Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Data Factory dans Microsoft Fabric est la prochaine génération de Azure Data Factory, avec une architecture plus simple, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'intégration des données, commencez par Fabric Data Factory. Les charges de travail ADF existantes peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Azure Data Factory est le service d’intégration des données et DEL de Microsoft dans le cloud. Ce document fournit des conseils sur DataOps dans la fabrique de données. Il n’a pas vocation à constituer un tutoriel complet sur CI/CD, Git ou DevOps. Vous y trouverez plutôt les conseils de l’équipe Data Factory pour la réalisation de DataOps dans le service avec des références à des liens vers des implémentations détaillées décrivant les bonnes pratiques de déploiement d’une fabrique de données, la gestion de la fabrique et la gouvernance. Une section liste des ressources à la fin de cet article avec des liens vers des tutoriels.
Qu’est-ce que DataOps ?
DataOps est un processus que les organisations de données pratiquent à des fins de gestion des données collaborative visant à fournir une valeur plus rapide aux décideurs.
Gartner propose cette définition précise de DataOps :
DataOps est une pratique de gestion des données collaborative qui se concentre sur l’amélioration de la communication, de l’intégration et de l’automatisation des flux de données entre les gestionnaires de données et les consommateurs de données au sein d’une organisation. L’objectif de DataOps est de fournir de la valeur plus rapidement en créant une livraison et une gestion prévisibles des modifications des données, des modèles de données et des artefacts associés. DataOps utilise la technologie pour automatiser la conception, le déploiement et la gestion de la livraison des données avec des niveaux de gouvernance appropriés. Des métadonnées sont utilisées pour améliorer la facilité d’utilisation et la valeur des données dans un environnement dynamique.
Comment obtenir DataOps dans Azure Data Factory ?
Azure Data Factory fournit aux ingénieurs de données un paradigme de pipeline de données visuel pour créer facilement des projets d'intégration de données et ETL à l'échelle du cloud. Data Factory s’appuie sur des intégrations natives avec des outils de contrôle de version matures tels que GitHub et Azure DevOps, ainsi que l’écosystème de Azure plus large, pour fournir de nombreuses fonctionnalités intégrées pour faciliter dataOps qui incluent une collaboration, une gouvernance et des relations d’artefact enrichies.
Plus précisément, une fois que vous importez votre dépôt GitHub ou Azure DevOps dans Data Factory, le service propose des options d'interface utilisateur intégrées et intuitives pour les commandes courantes telles que les commits, l’enregistrement des artefacts et le contrôle de version. Le service offre également la possibilité d’appliquer les bonnes pratiques en matière de CI/CD et d’archivage de code, afin de protéger la validité et l’intégrité de votre environnement de production.
« Code » dans Azure Data Factory
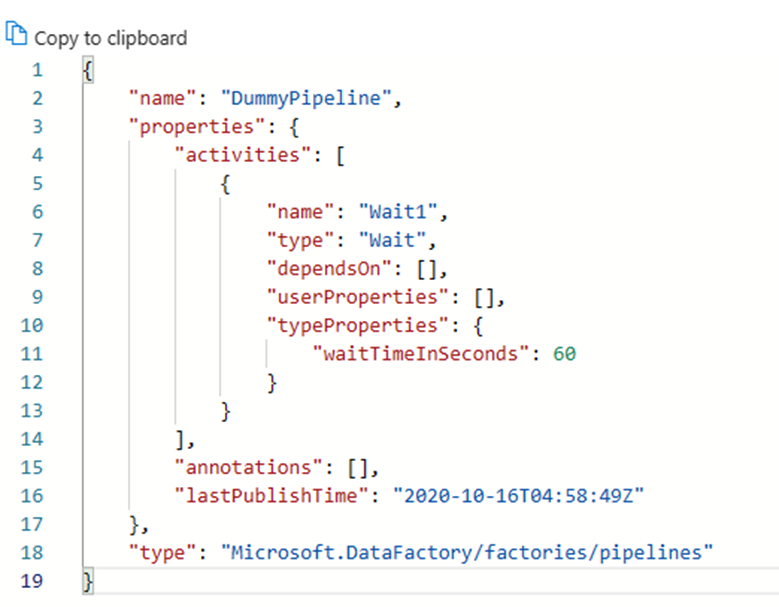
Tous les artefacts de Azure Data Factory, qu'ils soient des pipelines, des services liés, des déclencheurs, etc. ont des représentations « code » correspondantes dans JSON derrière l'intégration de l'interface utilisateur visuelle. Ces artefacts agissent en conformité avec les modèles Azure Resource Manager. Vous pouvez trouver le code en cliquant sur l’icône des crochets située en haut à droite du canevas. Voici ce à quoi ressemble un exemple de « code » JSON :
Mode réel et gestion de versions Git
Chaque fabrique a une seule source de vérité : pipelines, services liés et définitions de déclencheur stockés au sein du service. Cette source de vérité à ce que le pipeline exécute et à ce qui détermine les comportements des déclencheurs. Si vous êtes en mode réel, chaque fois que vous publiez, vous modifiez directement la source unique de vérité. L’image suivante montre ce à quoi ressemble le bouton Publier tout en mode réel.

Le mode direct peut s’avérer pratique pour une personne seule qui travaille sur des projets parallèles, car il permet aux développeurs de voir les effets immédiats de leurs modifications de code. Toutefois, il est déconseillé aux équipes de développeurs de travailler sur des projets au niveau de la production. Les risques incluent les erreurs de frappe, les suppressions accidentelles de ressources critiques, la publication de codes non testés, etc., pour n’en citer que quelques-uns. Quand vous travaillez sur des plateformes et des projets stratégiques, envisagez d’intégrer un dépôt Git et d’utiliser le mode Git dans la fabrique de données pour simplifier le processus de développement. contrôle de version et les fonctionnalités de validation de check-in en mode Git vous aident à éviter la plupart, voire la totalité, des accidents liés à la modification directe du mode live.
Note
En mode Git, le bouton Publier ou Publier tout est remplacé par Enregistrer ou Enregistrer tout et vos changements sont commités dans vos propres branches (sans modifier directement les codebases réels).
Configuration de l’intégration de GitHub et de Azure DevOps
Dans Azure Data Factory, il est vivement recommandé de stocker votre référentiel dans GitHub ou Azure DevOps. Le service prend entièrement en charge les deux méthodes et le choix du dépôt à utiliser dépend des normes propres à votre organisation. Il existe deux méthodes pour configurer un nouveau référentiel ou pour vous connecter à un référentiel existant : à l’aide du portail Azure ou de la création à partir de l’interface utilisateur Azure Data Factory Studio
création d’une fabrique de portail Azure
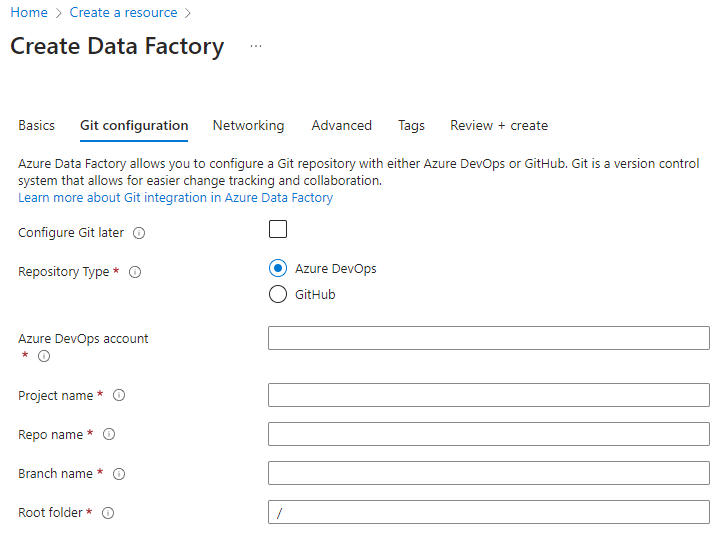
Lorsque vous créez une fabrique de données à partir du portail Azure, le dépôt Git par défaut est Azure DevOps. Vous pouvez également sélectionner GitHub en tant que dépôt et configurer vos paramètres de dépôt.
Dans le portail Azure, sélectionnez le type de dépôt et entrez le dépôt et les noms de branche pour créer une fabrique intégrée en mode natif à Git.
Application de l’utilisation de Git avec Azure Policy dans votre organisation
L’utilisation de Git dans vos projets Azure Data Factory est une bonne pratique fortement recommandée. Même si vous n’implémentez pas un processus CI/CD complet, l’intégration de Git à ADF permet d’enregistrer vos artéfacts dans votre propre environnement de développement isolé (branche Git) où vous pouvez tester vos changements indépendamment du reste des branches du projet. Vous pouvez utiliser Azure Policy pour appliquer l’utilisation de Git dans la fabrique de votre organisation.
Azure Data Factory Studio
Après avoir créé votre fabrique de données, vous pouvez également vous connecter à votre dépôt via le Azure Data Factory Studio. Sous l’onglet Gérer, vous allez voir l’option permettant de configurer votre dépôt et ses paramètres.

Par le biais d’un processus guidé, vous êtes accompagné tout au long d’une série d’étapes pour configurer le dépôt de votre choix et vous y connecter facilement. Une fois la configuration effectuée, vous pouvez commencer à travailler en collaboration et à enregistrer vos ressources dans votre dépôt.
Intégration continue et livraison continue (CI/CD)
CI/CD est un paradigme de développement de code dans lequel les changements sont inspectés et testés à mesure qu’ils passent par différentes étapes : développement, test, préproduction, etc. Après avoir été examinés et testés à chaque étape, ils sont finalement publiés sur des codebases réels dans un environnement de production.
L’intégration continue (CI) est la pratique qui consiste à tester et valider automatiquement chaque changement apporté par un développeur à votre codebase. La livraison continue (CD) signifie qu’une fois les tests d’intégration continue réussis, les changements passent à l’étape suivante en continu.
Comme indiqué brièvement, « code » dans Azure Data Factory prend la forme d’un modèle Azure Resource Manager JSON. Ainsi, les changements qui passent par le processus d’intégration et de livraison continues (CI/CD) comprennent des ajouts, des suppressions et des modifications de blobs JSON.
Exécutions de pipeline dans Azure Data Factory
Avant de parler de CI/CD dans Azure Data Factory, nous devons d’abord parler de la façon dont le service exécute un pipeline. Avant qu'un Data Factory exécute un pipeline, il effectue les opérations suivantes :
- Tirage (pull) de la dernière définition publiée du pipeline et de ses ressources associées, comme des jeux de données, des services liés, etc.
- Compilation du pipeline en actions. Si la fabrique de données l’a exécuté récemment, elle récupère les actions dans les compilations mises en cache.
- Exécution du pipeline.
L’exécution du pipeline implique les étapes suivantes :
- Le service prend l’instantané à un point dans le temps de la définition du pipeline.
- Pendant toute la durée du pipeline, les définitions ne changent pas.
- Même si vos pipelines s’exécutent longtemps, ils ne sont pas affectés par les changements ultérieurs apportés après leur démarrage. Si vous publiez des changements sur le service lié, les pipelines, etc., pendant l’exécution, ceux-ci n’affectent pas les exécutions en cours.
- Lorsque vous publiez des modifications, les exécutions suivantes démarrées après la publication utilisent les définitions mises à jour.
Publication dans Azure Data Factory
Que vous déployiez des pipelines avec Azure Release Pipeline pour automatiser la publication, ou avec le déploiement manuel de modèles Resource Manager, dans le serveur principal, la publication est une série d'opérations de création/mise à jour sur les datasets, les services liés, les pipelines et les triggers, pour chacun des artefacts. L’effet est le même que si vous effectuiez les appels d’API REST sous-jacents directement.
Voici quelques éléments qui sont le résultat des actions :
- Tous ces appels d’API sont synchrones, ce qui signifie que l’appel est retourné uniquement quand la publication réussit/échoue. Il n’y aura pas d’état de déploiement partiel pour l’artefact.
- Les appels d’API sont, dans une large mesure, séquentiels. Nous essayons de paralléliser les appels, tout en conservant les dépendances référentielles des artefacts. L’ordre des déploiements est service lié -> jeu de données/runtime d’intégration -> pipeline -> déclencheur. Cet ordre garantit que les artefacts dépendants peuvent référencer correctement leurs dépendances. Par exemple, les pipelines dépendent des jeux de données et la fabrique de données les déploie après les jeux de données.
- Les déploiements de services liés, jeux de données, etc. sont indépendants des pipelines. Dans certaines situations, Azure Data Factory met à jour les services liés avant qu'un pipeline ne soit mis à jour. Nous aborderons cette situation dans la section Quand arrêter un déclencheur.
- Le déploiement ne supprime pas les artefacts des fabriques. Vous avez besoin d’appeler explicitement les API de suppression pour chaque type d’artefact (pipeline, jeu de données, service lié, etc.) pour nettoyer une fabrique. Reportez-vous à l’exemple de script post-déploiement à partir de Azure Data Factory par exemple.
- Même si vous n’avez pas touché un pipeline, un jeu de données ou un service lié, il effectue quand même un appel d’API de mise à jour rapide de la fabrique.
Déclencheurs de publication
- Les déclencheurs ont un état : démarré ou arrêté.
- Vous ne pouvez pas apporter de changements à un déclencheur en mode démarré. Vous avez besoin d’arrêter un déclencheur avant de publier des changements.
- Vous pouvez appeler l’API de création ou mise à jour d’un déclencheur sur un déclencheur en mode démarré.
- Si la charge utile change, l’API échoue.
- Si la charge utile reste inchangée, l’API réussit.
- Ce comportement exerce un fort impact sur le moment auquel arrêter un déclencheur.
Quand arrêter un déclencheur
Dans le cas d’un déploiement sur une fabrique de données de production, avec des déclencheurs réels qui démarrent en permanence des exécutions de pipeline, la question se pose de savoir si nous avons intérêt à les arrêter.
La réponse rapide est que dans les quelques scénarios suivants uniquement, il est préférable d’envisager d’arrêter le déclencheur :
- Vous avez besoin d’arrêter le déclencheur si vous mettez à jour ses définitions, notamment des champs comme la date de fin, la fréquence et l’association de pipeline.
- Il est recommandé d’arrêter le déclencheur si vous mettez à jour les jeux de données ou les services liés référencés dans un pipeline réel. Par exemple, si vous effectuez une rotation des informations d'identification pour SQL Server.
- Vous pouvez choisir d’arrêter le déclencheur si le pipeline associé génère des erreurs, échoue et accable vos serveurs.
Voici les quelques points à prendre en compte sur l’arrêt des déclencheurs :
- Comme expliqué dans la section Pipeline s’exécute dans Azure Data Factory, lorsqu’un déclencheur lance une exécution de pipeline, il prend un instantané du pipeline, du jeu de données, du runtime d’intégration et des définitions de service lié. Si le pipeline s’exécute avant que les changements ne soient renseignés dans le back-end, le déclencheur démarre une exécution avec l’ancienne version. Dans la plupart des cas, cela fonctionne bien.
- Comme expliqué dans la section Déclencheurs de publication, quand un déclencheur est à l’état démarré, il ne peut pas être mis à jour. Par conséquent, si vous avez besoin de modifier des détails de la définition du déclencheur, arrêtez le déclencheur avant de publier les changements.
- Comme expliqué dans la section Publishing dans Azure Data Factory, les modifications apportées aux jeux de données ou aux services liés sont publiées avant les modifications du pipeline. Pour veiller à ce que les exécutions de pipeline utilisent les informations d’identification correctes et communiquent avec les serveurs appropriés, nous vous recommandons d’arrêter aussi le déclencheur associé.
Préparation des changements de « code »
Nous vous recommandons de suivre ces meilleures pratiques pour les pull requests.
- Chaque développeur doit travailler sur ses propres branches individuelles et, en fin de journée, créer des demandes de tirage vers la branche primaire du dépôt. Consultez les tutoriels sur les demandes de tirage dans GitHub et DevOps.
- Quand les gardiens (gatekeepers) approuvent les demandes de tirage et fusionnent les changements dans la branche primaire, le processus CI/CD peut démarrer. Il existe deux méthodes suggérées pour promouvoir des changements dans tous les environnements : automatisée et manuelle.
- Une fois que vous êtes prêt à démarrer des pipelines CI/CD, vous pouvez généralement utiliser Azure Pipeline Release ou déployer des pipelines individuels spécifiques à l'aide de cet utilitaire open source de Azure Player.
Déploiement automatisé des changements
Pour faciliter les déploiements automatisés, nous vous recommandons d’utiliser le package npm des utilitaires Azure Data Factory. L’utilisation du package npm permet de valider toutes les ressources incluses dans un pipeline et de générer les modèles ARM pour l’utilisateur.
Pour bien démarrer avec le package npm des utilitaires Azure Data Factory, reportez-vous à la publication automatisée pour l’intégration et la livraison continues.
Déploiement manuel des changements
Une fois que vous avez fusionné votre branche vers la branche de collaboration principale dans votre dépôt Git, vous pouvez publier manuellement vos modifications dans le service live Azure Data Factory. Le service offre un contrôle d’interface utilisateur sur la publication à partir de fabriques hors développement avec l’option Désactiver la publication (à partir d’ADF Studio).
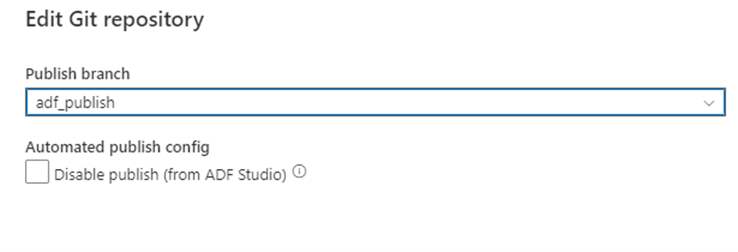
Déploiement sélectif
Le déploiement sélectif s’appuie sur une fonctionnalité de GitHub et de Azure DevOps, appelée cherry picking. Cette fonctionnalité vous permet de déployer uniquement certains changements, mais pas d’autres. Par exemple, un développeur a apporté des changements à plusieurs pipelines, mais pour le déploiement d’aujourd’hui, vous avez peut-être envie de déployer ces changements sur un seul pipeline.
Suivez les didacticiels de Azure DevOps et de GitHub pour sélectionner les validations pertinentes pour le pipeline dont vous avez besoin. Vérifiez que tous les changements, y compris les changements pertinents apportés aux déclencheurs, aux services liés et aux dépendances associés au pipeline, ont fait l’objet d’un cherry picking.
Une fois que vous avez appliqué un cherry picking aux changements et effectué une fusion avec le pipeline de collaboration primaire, vous pouvez lancer le processus CI/CD pour les changements proposés. Pour plus d’informations sur la façon de corriger à chaud, d’appliquer un cherry picking ou d’utiliser des frameworks externes pour un déploiement sélectif, consultez la section Tests automatisés de cet article.
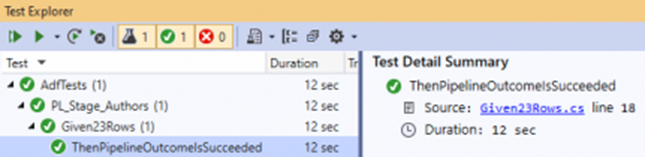
Effectuer des tests unitaires
Les tests unitaires forment une partie importante du processus de développement de nouveaux pipelines ou de modification d’artefacts de fabrique de données existants, qui se concentre sur les tests des composants du code. Data Factory autorise les tests unitaires individuels au niveau du pipeline et de l’artefact du flux de données à l’aide de la fonctionnalité de débogage du pipeline.

Quand vous développez des flux de données, vous pouvez obtenir des insights sur chaque transformation individuelle et chaque changement de code à l’aide de la fonctionnalité d’aperçu des données pour effectuer des tests unitaires avant de déployer vos changements en production.

Le service fournit des commentaires en direct et interactifs sur vos activités de pipeline dans l’interface utilisateur lors du débogage et des tests unitaires dans Azure Data Factory.
Tests automatisés
Il existe plusieurs outils disponibles pour les tests automatisés que vous pouvez utiliser avec Azure Data Factory. Étant donné que le service stocke des objets dans le service en tant qu’entités JSON, il peut être pratique d’utiliser l’infrastructure de test unitaire open source .NET NUnit avec Visual Studio. Reportez-vous à ce billet Setup des tests automatisés pour Azure Data Factory qui fournit une explication détaillée de la configuration d’un environnement de test unitaire automatisé pour votre fabrique. (Un grand merci à Richard Swinbank qui a donné son autorisation pour utiliser ce blog.)
Les clients peuvent également exécuter des pipelines TEST avec PowerShell ou l’interface CLI AZ dans le cadre du processus CI/CD pour les étapes de pré-déploiement et de post-déploiement.
Un avantage non négligeable de la fabrique de données réside dans son paramétrage des jeux de données. Cette fonctionnalité permet aux clients d’exécuter les mêmes pipelines avec différents jeux de données pour veiller à ce que leur nouveau développement réponde à toutes les exigences de source et de destination.
Autres frameworks CI/CD pour Azure Data Factory
Comme décrit précédemment, l’intégration Git intégrée est disponible en mode natif via l’interface utilisateur de Azure Data Factory, notamment la fusion, la branchement, la comparaison et la publication. Toutefois, il existe d’autres frameworks CI/CD utiles qui sont populaires dans la communauté Azure, qui fournissent des mécanismes alternatifs pour fournir des fonctionnalités similaires. La méthodologie git Azure Data Factory est basée sur des modèles ARM, tandis que les frameworks comme ADFTools de Kamil Nowinski adoptent une approche différente en s’appuyant sur des artefacts JSON spécifiques à votre usine. Les ingénieurs données qui sont avertis dans Azure DevOps et préfèrent travailler dans cet environnement (par opposition à l’approche de l’interface utilisateur basée sur ARM que le service offre hors de la boîte de dialogue) peuvent constater que ce framework fonctionne bien pour eux et pour des scénarios courants tels que des déploiements partiels. Ce framework peut également simplifier la gestion des déclencheurs lors du déploiement dans des environnements qui ont des états de déclencheur en cours d’exécution.
Gouvernance des données dans Azure Data Factory
La gouvernance des données est un aspect important de l’efficacité de DataOps. Pour des outils ETL d’intégration de données, la traçabilité des données et les relations d’artefacts peuvent fournir des informations importantes à un ingénieur Données afin de comprendre l’impact des changements en aval. Data Factory fournit des vues intégrées d'artefacts associés qui font partie intégrante de l’implémentation de votre usine.
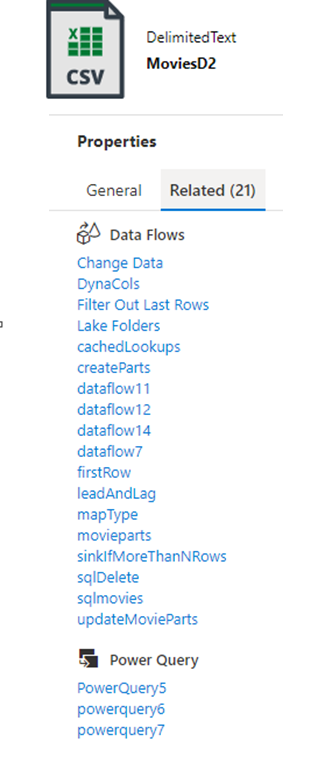
L’intégration native avec Microsoft Purview fournit davantage de traçabilité, d’analyse d’impact et de catalogue de données.
Microsoft Purview fournit une solution unifiée de gouvernance des données pour vous aider à gérer et à régir vos données saaS (software as a service) locales, multiclouds et logicielles. Elle vous permet de créer facilement une carte holistique actualisée du paysage de vos données, avec la découverte automatisée des données, la classification des données sensibles et la traçabilité des données de bout en bout. Ces fonctionnalités donnent les moyens aux consommateurs de données d’accéder à une gestion des données utile et fiable.
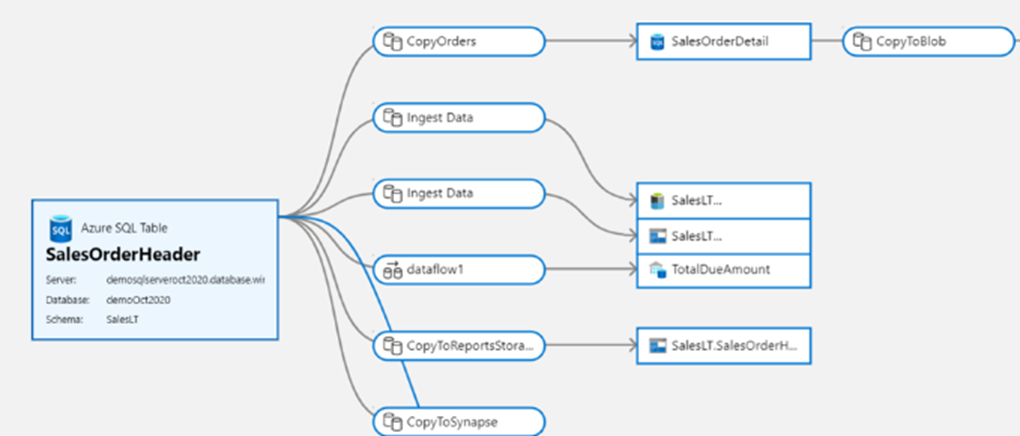
Avec l’intégration native à votre Data Catalog Purview, data factory permet de rechercher et de découvrir facilement les ressources de données à utiliser dans vos pipelines d’intégration de données dans l’étendue complète du patrimoine de données de votre organisation.

Vous pouvez utiliser la barre de recherche principale à partir du Azure Data Factory Studio pour rechercher des ressources de données dans votre catalogue Purview.
