Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Data Factory dans Microsoft Fabric est la prochaine génération de Azure Data Factory, avec une architecture plus simple, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'intégration des données, commencez par Fabric Data Factory. Les charges de travail ADF existantes peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
L’activité Azure Databricks Notebook dans un pipeline exécute un notebook Databricks dans votre espace de travail Azure Databricks. Cet article s'appuie sur l'article Activités de transformation des données qui présente une vue d'ensemble de la transformation des données et les activités de transformation prises en charge. Azure Databricks est une plateforme managée pour l’exécution d’Apache Spark.
Vous pouvez créer un notebook Databricks avec un modèle ARM à l’aide de JSON ou directement via l’interface utilisateur Azure Data Factory Studio. Pour une procédure pas à pas sur la création d’une activité de notebook Databricks à l’aide de l’interface utilisateur, reportez-vous au didacticiel Exécuter un notebook Databricks avec l’activité Databricks Notebook dans Azure Data Factory.
Ajouter une activité Notebook pour Azure Databricks à un pipeline avec l’interface utilisateur
Pour utiliser une activité Notebook pour Azure Databricks dans un pipeline, procédez comme suit :
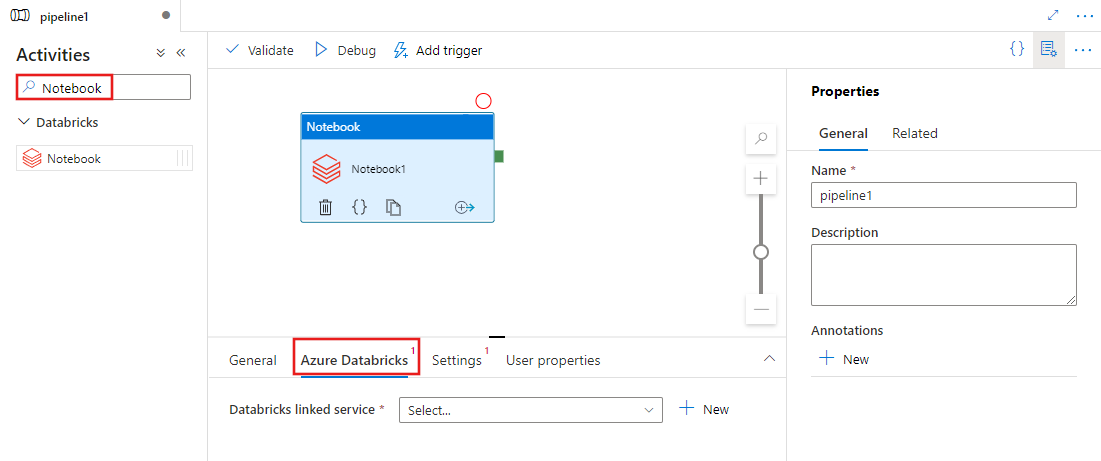
Recherchez Notebook dans le volet Activités de pipeline, puis faites glisser une activité Notebook vers le canevas du pipeline.
Sélectionnez la nouvelle activité Notebook sur le canevas si elle n'est pas déjà sélectionnée.
Sélectionnez l’onglet Azure Databricks pour sélectionner ou créer un service lié Azure Databricks qui exécutera l’activité notebook.
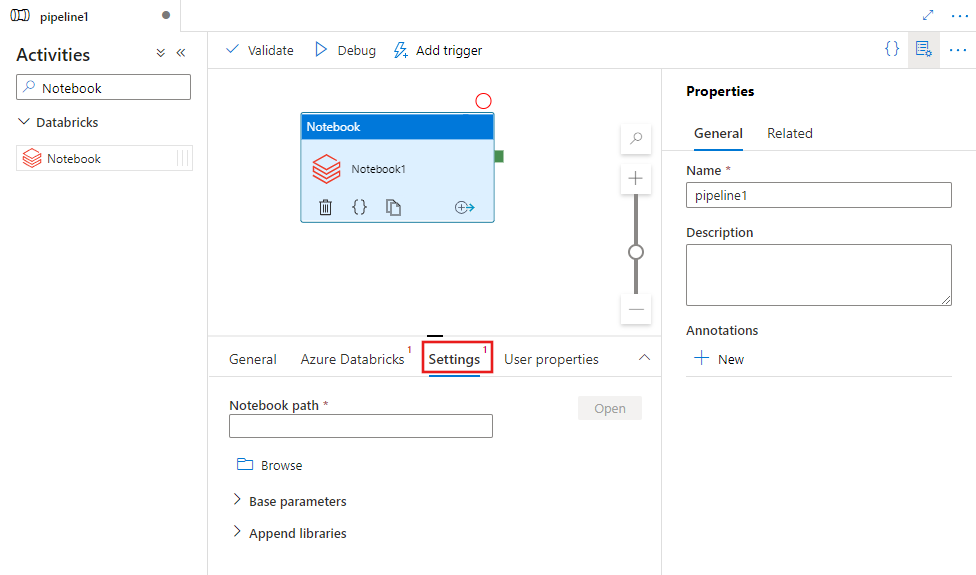
Sélectionnez l’onglet Settings et spécifiez le chemin d’accès du bloc-notes à exécuter sur Azure Databricks, les paramètres de base facultatifs à passer au bloc-notes et les autres bibliothèques à installer sur le cluster pour exécuter le travail.
Définition de l’activité Databricks Notebook
Voici l’exemple de définition JSON d’une activité Databricks Notebook :
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksNotebook",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedservice",
"type": "LinkedServiceReference"
},
"typeProperties": {
"notebookPath": "/Users/user@example.com/ScalaExampleNotebook",
"baseParameters": {
"inputpath": "input/folder1/",
"outputpath": "output/"
},
"libraries": [
{
"jar": "dbfs:/docs/library.jar"
}
]
}
}
}
Propriétés de l’activité Databricks Notebook
Le tableau suivant décrit les propriétés JSON utilisées dans la définition JSON :
| Propriété | Description | Obligatoire |
|---|---|---|
| nom | Nom de l'activité dans le pipeline. | Oui |
| description | Texte décrivant l’activité. | Non |
| type | Pour l’activité Databricks Notebook, le type d’activité est DatabricksNotebook. | Oui |
| linkedServiceName | Nom du service lié Databricks sur lequel s’exécute le bloc-notes Databricks. Pour en savoir plus sur ce service lié, consultez l’article Services liés de calcul. | Oui |
| notebookPath | Chemin absolu du notebook à exécuter dans l’espace de travail Databricks. Ce chemin doit commencer par une barre oblique. | Oui |
| paramètres de base | Tableau de paires clé-valeur. Des paramètres de base peuvent être utilisés pour chaque exécution d’activité. Si le notebook accepte un paramètre qui n’est pas spécifié, la valeur par défaut du notebook est utilisée. Pour obtenir d’autres paramètres, consultez Databricks Notebooks. | Non |
| bibliothèques | Liste de bibliothèques à installer sur le cluster qui exécute le travail. Il peut s’agir d’un tableau de <chaînes et objets>. | Non |
Bibliothèques prises en charge pour les activités Databricks
Dans la définition d’activité Databricks ci-dessus, vous précisez ces types de bibliothèques : jar, egg, whl, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"whl": "dbfs:/mnt/libraries/mlflow-0.0.1.dev0-py2-none-any.whl"
},
{
"whl": "dbfs:/mnt/libraries/wheel-libraries.wheelhouse.zip"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Pour plus d’informations, consultez la documentation Databricks pour les types de bibliothèques.
Transmission de paramètres entre des notebooks et des pipelines
Vous pouvez transmettre les paramètres à des notebooks en utilisant la propriété baseParameters dans l'activité Databricks.
Dans certains cas, il peut être nécessaire de retransmettre certaines valeurs du notebook vers le service. Celles-ci peuvent être utilisées pour le flux de contrôle (vérifications conditionnelles) dans le service ou être consommées par les activités situées en aval (taille maximale autorisée : 2 Mo).
Dans votre notebook, vous pouvez appeler dbutils.notebook.exit (« returnValue ») et la valeur « returnValue » correspondante sera renvoyée au service.
Vous pouvez consommer la sortie du service avec une expression telle que
@{activity('databricks notebook activity name').output.runOutput}.Important
Si vous transmettez un objet JSON, vous pouvez récupérer des valeurs en ajoutant des noms de propriété. Exemple :
@{activity('databricks notebook activity name').output.runOutput.PropertyName}
Comment charger une bibliothèque dans Databricks
Vous pouvez utiliser l’interface utilisateur de l’espace de travail :
Utiliser l’interface utilisateur de l’espace de travail Databricks
Pour obtenir le chemin dbfs de la bibliothèque ajoutée par le biais de l’interface utilisateur, vous pouvez utiliser l’interface CLI de Databricks.
En général, les bibliothèques Jar sont stockées sous dbfs:/FileStore/jars lors de l’utilisation de l’interface utilisateur. Vous pouvez répertorier toutes les éléments à l’aide de l’interface de ligne de commande (CLI) : databricks fs ls dbfs:/FileStore/job-jars
Vous pouvez utiliser l’interface CLI de Databricks :
Suivez Copier la bibliothèque avec l’interface CLI de Databricks.
Utilisez l’interface CLI de Databricks (étapes d’installation).
Par exemple, pour copier un fichier JAR sur dbfs :
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar