Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Data Factory dans Microsoft Fabric est la prochaine génération de Azure Data Factory, avec une architecture plus simple, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'intégration des données, commencez par Fabric Data Factory. Les charges de travail ADF existantes peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
L'activité Spark dans une fabrique de données et dans des pipelines Synapse exécute un programme Spark sur votre propre cluster ou sur un cluster HDInsight à la demande. Cet article s'appuie sur l'article Activités de transformation des données qui présente une vue d'ensemble de la transformation des données et les activités de transformation prises en charge. Quand vous utilisez un service lié Spark à la demande, le service crée automatiquement un cluster Spark pour vous, juste le temps nécessaire pour traiter les données, puis il le supprime une fois le traitement terminé.
Ajouter une activité Spark à un pipeline avec l’interface utilisateur
Pour utiliser une activité Spark dans un pipeline, effectuez les étapes suivantes :
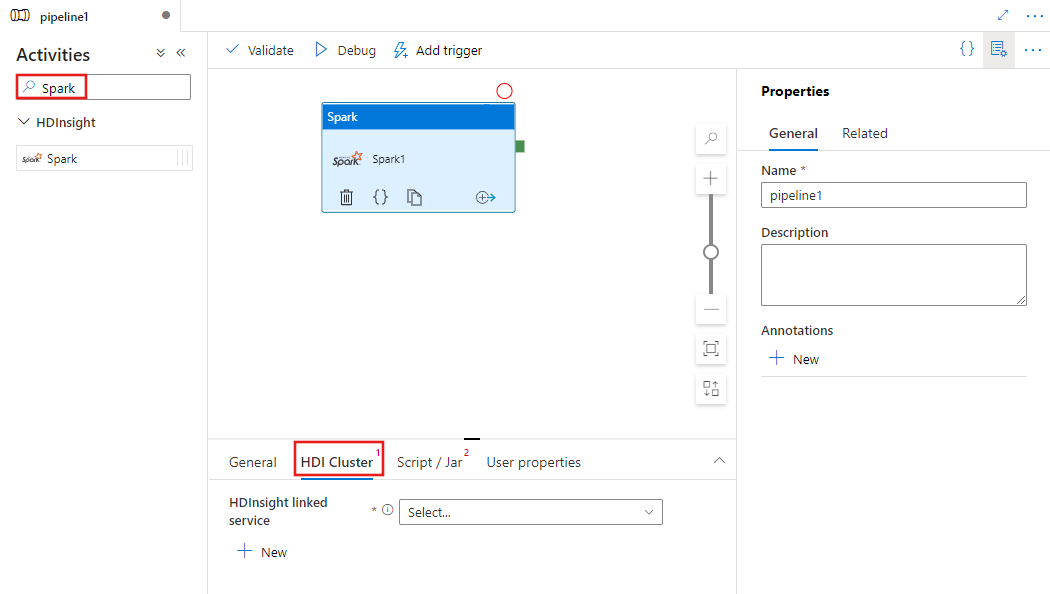
Recherchez Spark dans le volet Activités du pipeline, puis faites glisser une activité Spark vers le canevas du pipeline.
Sélectionnez la nouvelle activité Spark sur le canevas si elle n’est pas déjà sélectionnée.
Sélectionnez l’onglet Cluster HDI pour sélectionner ou créer un nouveau service lié à un cluster HDInsight qui sera utilisé pour exécuter l’activité Spark.
Sélectionnez l’onglet Script/Jar pour sélectionner ou créer un service lié de travail à un compte stockage Azure qui hébergera votre script. Spécifiez un chemin d’accès au fichier à exécuter ici. Vous pouvez également configurer des détails avancés, notamment un utilisateur proxy, une configuration de débogage et des arguments et des paramètres de configuration Spark à transmettre au script.
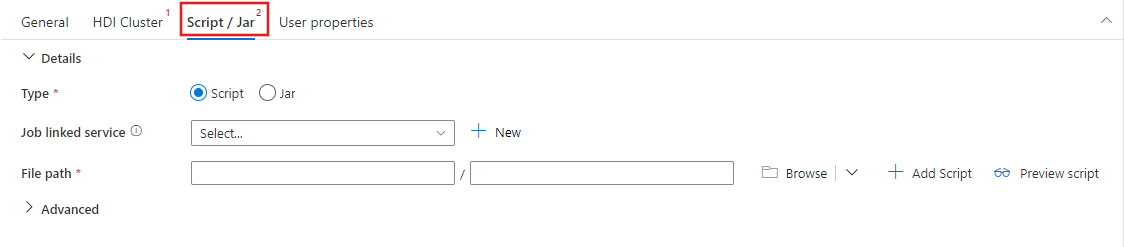
Propriétés de l'activité Spark
Voici l’exemple de définition JSON d’une activité Spark :
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
Le tableau suivant décrit les propriétés JSON utilisées dans la définition JSON :
| Propriété | Description | Obligatoire |
|---|---|---|
| nom | Nom de l'activité dans le pipeline. | Oui |
| description | Texte décrivant l’activité. | Non |
| type | Pour l’activité Spark, le type d’activité est HDinsightSpark. | Oui |
| linkedServiceName | Nom du service lié HDInsight Spark sur lequel s’exécute le programme Spark. Pour en savoir plus sur ce service lié, consultez l’article Services liés de calcul. | Oui |
| SparkJobLinkedService | Service lié de stockage Azure qui contient le fichier de travail, les dépendances et les journaux d’activité Spark. Seuls Stockage Blob Azure et ADLS Gen2 services liés sont pris en charge ici. Si vous ne spécifiez pas de valeur pour cette propriété, le stockage associé au cluster HDInsight est utilisé. La valeur de cette propriété ne peut être qu'un service lié à stockage Azure. | Non |
| chemin racine | Conteneur et répertoire Azure Blob qui contient le fichier Spark. Le nom de fichier respecte la casse. Reportez-vous à la section décrivant la structure des dossiers (section suivante) pour obtenir plus d’informations sur la structure de ce dossier. | Oui |
| entryFilePath | Chemin d’accès relatif au dossier racine du code/package Spark. Le fichier d’entrée doit être un fichier Python ou un fichier .jar. | Oui |
| className | Classe principale Java/Spark de l'application | Non |
| arguments | Liste d’arguments de ligne de commande du programme Spark. | Non |
| proxyUser | Identité du compte d'utilisateur à usurper afin d'exécuter le programme Spark. | Non |
| sparkConfig | Spécifiez les valeurs des propriétés de configuration de Spark listées dans la rubrique : Configuration Spark - Propriétés de l’application. | Non |
| getDebugInfo | Spécifie quand les fichiers journaux Spark sont copiés dans le stockage Azure utilisé par le cluster HDInsight (ou) spécifié par sparkJobLinkedService. Valeurs autorisées : Aucun, Toujours ou Échec. Valeur par défaut : Aucun. | Non |
Structure de dossiers
Les tâches Spark sont plus extensibles que les tâches Pig/Hive. Pour les travaux Spark, vous pouvez fournir plusieurs dépendances telles que des packages jar (placés dans la Java CLASSPATH), des fichiers Python (placés sur PYTHONPATH) et d’autres fichiers.
Créez la structure de dossiers suivante dans le Azure Stockage Blob référencé par le service lié HDInsight. Ensuite, téléchargez les fichiers dépendants dans les sous-dossiers appropriés dans le dossier racine représenté par entryFilePath. Par exemple, chargez les fichiers Python dans le sous-dossier pyFiles et les fichiers jar dans le sous-dossier jars du dossier racine. Au moment de l’exécution, le service attend la structure de dossiers suivante dans le stockage Blob Azure :
| Chemin | Description | Obligatoire | Type |
|---|---|---|---|
. (racine) |
Chemin d’accès racine du travail Spark dans le service lié de stockage | Oui | Dossier |
| <défini par l’utilisateur > | Chemin d’accès pointant vers le fichier d’entrée du travail Spark | Oui | Fichier |
| ./jars | Tous les fichiers sous ce dossier sont chargés et placés sur le chemin de classe Java du cluster | Non | Dossier |
| ./pyFiles | Tous les fichiers dans ce dossier sont téléchargés et placés dans le PYTHONPATH du cluster | Non | Dossier |
| ./files | Tous les fichiers dans ce dossier sont téléchargés et placés dans le répertoire de travail de l’exécuteur | Non | Dossier |
| ./archives | Tous les fichiers dans ce dossier ne sont pas compressés | Non | Dossier |
| ./logs | Dossier qui contient les journaux d’activité à partir du cluster Spark. | Non | Dossier |
Voici un exemple de stockage contenant deux fichiers de travail Spark dans le Stockage Blob Azure référencé par le service lié HDInsight.
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
Contenu connexe
Consultez les articles suivants qui expliquent comment transformer des données par d’autres moyens :