Copier en bloc à partir d’une base de données vers Azure Data Explorer à l’aide du modèle Azure Data Factory
Azure Data Explorer est un service d’analyse de données rapide et complètement managé. Il effectue une analyse en temps réel de grands volumes de données diffusées en continu à partir de nombreuses sources, telles que des applications, des sites web et des appareils IoT.
Pour copier des données à partir d’une base de données dans Oracle Server, Netezza, Teradata ou SQL Server vers Azure Data Explorer, vous devez charger de grandes quantités de données à partir de plusieurs tables. Généralement, les données doivent être partitionnées dans chaque table pour que vous puissiez charger des lignes avec plusieurs threads en parallèle à partir d’une seule table. Cet article décrit un modèle à utiliser dans ces scénarios.
Les modèles Azure Data Factory sont des pipelines Data Factory prédéfinis. Ces modèles peuvent vous aider à commencer rapidement à utiliser Data Factory et à réduire le temps de développement de projets d’intégration de données.
Vous créez le modèle Copie en bloc à partir d’une base de données vers Azure Data Explorer à l’aide des activités Lookup et ForEach. Pour accélérer la copie de données, vous pouvez utiliser le modèle pour créer un grand nombre de pipelines par base de données ou par table.
Important
Veillez à utiliser l’outil approprié pour la quantité de données que vous souhaitez copier.
- Utilisez le modèle Copie en bloc à partir d’une base de données vers Azure Data Explorer pour copier de grandes quantités de données à partir de bases de données comme SQL Server et Google BigQuery vers Azure Data Explorer.
- Servez-vous de l’outil de copie de données Data Factory pour copier quelques tables contenant des quantités de données faibles ou modérées dans Azure Data Explorer.
Prérequis
- Un abonnement Azure. Créez un compte Azure gratuit.
- Un cluster et une base de données Azure Data Explorer. Créez un cluster et une base de données.
- Une fabrique de données. Créez une fabrique de données.
- Une source de données.
Créer ControlTableDataset
ControlTableDataset indique les données qui seront copiées de la source vers la destination dans le pipeline. Le nombre de lignes indique le nombre total de pipelines nécessaires pour copier les données. Vous devez définir ControlTableDataset dans le cadre de la base de données source.
Un exemple du format de table source SQL Server est illustré dans le code suivant :
CREATE TABLE control_table (
PartitionId int,
SourceQuery varchar(255),
ADXTableName varchar(255)
);
Les éléments de code sont décrits dans le tableau suivant :
| Propriété | Description | Exemple |
|---|---|---|
| PartitionId | Ordre de copie | 1 |
| SourceQuery | Requête indiquant les données qui seront copiées pendant l’exécution du pipeline | select * from table where lastmodifiedtime LastModifytime >= ''2015-01-01 00:00:00''> |
| ADXTableName | Nom de la table de destination | MyAdxTable |
Si votre ControlTableDataset est dans un format différent, créez un ControlTableDataset comparable pour votre format.
Utiliser le modèle Copie en bloc à partir d’une base de données vers Azure Data Explorer
Dans le volet C’est parti, sélectionnez Créer un pipeline à partir d’un modèle pour ouvrir le volet Galerie de modèles.
Sélectionnez le modèle Copie en bloc à partir d’une base de données vers Azure Data Explorer.
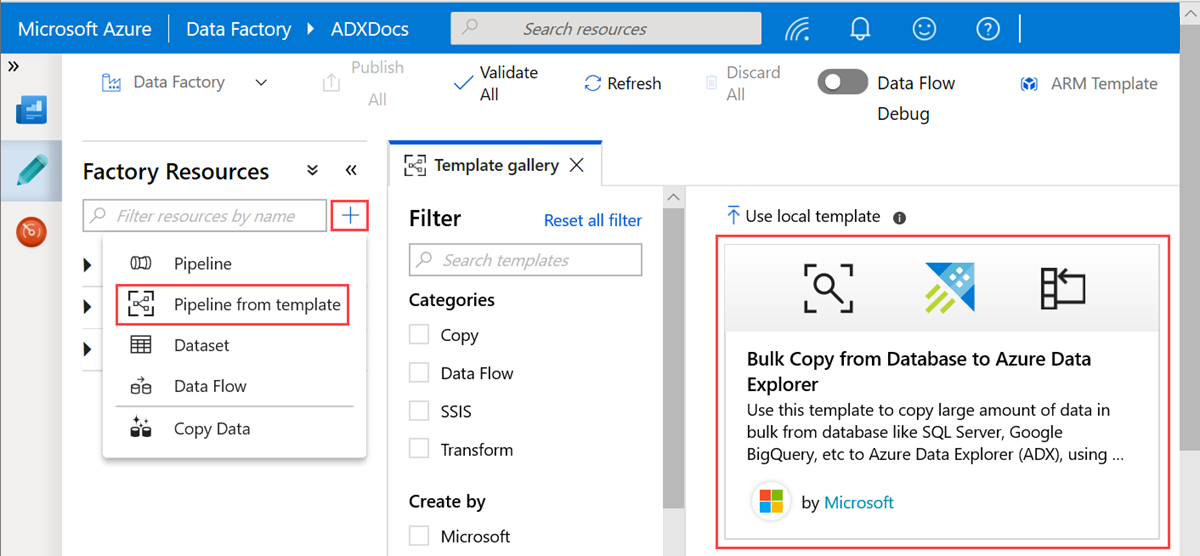
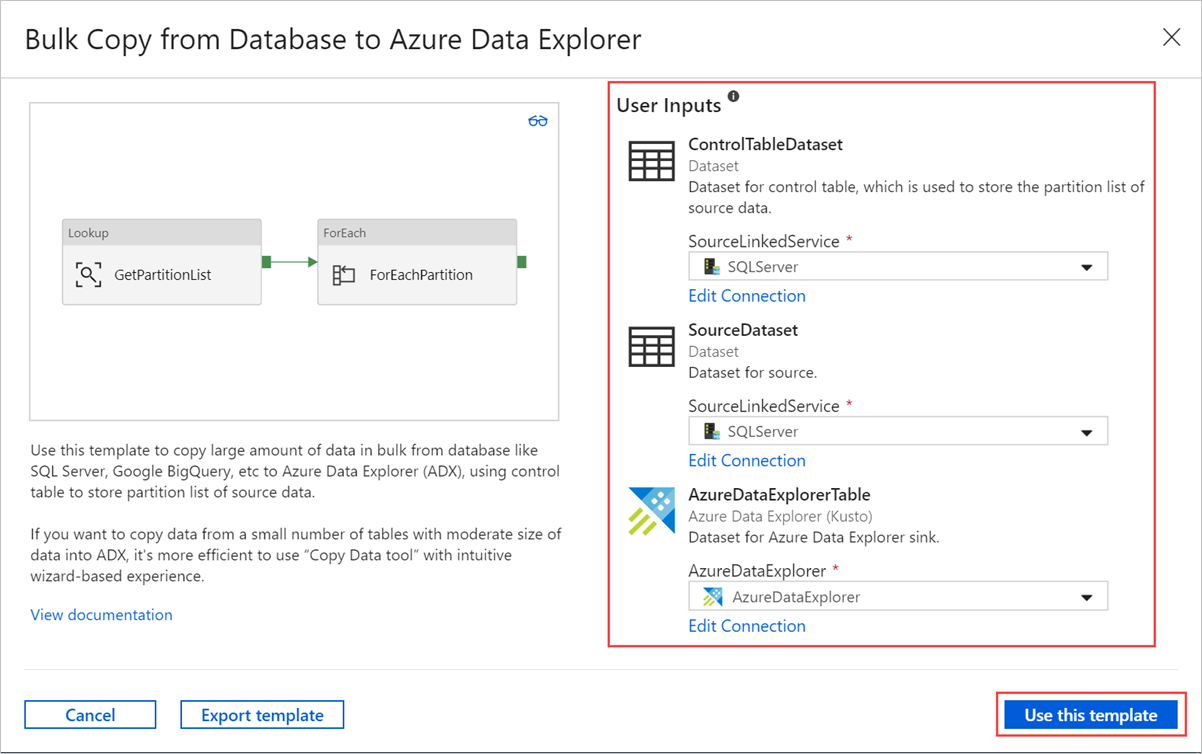
Dans le volet Copie en bloc à partir d’une base de données vers Azure Data Explorer, sous Entrées d’utilisateur, spécifiez vos jeux de données en procédant comme suit :
a. Dans la liste déroulante ControlTableDataset, sélectionnez le service lié à la table de contrôle qui indique quelles données sont copiées de la source vers la destination et où elles seront placées dans celle-ci.
b. Dans la liste déroulante SourceDataset, sélectionnez le service lié à la base de données source.
c. Dans la liste déroulante AzureDataExplorerTable, sélectionnez la table Azure Data Explorer. Si le jeu de données n’existe pas, créez le service lié Azure Data Explorer pour ajouter le jeu de données.
d. Cliquez sur Utiliser ce modèle.
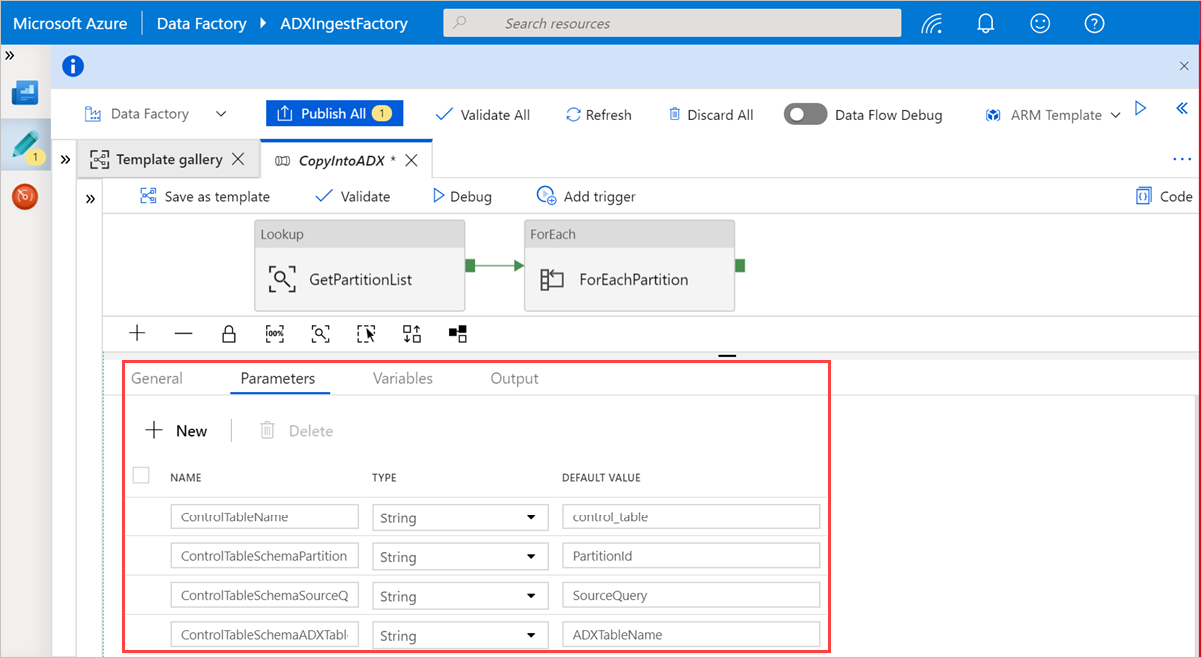
Sélectionnez une zone dans le canevas, en dehors des activités, pour accéder au pipeline de modèle. Sélectionnez l’onglet Paramètres pour entrer les paramètres de la table, à savoir le Nom de la table de contrôle et la Valeur par défaut (noms des colonnes).
Sous Rechercher, sélectionnez GetPartitionList pour afficher les paramètres par défaut. La requête est automatiquement créée.
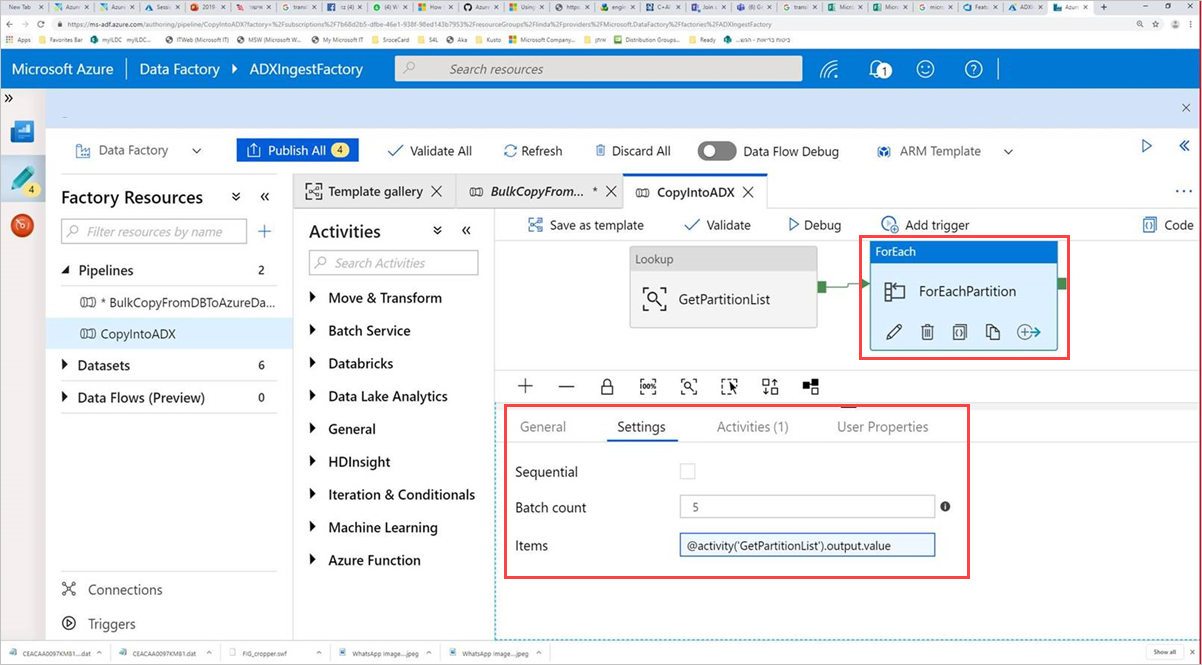
Sélectionnez l’activité Command, ForEachPartition, sélectionnez l’onglet Paramètres, puis procédez comme suit :
a. Dans la zone Nombre de lots, entrez un nombre compris entre 1 et 50. Cette sélection détermine le nombre de pipelines qui s’exécutent en parallèle jusqu’à ce que le nombre de lignes de ControlTableDataset soit atteint.
b. Pour vous assurer que les lots du pipeline s’exécutent en parallèle, n’activez pas la case à cocher Séquentiel.
Conseil
La meilleure pratique consiste à exécuter un grand nombre de pipelines en parallèle afin d’accélérer la copie de vos données. Pour accroître l’efficacité, partitionnez les données de la table source et allouez une partition par pipeline, en fonction de la date et de la table.
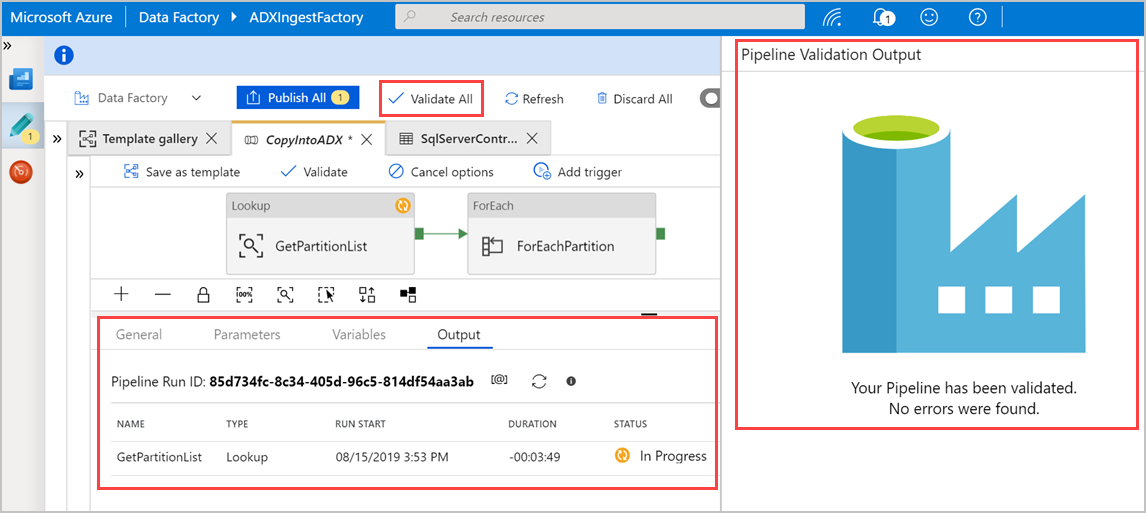
Sélectionnez Valider tout pour valider le pipeline Azure Data Factory, puis affichez le résultat dans le volet de sortie de la validation du pipeline.
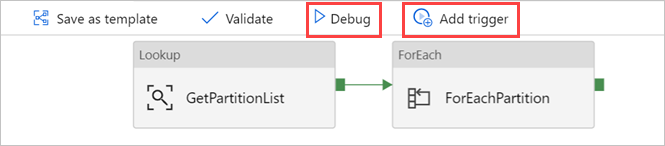
Si nécessaire, sélectionnez Déboguer, puis Ajouter un déclencheur pour exécuter le pipeline.
Vous pouvez maintenant utiliser le modèle pour copier efficacement de grandes quantités de données à partir de vos bases de données et tables.
Contenu connexe
- Découvrez le connecteur Azure Data Explorer pour Azure Data Factory.
- Modifiez des services liés, des jeux de données et des pipelines dans l’interface utilisateur Data Factory.
- Interroger des données dans l’interface utilisateur web Azure Data Explorer.