à niveau des composants matériels ou logiciels dans le centre de données). Pendant la maintenance de la base de données, Azure SQL peut mettre fin à des connexions existantes et en refuser de nouvelles. Les échecs de connexion rencontrés pendant une maintenance planifiée sont généralement temporaires. Une logique de nouvelle tentative pour les erreurs réseau occasionnelles permet d’en réduire l’impact. Si vous êtes toujours confronté à des erreurs de connexion, contactez le support technique.
Reconfiguration
Les reconfigurations sont considérées comme des conditions transitoires et prévues de temps à autre. Ces événements peuvent être déclenchés par les échecs d’équilibrage de charge ou de logiciel/matériel. Toute application de production client qui se connecte à une base de données cloud doit implémenter une logique de nouvelle tentative pour les erreurs temporaires de connexion robuste, qui aide à remédier à ces situations et rend généralement les erreurs transparentes pour l’utilisateur final.
Étapes suivantes
- Apprenez-en davantage sur la logique de nouvelle tentative pour les erreurs temporaires.
- Diagnostiquer, résoudre et empêcher les erreurs de connexion SQL.
- Apprenez-en davantage sur la configuration des alertes Resource Health.
- Découvrez une vue d’ensemble de Resource Health.
- Consultez le FAQ Resource Health.
- Configurez une fenêtre de maintenance et des notifications préalables.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour