Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Data Factory dans Microsoft Fabric est la prochaine génération de Azure Data Factory, avec une architecture plus simple, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'intégration des données, commencez par Fabric Data Factory. Les charges de travail ADF existantes peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Un pipeline dans un espace de travail Azure Data Factory ou Synapse Analytics traite les données dans les services de stockage liés à l’aide de services de calcul liés. Il contient une séquence d'activités dans laquelle chaque activité effectue une opération de traitement spécifique. Cet article décrit l’activité U-SQL Data Lake Analytics qui exécute un script U-SQL sur un service lié de calcul Azure Data Lake Analytics.
Créez un compte Azure Data Lake Analytics avant de créer un pipeline avec une activité U-SQL Data Lake Analytics. Pour en savoir plus sur Azure Data Lake Analytics, consultez Get démarré avec Azure Data Lake Analytics.
Ajouter une activité U-SQL pour Azure Data Lake Analytics à un pipeline avec interface utilisateur
Pour utiliser une activité U-SQL pour Azure Data Lake Analytics dans un pipeline, procédez comme suit :
Recherchez Data Lake dans le volet Activités du pipeline, puis faites glisser une activité U-SQL vers le canevas du pipeline.
Sélectionnez la nouvelle activité U-SQL sur le canevas si elle n’est pas déjà sélectionnée.
Sélectionnez l’onglet ADLA Account pour sélectionner ou créer un service lié Azure Data Lake Analytics qui sera utilisé pour exécuter l’activité U-SQL.
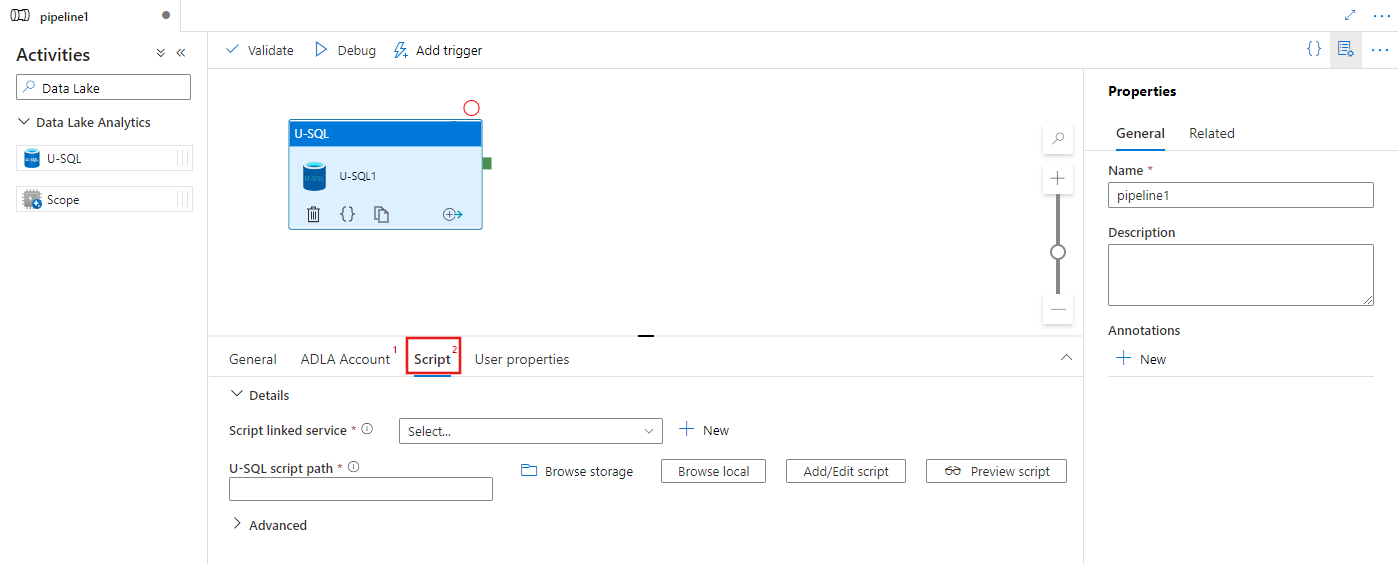
Sélectionnez l’onglet Script pour sélectionner ou créer un service lié de stockage, ainsi qu’un chemin d’accès dans l’emplacement de stockage, qui hébergera le script.
Service lié Azure Data Lake Analytics
Vous créez un service lié Azure Data Lake Analytics pour lier un service de calcul Azure Data Lake Analytics à un espace de travail Azure Data Factory ou Synapse Analytics. L’activité U-SQL dans le pipeline Data Lake Analytics fait référence à ce service lié.
Le tableau suivant décrit les propriétés génériques utilisées dans la définition JSON.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété de type doit être définie sur : AzureDataLakeAnalytics. | Oui |
| accountName | nom du compte Azure Data Lake Analytics. | Oui |
| dataLakeAnalyticsUri | URI d'Azure Data Lake Analytics | Non |
| subscriptionId | ID d’abonnement Azure | Non |
| resourceGroupName | nom du groupe de ressources Azure | Non |
Authentification d’un principal du service
Le service lié Azure Data Lake Analytics nécessite une authentification de principal de service pour se connecter au service Azure Data Lake Analytics. Pour utiliser l’authentification du principal de service, inscrivez une entité d’application dans Microsoft Entra ID et accordez-lui l’accès aux Data Lake Analytics et au magasin Data Lake qu’il utilise. Consultez la page Authentification de service à service pour des instructions détaillées. Prenez note des valeurs suivantes, qui vous permettent de définir le service lié :
- ID de l'application
- Clé de l'application
- ID locataire
Accordez l’autorisation de principal de service à Azure Data Lake Analytics à l’aide de l’Assistant Ajout d’un utilisateur.
Utilisez l’authentification par principal de service en spécifiant les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| servicePrincipalId | Spécifiez l’ID client de l’application. | Oui |
| servicePrincipalKey | Spécifiez la clé de l’application. | Oui |
| locataire | Spécifiez les informations de locataire (nom de domaine ou ID de locataire) sous lequel se trouve votre application. Vous pouvez le récupérer en pointant la souris dans le coin supérieur droit du portail Azure. | Oui |
Exemple : Authentification d’une entité de service
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Pour en savoir plus sur le service lié, consultez Services liés de calcul.
Activité U-SQL de l'analyse de Data Lake
L’extrait de code JSON suivant définit un pipeline avec une activité U-SQL Data Lake Analytics. La définition d’activité a une référence au service lié Azure Data Lake Analytics que vous avez créé précédemment. Pour exécuter un script U-SQL Data Lake Analytics, le service envoie le script que vous avez spécifié au Data Lake Analytics, et les entrées et sorties requises sont définies dans le script pour Data Lake Analytics extraire et générer.
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
Le tableau suivant indique les noms et les descriptions des propriétés qui sont spécifiques à cette activité.
| Propriété | Description | Obligatoire |
|---|---|---|
| nom | Nom de l’activité dans le pipeline | Oui |
| description | Texte décrivant l’activité. | Non |
| type | Pour Data Lake Analytics activité U-SQL, le type d’activité est DataLakeAnalyticsU-SQL. | Oui |
| linkedServiceName | Service lié à Azure Data Lake Analytics. Pour en savoir plus sur ce service lié, consultez l’article Services liés de calcul. | Oui |
| scriptPath | Chemin d'accès au dossier qui contient le script SQL-U. Le nom de fichier respecte la casse. | Oui |
| scriptLinkedService | Service lié qui lie le Azure Data Lake Store ou Azure Storage qui contient le script | Oui |
| degréDeParallélisme | Le nombre maximal de nœuds utilisés simultanément pour exécuter le travail. | Non |
| priorité | Détermine les travaux parmi tous ceux qui sont en file d'attente qui doivent être sélectionnés pour s'exécuter en premier. Plus le numéro est faible, plus la priorité est élevée. | Non |
| paramètres | Paramètres à transmettre au script U-SQL. | Non |
| version d'exécution | Version du runtime du moteur U-SQL à utiliser. | Non |
| compilationMode | Mode de compilation d’U-SQL. Doit avoir l’une des valeurs suivantes : Semantic : Exécuter uniquement les vérifications sémantiques et les contrôles d’intégrité nécessaires. Full : Effectuer la compilation complète, y compris la vérification de la syntaxe, l’optimisation, la génération de code, etc. SingleBox : effectuer la compilation complète, avec le paramètre TargetType défini sur SingleBox. Si vous ne spécifiez pas de valeur pour cette propriété, le serveur détermine le mode de compilation optimal. |
Non |
Vous trouverez la définition du script dans la section SearchLogProcessing.txt.
Exemple de script U-SQL
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
Dans l’exemple de script ci-dessus, l’entrée et la sortie du script sont définies dans les paramètres @in et @out. Les valeurs des paramètres @in et @out dans le script U-SQL sont transmises dynamiquement par le service en utilisant la section « parameters ».
Vous pouvez spécifier d’autres propriétés telles que degreeOfParallelism et priority ainsi que dans votre définition de pipeline pour les travaux qui s’exécutent sur le service Azure Data Lake Analytics.
Paramètres dynamiques
Dans l’exemple de définition de pipeline, des valeurs codées en dur sont affectées aux paramètres de sortie.
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
Il est possible d’utiliser des paramètres dynamiques à la place. Par exemple :
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
Dans ce cas, les fichiers d’entrée sont toujours récupérés à partir du dossier /datalake/input et les fichiers de sortie sont générés dans le dossier /datalake/output. Les noms de fichiers sont dynamiques en fonction de l’heure de début de la fenêtre lorsque le pipeline est déclenché.
Contenu connexe
Consultez les articles suivants qui expliquent comment transformer des données par d’autres moyens :