Copier des données dans Azure Data Explorer à l’aide d’Azure Data Factory
Important
Ce connecteur peut être utilisé dans Real-Time Intelligence dans Microsoft Fabric. Utilisez les instructions contenues dans cet article, à l’exception des points suivants :
- Si nécessaire, créez des bases de données en suivant les instructions fournies dans Créer une base de données KQL.
- Si nécessaire, créez des tables en suivant les instructions fournies dans Créer une table vide.
- Obtenez les URI de requête ou d’ingestion en suivant les instructions fournies dans Copier l’URI.
- Exécutez des requêtes dans un ensemble de requêtes KQL.
Azure Data Explorer est un service d’analyse de données rapide et complètement managé. Il effectue une analyse en temps réel de grands volumes de données diffusées en continu à partir de nombreuses sources, telles que des applications, des sites web et des appareils IoT. Avez Azure Data Explorer, vous pouvez explorer les données de façon itérative et identifier des tendances et anomalies afin d’améliorer les produits et les expériences client, surveiller des appareils et optimiser les opérations. Cela vous permet de parcourir les nouvelles questions et de recevoir des réponses en quelques minutes.
Azure Data Factory est un service informatique d’intégration de données informatique intégralement managé. Vous pouvez l’utiliser pour remplir votre base de données Azure Data Explorer avec les données de votre système existant. Cela peut vous permettre de gagner du temps lorsque vous créez des solutions d’analyse.
Lorsque vous chargez des données dans Azure Data Explorer, Data Factory offre les avantages suivants :
- Configuration facile : accès à un Assistant intuitif en cinq étapes ne nécessitant pas de script.
- Prise en charge étendue du magasin de données : bénéficiez d’une prise en charge intégrée d’un ensemble complet de magasins de données locaux et informatiques. Pour une liste détaillée, consultez le tableau Banques de données prises en charge.
- Sécurité et conformité : les données sont transférées via HTTPS ou ExpressRoute. La présence globale du service garantit que vos données ne quittent jamais les limites géographiques.
- Hautes performances : la vitesse de chargement des données est de 1 Go par seconde (Go/s) dans Azure Data Explorer. Pour plus d’informations, consultez Performances de l’activité de copie.
Dans cet article, vous utilisez l’outil de copie de données Data Factory pour charger les données d’Amazon Simple Storage Service (S3) dans Azure Data Explorer. Vous pouvez procéder de façon similaire pour copier des données à partir d’autres banques de données, par exemple :
- stockage d’objets blob Azure
- Azure SQL Database
- Azure SQL Data Warehouse
- Google BigQuery
- Oracle
- Système de fichiers
Prérequis
- Un abonnement Azure. Créez un compte Azure gratuit.
- Un cluster et une base de données Azure Data Explorer. Créez un cluster et une base de données.
- Une source de données.
Créer une fabrique de données
Connectez-vous au portail Azure.
Dans le volet de gauche, sélectionnez Créer une ressource>Analytics>Data Factory.

Dans le volet Nouvelle fabrique de données, fournissez les valeurs des champs dans le tableau suivant :
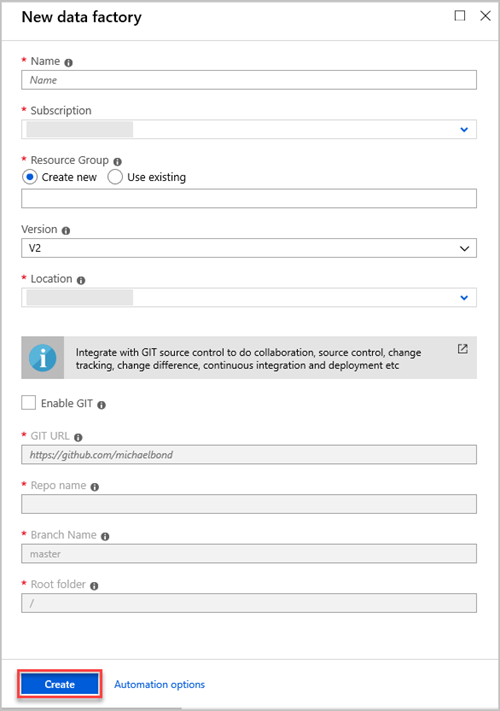
Setting Valeur à entrer Nom Dans la zone, entrez un nom global unique pour votre fabrique de données. Si l’erreur Le nom de fabrique de données « LoadADXDemo » n’est pas disponible apparaît, saisissez un autre nom pour la fabrique de données. Pour savoir comment nommer les artefacts Data Factory, consultez Data Factory - Règles d’affectation des noms. Abonnement Dans la liste déroulante, sélectionnez l’abonnement Azure dans lequel créer la fabrique de données. Groupe de ressources Sélectionnez Créer, puis entrez le nom d’un nouveau groupe de ressources. Si vous disposez déjà d’un groupe de ressources, sélectionnez Utiliser l’existant. Version Dans la liste déroulante, sélectionnez V2. Lieu Dans la liste déroulante, sélectionnez l’emplacement de la fabrique de données. Seuls les emplacements pris en charge sont affichés dans la liste. Les magasins de données utilisés par la fabrique de données peuvent résider dans d’autres emplacements ou régions. Sélectionnez Créer.
Pour superviser le processus de création, sélectionnez Notifications dans la barre d’outils. Une fois que vous avez créé la fabrique de données, sélectionnez-la.
Le volet Fabrique de données s’ouvre.
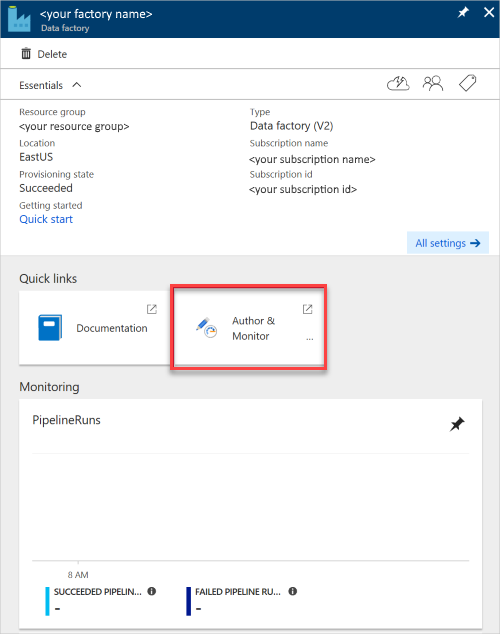
Pour ouvrir l’application dans un onglet séparé, sélectionnez la vignette Créer et surveiller.
Charger des données dans Azure Data Explorer
Vous pouvez charger des données à partir de nombreux types de magasins de données dans Azure Data Explorer. Cet article explique comment charger des données à partir d’Amazon S3.
Vous pouvez charger vos données de l’une des manières suivantes :
- Dans l’interface utilisateur d’Azure Data Factory, dans le volet gauche, sélectionnez l’icône Auteur. Cela est illustré dans la section « Créer une fabrique de données » de Créer une fabrique de données à l’aide de l’interface utilisateur d’Azure Data Factory.
- Dans l’outil Copier des données d’Azure Data Factory, comme l’indique Utiliser l’outil Copier des données pour copier des données.
Copier des données à partir d’Amazon S3 (source)
Dans la page Prise en main, sélectionnez Copier des données pour ouvrir l’outil Copier des données.
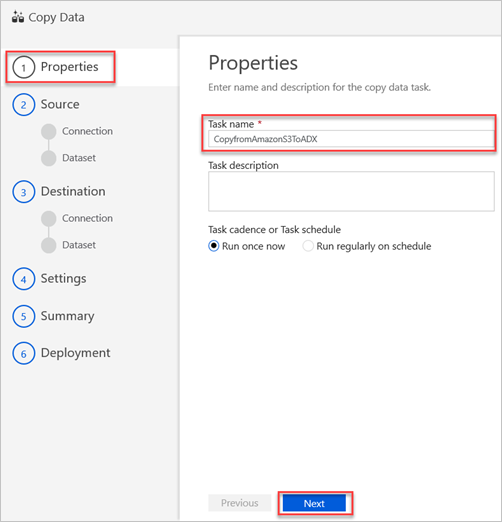
Dans la zone Nom de la tâche du volet Propriétés, entrez un nom, puis sélectionnez Suivant.
Dans le volet Banque de données sources, sélectionnez Créer une connexion.
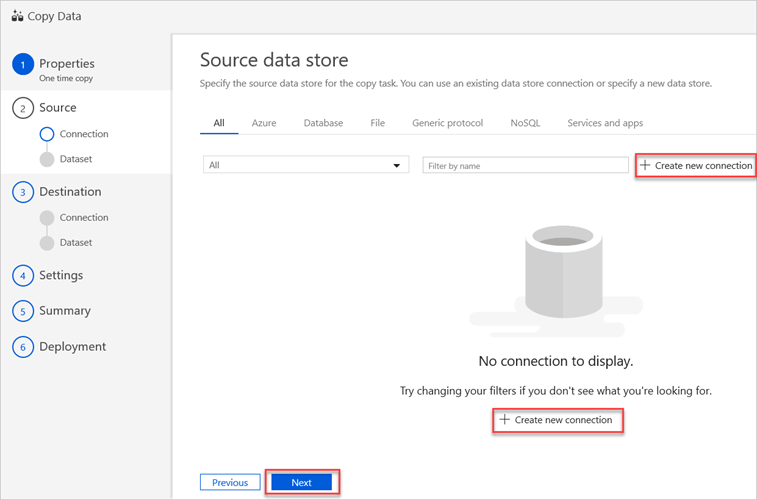
Sélectionnez Amazon S3, puis Continuer.
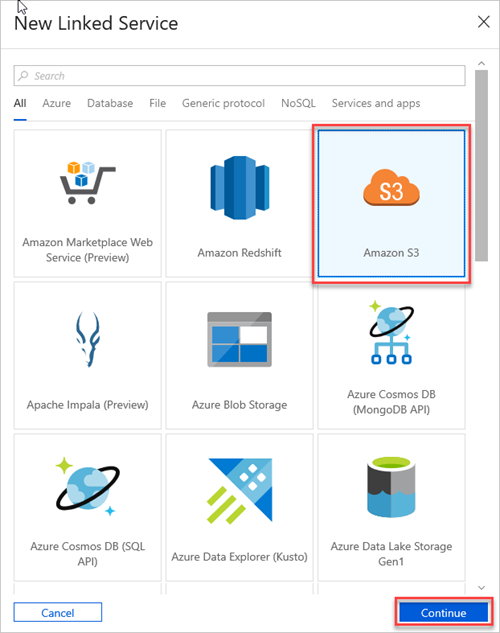
Dans le volet Nouveau service lié (Amazon S3), procédez comme suit :
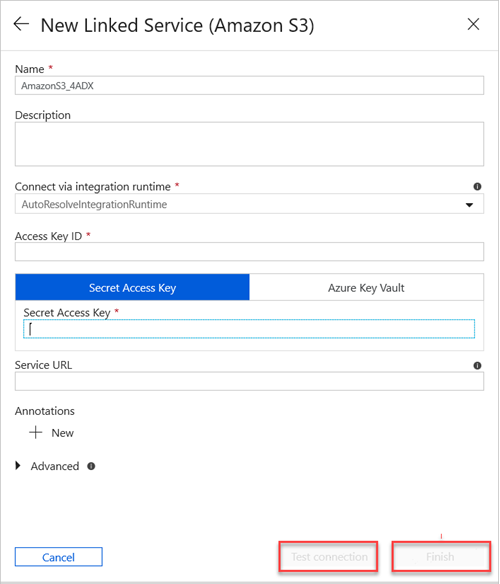
a. Dans la zone Nom, entrez le nom de votre nouveau service lié.
b. Dans la liste déroulante Se connecter via le runtime d'intégration, sélectionnez la valeur.
c. Dans la zone ID de clé d’accès, entrez la valeur appropriée.
Remarque
Dans Amazon S3, pour localiser votre clé d’accès, sélectionnez votre nom d’utilisateur Amazon dans la barre de navigation, puis sélectionnez My Security Credentials (Mes informations d’identification de sécurité).
d. Dans la zone Clé d’accès secrète, entrez une valeur.
e. Pour tester la connexion au service lié que vous avez créée, sélectionnez Test Connection (Tester la connexion).
f. Sélectionnez Terminer.
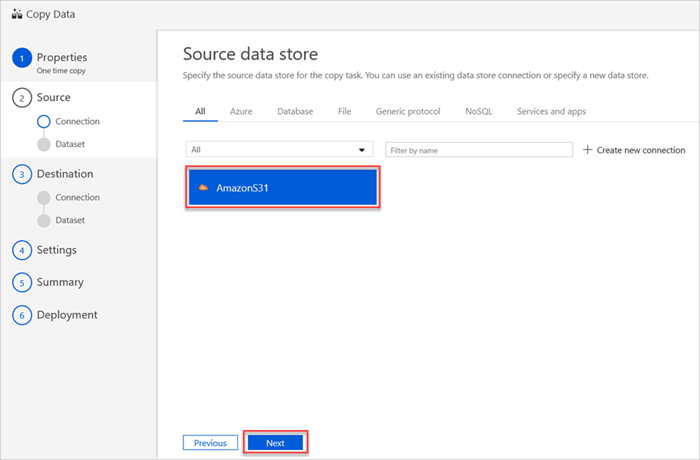
Votre nouvelle connexion AmazonS31 s’affiche dans le volet Magasin de données sources.
Cliquez sur Suivant.
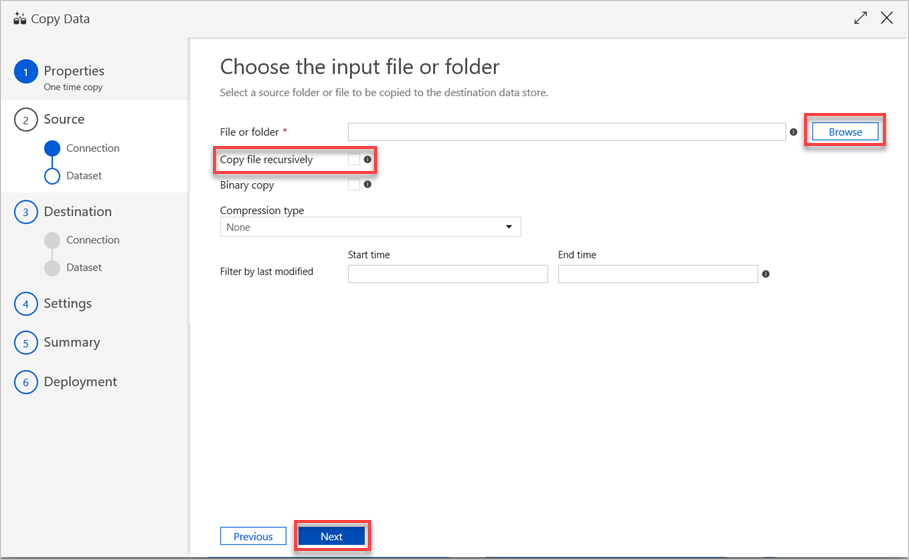
Dans le volet Choisir le fichier ou le dossier d’entrée, procédez comme suit :
a. Accédez au fichier ou dossier que vous souhaitez copier, puis sélectionnez-le.
b. Sélectionnez le comportement de copie souhaité. Assurez-vous que la case à cocher Copie binaire est désactivée.
c. Cliquez sur Suivant.
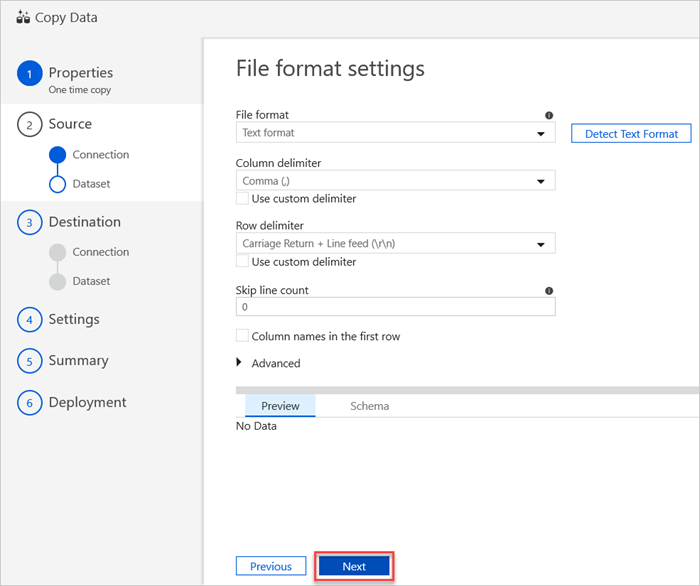
Dans le volet des paramètres de formats de fichier, sélectionnez les paramètres appropriés pour votre fichier. Sélectionnez sur Suivant.
Copier des données dans Azure Data Explorer (destination)
Le nouveau service lié Azure Data Explorer est créé pour copier les données dans la table de destination Azure Data Explorer (récepteur) spécifiée dans cette section.
Remarque
Utilisez l’activité de commande Azure Data Factory pour exécuter des commandes de gestion d’Azure Data Explorer et utilisez l’une des commandes d’ingestion à partir d’une requête, par exemple .set-or-replace.
Créer le service lié Azure Data Explorer
Pour créer le service lié Azure Data Explorer, procédez comme suit :
Pour utiliser une connexion au magasin de données existant ou spécifier un nouveau magasin de données, dans le volet Banques de données de destination, sélectionnez Créer une connexion.
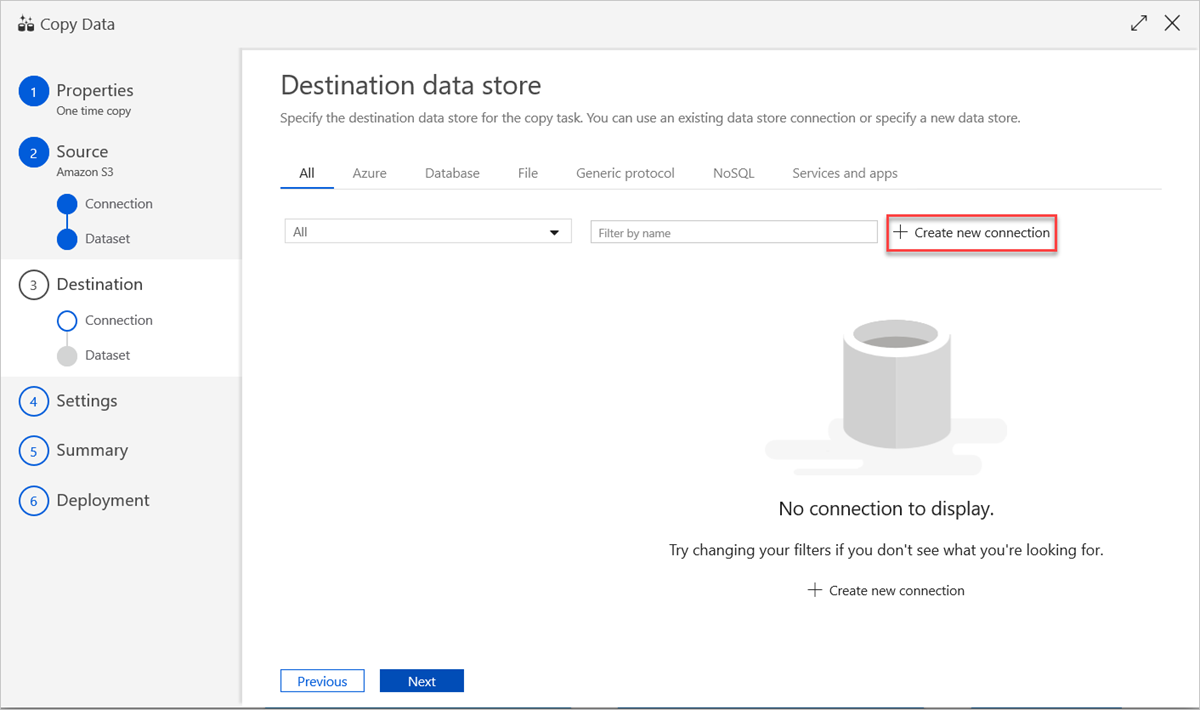
Dans le volet Nouveau service lié, sélectionnez Azure Data Explorer, puis sélectionnez Continuer.

Dans le volet Nouveau service lié (Azure Data Explorer), procédez comme suit :
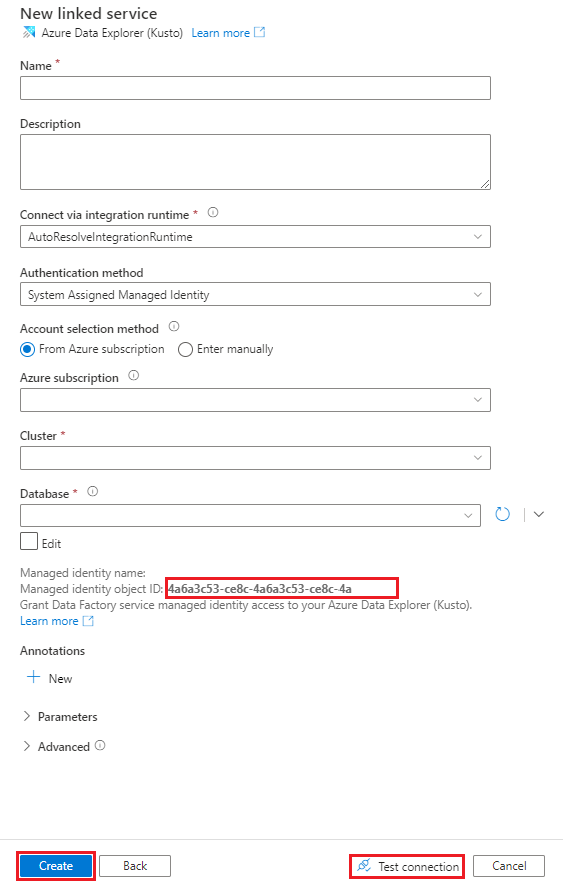
Dans la zone Nom, entrez le nom du service lié Azure Data Explorer.
Sous Méthode d’authentification, choisissez Identité managée affectée par le système ou Principal de service.
Pour vous authentifier à l’aide d’une identité managée, accordez-lui l’accès à la base de données à l’aide du Nom de l’identité managée ou de l’ID d’objet de l’identité managée.
Pour vous authentifier à l’aide d’un principal de service, procédez comme suit :
- Dans la zone Locataire, entrez le nom du locataire.
- Dans la zone ID du principal de service, entrez l’ID du principal de service.
- Sélectionnez Clé du principal du service, puis, dans la zone Clé du principal du service, entrez la valeur de la clé.
Remarque
- Le principal du service est utilisé par Azure Data Factory pour accéder au service Azure Data Explorer. Pour créer un principal de service, accédez à créer un principal de service Microsoft Entra.
- Pour attribuer des autorisations à une identité managée ou à un principal de service, consultez Gestion des autorisations.
- N’utilisez pas la méthode Azure Key Vault ni l’identité managée affectée par l’utilisateur.
Sous Méthode de sélection du compte, effectuez une des actions suivantes :
Sélectionnez À partir d’un abonnement Azure, puis, dans les listes déroulantes, sélectionnez votre Abonnement Azure et votre Cluster.
Remarque
- Le contrôle de liste déroulante Cluster répertorie uniquement les clusters associés à votre abonnement.
- Votre cluster doit disposer de la référence SKU appropriée pour des performances optimales.
Sélectionnez Entrer manuellement, puis entrez votre Point de terminaison.
Dans la liste déroulante Base de données, sélectionnez le nom de votre base de données. Vous pouvez également activer la case à cocher Modifier, puis entrer le nom de la base de données.
Pour tester la connexion au service lié que vous avez créée, sélectionnez Test Connection (Tester la connexion). Si vous pouvez vous connecter à votre service lié, le volet affiche une coche verte et le message Connexion établie.
Sélectionnez Créer pour effectuer la création du service lié.
Configurer la connexion de données Azure Data Explorer
Une fois que vous avez créé la connexion au service lié, le volet Banque de données de destination s’ouvre, et cette connexion peut être utilisée. Pour configurer la connexion, procédez comme suit :
Cliquez sur Suivant.
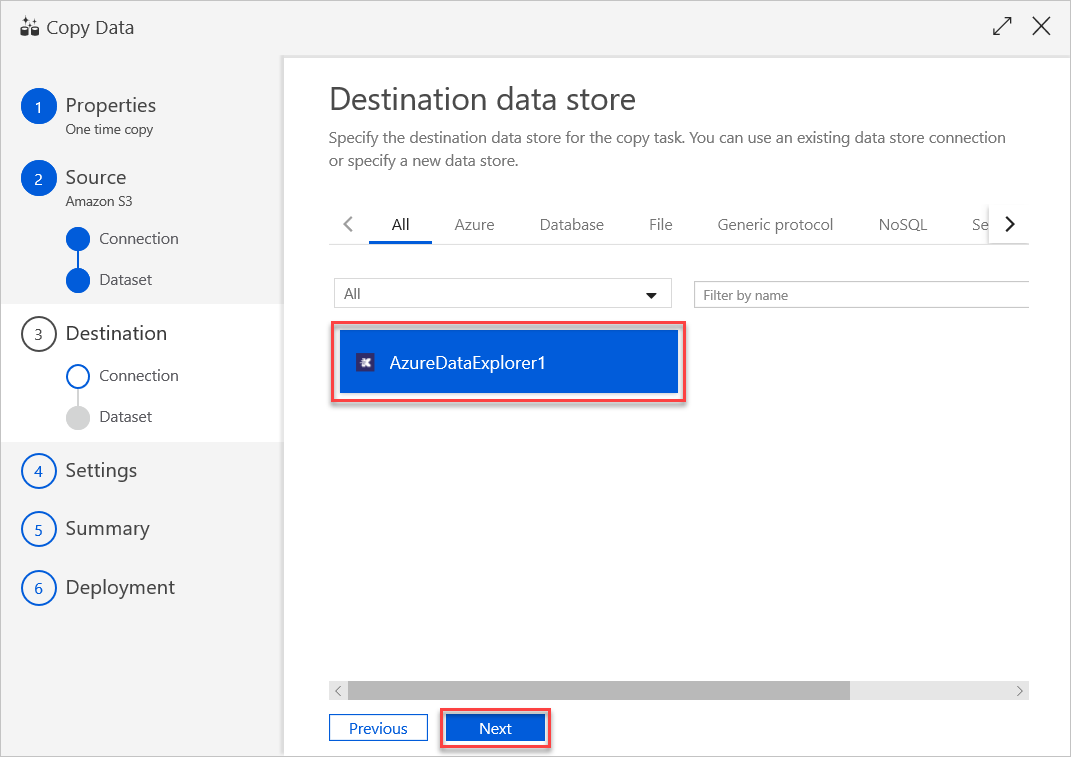
Dans le volet Table mapping (Mappage de table), définissez le nom de la table de destination, puis sélectionnez Next (Suivant).
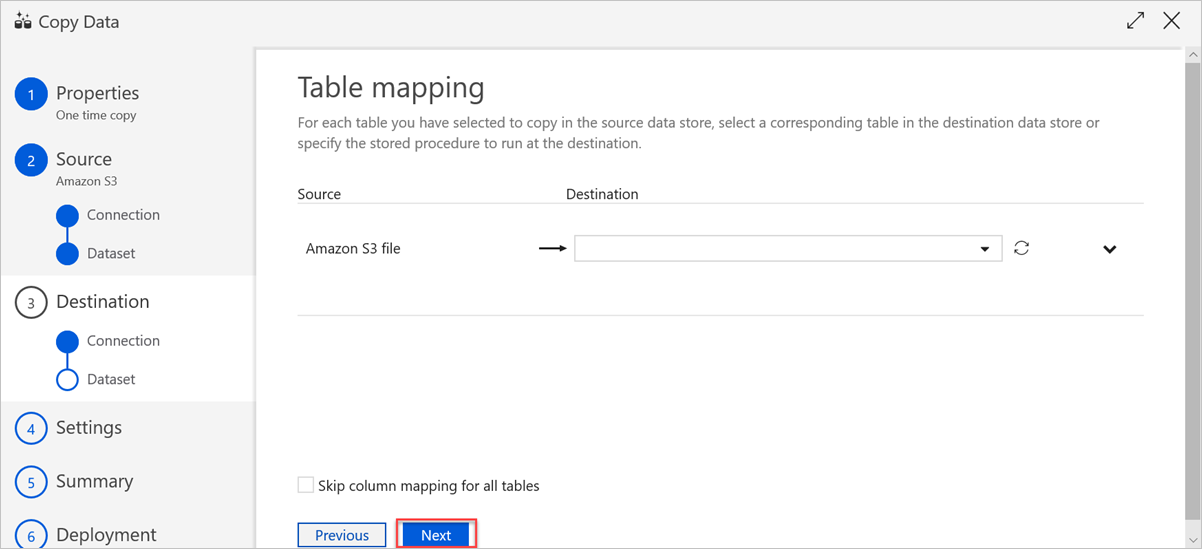
Dans le volet Mappage de colonnes, les mappages suivants ont lieu :
a. Le premier mappage est effectué par Azure Data Factory conformément au mappage de schéma Azure Data Factory . Effectuez les actions suivantes :
Définissez les Column mappings (Mappages de colonnes) pour la table de destination Azure Data Factory. Le mappage par défaut est affiché de la source à la table de destination Azure Data Factory.
Annulez la sélection des colonnes dont vous n’avez pas besoin pour définir votre mappage de colonnes.
b. Le deuxième mappage se produit lorsque ces données tabulaires sont ingérées dans Azure Data Explorer. Le mappage est effectué conformément aux CSV mapping rules (Règles de mappage CSV). Même si les données sources ne sont pas au format CSV, Azure Data Factory les convertit dans un format tabulaire. Par conséquent, le mappage CSV est le seul mappage pertinent à ce niveau. Effectuez les actions suivantes :
(Facultatif) Sous Azure Data Explorer (Kusto) sink properties (Propriétés du récepteur Azure Data Explorer (Kusto)), ajoutez le Ingestion mapping name (Nom de mappage d’ingestion) pertinent afin que ce mappage de colonnes puisse être utilisé.
Si le Ingestion mapping name (Nom de mappage d’ingestion) n’est pas spécifié, l’ordre de mappage par nom défini dans la section Column mappings (Mappages de colonnes) est appliqué. Si le mappage par nom échoue, Azure Data Explorer tente d’ingérer les données dans un ordre par position de colonne (c’est-à-dire, mappe par position par défaut).
Cliquez sur Suivant.
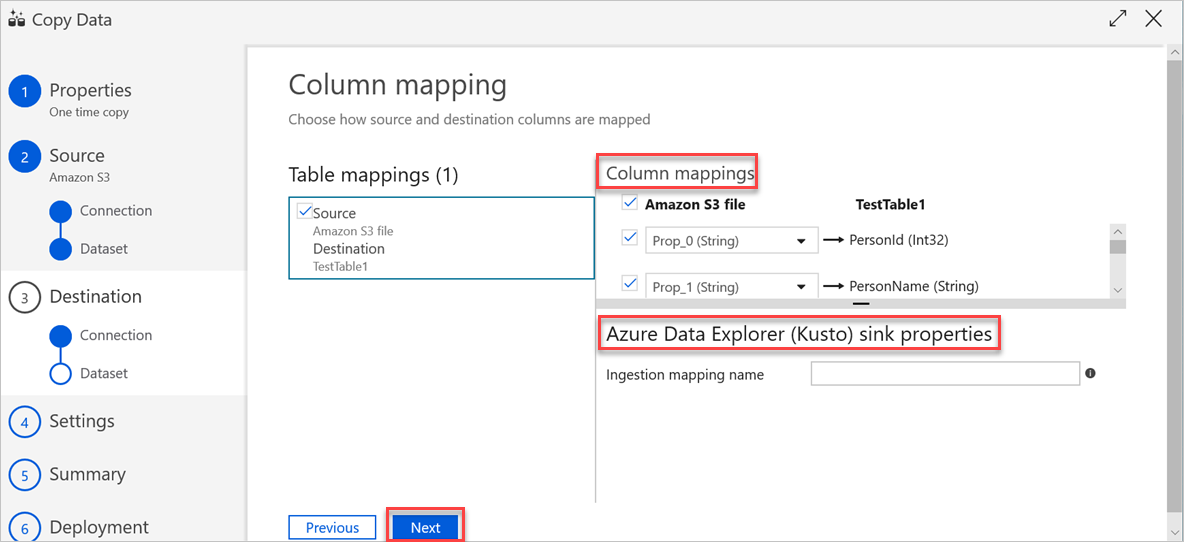
Dans le volet Paramètres, procédez comme suit :
a. Sous les Paramètres de tolérance de panne, entrez les paramètres appropriés.
b. Sous Paramètres de performance, Activer le mode de préproduction ne s’applique pas, et Paramètres avancés inclut des considérations relatives aux coûts. Si vous n’avez pas d’exigences spécifiques, ne modifiez pas ces paramètres.
c. Cliquez sur Suivant.
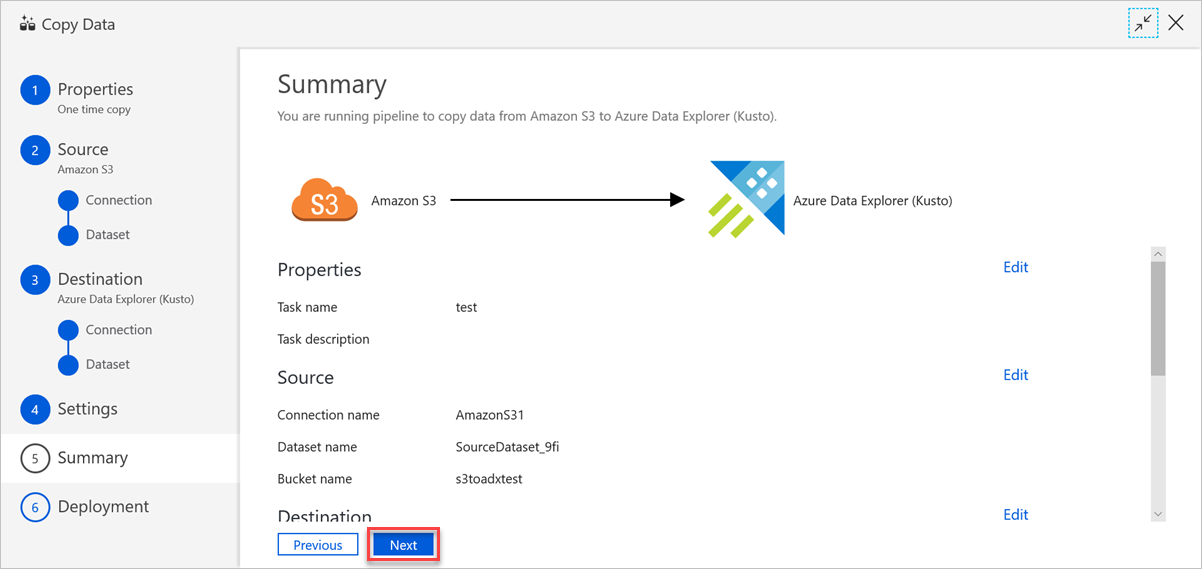
Dans le volet Résumé, vérifiez les paramètres, puis sélectionnez Suivant.
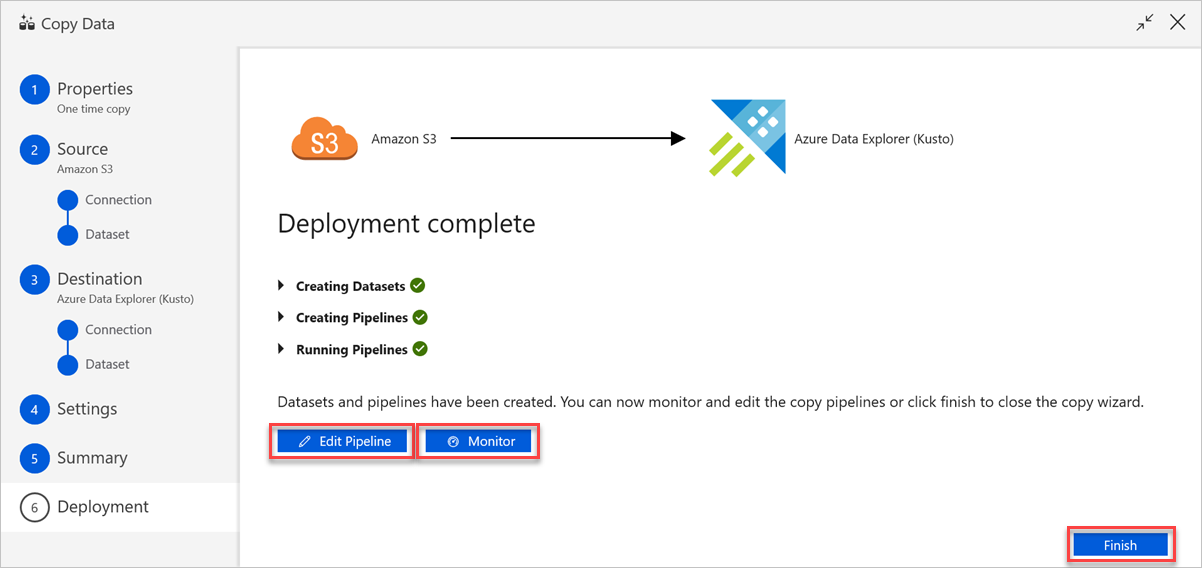
Dans le volet Déploiement terminé, procédez comme suit :
a. Pour basculer vers l’onglet Moniteur et voir l’état du pipeline (progression, erreurs et flux de données), sélectionnez Monitor (Moniteur).
b. Pour modifier les services liés, les jeux de données et les pipelines, sélectionnez Edit Pipeline (Modifier le pipeline).
c. Sélectionnez Finish (Terminer) pour achever la tâche de copie de données.
Contenu connexe
- Découvrez le connecteur Azure Data Explorer pour Azure Data Factory.
- Modifiez des services liés, des jeux de données et des pipelines dans l’interface utilisateur Data Factory.
- Interroger des données dans l’interface utilisateur web Azure Data Explorer.