Copier des données depuis/vers Azure Data Explorer en utilisant Azure Data Factory ou Synapse Analytics
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article décrit comment utiliser l’activité de copie dans Azure Data Factory et Synapse Analytics pour copier des données vers ou depuis Azure Data Explorer. Il s’appuie sur l’article Vue d’ensemble de l’activité de copie.
Conseil
Pour en savoir plus sur l’intégration du service avec Azure Data Explorer, consultez l’article Intégrer Azure Data Explorer.
Fonctionnalités prises en charge
Ce connecteur Azure Data Explorer est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/récepteur) | ① ② |
| Mappage de flux de données (source/récepteur) | ① |
| Activité de recherche | ① ② |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Vous pouvez copier des données à partir de tout magasin de données source pris en charge vers Azure Data Explorer. Vous pouvez également copier des données à partir d’Azure Data Explorer vers tout magasin de données récepteur pris en charge. Pour obtenir la liste des magasins de données prises en charge par l'activité de copie en tant que sources ou récepteurs, consultez la table Magasins de données pris en charge.
Notes
La copie de données vers ou depuis Azure Data Explorer via un magasin de données local à l’aide d’un runtime d’intégration auto-hébergé est prise en charge depuis la version 3.14.
Le connecteur Azure Data Explorer vous permet d’effectuer les opérations suivantes :
- Copier des données en utilisant une authentification de jeton d’application Microsoft Entra avec un principal de service.
- En tant que source, récupérer des données à l’aide d’une requête KQL (Kusto).
- En tant que récepteur, ajouter des données à une table de destination.
Prise en main
Conseil
Pour obtenir une description de l’utilisation du connecteur Azure Data Explorer, consultez Copier des données vers ou depuis Azure Data Explorer et Copie en bloc depuis une base de données vers Azure Data Explorer.
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
Créer un service lié à Azure Data Explorateur à l’aide de l’interface utilisateur
Utilisez les étapes suivantes pour créer un service lié à Azure Data Explorer dans l’interface utilisateur du portail Azure.
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse, sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez Explorer et sélectionnez le connecteur Azure Data Explorer (Kusto).
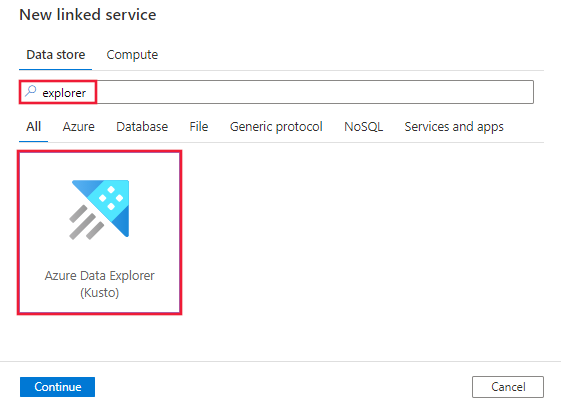
Configurez les informations du service, testez la connexion et créez le nouveau service lié.
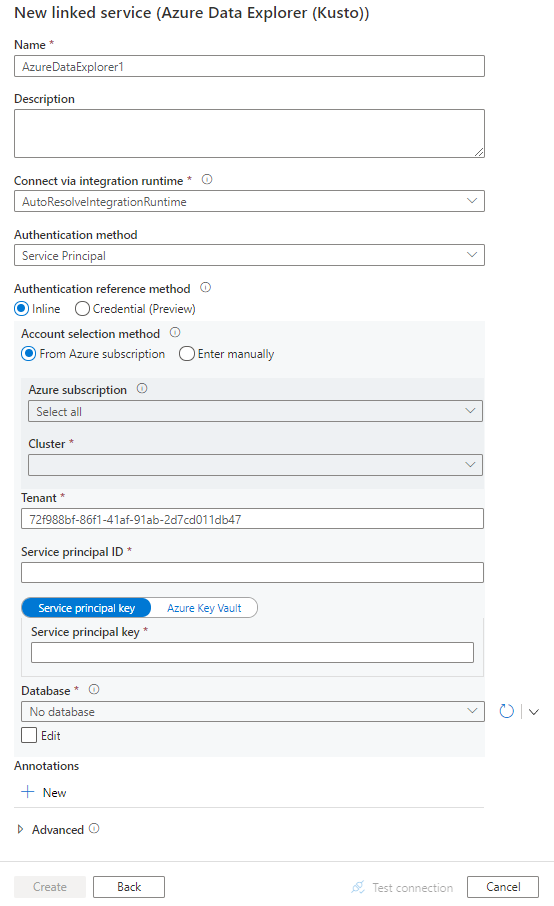
Informations de configuration du connecteur
Les sections suivantes fournissent des informations détaillées sur les propriétés utilisées pour définir des entités spécifiques au connecteur Azure Data Explorer.
Propriétés du service lié
Le connecteur Azure Data Explorer prend en charge les types d’authentification suivants. Consultez les sections correspondantes pour plus d’informations :
- Authentification d’un principal du service
- Authentification d’identité managée affectée par le système
- Authentification d’identité managée affectée par l’utilisateur
Authentification d’un principal du service
Pour utiliser l’authentification du principal du service, procédez comme suit pour obtenir un principal du service et accorder des autorisations :
Inscrire une application à l’aide de la plateforme d’identités Microsoft. Pour savoir comment, regardez Démarrage rapide : Inscrire une application à l’aide de la plateforme d’identités Microsoft. Prenez note des valeurs suivantes qui vous permettent de définir le service lié :
- ID de l'application
- Clé de l'application
- ID client
Accordez les autorisations qui conviennent au principal de service dans Azure Data Explorer. Consultez Gérer les autorisations de base de données d’Azure Data Explorer pour obtenir des informations détaillées sur les rôles et les autorisations, ainsi que la gestion des autorisations. En règle générale, vous devez :
- En tant que source, accorder au moins le rôle Observateur de base de données à votre base de données
- En tant que récepteur, accordez au moins le rôle d’utilisateur de base de données à votre base de données
Notes
Lorsque vous utilisez l’interface utilisateur pour créer, votre compte d’utilisateur de connexion est utilisé par défaut pour répertorier les clusters, bases de données et tables Azure Data Explorer. Vous pouvez choisir de répertorier les objets à l’aide du principal de service en cliquant sur la liste déroulante à côté du bouton actualiser, ou en entrant manuellement le nom si vous n’êtes pas autorisé à effectuer ces opérations.
Les propriétés suivantes sont prises en charge pour le service lié Azure Data Explorer :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur AzureDataExplorer. | Oui |
| endpoint | URL de point de terminaison du cluster Azure Data Explorer, avec le format https://<clusterName>.<regionName>.kusto.windows.net. |
Oui |
| database | Nom de base de données. | Oui |
| tenant | Spécifiez les informations de locataire (nom de domaine ou ID de locataire) dans lesquels se trouve votre application. C’est ce que vous connaissez sous le nom « ID d’autorité » dans la chaîne de connexion Kusto. Récupérez-les en pointant la souris dans le coin supérieur droit du Portail Azure. | Oui |
| servicePrincipalId | Spécifiez l’ID client de l’application. C’est ce qu’on appelle « ID client d’application Microsoft Entra » dans la chaîne de connexion Kusto. | Oui |
| servicePrincipalKey | Spécifiez la clé de l’application. C’est ce qu’on appelle « Clé d’application Microsoft Entra » dans la chaîne de connexion Kusto. Marquez ce champ en tant que SecureString afin de le stocker de façon sécurisée, ou référencez un secret stocké dans Azure Key Vault. | Oui |
| connectVia | Le runtime d’intégration à utiliser pour se connecter à la banque de données. Vous pouvez utiliser le runtime d'intégration Azure ou un runtime d’intégration auto-hébergé si votre banque de données se trouve sur un réseau privé. À défaut de spécification, l’Azure Integration Runtime par défaut est utilisé. | Non |
Exemple : utilisation de l’authentification de la clé du principal de service
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"tenant": "<tenant name/id e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
}
}
Authentification d’identité managée affectée par le système
Pour en savoir plus sur les identités managées pour les ressources Azure, consultez Identités managées pour les ressources Azure.
Pour utiliser l’authentification via une identité managée affectée par le système, procédez comme suit pour accorder les autorisations :
Récupérez les informations d’identité managée en copiant la valeur de l’ID d’objet d’identité managée générée en même temps que votre fabrique ou espace de travail Synapse.
Accordez les autorisations qui conviennent à l’identité managée dans Azure Data Explorer. Consultez Gérer les autorisations de base de données d’Azure Data Explorer pour obtenir des informations détaillées sur les rôles et les autorisations, ainsi que la gestion des autorisations. En règle générale, vous devez :
- En tant que source, accordez le rôle Observateur de base de données à votre base de données.
- En tant que récepteur, accordez les rôles Ingesteur de base de données et Observateur de base de données à votre base de données.
Remarque
Lorsque vous utilisez l’interface utilisateur pour créer, votre compte d’utilisateur de connexion est utilisé pour répertorier les clusters, bases de données et tables Azure Data Explorer. Entrez manuellement le nom si vous n’avez pas d’autorisation pour ces opérations.
Les propriétés suivantes sont prises en charge pour le service lié Azure Data Explorer :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur AzureDataExplorer. | Oui |
| endpoint | URL de point de terminaison du cluster Azure Data Explorer, avec le format https://<clusterName>.<regionName>.kusto.windows.net. |
Oui |
| database | Nom de base de données. | Oui |
| connectVia | Le runtime d’intégration à utiliser pour se connecter à la banque de données. Vous pouvez utiliser le runtime d'intégration Azure ou un runtime d’intégration auto-hébergé si votre banque de données se trouve sur un réseau privé. À défaut de spécification, l’Azure Integration Runtime par défaut est utilisé. | Non |
Exemple : utiliser l’authentification via une identité managée affectée par le système
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
}
}
}
Authentification d’identité managée affectée par l’utilisateur
Pour en savoir plus sur les identités managées pour les ressources Azure, consultez Identités managées pour les ressources Azure
Pour utiliser l’authentification par identité managée affectée par l’utilisateur, effectuez les étapes suivantes :
Créez une ou plusieurs identités managées affectées par l’utilisateur et accordez une autorisation dans Azure Data Explorer. Consultez Gérer les autorisations de base de données d’Azure Data Explorer pour obtenir des informations détaillées sur les rôles et les autorisations, ainsi que la gestion des autorisations. En règle générale, vous devez :
- En tant que source, accorder au moins le rôle Observateur de base de données à votre base de données
- En tant que récepteur, accorder au moins le rôle Ingéreur de base de données à votre base de données
Attribuez une ou plusieurs identités managées affectées par l’utilisateur à votre fabrique de données ou espace de travail Synapse et créez des informations d’identification pour chaque identité managée affectée par l’utilisateur.
Les propriétés suivantes sont prises en charge pour le service lié Azure Data Explorer :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur AzureDataExplorer. | Oui |
| endpoint | URL de point de terminaison du cluster Azure Data Explorer, avec le format https://<clusterName>.<regionName>.kusto.windows.net. |
Oui |
| database | Nom de base de données. | Oui |
| credentials | Spécifiez l’identité managée affectée par l’utilisateur en tant qu’objet d’informations d’identification. | Oui |
| connectVia | Le runtime d’intégration à utiliser pour se connecter à la banque de données. Vous pouvez utiliser le runtime d'intégration Azure ou un runtime d’intégration auto-hébergé si votre banque de données se trouve sur un réseau privé. À défaut de spécification, l’Azure Integration Runtime par défaut est utilisé. | Non |
Exemple : utiliser l’authentification via une identité managée affectée par l’utilisateur
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
}
}
}
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article sur les jeux de données. Cette section répertorie les propriétés prises en charge par le jeu de données Azure Data Explorer.
Pour copier des données vers Azure Data Explorer, définissez la propriété type du jeu de données sur AzureDataExplorerTable.
Les propriétés prises en charge sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur AzureDataExplorerTable. | Oui |
| table | Nom de la table dans la base à laquelle le service lié fait référence. | Oui pour le récepteur, Non pour la source |
Exemple de propriétés du jeu de données :
{
"name": "AzureDataExplorerDataset",
"properties": {
"type": "AzureDataExplorerTable",
"typeProperties": {
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure Data Explorer linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition des activités, consultez Pipelines et activités. Cette section fournit la liste des propriétés prises en charge par les sources et récepteurs Azure Data Explorer.
Azure Data Explorer en tant que source
Pour copier des données à partir d’Azure Data Explorer, définissez la propriété type dans la source d’activité de copie sur AzureDataExplorerSource. Les propriétés prises en charge dans la section source de l’activité de copie sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité de copie doit être définie sur : AzureDataExplorerSource | Oui |
| query | Requête en lecture seule au format KQL. Utilisez la requête KQL personnalisée en tant que référence. | Oui |
| queryTimeout | Temps d’attente avant l’expiration de la demande de requête. La valeur par défaut est 10 minutes (00:10:00) et la valeur maximale autorisée 1 heure (01:00:00). | Non |
| noTruncation | Indique s’il faut tronquer le jeu de résultats retourné. Par défaut, le résultat est tronqué après 500 000 enregistrements ou au-delà de 64 mégaoctets (Mo). La troncation est vivement recommandée pour garantir le bon comportement de l’activité. | Non |
Notes
Par défaut, la source d’Azure Data Explorer présente une taille limite de 500 000 enregistrements ou 64 Mo. Pour récupérer tous les enregistrements sans troncation, vous pouvez spécifier set notruncation; au début de votre requête. Pour plus d'informations, consultez Limites de requête.
Exemple :
"activities":[
{
"name": "CopyFromAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "AzureDataExplorerSource",
"query": "TestTable1 | take 10",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
},
"inputs": [
{
"referenceName": "<Azure Data Explorer input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
]
}
]
Azure Data Explorer en tant que récepteur
Pour copier des données vers Azure Data Explorer, définissez la propriété type dans le récepteur d’activité de copie sur AzureDataExplorerSink. Les propriétés prises en charge dans la section sink (récepteur) de l’activité de copie sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du récepteur d’activité de copie doit être définie sur : AzureDataExplorerSink. | Oui |
| ingestionMappingName | Nom d’un mappage créé au préalable sur une table Kusto. Pour mapper les colonnes de la source et Azure Data Explorer, ce qui s’applique à tous les magasins et formats de source pris en charge, notamment les formats CSV/JSON/Avro, vous pouvez utiliser l’activité de copie mappage des colonnes (implicitement par nom ou explicitement configurée) et/ou les mappages d’Azure Data Explorer. | Non |
| additionalProperties | Conteneur des propriétés qui peut être utilisé pour spécifier l’une des propriétés d’ingestion qui ne sont pas déjà définies par le récepteur Azure Data Explorer. Plus précisément, il peut être utile pour spécifier des balises d’ingestion. Pour en savoir plus, consultez le document relatif à l’ingestion des données Azure Data Explorer. | Non |
Exemple :
"activities":[
{
"name": "CopyToAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDataExplorerSink",
"ingestionMappingName": "<optional Azure Data Explorer mapping name>",
"additionalProperties": {<additional settings for data ingestion>}
}
},
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure Data Explorer output dataset name>",
"type": "DatasetReference"
}
]
}
]
Propriétés du mappage de flux de données
Lors de la transformation de données dans le flux de données de mappage, vous pouvez lire et écrire dans des tables dans Azure Data Explorer. Pour plus d’informations, consultez la transformation de la source et la transformation du récepteur dans le flux de données de mappage. Vous pouvez choisir d’utiliser un jeu de données Azure Data Explorer ou un jeu de données inlined en tant que type de source et de récepteur.
Transformation de la source
Le tableau ci-dessous liste les propriétés prises en charge par une source Azure Data Explorer. Vous pouvez modifier ces propriétés sous l’onglet Options de la source.
| Nom | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Table de charge de travail | Si vous sélectionnez Table comme entrée, le flux de données extrait toutes les données de la table spécifiée dans le jeu de données Azure Data Explorer ou dans les options source lorsque vous utilisez le jeu de données inlined. | Non | String | (pour le jeu de données inlined uniquement) tableName |
| Requête | Requête en lecture seule au format KQL. Utilisez la requête KQL personnalisée en tant que référence. | Non | String | query |
| Délai d'expiration | Temps d’attente avant l’expiration de la demande de requête. La valeur par défaut est 172000 (2 jours). | Non | Integer | timeout |
Exemples de scripts sources Azure Data Explorer
Quand vous utilisez un jeu de données Azure Data Explorer comme type de source, le script de flux de données associé est le suivant :
source(allowSchemaDrift: true,
validateSchema: false,
query: 'table | take 10',
format: 'query') ~> AzureDataExplorerSource
Si vous utilisez un jeu de données inlined, le script de flux de données associé est le suivant :
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'table | take 10',
store: 'azuredataexplorer') ~> AzureDataExplorerSource
Transformation du récepteur
Le tableau ci-dessous liste les propriétés prises en charge par le récepteur Azure Data Explorer. Vous pouvez modifier ces propriétés sous l’onglet Paramètres. Lorsque vous utilisez un jeu de données inlined, vous verrez des paramètres supplémentaires qui sont les mêmes que les propriétés décrites dans la section Propriétés du jeu de données.
| Nom | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Action table | Détermine si toutes les lignes de la table de destination doivent être recréées ou supprimées avant l’écriture. - Aucun : Aucune action ne sera effectuée sur la table. - Recréer : La table sera supprimée et recréée. Obligatoire en cas de création dynamique d’une nouvelle table. - Tronquer : Toutes les lignes de la table cible seront supprimées. |
Non | true ou false |
recreate truncate |
| Pré et post-scripts SQL | Spécifiez plusieurs scripts de commandes de contrôle Kusto qui s’exécutent avant (prétraitement) et après (post-traitement) l’écriture de données dans votre base de données de réception. | Non | String | preSQLs ; postSQLs |
| Délai d'expiration | Temps d’attente avant l’expiration de la demande de requête. La valeur par défaut est 172000 (2 jours). | Non | Integer | timeout |
Exemples de scripts de récepteur Azure Data Explorer
Quand vous utilisez un jeu de données Azure Data Explorer comme type de récepteur, le script de flux de données associé est le suivant :
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
preSQLs:['pre SQL scripts'],
postSQLs:['post SQL script'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Si vous utilisez un jeu de données inlined, le script de flux de données associé est le suivant :
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
store: 'azuredataexplorer',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Propriétés de l’activité Lookup
Pour plus d’informations sur les propriétés, consultez Activité de recherche.
Contenu connexe
Pour obtenir la liste des magasins de données pris en charge par l'activité de copie en tant que sources et récepteurs, consultez Magasins de données pris en charge.
Apprenez-en davantage sur la copie de données d’Azure Data Factory et Synapse Analytics vers Azure Data Explorer.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour