Résoudre des problèmes courants dans Azure Cosmos DB for Apache Cassandra
S’APPLIQUE À : ![]() Cassandra
Cassandra
L’API pour Cassandra dans Azure Cosmos DB est une couche de compatibilité qui assure la prise en charge du protocole filaire pour la base de données Apache Cassandra open source.
Cet article décrit les erreurs et solutions courantes pour les applications qui utilisent Azure Cosmos DB for Apache Cassandra. Si votre erreur n’est pas répertoriée et si vous rencontrez une erreur lorsque vous exécutez une opération prise en charge dans Cassandra, mais que l’erreur n’est pas présente lorsque vous utilisez Apache Cassandra en mode natif, créez une demande de support Azure.
Notes
En tant que service natif cloud entièrement managé, Azure Cosmos DB fournit des garanties de disponibilité, de débit et de cohérence pour l’API pour Cassandra. L’API pour Cassandra facilite également les opérations de plateforme sans maintenance et les mises à jour correctives sans temps d’arrêt.
Ces garanties ne sont pas possibles dans les implémentations précédentes d’Apache Cassandra, de sorte que de nombreuses opérations back end de l’API pour Cassandra diffèrent d’Apache Cassandra. Nous vous recommandons d’utiliser des paramètres et des approches spécifiques pour éviter les erreurs courantes.
NoNodeAvailableException
Cette erreur est une exception de wrapper de niveau supérieur avec un grand nombre de causes possibles et d’exceptions internes, dont la plupart peuvent être liées au client.
Causes et solutions courantes :
Délai d’inactivité d’Azure LoadBalancers : Ce problème peut également se manifester sous la forme
ClosedConnectionException. Pour résoudre le problème, définissez le paramètre Keep Alive dans le pilote (consultez Activer Keep Alive pour le pilote Java) et augmentez les paramètres Keep Alive dans votre système d’exploitation, ou ajustez le délai d’inactivité dans Azure Load Balancer.Épuisement des ressources de l’application cliente : Vérifiez que les ordinateurs clients disposent de suffisamment de ressources pour traiter la demande.
Impossible de se connecter à un hôte
Vous pouvez voir l’erreur suivante : « Impossible de se connecter à un hôte, planification d’une nouvelle tentative dans 600 000 millisecondes ».
Cette erreur peut être causée par l’épuisement de la traduction d’adresses réseau sources (SNAT) côté client. Pour écarter ce problème, suivez les étapes indiquées dans SNAT pour les connexions sortantes.
Il peut également s’agir d’un problème de délai d’inactivité où l’équilibreur de charge Azure dispose d’un délai d’inactivité de quatre minutes par défaut. Consultez Délai d’inactivité de l’équilibreur de charge. Activez Keep Alive pour le pilote Java et définissez l’intervalle keepAlive sur le système d’exploitation sur une valeur inférieure à quatre minutes.
Consultez dépanner NoHostAvailableException pour connaître différents modes de gestion de l’exception.
OverloadedException (Java)
Les requêtes sont limitées, car le nombre total d’unités de requête consommées est supérieur au nombre d’unités de requête que vous avez approvisionné sur l’espace de clés ou la table.
Envisagez de mettre à l’échelle le débit attribué à un espace de clés ou à une table à partir du Portail Azure (voir Mettre à l’échelle de manière élastique un compte Azure Cosmos DB for Apache Cassandra) ou d’implémenter une stratégie de nouvelle tentative.
Pour Java, consultez les exemples de nouvelles tentatives pour le pilote v3.x et le pilote v4.x. Consultez également Extensions Azure Cosmos DB Cassandra pour Java.
OverloadedException malgré un débit suffisant
Le système semble limiter les requêtes bien que le débit approvisionné soit suffisant pour le volume de requêtes ou le coût d’unités de requête consommé. Il existe deux causes possibles :
Opérations au niveau du schéma : L’API pour Cassandra implémente un budget de débit du système pour les opérations au niveau du schéma (CREATE TABLE, ALTER TABLE, DROP TABLE). Ce budget doit être suffisant pour les opérations de schéma dans un système de production. Toutefois, si vous avez un grand nombre d’opérations au niveau du schéma, vous risquez de dépasser cette limite.
Comme le budget n’est pas contrôlé par l’utilisateur, envisagez de réduire le nombre d’opérations de schéma que vous exécutez. Si cette action ne résout pas le problème, ou si elle n’est pas possible pour votre charge de travail, créez une demande de support Azure.
Asymétrie des données : Lorsque le débit est approvisionné dans l’API pour Cassandra, il est divisé de manière égale entre les partitions physiques, et chaque partition physique a une limite supérieure. Si une quantité importante de données est insérée ou interrogée à partir d’une partition particulière, le débit peut être limité même si vous approvisionnez une grande quantité de débit global (unités de requête) pour cette table.
Examinez votre modèle de données et assurez-vous qu’il n’y a pas d’asymétrie excessive susceptible de provoquer des partitions chaudes.
Erreurs de connectivité intermittente (Java)
La connexion s’interrompt ou expire de manière inattendue.
Les pilotes Apache Cassandra pour Java fournissent deux stratégies de reconnexion natives : ExponentialReconnectionPolicy et ConstantReconnectionPolicy. Par défaut, il s’agit de ExponentialReconnectionPolicy. Toutefois, pour Azure Cosmos DB for Apache Cassandra, nous vous recommandons ConstantReconnectionPolicy avec un délai de deux secondes.
Consultez la documentation du pilote Java 4.x, la documentation du pilote Java 3.x ou les exemples dans Configurer ReconnectionPolicy pour le pilote Java.
Erreur avec la stratégie d’équilibrage de charge
Vous avez peut-être implémenté une stratégie d’équilibrage de charge dans la version 3.x du pilote Java DataStax, avec un code similaire à ce qui suit :
cluster = Cluster.builder()
.addContactPoint(cassandraHost)
.withPort(cassandraPort)
.withCredentials(cassandraUsername, cassandraPassword)
.withPoolingOptions(new PoolingOptions() .setConnectionsPerHost(HostDistance.LOCAL, 1, 2)
.setMaxRequestsPerConnection(HostDistance.LOCAL, 32000).setMaxQueueSize(Integer.MAX_VALUE))
.withSSL(sslOptions)
.withLoadBalancingPolicy(DCAwareRoundRobinPolicy.builder().withLocalDc("West US").build())
.withQueryOptions(new QueryOptions().setConsistencyLevel(ConsistencyLevel.LOCAL_QUORUM))
.withSocketOptions(getSocketOptions())
.build();
Si la valeur de withLocalDc() ne correspond pas au centre de données du point de contact, il se peut que vous rencontriez une erreur intermittente : com.datastax.driver.core.exceptions.NoHostAvailableException: All host(s) tried for query failed (no host was tried).
Implémentez CosmosLoadBalancingPolicy. Pour que cela fonctionne, vous devrez peut-être mettre à niveau DataStax à l’aide du code suivant :
LoadBalancingPolicy loadBalancingPolicy = new CosmosLoadBalancingPolicy.Builder().withWriteDC("West US").withReadDC("West US").build();
Le décompte échoue sur une grande table
Lorsque vous exécutez select count(*) from table ou une commande similaire pour un grand nombre de lignes, le délai d’attente du serveur expire.
Si vous utilisez un client CQLSH local, modifiez les paramètres --connect-timeout ou --request-timeout. Consultez la page cqlsh: the CQL shell.
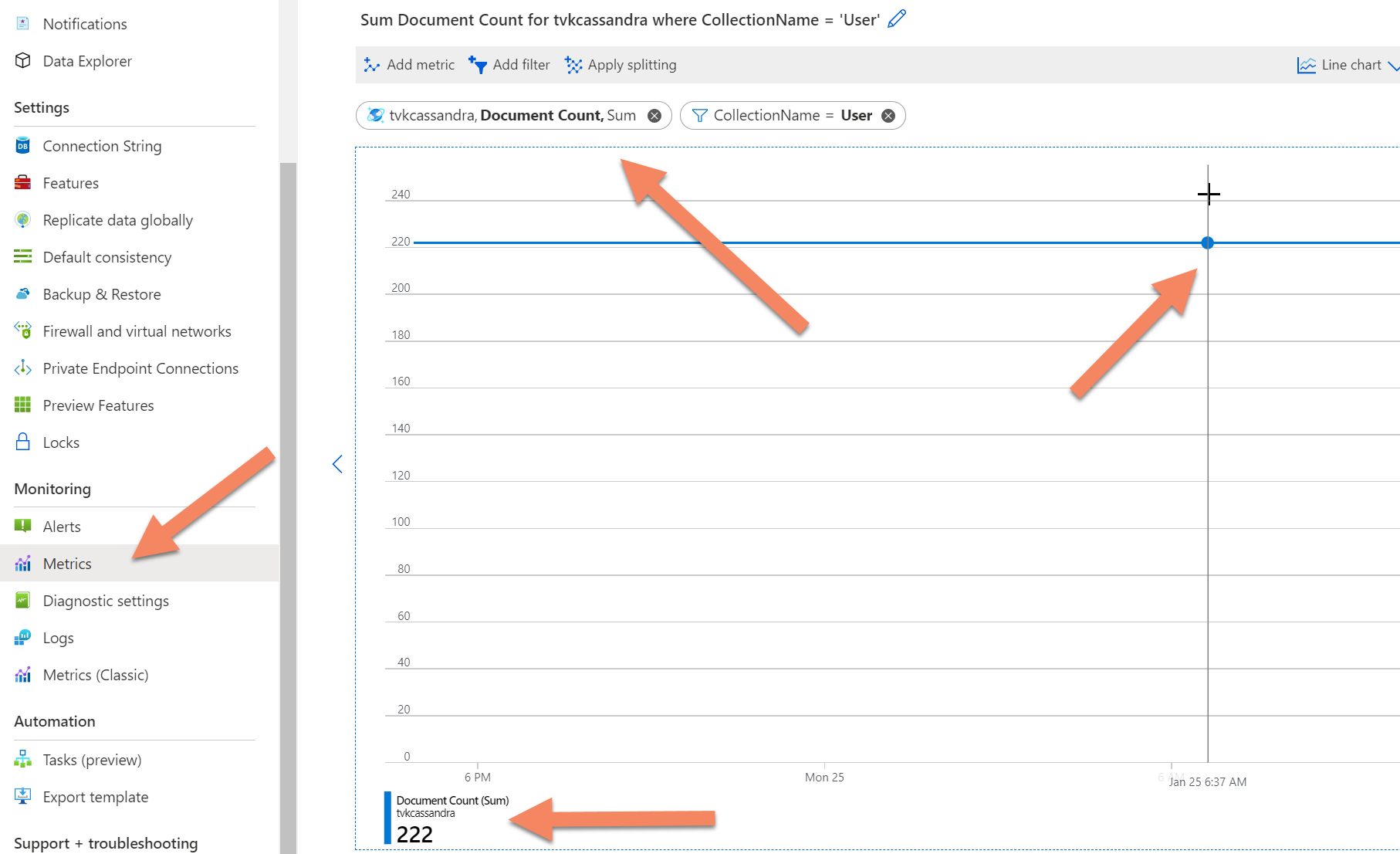
Si le décompte est toujours interrompu, vous pouvez obtenir le décompte des enregistrements à partir de la télémétrie principale d’Azure Cosmos DB en accédant à l’onglet Métriques dans le portail Azure, en sélectionnant la métrique document count, puis en ajoutant un filtre pour la base de données ou la collection (l’équivalent de la table dans Azure Cosmos DB). Vous pouvez alors pointer la souris sur le graphique résultant sur le moment pour lequel vous souhaitez connaître le décompte du nombre d’enregistrements.
Configurer ReconnectionPolicy pour le pilote Java
Version 3.x
Pour la version 3.x du pilote Java, configurez la stratégie de reconnexion lorsque vous créez un objet cluster :
import com.datastax.driver.core.policies.ConstantReconnectionPolicy;
Cluster.builder()
.withReconnectionPolicy(new ConstantReconnectionPolicy(2000))
.build();
Version 4.x
Pour la version 4.x du pilote Java, configurez la stratégie de reconnexion en remplaçant les paramètres dans le fichier reference.conf :
datastax-java-driver {
advanced {
reconnection-policy{
# The driver provides two implementations out of the box: ExponentialReconnectionPolicy and
# ConstantReconnectionPolicy. We recommend ConstantReconnectionPolicy for API for Cassandra, with
# base-delay of 2 seconds.
class = ConstantReconnectionPolicy
base-delay = 2 second
}
}
Activer Keep Alive pour le pilote Java
Version 3.x
Pour la version 3.x du pilote Java, définissez Keep Alive lorsque vous créez un objet cluster, puis assurez-vous que l’option Keep Alive est activée dans le système d’exploitation :
import java.net.SocketOptions;
SocketOptions options = new SocketOptions();
options.setKeepAlive(true);
cluster = Cluster.builder().addContactPoints(contactPoints).withPort(port)
.withCredentials(cassandraUsername, cassandraPassword)
.withSocketOptions(options)
.build();
Version 4.x
Pour la version 4.x du pilote Java, définissez Keep Alive en remplaçant les paramètres dans reference.conf, puis assurez-vous que l’option Keep Alive est activée dans le système d’exploitation :
datastax-java-driver {
advanced {
socket{
keep-alive = true
}
}
Étapes suivantes
- En savoir plus sur les fonctionnalités prises en charge dans Azure Cosmos DB for Apache Cassandra.
- Découvrez comment migrer d’Apache Cassandra natif vers Azure Cosmos DB for Apache Cassandra.