Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Data Factory dans Microsoft Fabric est la prochaine génération de Azure Data Factory, avec une architecture plus simple, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'intégration des données, commencez par Fabric Data Factory. Les charges de travail ADF existantes peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
L’outil Copy Data facilite et optimise le processus d'ingestion des données dans un lac de données, qui est généralement la première étape d'un scénario d’intégration de données de bout en bout. Il permet de gagner du temps, surtout lorsque vous utilisez le service pour réceptionner des données à partir d’une source de données pour la première fois. Voici certains des avantages de l’utilisation de cet outil :
- Lorsque vous utilisez l’outil Copier des données, vous n’avez pas besoin de comprendre les définitions de service pour les services liés, les jeux de données, les pipelines, les activités et les déclencheurs.
- Le flux de l’outil de copie de données est intuitif pour le chargement des données dans le lac de données. L’outil crée automatiquement toutes les ressources nécessaires pour copier des données depuis le magasin de données source sélectionné vers le magasin de données de destination/récepteur sélectionné.
- L’outil de copie des données vous permet de valider les données ingérées lors de la création, ce qui aide à éviter toute erreur potentielle dès le départ.
- Si vous devez implémenter une logique métier complexe pour charger des données dans Data Lake, vous pouvez toujours modifier les ressources créées par l’outil Copier des données à l’aide de la création par activité dans l’interface utilisateur.
Le tableau suivant fournit des instructions concernant l’utilisation de Copier des données par rapport à la création par activité dans l’interface utilisateur :
| Outil Copier des données | Création par activité (activité de copie) |
|---|---|
| Vous souhaitez créer facilement une tâche de chargement des données sans connaître en détail les entités (services, jeux de données, pipelines liés, etc.). | Vous souhaitez implémenter une logique complexe et flexible pour charger des données dans Data Lake. |
| Vous souhaitez charger rapidement un grand nombre d’artefacts de données dans Data Lake. | Vous souhaitez enchaîner l'activité de copie avec les activités suivantes pour le nettoyage ou le traitement des données. |
Pour démarrer l’outil Copier des données, sélectionnez la vignette Ingest sur la page d’accueil de l’interface utilisateur de Data Factory ou de Synapse Studio.
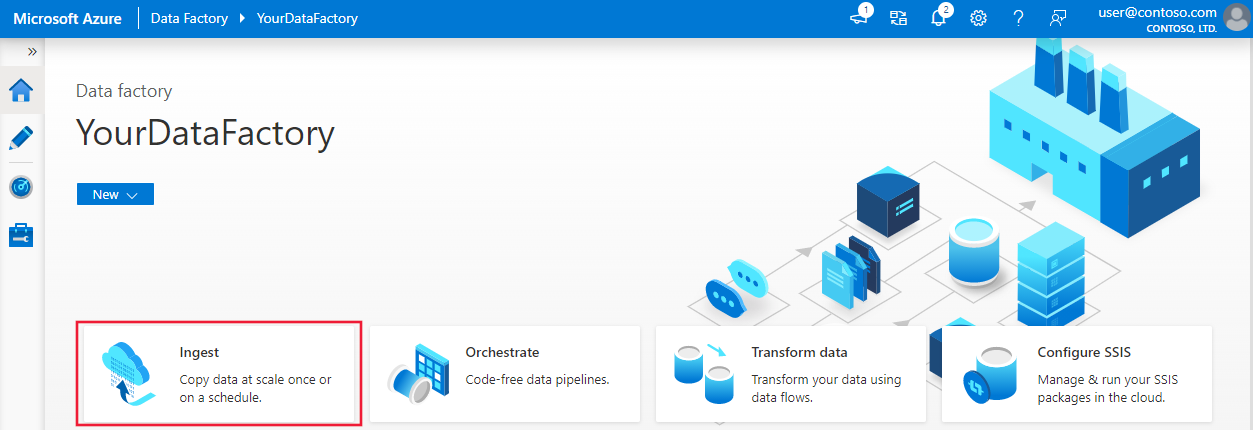
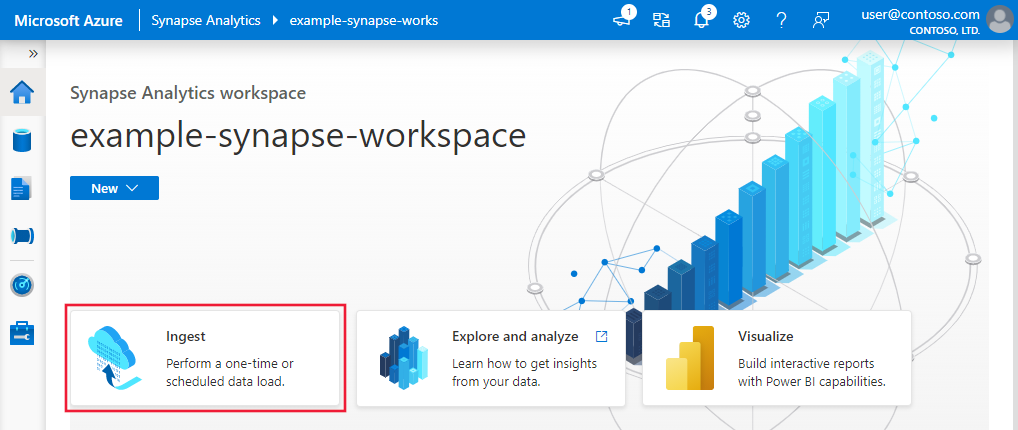
Une fois que vous avez lancé l’outil copier des données, vous verrez deux types de tâches : une tâche de copie intégrée et une autre est pilotée par les métadonnées. La tâche de copie intégrée vous permet de créer un pipeline en moins de cinq minutes pour répliquer les données sans en apprendre plus sur les entités. La tâche de copie basée sur les métadonnées facilite la création de pipelines paramétrables et d’une table de contrôle externe afin de pouvoir copier de grandes quantités d’objets (par exemple, des milliers de tables) à l’échelle. Vous pouvez voir plus de détails dans Copie de données basée sur les métadonnées.
Flux intuitif pour le chargement des données dans Data Lake
Cet outil vous permet de déplacer facilement et en quelques minutes des données provenant de nombreuses sources différentes vers des destinations, à l’aide d’un flux intuitif :
Configurez les paramètres pour la source.
Configurez les paramètres pour la destination.
Configurez les paramètres avancés pour l’opération de copie, notamment le mappage de colonnes, les paramètres de performances et les paramètres de tolérance de panne.
Spécifiez une planification pour les tâche de chargement des données.
Examinez le résumé des entités à créer.
Modifiez le pipeline pour mettre à jour les paramètres de l’activité de copie, selon les besoins.
La conception de l’outil est particulièrement adaptée au Big Data, avec la prise en charge de divers types d’objet et de données. Vous pouvez l’utiliser pour déplacer des centaines de dossiers, fichiers ou tables. L’outil prend en charge l’aperçu des données automatique, la capture et le mappage automatique de schéma, ainsi que le filtrage des données.
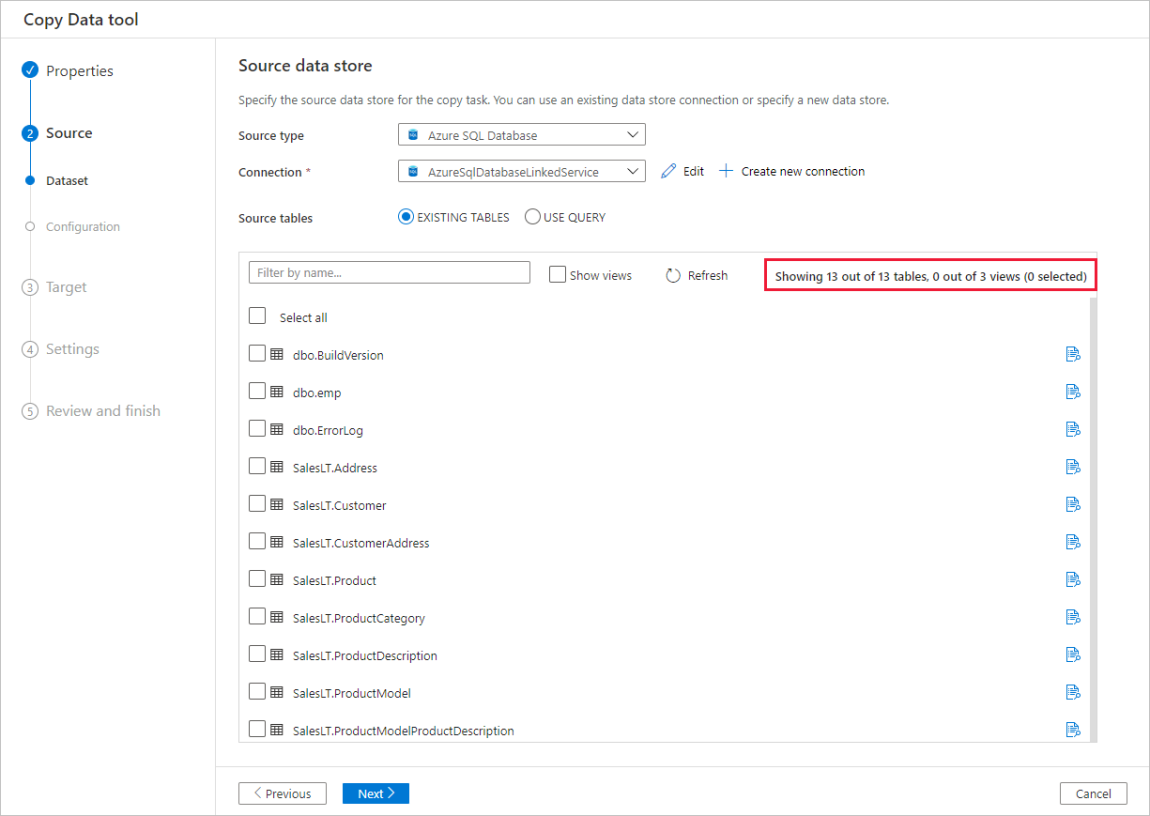
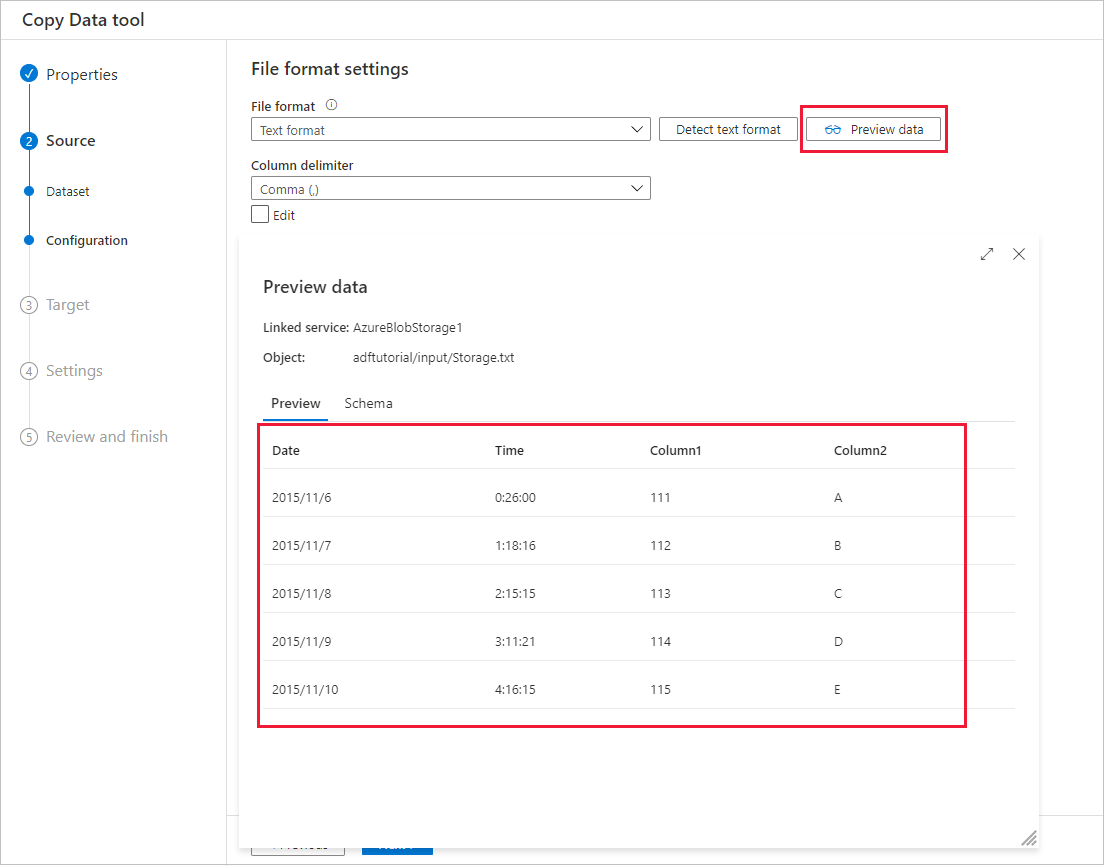
Aperçu des données automatique
Vous pouvez afficher un aperçu d’une partie des données à partir du magasin de données source sélectionné et valider ainsi les données copiées. En outre, si les données sources sont contenues dans un fichier texte, l’outil Copier des données analyse ce fichier pour détecter les délimiteurs de colonnes et de lignes ainsi que le schéma.
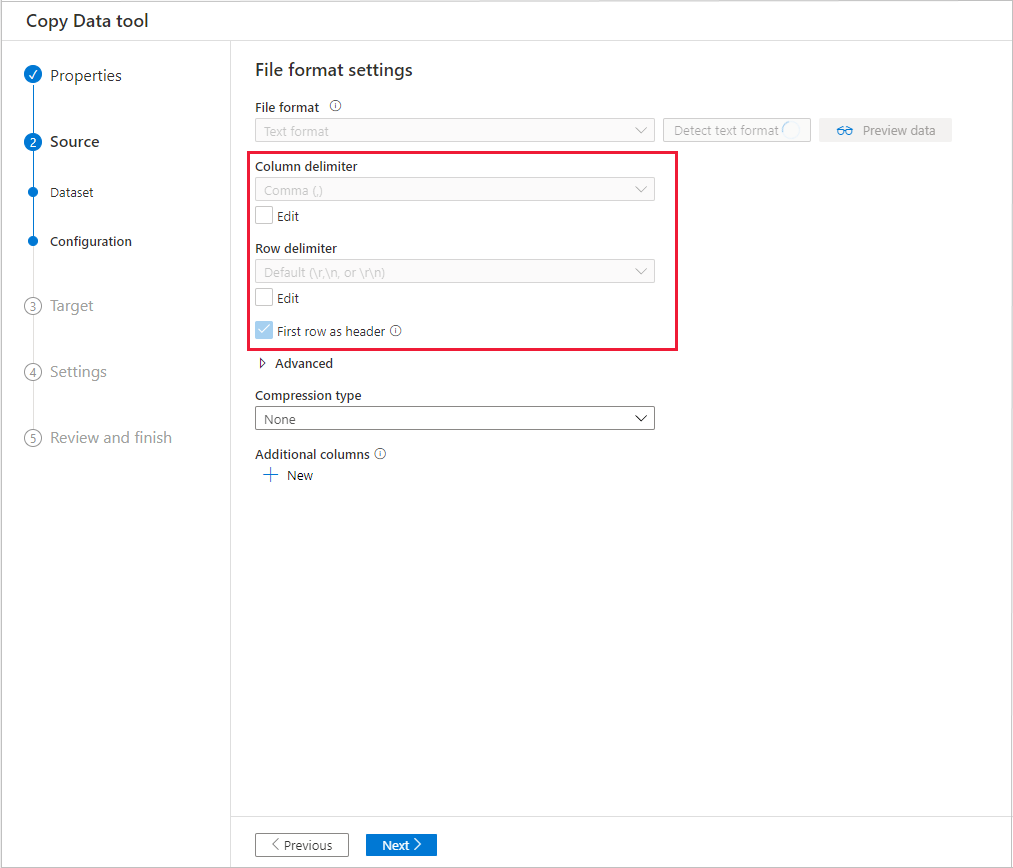
Après la détection, sélectionnez Aperçu des données:
Capture et mappage automatique du schéma
Souvent, le schéma de la source de données n’est peut-être pas identique au schéma de la destination de données. Le cas échéant, vous devez mapper les colonnes du schéma source aux colonnes du schéma de destination.
L'outil « Copier des données » surveille et apprend votre comportement lorsque vous mappez des colonnes entre les magasins source et destination. Après avoir sélectionné une ou plusieurs colonnes à partir du magasin de données source et les avoir mappées au schéma de destination, l’outil Copier des données commence à analyser le modèle pour les paires de colonnes que vous avez choisies des deux côtés. Il applique ensuite le même modèle aux autres colonnes. Par conséquent, vous voyez que toutes les colonnes ont été mappées vers la destination comme vous le souhaitez, et cela, en seulement quelques clics. Si vous n’êtes pas satisfait du choix de mappage de colonnes fourni par l’outil Copier des données, vous pouvez l’ignorer et continuer à mapper manuellement les colonnes. Pendant ce temps, l’outil Copier des données assimile et met à jour continuellement le modèle jusqu’à obtenir le modèle adapté au mappage de colonnes que vous voulez.
Note
Lors de la copie de données de SQL Server ou de Azure SQL Database dans Azure Synapse Analytics, si la table n'existe pas dans le magasin de destination, l'outil Copier les données prend en charge la création automatique de la table à l'aide du schéma source.
Filtrer les données
Vous pouvez filtrer les données sources pour sélectionner uniquement les données devant être copiées vers le magasin de données cible. Le filtrage réduit le volume des données à copier vers le magasin de données de récepteur et améliore de ce fait le débit de la copie. L’outil Copier des données fournit un moyen souple de filtrer les données dans une base de données relationnelle à l’aide du langage de requête SQL ou les fichiers d’un dossier d’objets blob Azure.
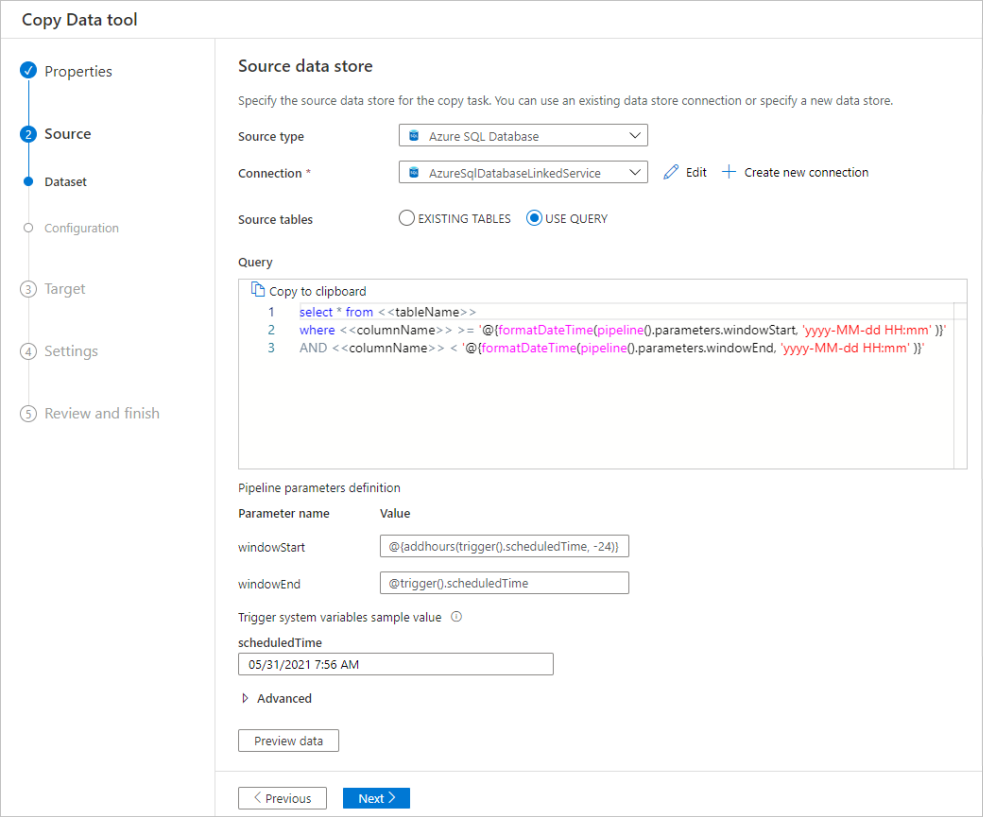
Filtrer les données d’une base de données
La capture d’écran suivante montre une requête SQL permettant de filtrer les données.
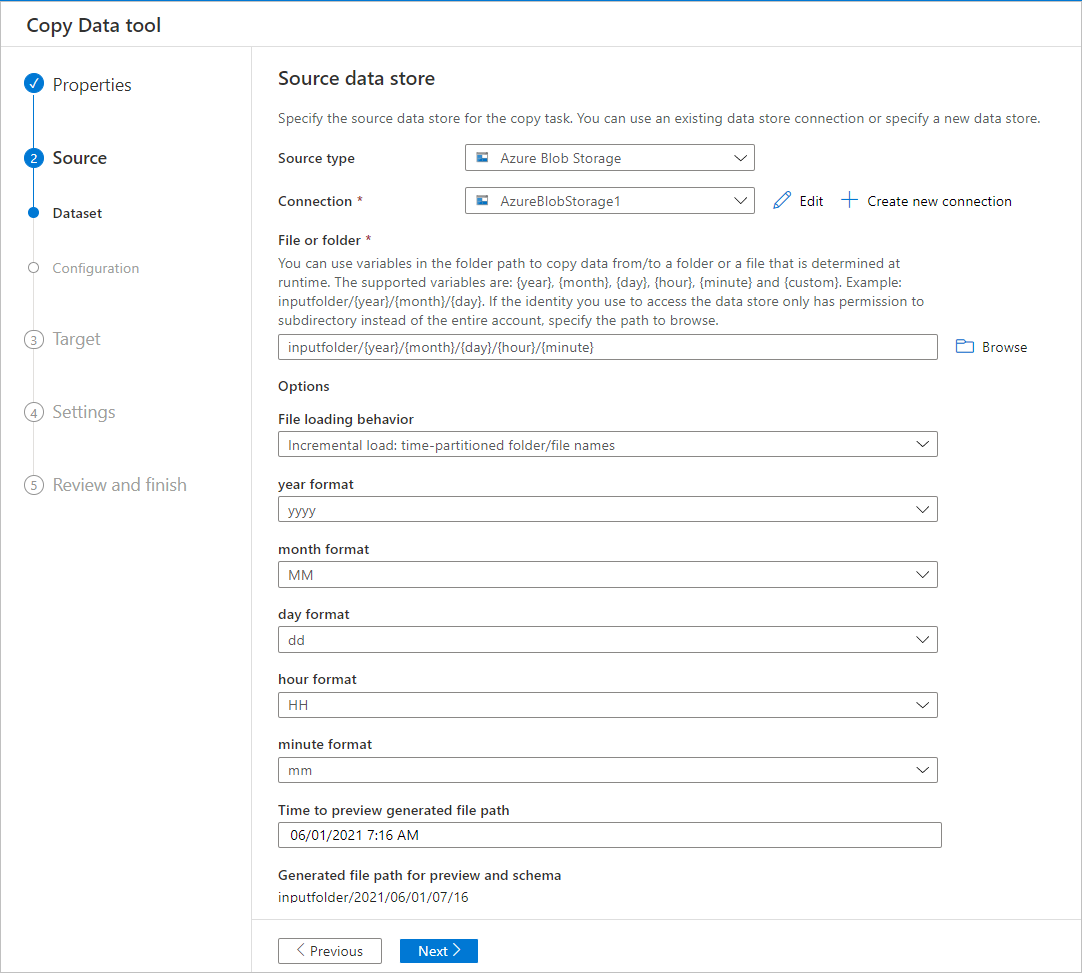
Filtrer les données dans un dossier d’objets blob Azure
Vous pouvez utiliser des variables dans le chemin d’accès au dossier pour copier des données à partir d’un dossier. Les variables prises en charge sont les suivantes : {year} , {month} , {day} , {hour} et {minute} . Exemple : inputfolder/{year}/{month}/{day}.
Supposons que vos dossiers d’entrée présentent le format suivant :
2016/03/01/01
2016/03/01/02
2016/03/01/03
...
Sélectionnez le bouton Parcourir pour fichier ou dossier, accédez à l’un de ces dossiers (par exemple, 2016-03-01-02>>>), puis sélectionnez Choisir. Vous devez voir 2016/03/01/02 dans la zone de texte.
Puis remplacez 2016 par {year} , 03 par {month} , 01 par {day} et 02 par {hour} , puis appuyez sur la touche de tabulation. Lorsque vous sélectionnez charge incrémentielle : noms de fichiers/dossiers partitionnés dans la section Comportement de chargement de fichier et sélectionnez Planification ou Fenêtre glissante sur la page Propriétés, vous devez voir les listes déroulantes pour sélectionner le format de ces quatre variables :
L’outil Copier des données génère des paramètres avec des expressions, fonctions et variables système qui peuvent être utilisés pour représenter les variables {year}, {month}, {day}, {hour} et {minute} lors de la création du pipeline.
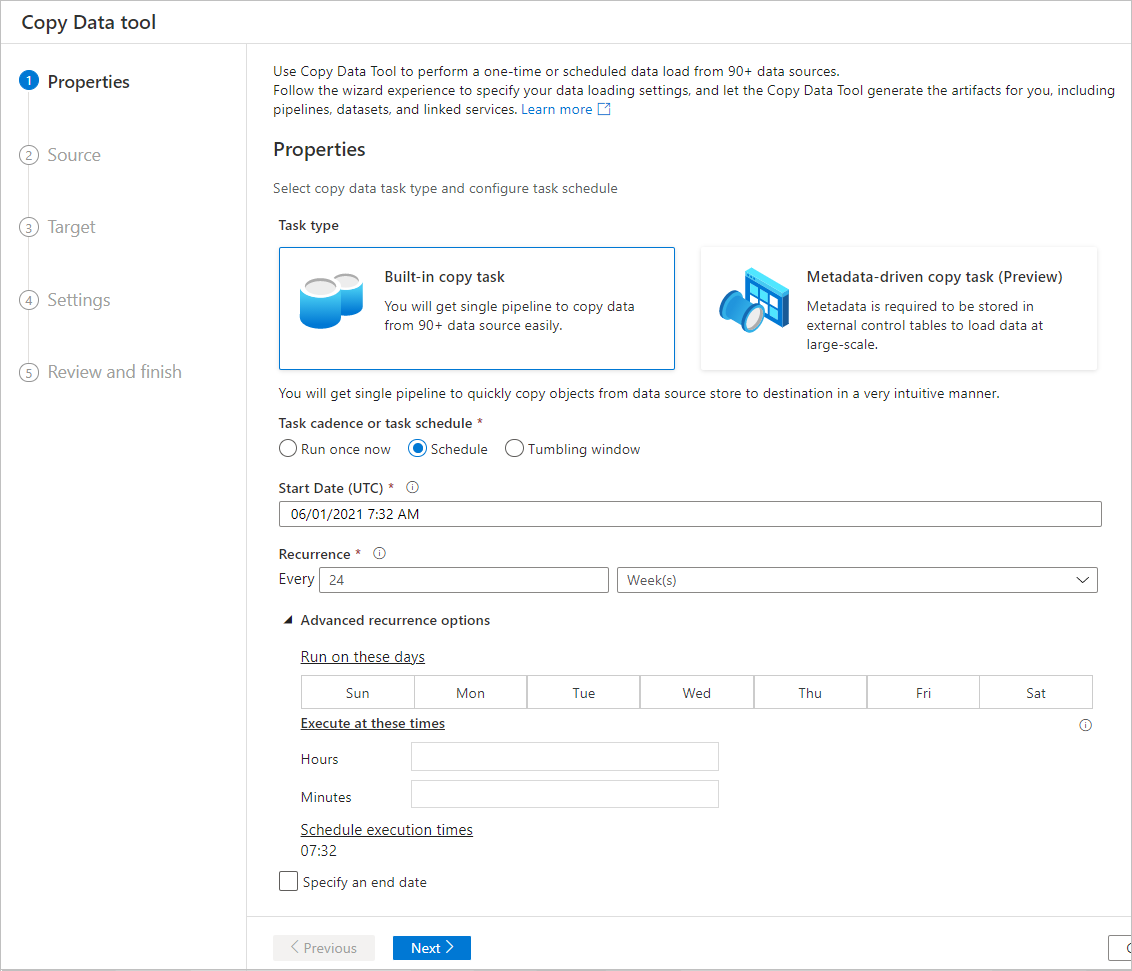
Options de planification
Vous pouvez effectuer l’opération de copie une seule fois ou la répéter selon une planification établie (horaire, quotidienne et ainsi de suite.). Ces options peuvent être utilisées pour les connecteurs entre différents environnements, notamment les environnements locaux, dans le cloud ou sur un bureau local.
Une opération de copie unique ne permet le déplacement des données à d’une source vers une destination qu’une seule fois. Elle s’applique aux données de toute taille et de n’importe quel format pris en charge. La copie planifiée vous permet de copier des données selon la récurrence de votre choix. Vous pouvez utiliser des paramètres enrichis (comme une nouvelle tentative, un délai d’attente et des alertes) pour configurer la copie planifiée.
Contenu connexe
Essayez ces didacticiels qui utilisent l’outil de copie de données :