Charger de façon incrémentielle des données d’Azure SQL Database sur le Stockage Blob Azure en utilisant des informations de suivi des modifications avec PowerShell
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Dans ce tutoriel, vous allez créer une fabrique de données Azure avec un pipeline qui charge des données delta basées sur des informations de suivi des modifications dans la base de données source dans Azure SQL Database vers un stockage Blob Azure.
Dans ce tutoriel, vous allez effectuer les étapes suivantes :
- Préparer le magasin de données source
- Créer une fabrique de données.
- créez des services liés.
- Créez des jeux de données source, récepteur et de suivi des modifications.
- Créer, exécuter et surveiller le pipeline de copie complète
- Ajouter ou mettre à jour des données dans la table source
- Créer, exécuter et surveiller le pipeline de copie incrémentielle
Notes
Nous vous recommandons d’utiliser le module Azure Az PowerShell pour interagir avec Azure. Pour bien démarrer, consultez Installer Azure PowerShell. Pour savoir comment migrer vers le module Az PowerShell, consultez Migrer Azure PowerShell depuis AzureRM vers Az.
Vue d’ensemble
Dans une solution d’intégration de données, le chargement incrémentiel de données après des chargements de données initiaux est un scénario largement utilisé. Dans certains cas, les données modifiées pendant une période dans votre magasin de données source peuvent être facilement découpées (par exemple, LastModifyTime, CreationTime). Dans certains cas, il n’existe pas de manière explicite pour identifier les données delta depuis le dernier traitement des données. La technologie Change Tracking prise en charge par les magasins de données tels qu’Azure SQL Database et SQL Server peut être utilisée pour identifier les données delta. Ce tutoriel explique comment utiliser Azure Data Factory avec la technologie Change Tracking SQL afin de charger de façon incrémentielle des données delta d’Azure SQL Database dans Stockage Blob Azure. Pour des informations plus concrètes sur la technologie Change Tracking SQL, consultez Change Tracking dans SQL Server.
Workflow de bout en bout
Voici les étapes de workflow de bout en bout classiques pour charger de façon incrémentielle des données à l’aide de la technologie Change Tracking.
Notes
Azure SQL Database et SQL Server prennent en charge la technologie Change Tracking. Ce tutoriel utilise Azure SQL Database comme magasin de données source. Vous pouvez également utiliser une instance SQL Server.
- Chargement initial de données d’historique (exécuter une fois) :
- Activez la technologie Change Tracking dans la base de données source dans Azure SQL Database.
- Obtenez la valeur initiale de SYS_CHANGE_VERSION dans la base de données comme base de référence pour la capture des données modifiées.
- Chargez les données complètes de la base de données source vers un compte de stockage blob Azure.
- Chargement incrémentiel de données delta selon une planification (exécuter périodiquement après le chargement initial des données) :
- Obtenez les valeurs SYS_CHANGE_VERSION anciennes et nouvelles.
- Chargez les données delta en associant les clés primaires des lignes modifiées (entre deux valeurs SYS_CHANGE_VERSION) de sys.change_tracking_tables avec des données dans la table source, puis déplacez les données delta vers la destination.
- Mettez à jour SYS_CHANGE_VERSION pour le chargement delta suivant.
Solution générale
Dans ce didacticiel, vous créez deux pipelines qui effectuent les deux opérations suivantes :
Chargement initial : vous créez un pipeline avec une activité de copie qui copie l’ensemble des données du magasin de données source (Azure SQL Database) dans le magasin de données de destination (Stockage Blob Azure).

Chargement incrémentiel : vous créez un pipeline avec les activités suivantes, et vous l’exécutez régulièrement.
- Créez deux activités de recherche pour obtenir les valeurs SYS_CHANGE_VERSION anciennes et nouvelles dans Azure SQL Database et les transmettre à l’activité de copie.
- Créez une activité de copie pour copier les données insérées/mises à jour/supprimées entre deux valeurs SYS_CHANGE_VERSION d’Azure SQL Database dans Stockage Blob Azure.
- Créez une activité de procédure stockée pour mettre à jour la valeur de SYS_CHANGE_VERSION pour la prochaine exécution du pipeline.

Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
- Azure PowerShell. Installez les modules Azure PowerShell les plus récents en suivant les instructions décrites dans Comment installer et configurer Azure PowerShell.
- Azure SQL Database. Vous utilisez la base de données comme magasin de données sources. Si vous n’avez pas de base de données dans Azure SQL Database, consultez l’article Créer une base de données dans Azure SQL Database pour savoir comme en créer une.
- Compte Stockage Azure. Vous utilisez le stockage Blob comme magasin de données récepteur. Si vous n’avez pas de compte de stockage Azure, consultez l’article Créer un compte de stockage pour découvrir comment en créer un. Créez un conteneur sous le nom adftutorial.
Créer une table de source de données dans votre base de données
Lancez SQL Server Management Studio, puis connectez-vous à SQL Database.
Dans l’Explorateur de serveurs, cliquez avec le bouton droit sur votre base de données et choisissez Nouvelle requête.
Exécutez la commande SQL suivante sur votre base de données pour créer une table sous le nom
data_source_tablecomme magasin de la source de données.create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Activez le mécanisme Change Tracking sur votre base de données et la table source (data_source_table) en exécutant la requête SQL suivante :
Notes
- Remplacez le <nom de votre base de données> par le nom de votre base de données contenant la data_source_table.
- Dans cet exemple, les données modifiées sont conservées pendant deux jours. Si vous chargez les données modifiées tous les trois jours ou plus, certaines données modifiées ne sont pas incluses. Vous devez remplacer la valeur de CHANGE_RETENTION par un plus grand nombre. Assurez-vous également que votre période pour charger les données modifiées est de moins de deux jours. Pour plus d’informations, consultez Activer le suivi des modifications pour une base de données
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)Créez une nouvelle table et stockez la ChangeTracking_version avec une valeur par défaut en exécutant la requête suivante :
create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Notes
Si les données ne sont pas modifiées une fois que vous avez activé le suivi des modifications pour SQL Database, la valeur de la version de suivi des modifications est 0.
Exécutez la requête suivante pour créer une procédure stockée dans votre base de données. Le pipeline appelle cette procédure stockée pour mettre à jour la version de suivi des modifications dans la table que vous avez créée à l’étape précédente.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Azure PowerShell
Installez les modules Azure PowerShell les plus récents en suivant les instructions décrites dans Comment installer et configurer Azure PowerShell.
Créer une fabrique de données
Définissez une variable pour le nom du groupe de ressources que vous utiliserez ultérieurement dans les commandes PowerShell. Copiez le texte de commande suivant dans PowerShell, spécifiez un nom pour le groupe de ressources Azure entre des guillemets doubles, puis exécutez la commande. Par exemple :
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Si le groupe de ressources existe déjà, vous pouvez ne pas le remplacer. Affectez une valeur différente à la variable
$resourceGroupNameet exécutez à nouveau la commandeDéfinissez une variable pour l’emplacement de la fabrique de données :
$location = "East US"Pour créer le groupe de ressources Azure, exécutez la commande suivante :
New-AzResourceGroup $resourceGroupName $locationSi le groupe de ressources existe déjà, vous pouvez ne pas le remplacer. Affectez une valeur différente à la variable
$resourceGroupNameet exécutez à nouveau la commande.Définissez une variable pour le nom de la fabrique de données.
Important
Mettez à jour le nom de la fabrique de données afin qu’il soit globalement unique.
$dataFactoryName = "IncCopyChgTrackingDF";Pour créer la fabrique de données, exécutez la cmdlet Set-AzDataFactoryV2 suivante :
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Notez les points suivants :
Le nom de la fabrique de données Azure doit être un nom global unique. Si vous recevez l’erreur suivante, changez le nom, puis réessayez.
The specified Data Factory name 'ADFIncCopyChangeTrackingTestFactory' is already in use. Data Factory names must be globally unique.Pour créer des instances de fabrique de données, le compte d’utilisateur que vous utilisez pour vous connecter à Azure doit être un membre des rôles contributeur ou propriétaire, ou un administrateur de l’abonnement Azure.
Pour obtenir la liste des régions Azure dans lesquelles Data Factory est actuellement disponible, sélectionnez les régions qui vous intéressent dans la page suivante, puis développez Analytique pour localiser Data Factory : Disponibilité des produits par région. Les magasins de données (Stockage Azure, Azure SQL Database, etc.) et les services de calcul (HDInsight, etc.) utilisés par la fabrique de données peuvent être proposés dans d’autres régions.
Créez des services liés
Vous allez créer des services liés dans une fabrique de données pour lier vos magasins de données et vos services de calcul à la fabrique de données. Dans cette section, vous allez créer des services liés à votre compte de stockage Azure et à votre base de données dans Azure SQL Database.
Créer un service lié Stockage Azure.
Dans cette étape, vous liez votre compte Stockage Azure à la fabrique de données.
Créez un fichier JSON nommé AzureStorageLinkedService.json dans le dossier C:\ADFTutorials\IncCopyChangeTrackingTutorial avec le contenu suivant : (Créez le dossier s’il n’existe pas.) Remplacez
<accountName>,<accountKey>par le nom et la clé de votre compte de stockage Azure avant d’enregistrer le fichier.{ "name": "AzureStorageLinkedService", "properties": { "type": "AzureStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>" } } }Dans Azure PowerShell, basculez vers le dossier C:\ADFTutorials\IncCopyChangeTrackingTutorial.
Exécutez la cmdlet Set-AzDataFactoryV2LinkedService pour créer le service lié : AzureStorageLinkedService. Dans l’exemple suivant, vous passez les valeurs des paramètres ResourceGroupName et DataFactoryName.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"Voici l'exemple de sortie :
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureStorageLinkedService
Créez le service lié Azure SQL Database.
Dans cette étape, vous liez votre base de données à la fabrique de données.
Créez un fichier JSON nommé AzureSQLDatabaseLinkedService.json dans le dossier C:\ADFTutorials\IncCopyChangeTrackingTutorial avec le contenu suivant : Remplacez <nom-de-votre-serveur> et <nom-de-votre-base-de-données> par le nom de votre serveur et de votre base de données avant d’enregistrer le fichier. Vous devez également configurer votre instance Azure SQL Server pour accorder l’accès à l’identité managée de votre fabrique de données.
{ "name": "AzureSqlDatabaseLinkedService", "properties": { "type": "AzureSqlDatabase", "typeProperties": { "connectionString": "Server=tcp:<your-server-name>.database.windows.net,1433;Database=<your-database-name>;" }, "authenticationType": "ManagedIdentity", "annotations": [] } }Dans Azure PowerShell, exécutez la cmdlet Set-AzDataFactoryV2LinkedService pour créer le service lié : AzureSQLDatabaseLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Voici l'exemple de sortie :
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Créez les jeux de données
Dans cette étape, vous créez des jeux de données pour représenter la source de données et la destination de données. et l’emplacement pour stocker SYS_CHANGE_VERSION.
Créer un jeu de données source
Dans cette étape, vous créez un jeu de données pour représenter les données source.
Créez un fichier JSON sous le nom SourceDataset.json dans le même dossier avec le contenu suivant :
{ "name": "SourceDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "data_source_table" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Exécutez la cmdlet Set-AzDataFactoryV2Dataset pour créer le jeu de données : SourceDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Voici l’exemple de sortie de l’applet de commande :
DatasetName : SourceDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Créer un jeu de données récepteur
Dans cette étape, vous créez un jeu de données pour représenter les données copiées à partir du magasin de données source.
Créez un fichier JSON sous le nom SinkDataset.json dans le même dossier avec le contenu suivant :
{ "name": "SinkDataset", "properties": { "type": "AzureBlob", "typeProperties": { "folderPath": "adftutorial/incchgtracking", "fileName": "@CONCAT('Incremental-', pipeline().RunId, '.txt')", "format": { "type": "TextFormat" } }, "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" } } }Vous créez le conteneur adftutorial dans votre stockage blob Azure dans le cadre des prérequis. Créez le conteneur s’il n’existe pas (ou) attribuez-lui le nom d’un conteneur existant. Dans ce tutoriel, le nom du fichier de sortie est généré dynamiquement en utilisant l’expression @CONCAT('Incremental-', pipeline().RunId, '.txt').
Exécutez la cmdlet Set-AzDataFactoryV2Dataset pour créer le jeu de données : SinkDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Voici l’exemple de sortie de l’applet de commande :
DatasetName : SinkDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobDataset
Créer un jeu de données de suivi des modifications
Dans cette étape, vous créez un jeu de données pour stocker la version de suivi des modifications.
Créez un fichier JSON sous le nom ChangeTrackingDataset.json dans le même dossier avec le contenu suivant :
{ "name": " ChangeTrackingDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "table_store_ChangeTracking_version" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Vous créez la table table_store_ChangeTracking_version dans le cadre des prérequis.
Exécutez la cmdlet Set-AzDataFactoryV2Dataset pour créer le jeu de données : ChangeTrackingDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "ChangeTrackingDataset" -File ".\ChangeTrackingDataset.json"Voici l’exemple de sortie de l’applet de commande :
DatasetName : ChangeTrackingDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Créer un pipeline pour la copie complète
Dans cette étape, vous créez un pipeline avec une activité de copie qui copie l’ensemble des données du magasin de données source (Azure SQL Database) dans le magasin de données de destination (Stockage Blob Azure).
Créez un fichier JSON : FullCopyPipeline.json dans le même dossier avec le contenu suivant :
{ "name": "FullCopyPipeline", "properties": { "activities": [{ "name": "FullCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource" }, "sink": { "type": "BlobSink" } }, "inputs": [{ "referenceName": "SourceDataset", "type": "DatasetReference" }], "outputs": [{ "referenceName": "SinkDataset", "type": "DatasetReference" }] }] } }Exécutez la cmdlet Set-AzDataFactoryV2Pipeline pour créer le pipeline : FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "FullCopyPipeline" -File ".\FullCopyPipeline.json"Voici l'exemple de sortie :
PipelineName : FullCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {FullCopyActivity} Parameters :
Exécuter le pipeline de copie complète
Exécutez le pipeline : FullCopyPipeline en utilisant la cmdlet Invoke-AzDataFactoryV2Pipeline.
Invoke-AzDataFactoryV2Pipeline -PipelineName "FullCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
Surveiller le pipeline de copie complète
Connectez-vous au portail Azure.
Cliquez sur Tous les services, effectuez une recherche avec le mot clé
data factories, puis sélectionnez Fabriques de données.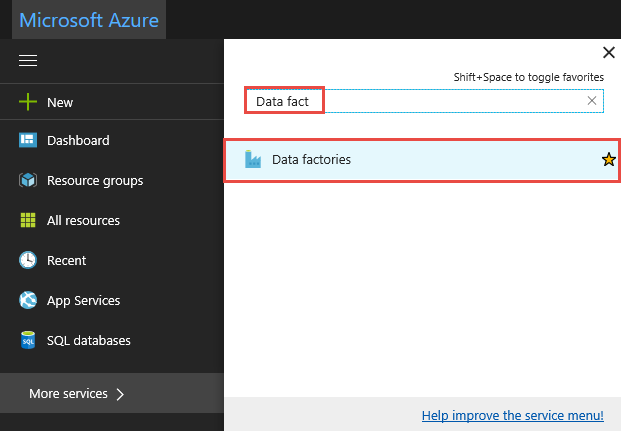
Recherchez votre fabrique de données dans la liste des fabriques de données et sélectionnez-la pour ouvrir la page de la fabrique de données.
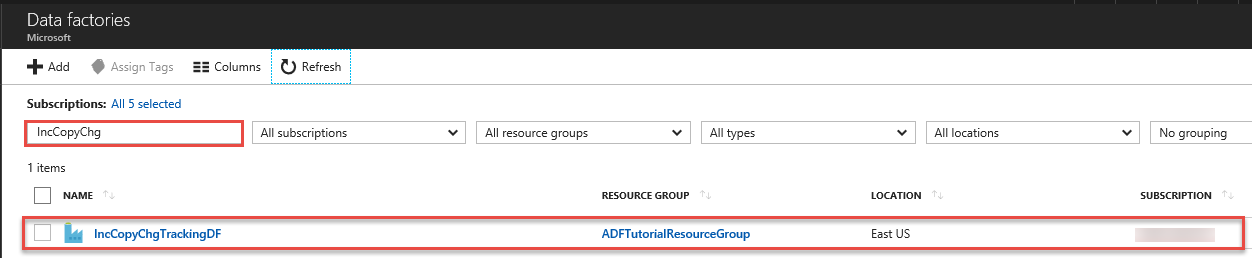
Sur la page Fabrique de données, cliquez sur la vignette Surveiller et gérer.
L’application d’intégration des données démarre dans un onglet séparé. Vous pouvez voir toutes les exécutions de pipeline et leurs états. Notez que dans l’exemple suivant, l’état d’exécution de pipeline est Réussite. Vous pouvez vérifier les paramètres transmis au pipeline en cliquant sur le lien dans la colonne Paramètres. Si une erreur s’est produite, vous voyez un lien dans la colonne Erreur. Cliquez sur le lien dans la colonne Actions.
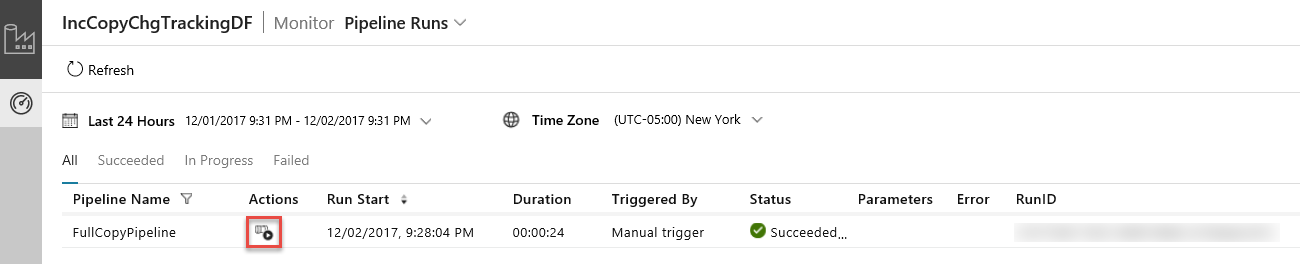
Lorsque vous cliquez sur le lien dans la colonne Actions, la page suivante affiche toutes les exécutions d’activité du pipeline.
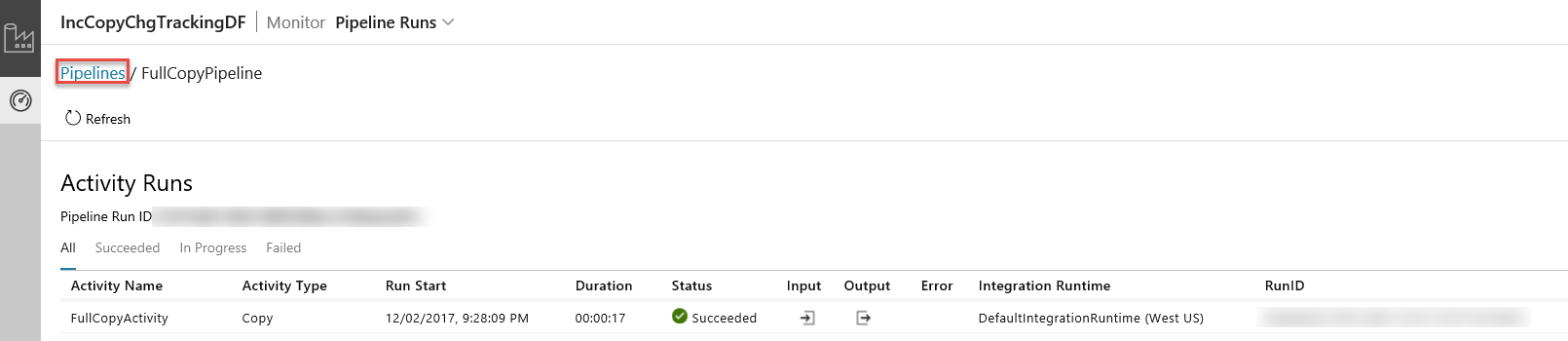
Pour revenir à la vue Exécutions de pipeline, cliquez sur Pipelines comme illustré dans l’image.
Passer en revue les résultats.
Vous voyez un fichier nommé incremental-<GUID>.txt dans le dossier incchgtracking du conteneur adftutorial.
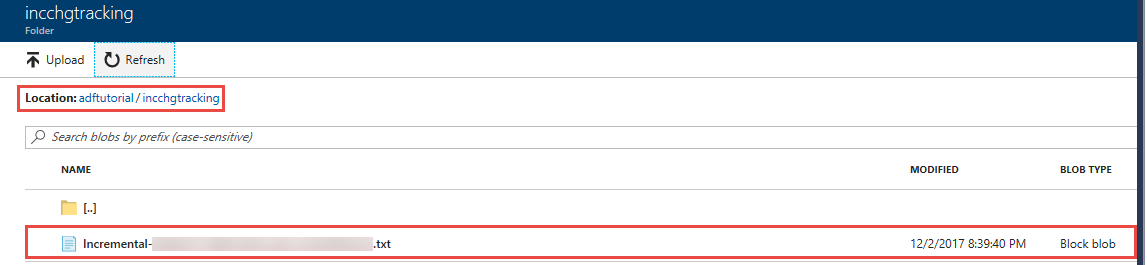
Le fichier doit contenir les données de votre base de données :
1,aaaa,21
2,bbbb,24
3,cccc,20
4,dddd,26
5,eeee,22
Ajouter plus de données à la table source
Exécutez la requête suivante par rapport à votre base de données pour ajouter une ligne et mettre à jour une ligne.
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Créer un pipeline pour la copie delta
Dans cette étape, vous créez un pipeline avec les activités suivantes, et vous l’exécutez régulièrement. Les activités de recherche obtiennent les valeurs SYS_CHANGE_VERSION anciennes et nouvelles dans Azure SQL Database et les transmettent à l’activité de copie. L’activité de copie copie les données insérées/mises à jour/supprimées entre deux valeurs SYS_CHANGE_VERSION d’Azure SQL Database dans Stockage Blob Azure. L’activité de procédure stockée met à jour la valeur de SYS_CHANGE_VERSION pour la prochaine exécution du pipeline.
Créez un fichier JSON : IncrementalCopyPipeline.json dans le même dossier avec le contenu suivant :
{ "name": "IncrementalCopyPipeline", "properties": { "activities": [ { "name": "LookupLastChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select * from table_store_ChangeTracking_version" }, "dataset": { "referenceName": "ChangeTrackingDataset", "type": "DatasetReference" } } }, { "name": "LookupCurrentChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion" }, "dataset": { "referenceName": "SourceDataset", "type": "DatasetReference" } } }, { "name": "IncrementalCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) as CT on data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}" }, "sink": { "type": "BlobSink" } }, "dependsOn": [ { "activity": "LookupLastChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] }, { "activity": "LookupCurrentChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] } ], "inputs": [ { "referenceName": "SourceDataset", "type": "DatasetReference" } ], "outputs": [ { "referenceName": "SinkDataset", "type": "DatasetReference" } ] }, { "name": "StoredProceduretoUpdateChangeTrackingActivity", "type": "SqlServerStoredProcedure", "typeProperties": { "storedProcedureName": "Update_ChangeTracking_Version", "storedProcedureParameters": { "CurrentTrackingVersion": { "value": "@{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}", "type": "INT64" }, "TableName": { "value": "@{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}", "type": "String" } } }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" }, "dependsOn": [ { "activity": "IncrementalCopyActivity", "dependencyConditions": [ "Succeeded" ] } ] } ] } }Exécutez la cmdlet Set-AzDataFactoryV2Pipeline pour créer le pipeline : FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Voici l'exemple de sortie :
PipelineName : IncrementalCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {LookupLastChangeTrackingVersionActivity, LookupCurrentChangeTrackingVersionActivity, IncrementalCopyActivity, StoredProceduretoUpdateChangeTrackingActivity} Parameters :
Exécuter le pipeline de copie incrémentielle
Exécutez le pipeline : IncrementalCopyPipeline en utilisant la cmdlet Invoke-AzDataFactoryV2Pipeline.
Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
Surveiller le pipeline de copie incrémentielle
Dans l’Application d’intégration de données, actualisez la vue Exécutions de pipeline. Vérifiez que IncrementalCopyPipeline apparaît dans la liste. Cliquez sur le lien dans la colonne Actions.
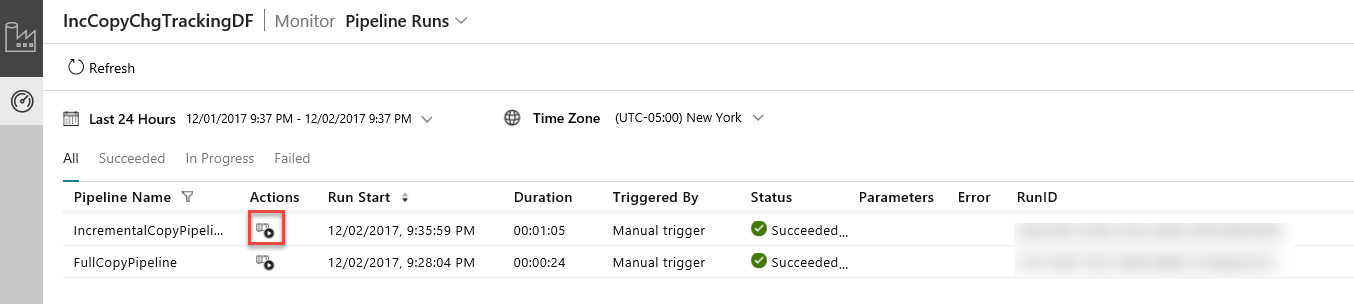
Lorsque vous cliquez sur le lien dans la colonne Actions, la page suivante affiche toutes les exécutions d’activité du pipeline.
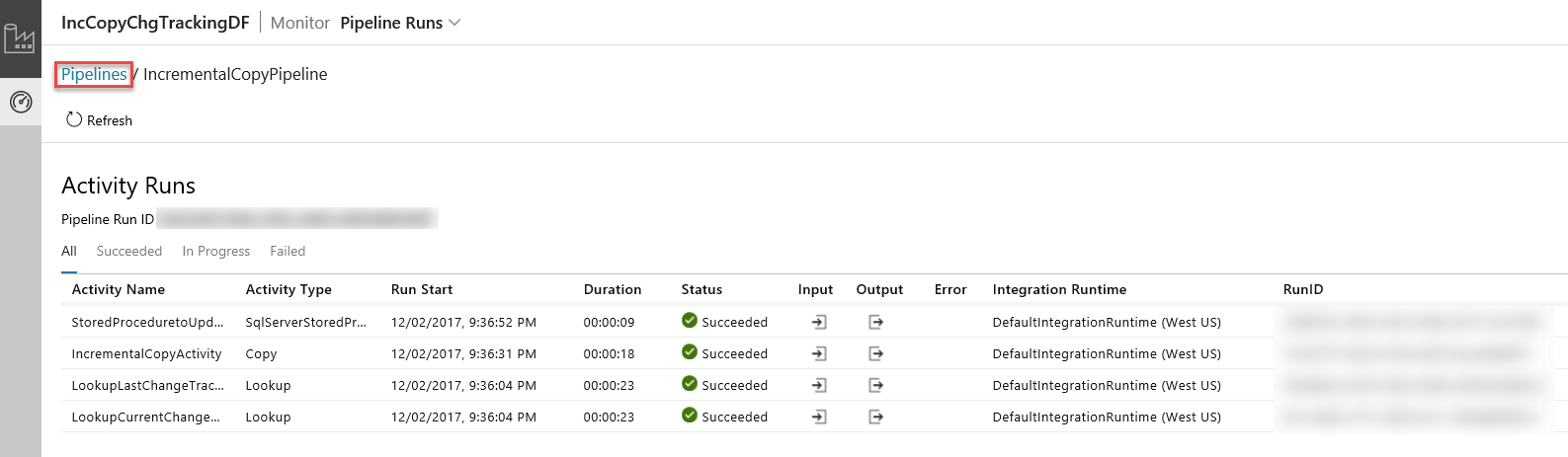
Pour revenir à la vue Exécutions de pipeline, cliquez sur Pipelines comme illustré dans l’image.
Passer en revue les résultats.
Vous voyez le second fichier dans le dossier incchgtracking du conteneur adftutorial.
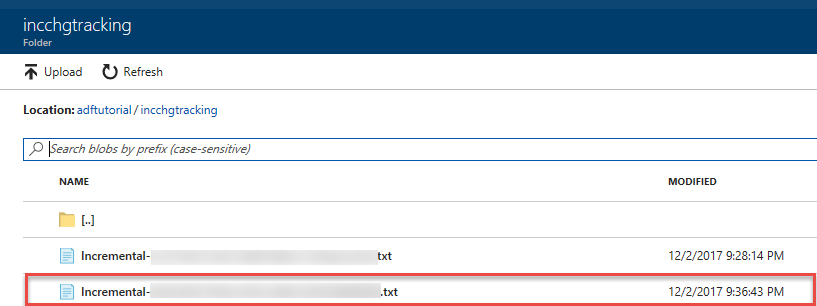
Le fichier ne doit contenir que les données delta de votre base de données. L’enregistrement avec U correspond à la ligne mise à jour dans la base de données et I à la ligne ajoutée.
1,update,10,2,U
6,new,50,1,I
Les trois premières colonnes correspondent aux données modifiées de data_source_table. Les deux dernières colonnes correspondent aux métadonnées de la table système de suivi des modifications. La quatrième colonne correspond à SYS_CHANGE_VERSION de chaque ligne modifiée. La cinquième colonne correspond à l’opération : U = mise à jour, I = insertion. Pour plus d’informations sur le suivi des modifications, consultez CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Contenu connexe
Passez au tutoriel suivant pour en savoir plus sur la copie des fichiers nouveaux et modifiés uniquement en fonction de leur LastModifiedDate :