Transformation de tri dans le flux de données de mappage
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Les flux de données sont disponibles à la fois dans les pipelines Azure Data Factory et Azure Synapse. Cet article s’applique aux flux de données de mappage. Si vous débutez dans le domaine des transformations, consultez l’article d’introduction Transformer des données avec un flux de données de mappage.
La transformation de tri permet de trier les lignes entrantes sur le flux de données actuel. Il est possible de sélectionner les colonnes une par une et de les trier par ordre croissant ou décroissant.
Notes
Les flux de données de mappage s’exécutent sur des clusters Spark qui distribuent les données entre plusieurs nœuds et partitions. Si vous choisissez de repartitionner vos données dans une transformation ultérieure, vous risquez de perdre le tri en raison de ce remaniement. La meilleure façon de conserver l’ordre de tri dans votre flux de données consiste à définir une partition unique sous l’onglet Optimiser de la transformation et à conserver la transformation de tri aussi proche que possible du récepteur.
Configuration
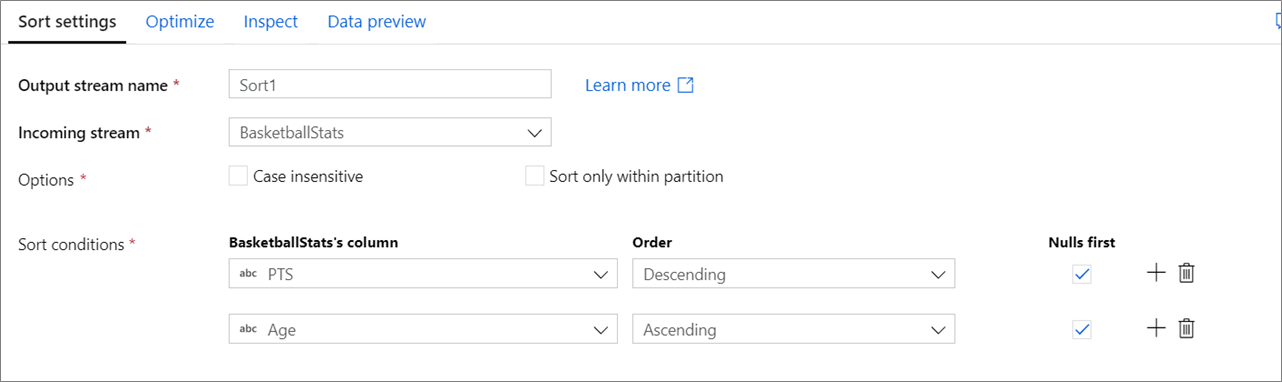
Insensible à la casse : si vous souhaitez ou non ignorer la casse lors du tri de champs de chaîne ou de texte.
Trier uniquement dans les partitions : chaque flux de données est divisé en partitions lors de son exécution sur Spark. Ce paramètre a pour effet de ne trier que les données des partitions entrantes, et non l’intégralité du flux de données.
Conditions de tri : choisissez les colonnes sur lesquelles porte le tri et l’ordre dans lequel il se produit. L’ordre détermine la priorité de tri. Indiquez si les valeurs Null s’affichent ou non au début et à la fin du flux de données.
Colonnes calculées
Pour modifier ou extraire une valeur de colonne avant d’appliquer le tri, placez le curseur sur la colonne et sélectionnez « colonne calculée ». Le générateur d’expressions qui s’ouvre permet de créer une expression pour l’opération de tri au lieu d’utiliser une valeur de colonne.
Script de flux de données
Syntaxe
<incomingStream>
sort(
desc(<sortColumn1>, { true | false }),
asc(<sortColumn2>, { true | false }),
...
) ~> <sortTransformationName<>
Exemple
Le flux de données correspondant à la configuration de tri ci-dessus est présenté dans l’extrait de code suivant.
BasketballStats sort(desc(PTS, true),
asc(Age, true)) ~> Sort1
Contenu connexe
Après le tri, vous souhaiterez peut-être utiliser la transformation d’agrégation