Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Azure Data Explorer est une plateforme d’analytique Big Data très performante et complètement managée, qui facilite l’analyse de grands volumes de données quasiment en temps réel. La boîte à outils d’Azure Data Explorer vous offre une solution de bout en bout pour ingérer, interroger, visualiser et gérer les données.
En analysant les données structurées, semi-structurées et non structurées sur une série chronologique et en utilisant le machine Learning, Azure Data Explorer simplifie l’extraction d’insights clés, le repérage de modèles et de tendances et la création de modèles de prévision. Azure Data Explorer utilise un modèle relationnel traditionnel, organisant les données en tables avec des schémas fortement typés. Les tables sont stockées dans des bases de données et un cluster peut gérer plusieurs bases de données. Azure Data Explorer est scalable, sécurisé, robuste et prêt pour l’entreprise. Il est utile pour l’analytique des journaux, l’analytique des séries chronologiques, l’IoT et l’analytique exploratoire à usage général.
Les fonctionnalités d’Azure Data Explorer sont étendues par d’autres services basés sur son langage de requête : Langage de requête Kusto (KQL). Ces services incluent les journaux Azure Monitor, Application Insights, Time Series Insights et Microsoft Defender pour point de terminaison.
Quand devez-vous utiliser Azure Data Explorer ?
Utilisez les questions suivantes pour déterminer si Azure Data Explorer convient à votre cas d’usage :
- Analyse interactive : l’analyse interactive fait-elle partie de la solution ? Par exemple agrégation, corrélation ou détection d’anomalies.
- Variété, Vélocité, Volume : votre schéma est-il diversifié ? Avez-vous besoin d’ingérer des quantités massives de données en quasi-temps réel ?
- Organisation des données : souhaitez-vous analyser des données brutes ? Par exemple schéma en étoile pas entièrement organisé.
- Simultanéité des requêtes : est-ce que plusieurs utilisateurs ou processus utilisent Azure Data Explorer ?
- Créer ou acheter : prévoyez-vous de personnaliser votre plateforme de données ?
Azure Data Explorer est parfait pour offrir des fonctionnalités d’analytique interactives sur des données brutes diverses à grande vélocité. Utilisez l’arbre de décision suivant pour vous aider à déterminer si Azure Data Explorer vous convient :
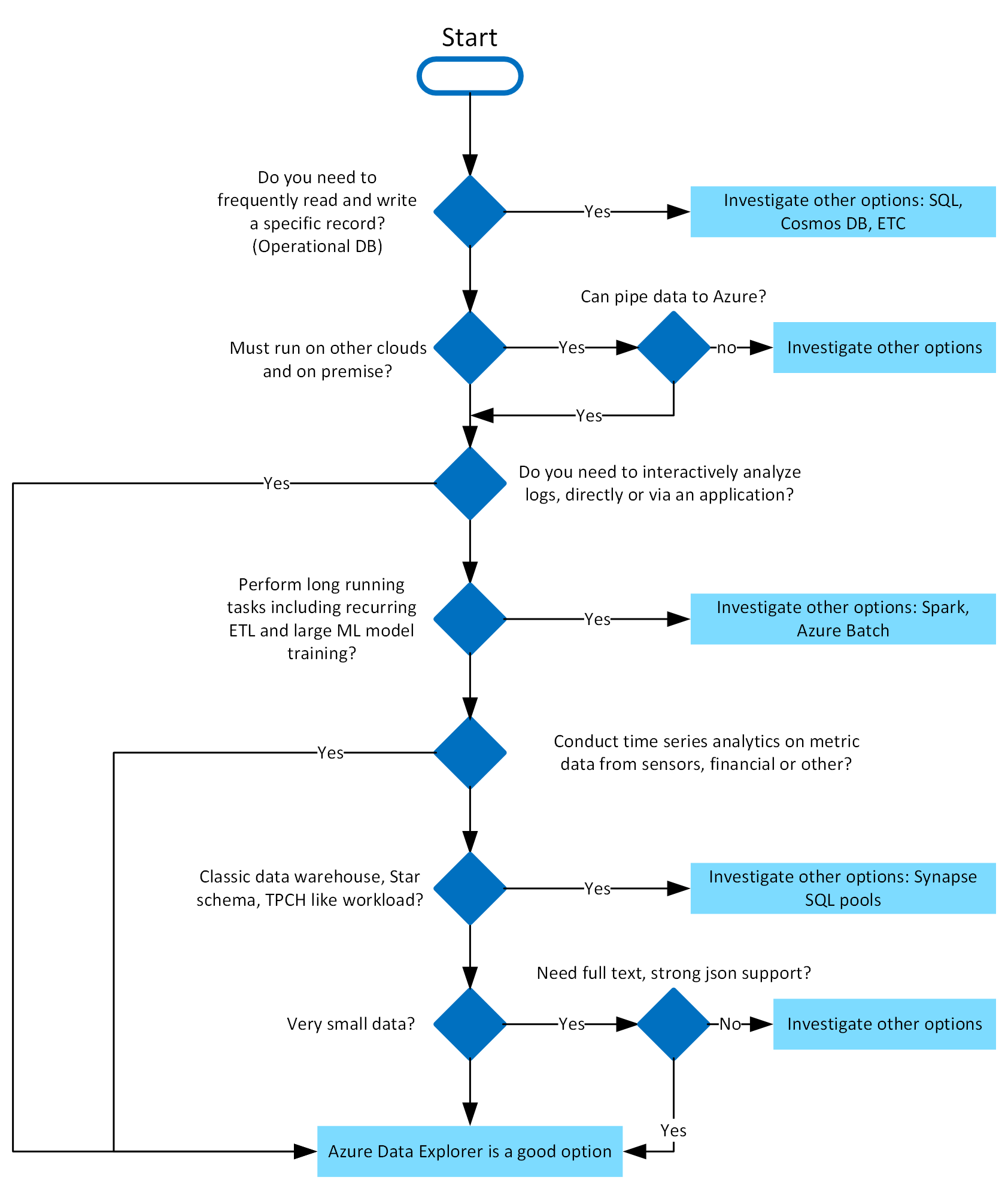
En quoi l’Explorateur de données Azure est unique ?
Vélocité, variété et volume des données
Avec Azure Data Explorer, vous pouvez ingérer des téraoctets de données en quelques minutes via l’ingestion en file d’attente ou l’ingestion de streaming. Vous pouvez interroger des pétaoctets de données, les résultats étant retournés en quelques millisecondes à quelques secondes. Azure Data Explorer fournit une vitesse élevée (millions d’événements par seconde), une faible latence (secondes) et une ingestion à échelle linéaire des données brutes. Ingérez vos données dans différents formats et structures, en provenance de différents pipelines et sources.
Langage de requête convivial
Interrogez Azure Data Explorer avec le langage de requête Kusto (KQL), langage open source inventé par l’équipe. Le langage est simple à comprendre et à apprendre et extrêmement productif. Vous pouvez utiliser des opérateurs simples et des analytiques avancées. Azure Data Explorer prend également en charge T-SQL.
Analytique avancée
Utilisez Azure Data Explorer pour l’analyse des séries chronologiques avec un grand nombre de fonctions, notamment l’ajout et le retrait de séries chronologiques, le filtrage, la régression, la détection de saisonnalité, l’analyse géospatiale, la détection d’anomalie, l’analyse et les prévisions. Les fonctions de séries chronologiques sont optimisées pour traiter des milliers de séries chronologiques en quelques secondes. La détection de modèles est simplifiée grâce aux plug-ins de cluster qui peuvent diagnostiquer les anomalies et effectuer une analyse de la cause racine. Vous pouvez également étendre les fonctionnalités d’Azure Data Explorer en incorporant du code python dans les requêtes KQL.
Assistant facile à utiliser
L’expérience obtenir des données facilite le processus d’ingestion des données, rapide et intuitif. L’interface utilisateur web d’Azure Data Explorer fournit une expérience intuitive et guidée avec laquelle vous pouvez rapidement commencer à ingérer des données, créer des tables de base de données et mapper des structures. Elle permet une ingestion unique ou continue à partir de différentes sources et dans divers formats de données. Les mappages et le schéma de tables sont suggérés automatiquement et faciles à modifier.
Visualisation polyvalente des données
La visualisation des données vous permet d’obtenir des insights importants. Azure Data Explorer offre une visualisation et un tableau de bord intégrés prêts à l’emploi, avec prise en charge de différents graphiques et visualisations. Il offre une intégration native à Power BI, des connecteurs natifs pour Grafana, Kibana et Databricks, la prise en charge ODBC pour Tableau, Sisense, Qlik et bien plus encore.
Ingestion, traitement et exportation automatiques
Azure Data Explorer prend en charge les fonctions stockées côté serveur, l’ingestion continue et l’exportation continue vers Azure Data Lake Store. Il prend également en charge les transformations de mappage au moment de l’ingestion côté serveur, les stratégies de mise à jour et les agrégats planifiés précalculés avec des vues matérialisées.
Flux de l’Explorateur de données Azure
Le diagramme suivant montre les différents aspects de l’utilisation de l’Explorateur de données Azure.
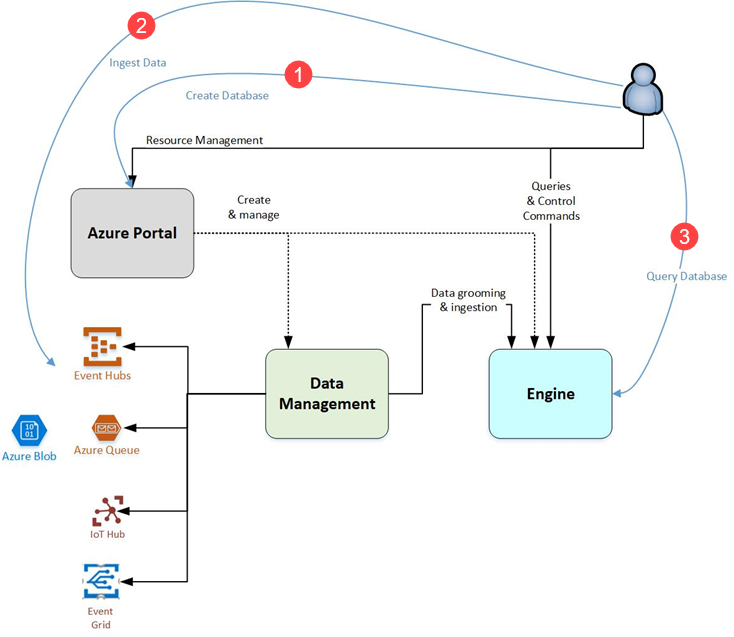
En règle générale, quand vous interagissez avec Azure Data Explorer, vous empruntez le workflow suivant :
Remarque
Vous pouvez accéder à vos ressources Azure Data Explorer dans l’IU web d’Azure Data Explorer ou avec des SDK.
Créer une base de données : Créez un cluster, puis une ou plusieurs bases de données dans ce cluster. Chaque cluster Azure Data Explorer peut contenir jusqu’à 10 000 bases de données et chaque base de données jusqu’à 10 000 tables. Les données de chaque table sont stockées dans des partitions de données, également appelées « étendues ». Toutes les données sont automatiquement indexées et partitionnées en fonction de l’heure d’ingestion. Cela signifie que vous pouvez stocker une grande quantité de données variées et en raison de la façon dont elles sont stockées, vous obtenez un accès rapide à l’interrogation. Démarrage rapide : Créer un cluster et une base de données pour l’Explorateur de données Azure
Ingérer des données : Chargez des données dans des tables de base de données pour pouvoir exécuter des requêtes dessus. Azure Data Explorer prend en charge plusieurs méthodes d’ingestion, chacune avec ses propres scénarios cibles. Parmi ces méthodes, citons des outils d’ingestion, des connecteurs et des plug-ins pour divers services, des pipelines gérés, l’ingestion programmatique à l’aide de kits SDK et l’accès direct à l’ingestion. Prise en main de l’expérience obtenir des données.
Base de données de requête : Azure Data Explorer utilise le langage de requête Kusto, qui est un langage de requête expressif, intuitif et très productif. Il permet de passer en douceur de simples lignes uniques à des scripts de traitement de données complexes, et d’interroger des données structurées, semi-structurées et non structurées (recherche textuelle). Il existe une grande variété d’opérateurs et de fonctions de langage de requête (agrégation, filtrage, fonctions de série chronologique, fonctions géospatiales, jointures, unions, etc.) dans le langage. KQL prend en charge les requêtes inter-clusters et inter-bases de données et est riche en fonctionnalités du point de vue de l’analyse (JSON, XML, etc.). Le langage prend également en charge l’analytique avancée en mode natif.
Utilisez l’application web pour exécuter, consulter et partager des requêtes et des résultats. Vous pouvez également envoyer des requêtes par programmation (à l’aide d’un kit SDK) ou à un point de terminaison de l’API REST. Si vous êtes familiarisé avec SQL, commencez avec la aide-mémoire SQL vers Kusto et démarrage rapide : Interroger des données dans l’interface utilisateur web d’Azure Data Explorer.
Visualiser les résultats : Utilisez des affichages visuels différents de vos données dans les tableaux de bord Azure Data Explorer natifs. Vous pouvez également afficher vos résultats en utilisant des connecteurs reliés à certains des principaux services de visualisation, tels que Power BI et Grafana. Azure Data Explorer prend également en charge les connecteurs ODBC et JDBC pour les outils tels que Tableau et Sisense.
Comment fournir des commentaires
Nous aimerions beaucoup avoir votre avis sur Azure Data Explorer et le langage de requête Kusto :
- Poser des questions
- Partager des suggestions produit dans User Voice
Contenu connexe
- Démarrage rapide : Créer un cluster et une base de données pour l’Explorateur de données Azure
- Démarrage rapide : Ingérer des données à partir d’un hub d’événements dans Azure Data Explorer
- Démarrage rapide : Interroger des données dans l’Explorateur de données Azure
- Rechercher un partenaire Azure Data Explorer