Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Data Factory dans Microsoft Fabric est la prochaine génération de Azure Data Factory, avec une architecture plus simple, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'intégration des données, commencez par Fabric Data Factory. Les charges de travail ADF existantes peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Exécutez vos pipelines Azure Machine Learning en tant qu’étape dans vos pipelines Azure Data Factory et Synapse Analytics. L’activité d’exécution de pipeline Machine Learning permet d’identifier les scénarios de prédiction par lots tels que l’identification des éventuels prêts par défaut, la détermination des sentiments et l’analyse des modèles de comportement des clients.
La vidéo ci-dessous, d’une durée de six minutes, comporte une présentation et une démonstration de cette fonctionnalité.
Créer une activité d’exécution de pipeline Machine Learning avec l’interface utilisateur
Pour utiliser une activité Execute Pipeline de Machine Learning dans un pipeline, effectuez les étapes suivantes :
Recherchez Machine Learning dans le volet Activités du pipeline, puis faites glisser une activité `Exécuter le pipeline` de Machine Learning vers le canevas du pipeline.
Sélectionnez la nouvelle activité Exécuter le pipeline de Machine Learning sur le canevas si elle n’est pas déjà sélectionnée, ainsi que son onglet Paramètres, pour modifier ses détails.
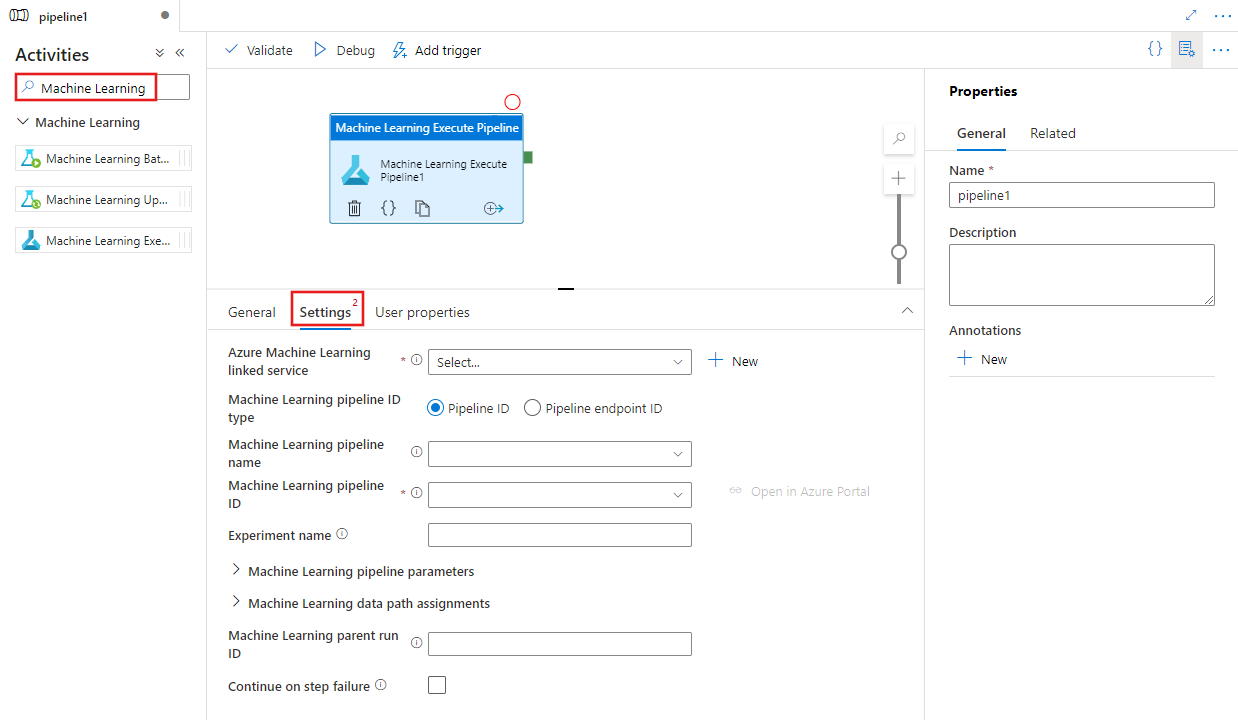
Sélectionnez un service lié Azure Machine Learning existant ou créez-en un, et fournissez des détails sur le pipeline et l’expérience, ainsi que les paramètres de pipeline ou les affectations de chemins de données requis pour le pipeline.
Syntaxe
{
"name": "Machine Learning Execute Pipeline",
"type": "AzureMLExecutePipeline",
"linkedServiceName": {
"referenceName": "AzureMLService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mlPipelineId": "machine learning pipeline ID",
"experimentName": "experimentName",
"mlPipelineParameters": {
"mlParameterName": "mlParameterValue"
}
}
}
Propriétés de type
| Propriété | Description | Valeurs autorisées | Obligatoire |
|---|---|---|---|
| nom | Nom de l’activité dans le pipeline | String | Oui |
| type | Le type d’activité est « AzureMLExecutePipeline ». | String | Oui |
| linkedServiceName | Service lié à Azure Machine Learning | référence de service lié | Oui |
| mlPipelineId | ID du pipeline de Azure Machine Learning publié | Chaîne (ou expression avec resultType de chaîne) | Oui |
| experimentNom | Nom de l’expérience de l’historique des exécutions pour l’exécution du pipeline Machine Learning | Chaîne (ou expression avec resultType de chaîne) | Non |
| mlPipelineParameters | Paires clé/valeur à passer au point de terminaison du pipeline Azure Machine Learning publié. Les clés doivent correspondre aux noms des paramètres de pipeline définis dans le pipeline de Machine Learning publié | Objet avec des paires clé/valeur (ou expression avec l’objet resultType) | Non |
| mlParentRunId | ID d’exécution du pipeline Azure Machine Learning parent | Chaîne (ou expression avec resultType de chaîne) | Non |
| dataPathAssignments | Dictionnaire utilisé pour modifier les chemins de données dans Azure Machine Learning. Permet la commutation des chemins de données | Objet avec des paires clé/valeur | Non |
| continueOnStepFailure | Continuer l’exécution d’autres étapes dans le pipeline Machine Learning en cas d’échec d’une étape | booléen | Non |
Note
Pour pouvoir remplir les éléments déroulants du nom et de l’ID du pipeline Machine Learning, l’utilisateur doit avoir l’autorisation de lister les pipelines ML. L’interface utilisateur appelle directement les API AzureMLService à l’aide des informations d’identification de l’utilisateur connecté. Le temps de découverte des éléments déroulants serait beaucoup plus long lors de l’utilisation de points de terminaison privés.
Contenu connexe
Consultez les articles suivants qui expliquent comment transformer des données par d’autres moyens :