Mappage de schéma et de type de données dans l’activité de copie
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article décrit comment l’activité Copy d’Azure Data Factory effectue un mappage de schéma et de type de données des données de la source au données du récepteur.
Mappage de schéma
Mappage par défaut
Par défaut, l’activité de copie mappe les données sources au récepteur par noms de colonnes de manière sensible à la casse. Si le récepteur n’existe pas, par exemple, en écrivant dans un ou plusieurs fichiers, les noms des champs sources sont rendus persistants en tant que noms de récepteurs. Si le récepteur existe déjà, il doit contenir toutes les colonnes copiées à partir de la source. Ce mappage par défaut prend en charge des schémas flexibles et des dérives de schéma de la source au récepteur d’une exécution à l’autre. Toutes les données retournées par le magasin de données source peuvent être copiées dans le récepteur.
Si votre source est un fichier texte sans ligne d’en-tête, un mappage explicite est requis, car la source ne contient pas de noms de colonne.
Mappage explicite
Vous pouvez également spécifier un mappage explicite pour personnaliser le mappage de colonne/de champ de la source au récepteur selon vos besoins. Avec le mappage explicite, vous pouvez copier uniquement des données sources partielles vers le récepteur, mapper les données sources au récepteur avec des noms différents ou remodeler les données tabulaires/hiérarchiques. Activité de copie :
- Lit les données de la source et détermine le schéma source.
- Applique votre mappage défini.
- Écrit les données sur le récepteur.
Pour en savoir plus :
- De la source tabulaire vers le récepteur tabulaire
- De la source hiérarchique vers le récepteur tabulaire
- De la source tabulaire/hiérarchique vers le récepteur hiérarchique
Vous pouvez configurer le mappage dans l’interface utilisateur de création -> activité de copie -> onglet Mappage, ou spécifier programmatiquement le mappage dans activité de copie ->translator propriété. Les propriétés suivantes sont prises en charge dans translator>mappings tableau -> objets ->source et sink, qui pointe vers la colonne/le champ spécifique pour mapper les données.
| Propriété | Description | Obligatoire |
|---|---|---|
| name | Nom de la colonne/du champ source ou récepteur. Appliquer à la source tabulaire et au récepteur. | Oui |
| ordinal | Index de colonne. Démarrer à partir de 1. À appliquer et requis lors de l’utilisation de texte sans ligne d’en-tête délimité. |
Non |
| path | Expression de chemin JSON pour l’extraction ou le mappage de chaque champ. Appliquer à la source hiérarchique et au récepteur, par exemple, les connecteurs Azure Cosmos DB, MongoDB ou REST. Pour les champs situés sous l’objet racine, le chemin JSON commence par la racine $ ; pour les champs qui se trouvent dans le tableau sélectionné par la propriété collectionReference, le chemin JSON commence par l’élément de tableau sans $. |
Non |
| type | Type de données intermédiaire de la colonne source ou récepteur. En général, vous n’avez pas besoin de spécifier ni de modifier cette propriété. En savoir plus sur le mappage des types de données. | Non |
| culture | Culture de la colonne source ou récepteur. À appliquer lorsque le type est Datetime ou Datetimeoffset. Par défaut, il s’agit de en-us.En général, vous n’avez pas besoin de spécifier ni de modifier cette propriété. En savoir plus sur le mappage des types de données. |
Non |
| format | Chaîne de format à utiliser lorsque le type est Datetime ou Datetimeoffset. Reportez-vous à Chaînes de format Date et Heure personnalisées sur la mise en forme des date/heure. En général, vous n’avez pas besoin de spécifier ni de modifier cette propriété. En savoir plus sur le mappage des types de données. |
Non |
Les propriétés suivantes sont prises en charge sous translator en plus de mappings :
| Propriété | Description | Obligatoire |
|---|---|---|
| collectionReference | Appliquer lors de la copie de données d’une source hiérarchique, par exemple, les connecteurs Azure Cosmos DB, MongoDB ou REST. Si vous souhaitez effectuer une itération et extraire des données à partir des objets situés à l’intérieur d’un champ de tableau présentant le même modèle et effectuer une conversion par ligne et par objet, spécifiez le chemin JSON de ce tableau afin d’effectuer une application croisée. |
Non |
De la source tabulaire vers le récepteur tabulaire
Par exemple, pour copier des données de Salesforce vers Azure SQL Database et mapper explicitement trois colonnes :
Dans activité de copie -> onglet de mappage, cliquez sur le bouton Importer les schémas pour importer les schémas source et récepteur.
Mappez les champs nécessaires et excluez/supprimez le reste.

Le même mappage peut être configuré comme suit dans la charge utile de l’activité de copie (voir translator) :
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "SalesforceSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "name": "Id" },
"sink": { "name": "CustomerID" }
},
{
"source": { "name": "Name" },
"sink": { "name": "LastName" }
},
{
"source": { "name": "LastModifiedDate" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
Pour copier des données à partir d’un ou de plusieurs fichiers texte délimités sans ligne d’en-tête, les colonnes sont représentées par numéros plutôt que par noms.
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "DelimitedTextSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "ordinal": "1" },
"sink": { "name": "CustomerID" }
},
{
"source": { "ordinal": "2" },
"sink": { "name": "LastName" }
},
{
"source": { "ordinal": "3" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
De la source hiérarchique vers le récepteur tabulaire
Lors de la copie de données d’une source hiérarchique vers un récepteur tabulaire, l’activité de copie prend en charge les fonctionnalités suivantes :
- Extraire des données d’objets et de tableaux.
- Cross applique plusieurs objets avec le même modèle à partir d’un tableau, dans ce cas pour convertir un objet JSON en plusieurs enregistrements dans un résultat tabulaire.
Pour une transformation hiérarchique-à-tabulaire plus avancée, vous pouvez utiliser Data Flow.
Par exemple, si vous avez un document MongoDB source avec le contenu suivant :
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
Et que vous souhaitez copier ce fichier dans un fichier texte au format suivant avec une ligne d’en-tête, en mettant à plat les données se trouvant dans le tableau (order_pd and order_price) et en effectuant une jointure croisée avec les informations racines communes (numéro, date et ville) :
| orderNumber | orderDate | order_pd | order_price | city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
Vous pouvez définir un mappage de ce type sur l’interface utilisateur de création Data Factory :
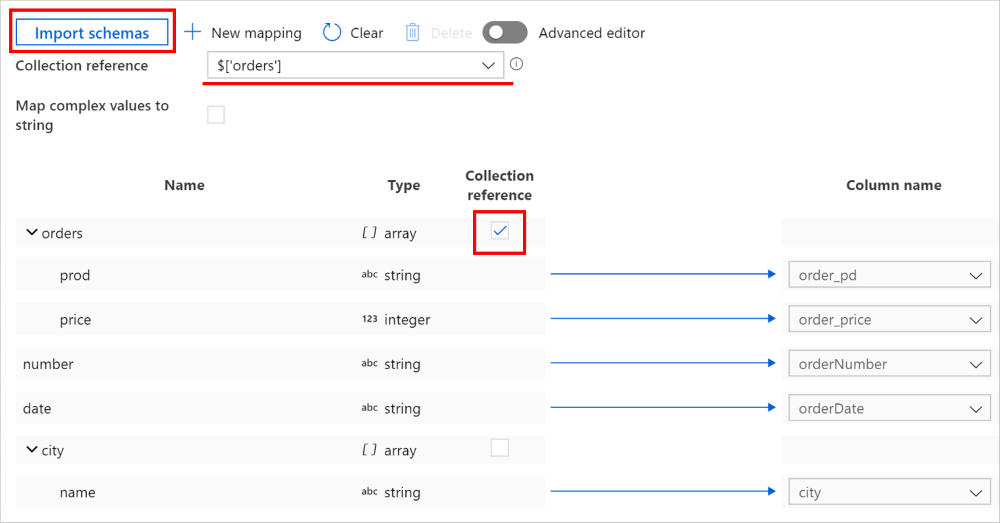
Dans activité de copie -> onglet de mappage, cliquez sur le bouton Importer les schémas pour importer les schémas source et récepteur. Comme le service échantillonne les quelques objets les plus importants lors de l’importation d’un schéma, si un champ n’apparaît pas, vous pouvez l’ajouter à la couche appropriée de la hiérarchie : pointez sur un nom de champ existant et choisissez d’ajouter un nœud, un objet ou un tableau.
Sélectionnez le tableau à partir duquel vous souhaitez effectuer une itération et extraire des données. Il sera automatiquement renseigné en tant que Référence de collection. Notez qu’un seul un tableau est pris en charge pour une telle opération.
Mappez les champs nécessaires au récepteur. Le service détermine automatiquement les chemins JSON correspondants pour le côté hiérarchique.
Notes
Pour les enregistrements où le tableau marqué comme référence de collection est vide alors que la case est cochée, l’enregistrement entier est ignoré.
Vous pouvez également basculer vers Éditeur avancé. Dans ce cas, vous pouvez afficher et modifier directement les chemins JSON des champs. Si vous choisissez d’ajouter un nouveau mappage dans cette vue, spécifiez le chemin JSON.
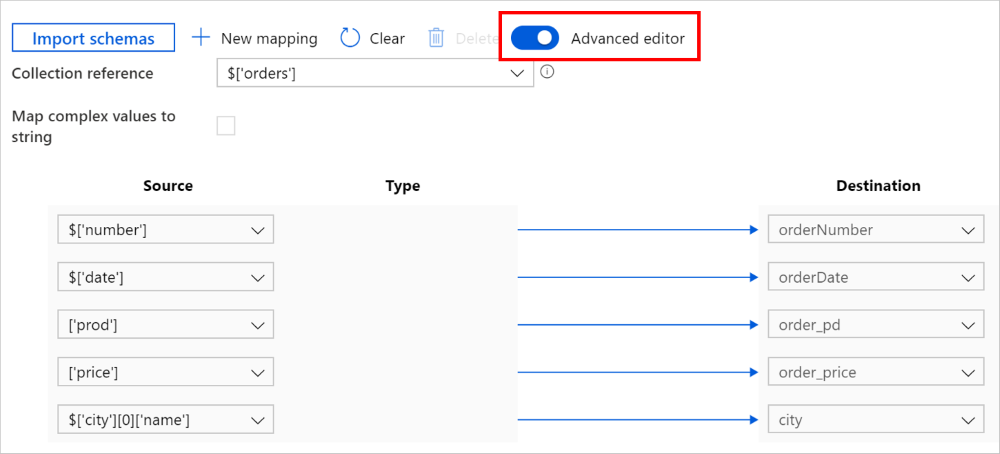
Le même mappage peut être configuré comme suit dans la charge utile de l’activité de copie (voir translator) :
{
"name": "CopyActivityHierarchicalToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "MongoDbV2Source" },
"sink": { "type": "DelimitedTextSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "path": "$['number']" },
"sink": { "name": "orderNumber" }
},
{
"source": { "path": "$['date']" },
"sink": { "name": "orderDate" }
},
{
"source": { "path": "['prod']" },
"sink": { "name": "order_pd" }
},
{
"source": { "path": "['price']" },
"sink": { "name": "order_price" }
},
{
"source": { "path": "$['city'][0]['name']" },
"sink": { "name": "city" }
}
],
"collectionReference": "$['orders']"
}
},
...
}
De la source tabulaire/hiérarchique vers le récepteur hiérarchique
Le flux de l’expérience utilisateur est similaire à De la source hiérarchique vers le récepteur tabulaire.
Lors de la copie de données d’une source tabulaire vers un récepteur hiérarchique, l’écriture dans un tableau à l’intérieur de l’objet n’est pas prise en charge.
Lorsque vous copiez des données à partir d’une source hiérarchique vers un récepteur hiérarchique, vous pouvez également conserver la hiérarchie de la couche entière en sélectionnant l’objet/le tableau et mapper au récepteur sans toucher aux champs internes.
Pour une transformation de remodelage plus avancée des données, vous pouvez utiliser Data Flow.
Paramétrer le mappage
Si vous souhaitez créer un pipeline modélisé pour copier dynamiquement un grand nombre d’objets, déterminez si vous pouvez tirer parti du mappage par défaut ou si vous devez définir un mappage explicite pour les objets respectifs.
Si vous avez besoin d’un mappage explicite, vous pouvez procéder comme suit :
Définir un paramètre avec le type d’objet au niveau du pipeline, par exemple,
mapping.Paramétrer le mappage : sur activité de copie -> onglet de mappage, choisissez d’ajouter du contenu dynamique et sélectionnez le paramètre ci-dessus. La charge utile d’activité serait la suivante :
{ "name": "CopyActivityHierarchicalToTabular", "type": "Copy", "typeProperties": { "source": {...}, "sink": {...}, "translator": { "value": "@pipeline().parameters.mapping", "type": "Expression" }, ... } }Construisez la valeur à transférer dans le paramètre de mappage. Il doit s’agir de l’intégralité de l’objet de la définition de
translator, reportez-vous aux échantillons dans la section de mappage explicite. Par exemple, pour la copie de la source tabulaire vers le récepteur tabulaire, la valeur doit être{"type":"TabularTranslator","mappings":[{"source":{"name":"Id"},"sink":{"name":"CustomerID"}},{"source":{"name":"Name"},"sink":{"name":"LastName"}},{"source":{"name":"LastModifiedDate"},"sink":{"name":"ModifiedDate"}}]}.
Mappage de types de données
L’activité de copie effectue un mappage des types de la source aux types du récepteur selon le flux suivant :
- Conversion de types de données natifs sources en types de données intermédiaires utilisés par les pipelines Azure Data Factory et Synapse.
- Conversion automatique du type de données intermédiaire en fonction des besoins pour les adapter aux types de récepteurs correspondants. Ceci est applicable à la fois au mappage par défaut et au mappage explicite.
- Conversion de types de données intermédiaires en types de données natifs de récepteur.
L’activité de copie prend actuellement en charge les types de données intermédiaires suivants : Boolean, Byte, Byte array, Datetime, DatetimeOffset, Decimal, Double, GUID, Int16, Int32, Int64, SByte, Single, String, Timespan, UInt16, UInt32 et UInt64.
Les conversions de types de données suivantes sont prises en charge entre les types intermédiaires de la source au récepteur.
| Source\Récepteur | Boolean | Tableau d’octets | Date/Heure | Décimal | Virgule flottante | GUID | Entier | Chaîne | TimeSpan |
|---|---|---|---|---|---|---|---|---|---|
| Boolean | ✓ | ✓ | ✓ | ✓ | |||||
| Tableau d’octets | ✓ | ✓ | |||||||
| Date/Heure | ✓ | ✓ | |||||||
| Decimal | ✓ | ✓ | ✓ | ✓ | |||||
| Virgule flottante | ✓ | ✓ | ✓ | ✓ | |||||
| GUID | ✓ | ✓ | |||||||
| Integer | ✓ | ✓ | ✓ | ✓ | |||||
| String | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| TimeSpan | ✓ | ✓ |
(1) Date/Heure inclut DateTime et DateTimeOffset.
(2) Virgule flottante inclut Simple et Double.
(3) Integer inclut SByte, Byte, Int16, UInt16, Int32, UInt32, Int64 et UInt64.
Notes
- Cette conversion de type de données est actuellement prise en charge lors de la copie entre des données tabulaires. Les sources/récepteurs hiérarchiques ne sont pas pris en charge, ce qui signifie qu’il n’existe aucune conversion de type de données définie par le système entre les types intermédiaires source et récepteur.
- Cette fonctionnalité fonctionne avec le modèle de jeu de données le plus récent. Si vous ne voyez pas cette option dans l’interface utilisateur, essayez de créer un nouveau jeu de données.
Les propriétés suivantes sont prises en charge dans l’activité de copie pour la conversion de types de données (sous translator section pour la création programmatique) :
| Propriété | Description | Obligatoire |
|---|---|---|
| typeConversion | Activez la nouvelle expérience de conversion de type de données. La valeur par défaut est false en raison de la compatibilité descendante. Pour les nouvelles activités de copie créées via l’interface utilisateur de création de Data Factory depuis la fin juin 2020, cette conversion de type de données est activée par défaut pour une expérience optimale. Vous pouvez voir les paramètres de conversion de type suivants sur activité de copie -> onglet de mappage pour les scénarios applicables. Pour créer un pipeline programmatiquement, vous devez définir explicitement la propriété typeConversion sur true pour l’activer.Pour les activités de copie existantes créées avant la publication de cette fonctionnalité, vous ne verrez pas les options de conversion de type sur l’interface utilisateur de création pour la compatibilité descendante. |
Non |
| typeConversionSettings | Groupe de paramètres de conversion de type. Appliquer lorsque typeConversion a la valeur true. Les propriétés suivantes sont toutes sous ce groupe. |
Non |
Sous : typeConversionSettings |
||
| allowDataTruncation | Autorisez la troncation des données lors de la conversion des données sources en récepteur avec un type différent pendant la copie, par exemple, de décimal à entier, de DatetimeOffset à DateTime. La valeur par défaut est true. |
Non |
| treatBooleanAsNumber | Traitez les valeurs booléennes comme des nombres, par exemple true comme 1. La valeur par défaut est false. |
Non |
| dateTimeFormat | Chaîne de format lors de la conversion entre des dates sans décalage de fuseau horaire et des chaînes, par exemple, yyyy-MM-dd HH:mm:ss.fff. Reportez-vous à Chaînes de format Date et Heure personnalisées pour obtenir des informations détaillées. |
Non |
| dateTimeOffsetFormat | Chaîne de format lors de la conversion entre des dates avec décalage de fuseau horaire et des chaînes, par exemple, yyyy-MM-dd HH:mm:ss.fff zzz. Reportez-vous à Chaînes de format Date et Heure personnalisées pour obtenir des informations détaillées. |
Non |
| timeSpanFormat | Chaîne de format lors de la conversion entre des périodes de temps et des chaînes, par exemple, dd\.hh\:mm. Reportez-vous à Chaînes de format TimeSpan personnalisées pour obtenir des informations détaillées. |
Non |
| culture | Informations concernant la culture à utiliser lors de la conversion de types, par exemple, en-us ou fr-fr. |
Non |
Exemple :
{
"name": "CopyActivity",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ParquetSource"
},
"sink": {
"type": "SqlSink"
},
"translator": {
"type": "TabularTranslator",
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": true,
"dateTimeFormat": "yyyy-MM-dd HH:mm:ss.fff",
"dateTimeOffsetFormat": "yyyy-MM-dd HH:mm:ss.fff zzz",
"timeSpanFormat": "dd\.hh\:mm",
"culture": "en-gb"
}
}
},
...
}
Modèles hérités
Notes
Les modèles suivants pour mapper des colonnes/champs sources vers un récepteur sont toujours pris en charge tels quels à des fins de compatibilité descendante. Nous vous suggérons d’utiliser le nouveau modèle mentionné dans mappage de schéma. L’interface utilisateur de création a basculé vers la génération du nouveau modèle.
Autre mappage de colonnes (modèle hérité)
Vous pouvez spécifier l’activité de copie ->translator ->columnMappings pour le mappage entre les données mises en forme tabulaire. Dans ce cas, la section « structure » est requise pour les jeux de données d’entrée et de sortie. Le mappage de colonnes prend en charge le mappage de la totalité ou d’un sous-ensemble des colonnes de la « structure » du jeu de données de la source à toutes les colonnes de la « structure » du jeu de données du récepteur. Voici une liste de conditions d’erreur qui entraînent la levée d’une exception :
- Le résultat de la requête de banque de données source n’a pas de nom de colonne spécifié dans la section « structure » du jeu de données d’entrée.
- La banque de données du récepteur (si un schéma est prédéfini) n’a pas de nom de colonne spécifié dans la section « structure » du jeu de données de sortie.
- La « structure » du jeu de données du récepteur contient un nombre de colonnes inférieur ou supérieur à celui spécifié par le mappage.
- Mappage en double.
Dans l’exemple suivant, le jeu de données d’entrée possède une structure et pointe vers une table dans une base de données Oracle locale.
{
"name": "OracleDataset",
"properties": {
"structure":
[
{ "name": "UserId"},
{ "name": "Name"},
{ "name": "Group"}
],
"type": "OracleTable",
"linkedServiceName": {
"referenceName": "OracleLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SourceTable"
}
}
}
Dans cet exemple, le jeu de données de sortie a une structure et pointe vers une table dans Salesforce.
{
"name": "SalesforceDataset",
"properties": {
"structure":
[
{ "name": "MyUserId"},
{ "name": "MyName" },
{ "name": "MyGroup"}
],
"type": "SalesforceObject",
"linkedServiceName": {
"referenceName": "SalesforceLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SinkTable"
}
}
}
Le JSON suivant définit une activité de copie dans un pipeline. Les colonnes de la source sont mappées aux colonnes dans le récepteur en utilisant la propriété translator ->columnMappings.
{
"name": "CopyActivity",
"type": "Copy",
"inputs": [
{
"referenceName": "OracleDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "SalesforceDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": { "type": "OracleSource" },
"sink": { "type": "SalesforceSink" },
"translator":
{
"type": "TabularTranslator",
"columnMappings":
{
"UserId": "MyUserId",
"Group": "MyGroup",
"Name": "MyName"
}
}
}
}
Si vous utilisiez la syntaxe de "columnMappings": "UserId: MyUserId, Group: MyGroup, Name: MyName" pour spécifier le mappage de colonnes, il est toujours pris en charge tel quel.
Autre mappage de schéma (modèle hérité)
Vous pouvez spécifier l’activité de copie ->translator ->schemaMapping pour mapper entre des données au format hiérarchique et tabulaire, par exemple la copie à partir de MongoDB/REST vers un fichier texte et la copie à partir d’Oracle vers Azure Cosmos DB for MongoDB. Les propriétés suivantes sont prises en charge dans la section translator de l’activité de copie :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du traducteur d’activité de copie doit être définie sur : TabularTranslator | Oui |
| schemaMapping | Une collection de paires clé-valeur, qui représente la relation de mappage du côté source au côté récepteur. - Clé : représente la source. Pour une source tabulaire, spécifiez le nom de colonne tel que défini dans la structure du jeu de données ; pour une source hiérarchique, spécifiez l’expression de chemin JSON pour chaque champ à extraire et mapper. - Valeur : représente le récepteur. Pour un récepteur tabulaire, spécifiez le nom de colonne tel que défini dans la structure du jeu de données ; pour un récepteur hiérarchique, spécifiez l’expression de chemin JSON pour chaque champ à extraire et mapper. Dans le cas de données hiérarchiques, pour les champs situés sous l’objet racine, le chemin JSON commence par $ racine ; pour ceux qui se trouvent dans le tableau sélectionné par la propriété collectionReference, le chemin JSON commence par l’élément de tableau. |
Oui |
| collectionReference | Si vous souhaitez effectuer une itération et extraire des données à partir des objets situés à l’intérieur d’un champ de tableau présentant le même modèle et effectuer une conversion par ligne et par objet, spécifiez le chemin JSON de ce tableau afin d’effectuer une application croisée. Cette propriété est prise en charge uniquement quand des données hiérarchiques sont la source. | Non |
Exemple : copier à partir de MongoDB vers Oracle :
Par exemple, si vous avez un document MongoDB avec le contenu suivant :
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
Vous souhaitez copier ce fichier dans une table SQL Azure au format suivant, en mettant à plat les données se trouvant dans le tableau (order_pd and order_price) et en effectuant une jointure croisée avec les informations racines communes (numéro, date et ville) :
| orderNumber | orderDate | order_pd | order_price | city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
Configurez la règle de mappage de schéma comme l’exemple JSON d’activité de copie suivant :
{
"name": "CopyFromMongoDBToOracle",
"type": "Copy",
"typeProperties": {
"source": {
"type": "MongoDbV2Source"
},
"sink": {
"type": "OracleSink"
},
"translator": {
"type": "TabularTranslator",
"schemaMapping": {
"$.number": "orderNumber",
"$.date": "orderDate",
"prod": "order_pd",
"price": "order_price",
"$.city[0].name": "city"
},
"collectionReference": "$.orders"
}
}
}
Contenu connexe
Voir les autres articles relatifs à l’activité de copie :