Architecture de Sauvegarde Azure pour la sauvegarde de SAP HANA
Le service Sauvegarde Azure vous permet de sauvegarder des données à partir de bases de données SAP HANA dans une application de manière cohérente. Cet article décrit l’architecture, les composants et les processus de Sauvegarde Azure.
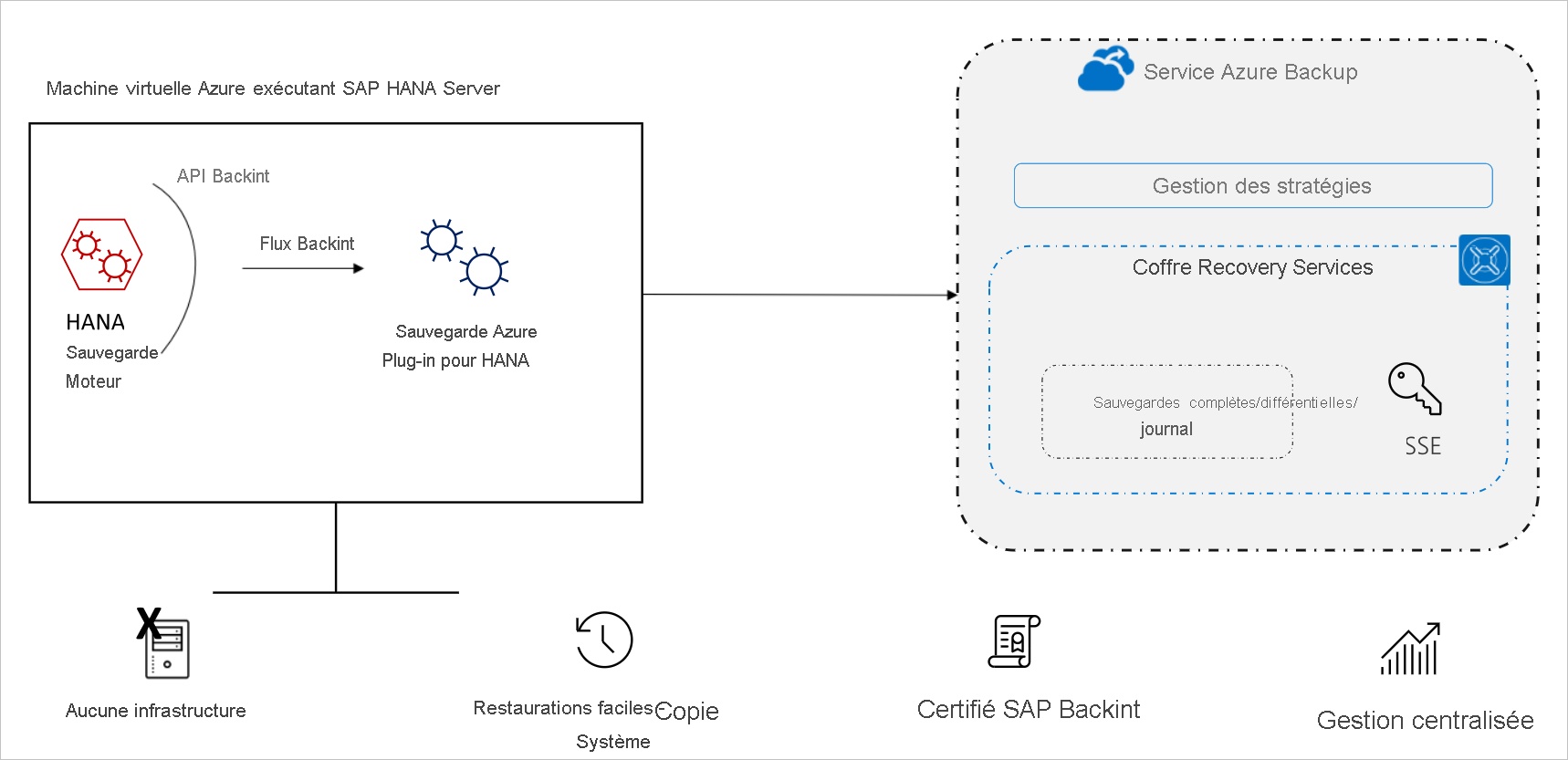
Le service Sauvegarde Azure fournit une solution de sauvegarde par diffusion en continu pour sauvegarder les bases de données SAP HANA s’exécutant sur une machine virtuelle Azure. Cette offre de sauvegarde nécessite une configuration sans infrastructure, ce qui élimine la nécessité de déployer et de gérer une infrastructure de sauvegarde.
Le service Sauvegarde Azure certifié Backint par SAP assure la prise en charge de sauvegarde native à l’aide d’API natives de SAP HANA. Cette solution vous permet de sauvegarder et restaurer en toute transparence les bases de données SAP HANA s’exécutant sur des machines virtuelles Azure, ainsi que d’utiliser les fonctionnalités de gestion d’entreprise de Sauvegarde Azure.
En savoir plus sur les valeurs ajoutées qu’apporte Sauvegarde Azure pour SAP HANA.
Sauvegarde Azure stocke les données sauvegardées dans des coffres Recovery Services. Un coffre est une entité de stockage en ligne dans Azure qui permet de stocker des données telles que des copies de sauvegarde, des points de récupération et des stratégies de sauvegarde.
En savoir plus sur le coffre Recovery Services.
Pour sauvegarder des bases de données SAP HANA s’exécutant sur une machine virtuelle Azure, vous devez autoriser l’installation du plug-in (agent de sauvegarde SAP HANA) sur la machine virtuelle Azure. Ce plug-in se connecte à HANA Backint et aide le service Sauvegarde Azure à déplacer les données vers le coffre. Il permet également au service Sauvegarde Azure d’effectuer des restaurations.
En savoir plus sur les types de sauvegardes SAP HANA.
Dans les sections suivantes, vous allez découvrir l’architecture de sauvegarde des bases de données HANA dans Sauvegarde Azure.
Examinez l’architecture de haut niveau de Sauvegarde Azure pour les bases de données SAP HANA. Pour une compréhension détaillée du processus de sauvegarde, examinez le processus suivant :
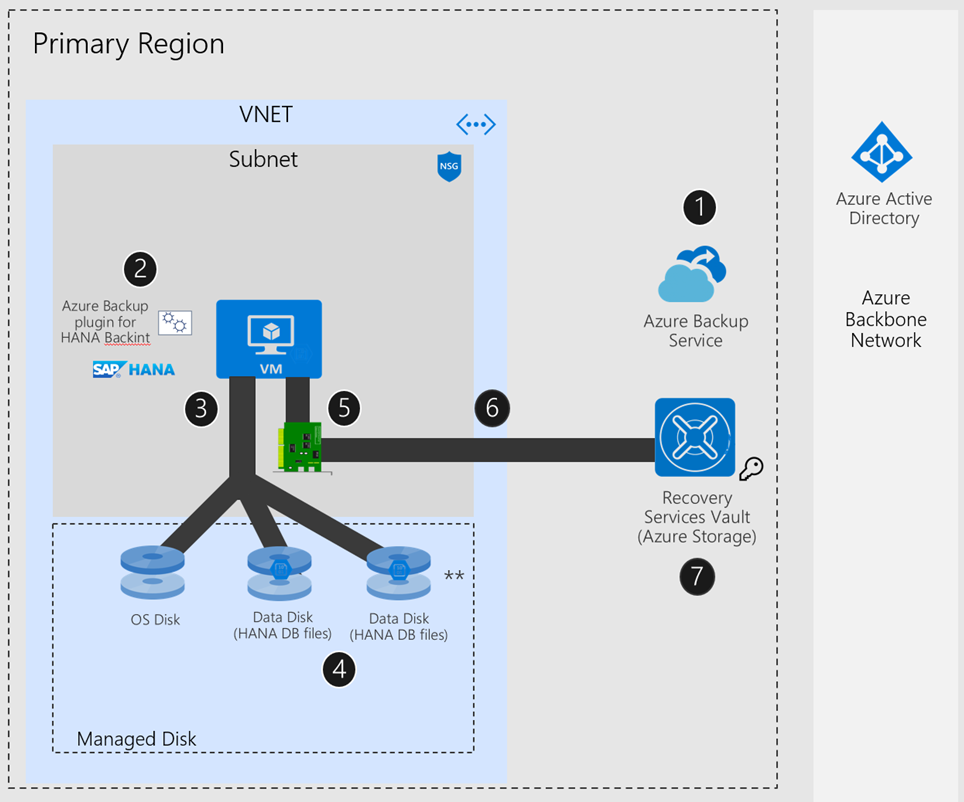
Pour commencer le processus de sauvegarde, créez un coffre Recovery Services dans Azure. Ce coffre sera utilisé pour stocker les sauvegardes et les points de récupération créés au fil du temps.
La machine virtuelle Azure exécutant un serveur SAP HANA est inscrite auprès du coffre, et les bases de données à sauvegarder sont découvertes. Pour permettre au service Sauvegarde Azure de découvrir les bases de données, vous devez exécuter ce script de préinscription sur le serveur HANA en tant qu’utilisateur racine.
Notes
Assurez-vous que l’instance HANA est en cours d’exécution pendant la découverte des bases de données dans cette instance.
Assurez-vous également que les autres conditions préalables sont remplies.
Important
Assurez-vous que la condition préalable pour configurer la connectivité réseau appropriée est remplie. Consultez la recommandation relative à la configuration des machines virtuelles Azure s’exécutant dans SAP Hana avec des composants réseau supplémentaires pour utiliser l’offre de sauvegarde.
Examinez les détails de ce que fait le script de préinscription. Si vous tentez de configurer une sauvegarde pour des bases de données SAP HANA sans exécuter ce script, il se peut que vous receviez l’erreur UserErrorHanaScriptNotRun.
Le service Sauvegarde Azure installe à présent le plug-in Sauvegarde Azure pour HANA sur le serveur SAP HANA inscrit. Ce plug-in se sert de l’utilisateur de Sauvegarde créé par le script de préinscription pour effectuer toutes les opérations de sauvegarde et de restauration.
Pour configurer une sauvegarde sur les bases de données découvertes, choisissez la stratégie de sauvegarde requise, puis activez les sauvegardes.
Le service Sauvegarde Azure pour SAP HANA (solution certifiée par BackInt), ne dépend pas des types de disque ou de machine virtuelle sous-jacents. La sauvegarde est effectuée via des flux générés par HANA.
Cette section vous permet de découvrir le processus de sauvegarde d’une base de données HANA exécutée sur une machine virtuelle Azure.
Les sauvegardes planifiées sont gérées par des entrées crontab créées sur la machine virtuelle HANA, tandis que les sauvegardes à la demande sont déclenchées directement par le service Sauvegarde Azure.
Lorsque le moteur de sauvegarde/Backint SAP HANA reçoit la demande de sauvegarde, il prépare la base de données SAP HANA pour une sauvegarde en créant un point d’enregistrement et en déplaçant les données vers les volumes de stockage sous-jacents.
Backint exécute ensuite l’opération de lecture à partir des volumes de données sous-jacents : le serveur d’index et le moteur XS pour la base de données de locataire, et le serveur de noms pour la SYSTEMDB. Les disques SSD Premium peuvent fournir un débit d’E/S optimal pour l’opération de diffusion en continu de sauvegarde. Toutefois, l’utilisation de disques non mis en cache avec M64Is peut offrir des vitesses supérieures.
Pour diffuser en continu les données de sauvegarde, Backint crée jusqu’à trois canaux qui écrivent directement dans le coffre Recovery Services de Sauvegarde Azure.
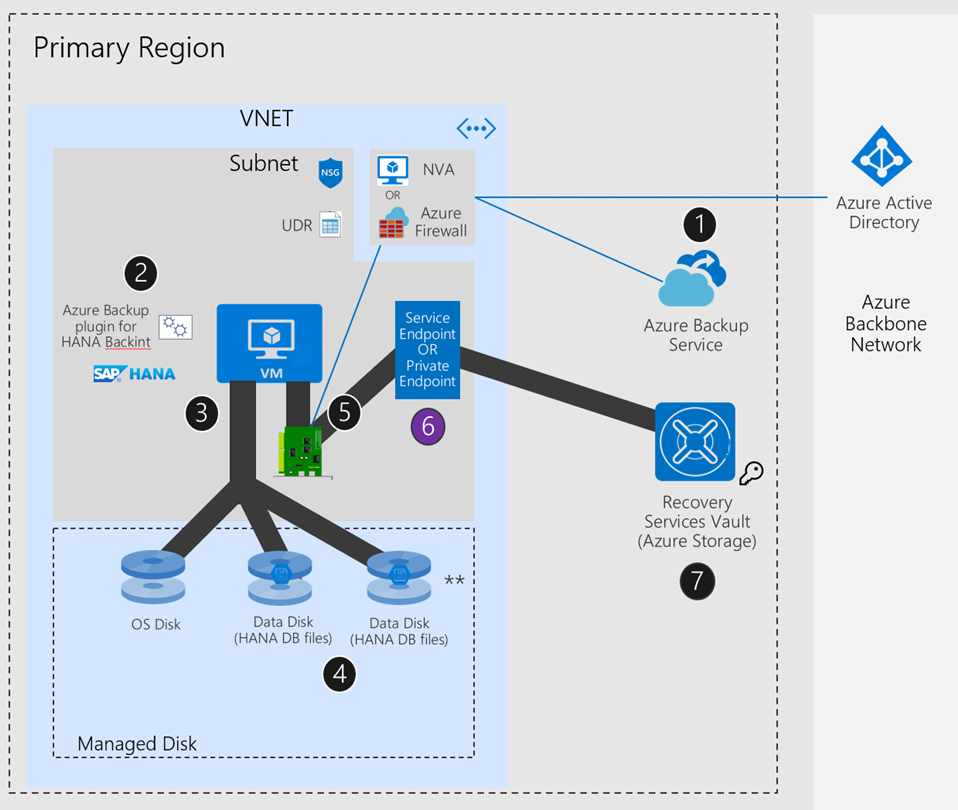
Si vous n’utilisez pas de pare-feu/appliance virtuelle réseau dans votre configuration, le flux de sauvegarde est transféré via le réseau Azure vers le coffre Recovery Services/Stockage Azure. Par ailleurs, vous pouvez configurer un point de terminaison de service de réseau virtuel ou un point de terminaison privé pour autoriser SAP HANA à envoyer le trafic de sauvegarde directement à un coffre Recovery Services ou Stockage Azure, en ignorant l’appliance virtuelle réseau ou le Pare-feu Azure. En outre, lorsque vous utilisez un pare-feu ou une appliance virtuelle réseau, le trafic vers Microsoft Entra ID et le service Sauvegarde Azure transite par le pare-feu ou l’appliance virtuelle réseau sans affecter les performances globales de sauvegarde.
Le service Sauvegarde Azure tente d’atteindre des vitesses jusqu’à 420 Mo/s pour les sauvegardes autres que de journaux et jusqu’à 100 Mo/s pour les sauvegardes de journaux. En savoir plus sur les performances en matière de débit de sauvegarde et de restauration.
Des journaux détaillés sont écrits dans les fichiers backup.log et backint.log sur l’instance SAP HANA.
Une fois la diffusion en continu de la sauvegarde terminée, le catalogue est diffusé vers le coffre Recovery Services. Si la sauvegarde (complète/différentielle/incrémentielle/de journal) et le catalogue pour cette sauvegarde sont correctement diffusés et enregistrés dans le coffre Recovery Services, le service Sauvegarde Azure considère que l’opération de sauvegarde est réussie.
Dans les sections suivantes, vous allez découvrir les différentes configurations SAP HANA et leur processus d’exécution de sauvegardes.
Scénario de configuration de SAP HANA : réseau Azure - sans appliance virtuelle réseau/Pare-feu Azure
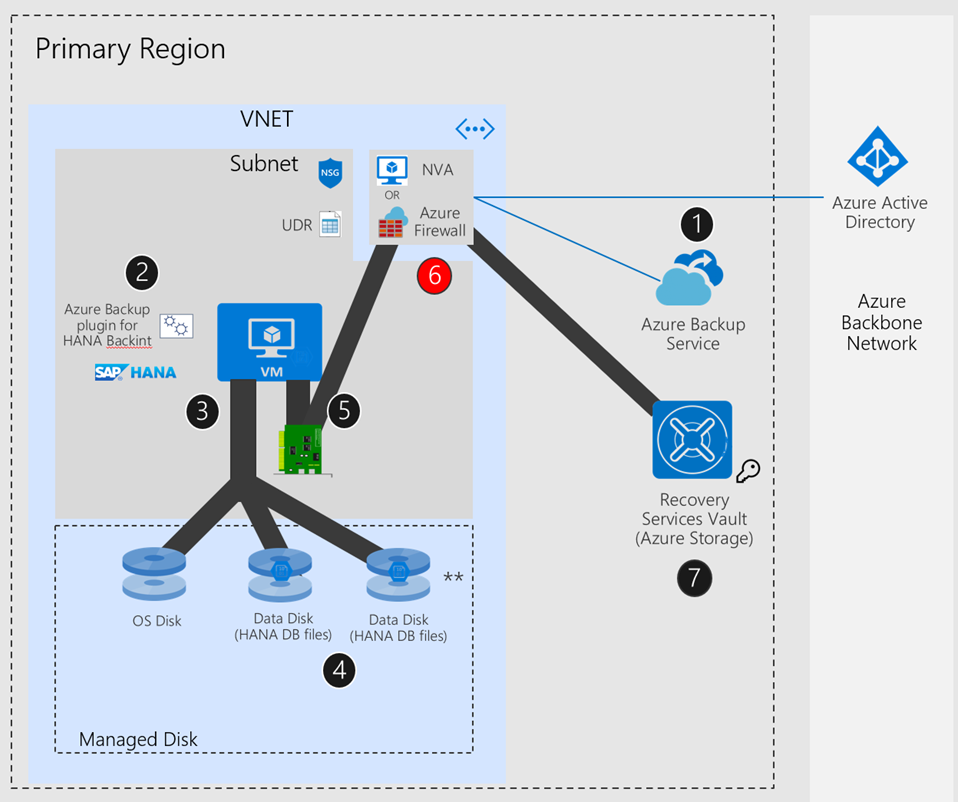
Scénario de configuration de SAP HANA : réseau Azure - avec itinéraire défini par l’utilisateur (UDR) + appliance virtuelle réseau/Pare-feu Azure
Notes
L’appliance virtuelle réseau ou le Pare-feu Azure peuvent ajouter une surcharge quand SAP HANA diffuse la sauvegarde vers le service Stockage Azure/coffre Recovery Services (plan de données). Regarde le point 6 dans le diagramme ci-dessus.
Scénario de configuration de SAP HANA : réseau Azure - avec itinéraire défini par l’utilisateur (UDR) + appliance virtuelle réseau/Pare-feu Azure + Point de terminaison privé ou Point de terminaison de service
Le service de sauvegarde réside dans les deux nœuds physiques de la configuration du HSR. Une fois que vous confirmez que ces nœuds se trouvent dans un groupe de réplication (à l’aide du script de préinscription), Sauvegarde Azure regroupe les nœuds logiquement et crée un seul élément de sauvegarde pendant la configuration de la protection.
Après la configuration, Sauvegarde Azure accepte les demandes de sauvegarde à partir du nœud principal. Lors du basculement, lorsque le nouveau nœud principal commence à générer des demandes de sauvegarde de journal, Sauvegarde Azure compare les nouvelles sauvegardes de journaux à la chaîne existante à partir du nœud principal plus ancien.
Si les sauvegardes sont séquentielles, Sauvegarde Azure les accepte et protège le nouveau nœud principal. S’il existe une incohérence ou un saut dans la séquence de journaux de transactions consécutifs, Sauvegarde Azure déclenche une sauvegarde complète corrective et les sauvegardes de journaux réussissent uniquement une fois la sauvegarde complète corrigée terminée.

Notes
Le service Sauvegarde Azure se connecte à HANA à l’aide de clés hdbuserstore. Comme les clés ne sont pas répliquées, nous vous recommandons de créer les mêmes clés dans tous les nœuds, afin que Sauvegarde Azure puisse se connecter automatiquement à tout nouveau nœud principal, sans intervention manuelle après le basculement/restauration automatique.
Dans les sections suivantes, vous allez découvrir le flux de sauvegarde pour les machines nouvelles/existantes.
Cette section vous permet de découvrir le processus de sauvegarde d’une base de données HANA avec la réplication de système HANA activée s’exécutant sur une nouvelle machine virtuelle Azure.
- Créez un utilisateur et une clé
hdbuserstorepersonnalisés sur tous les nœuds. - Exécutez le script de préinscription sur les deux nœuds avec l’utilisateur personnalisé comme utilisateur de sauvegarde pour implémenter un ID, ce qui indique que les deux nœuds appartiennent à un groupe unique/commun.
- Pendant la configuration de protection HANA, sélectionnez les deux nœuds pour découvrir. Cela permet d’identifier les deux nœuds en tant que base de données unique que vous pouvez associer à une stratégie et protéger
Cette section vous permet de découvrir le processus de sauvegarde d’une base de données HANA avec la réplication de système HANA activée s’exécutant sur une machine virtuelle Azure existante.
Arrêtez la protection et conservez les données pour les deux nœuds.
Exécutez le script de préinscription sur les deux nœuds avec l’utilisateur personnalisé comme utilisateur de sauvegarde pour mentionner un ID, ce qui indique que les deux nœuds appartiennent à un groupe unique/commun.
Redécouvrez les bases de données dans le nœud principal.
Configurez la sauvegarde pour la base de données répliquée nouvellement créée à partir de l’étape 2 de la configuration de la sauvegarde.
Supprimez les données de sauvegarde des anciens éléments de sauvegarde autonomes pour lesquels la protection a été suspendue.

Notes
Pour les machines virtuelles HANA qui sont déjà sauvegardées en tant que machines individuelles, vous pouvez effectuer le regroupement uniquement pour les sauvegardes futures.
La Sauvegarde Azure intègre des instantanés complets ou incrémentiels de disque managé Azure à des commandes d’instantané HANA pour fournir des fonctionnalités de sauvegarde et de récupération instantanées pour HANA.
Sauvegarde de l’instantané d’instance de base de données SAP HANA
L’architecture de sauvegarde explique les différentes autorisations nécessaires au service Sauvegarde Azure qui réside sur une machine virtuelle HANA pour prendre des instantanés des disques managés et les placer dans un groupe de ressources spécifié par l’utilisateur mentionné dans la stratégie. Pour ce faire, vous pouvez utiliser l’identité managée affectée par le système de la machine virtuelle source.

Restauration de l’instantané d’instance de base de données SAP HANA
L’architecture de restauration explique les différentes autorisations requises pendant l’opération de restauration. La Sauvegarde Azure utilise l’identité managée de la machine virtuelle cible pour lire les instantanés de disque à partir d’un groupe de ressources spécifié par l’utilisateur, créer des disques dans un groupe de ressources cible et les attacher à la machine virtuelle cible.

- Découvrez les configurations et scénarios pris en charge dans la matrice de prise en charge des sauvegardes SAP HANA.
- Découvrez comment sauvegarder des bases de données SAP HANA sur des machines virtuelles Azure.
- Découvrez comment sauvegarder des bases de données de réplication système SAP HANA dans des machines virtuelles Azure.
- Découvrez comment sauvegarder les instances d’instantané des bases de données SAP HANA dans des machines virtuelles Azure.