Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Ce tutoriel explique comment connecter l’interface utilisateur web locale de votre Data Box à un serveur de données local par le biais de NFS et de copier des données à partir de celle-ci. Les données de votre Data Box sont exportées à partir de votre compte de Stockage Azure.
Dans ce tutoriel, vous allez apprendre à :
- Prérequis
- Se connecter à Data Box
- Copier des données à partir de la Data Box
Prérequis
Avant de commencer, assurez-vous que :
- Vous avez passé la commande pour Azure Data Box.
- Pour une commande d’importation, consultez Tutoriel : Commander Azure Data Box.
- Pour une commande d’exportation, consultez Tutoriel : Commander Azure Data Box.
- Vous avez reçu votre Data Box et que l’état de la commande dans le portail est Remis.
- Vous disposez d’un ordinateur hôte sur lequel vous voulez copier les données de votre Data Box. Votre ordinateur hôte doit
- Exécuter un système d’exploitation pris en charge
- Connectez-vous à un réseau haut débit. Nous vous recommandons vivement d’utiliser au minimum une connexion 10 GbE. Si vous ne disposez pas d’une connexion 10 GbE, utilisez une liaison de données 1 GbE. Cependant, les vitesses de copie seront affectées.
Se connecter à Data Box
Selon le compte de stockage sélectionné, Data Box crée jusqu’à :
- Trois partages pour chaque compte de stockage associé pour GPv1 et GPv2.
- Un partage pour le stockage Premium.
- Un partage pour le compte de stockage Blob.
Sous les partages d’objet blob de blocs et d’objet blob de pages, les entités de premier niveau sont des conteneurs et les entités de second niveau sont des objets blob. Sous les partages Azure Files, les entités de premier niveau sont des partages et les entités de second niveau sont des fichiers.
Le tableau suivant montre le chemin UNC aux partages sur votre Data Box et l’URL de chemin Stockage Azure où les données sont chargées. La dernière URL de chemin de Stockage Azure peut être dérivée à partir du chemin de partage UNC.
| Blobs et fichiers | Chemins et URL |
|---|---|
| Objets blob de blocs Azure | \\<DeviceIPAddress>\<StorageAccountName_BlockBlob>\<ContainerName>\files\a.txthttps://<StorageAccountName>.blob.core.windows.net/<ContainerName>/files/a.txt |
| Objets blob de pages Azure | \\<DeviceIPAddress>\<StorageAccountName_PageBlob>\<ContainerName>\files\a.txthttps://<StorageAccountName>.blob.core.windows.net/<ContainerName>/files/a.txt |
| Azure Files | \\<DeviceIPAddress>\<StorageAccountName_AzFile>\<ShareName>\files\a.txthttps://<StorageAccountName>.file.core.windows.net/<ShareName>/files/a.txt |
Si vous utilisez un ordinateur hôte Linux, procédez comme suit afin de configurer Data Box pour autoriser l’accès aux clients NFS. Data Box peut connecter jusqu’à cinq clients NFS à la fois.
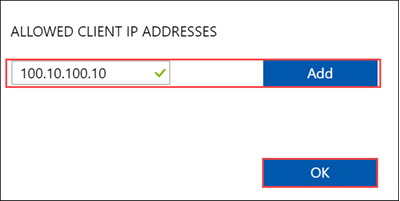
Spécifiez les adresses IP des clients autorisés pouvant accéder au partage :
Dans l’interface utilisateur web locale, accédez à la page Connexion et copie. Sous Paramètres NFS, cliquez sur Accès au client NFS.
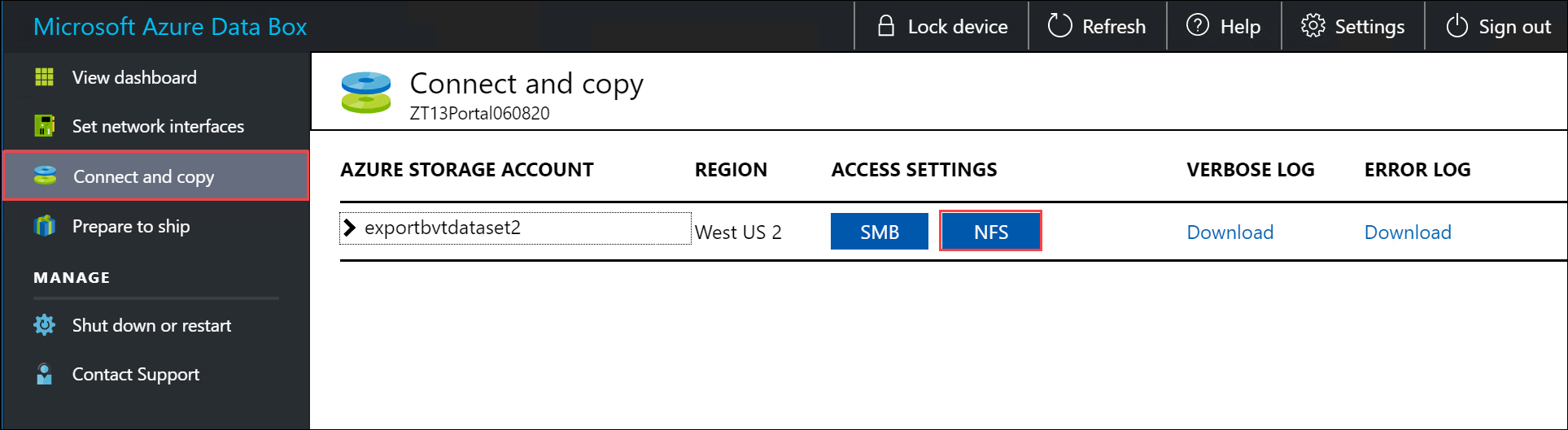
Pour ajouter un client NFS, spécifiez l’adresse IP du client, puis cliquez sur Ajouter. Data Box peut connecter jusqu’à cinq clients NFS à la fois. Quand vous avez terminé, cliquez sur OK.
Assurez-vous qu’une version prise en charge du client NFS est installée sur l’ordinateur hôte Linux. Utilisez la version spécifiquement adaptée à votre distribution Linux.
Une fois le client NFS installé, utilisez la commande suivante pour monter le partage NFS sur votre appareil Data Box :
sudo mount <Data Box device IP>:/<NFS share on Data Box device> <Path to the folder on local Linux computer>L’exemple suivant montre comment se connecter à un partage Data Box via NFS. L’adresse IP de l’appareil Data Box est
10.161.23.130. Le partageMystoracct_Blobest monté sur la machine virtuelle ubuntuVM avec le point de montage/home/databoxubuntuhost/databox.sudo mount -t nfs 10.161.23.130:/Mystoracct_Blob /home/databoxubuntuhost/databoxPour les clients Mac, vous devez ajouter une option supplémentaire, comme suit :
sudo mount -t nfs -o sec=sys,resvport 10.161.23.130:/Mystoracct_Blob /home/databoxubuntuhost/databoxToujours créer un dossier pour les fichiers que vous envisagez de copier sous le partage, puis copier les fichiers dans ce dossier. Le dossier créé sous les partages d’objets blob de pages et d’objets blob de blocs représente un conteneur dans lequel les données sont chargées en tant qu’objets blob. Vous ne pouvez pas copier de fichiers directement dans le dossier root du compte de stockage.
Copier des données à partir de la Data Box
Une fois que vous êtes connecté aux partages Data Box, l’étape suivante consiste à copier les données.
Avant de copier les données :
Téléchargez le journal de copie. Dans la page Connexion et copie, sélectionnez Copier le journal. Lorsque vous y êtes invité, enregistrez le journal sur votre système.
Si la taille de votre journal de copie est trop importante, vous devez utiliser l’Explorateur Stockage Azure ou AzCopy pour télécharger le journal de copie et éviter toute défaillance.
- Si vous utilisez l’Explorateur Stockage Azure pour télécharger le journal de copie, vous pouvez mapper votre compte de stockage Azure dans l’Explorateur Stockage Azure, puis télécharger le fichier brut.
- Si vous utilisez AzCopy pour télécharger le journal de copie, vous pouvez utiliser la commande
AzCopy copypour copier le fichier journal à partir de votre compte de stockage dans votre système local.
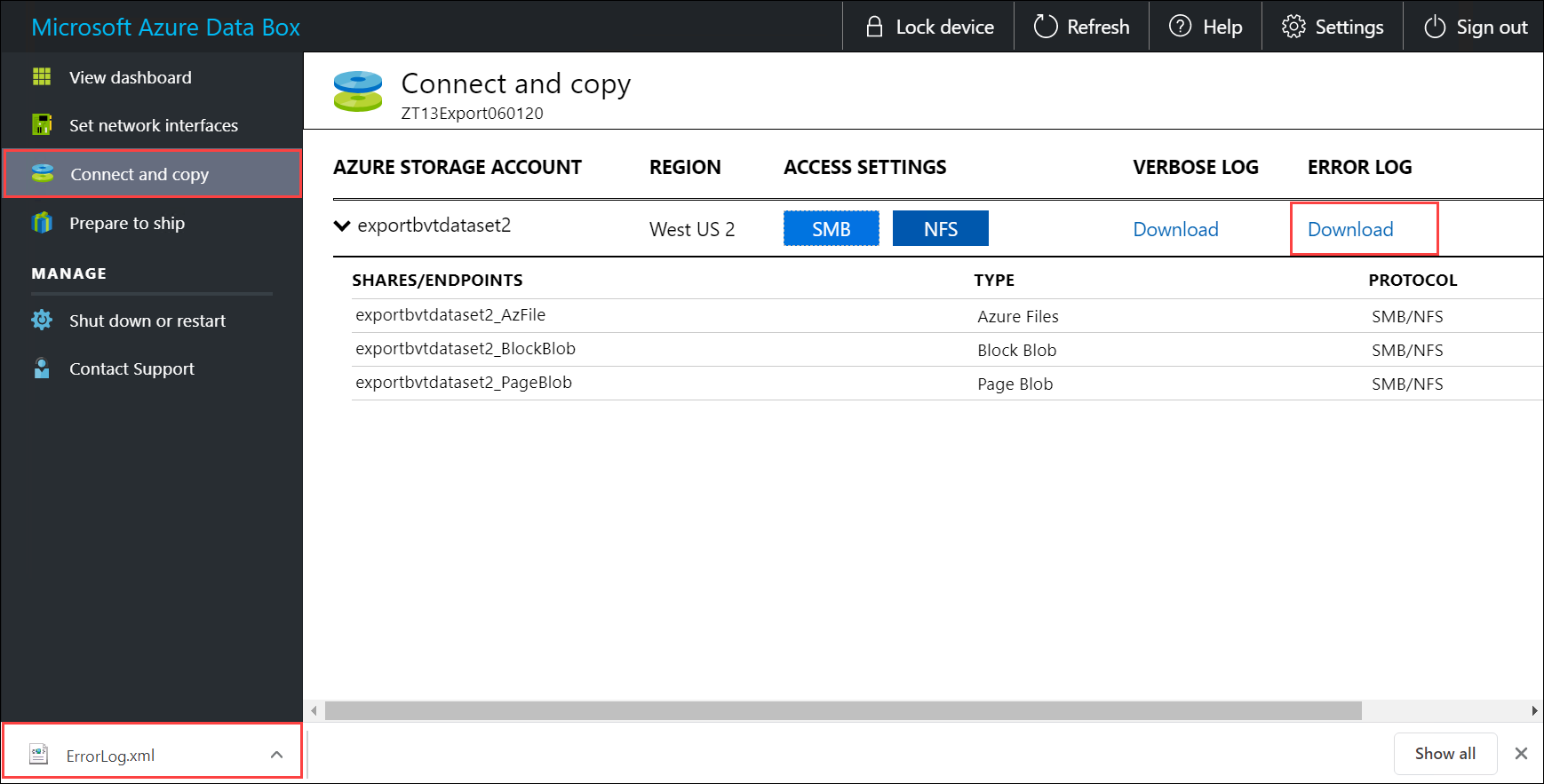
Répétez les étapes permettant de télécharger le journal détaillé.
Passez en revue le contenu du journal détaillé. Le journal détaillé contient la liste de tous les fichiers qui ont été exportés à partir du compte de stockage Azure. Le journal contient également la taille du fichier et le calcul de la somme de contrôle.
<File CloudFormat="BlockBlob" Path="validblobdata/test1.2.3.4" Size="1024" crc64="7573843669953104266"> </File><File CloudFormat="BlockBlob" Path="validblobdata/helloEndWithDot..txt" Size="11" crc64="7320094093915972193"> </File><File CloudFormat="BlockBlob" Path="validblobdata/test..txt" Size="12" crc64="17906086011702236012"> </File><File CloudFormat="BlockBlob" Path="validblobdata/test1" Size="1024" crc64="7573843669953104266"> </File><File CloudFormat="BlockBlob" Path="validblobdata/test1.2.3" Size="1024" crc64="7573843669953104266"> </File><File CloudFormat="BlockBlob" Path="validblobdata/.......txt" Size="11" crc64="7320094093915972193"> </File><File CloudFormat="BlockBlob" Path="validblobdata/copylogb08fa3095564421bb550d775fff143ed====..txt" Size="53638" crc64="1147139997367113454"> </File><File CloudFormat="BlockBlob" Path="validblobdata/testmaxChars-123456790-123456790-123456790-123456790-123456790-123456790-123456790-123456790-123456790-123456790-123456790-123456790-123456790-123456790-123456790-123456790-123456790-123456790-123456790-123456790-12345679" Size="1024" crc64="7573843669953104266"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/file0" Size="0" crc64="0"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/file1" Size="0" crc64="0"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/file4096_000001" Size="4096" crc64="16969371397892565512"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/file4096_000000" Size="4096" crc64="16969371397892565512"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/64KB-Seed10.dat" Size="65536" crc64="10746682179555216785"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/LiveSiteReport_Oct.xlsx" Size="7028" crc64="6103506546789189963"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/NE_Oct_GeoReport.xlsx" Size="103197" crc64="13305485882546035852"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/64KB-Seed1.dat" Size="65536" crc64="3140622834011462581"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/1mbfiles-0-0" Size="1048576" crc64="16086591317856295272"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/file524288_000001" Size="524288" crc64="8908547729214703832"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/4mbfiles-0-0" Size="4194304" crc64="1339017920798612765"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/file524288_000000" Size="524288" crc64="8908547729214703832"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/8mbfiles-0-1" Size="8388608" crc64="3963298606737216548"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/1mbfiles-0-1" Size="1048576" crc64="11061759121415905887"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/XLS-10MB.xls" Size="1199104" crc64="2218419493992437463"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/8mbfiles-0-0" Size="8388608" crc64="1072783424245035917"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/4mbfiles-0-1" Size="4194304" crc64="9991307204216370812"> </File><File CloudFormat="BlockBlob" Path="export-ut-container/VL_Piracy_Negtive10_TPNameAndGCS.xlsx" Size="12398699" crc64="13526033021067702820"> </File>Regardez si le journal de copie contient des erreurs. Ce journal indique les fichiers qui n’ont pas pu être copiés en raison d’erreurs.
Voici un exemple de sortie du journal de copie lorsqu’il n’y a pas d’erreurs et que tous les fichiers ont été copiés entre Azure et l’appareil Data Box.
<CopyLog Summary="Summary"> <Status>Succeeded</Status> <TotalFiles_Blobs>5521</TotalFiles_Blobs> <FilesErrored>0</FilesErrored> </CopyLog>Voici un exemple de sortie du journal de copie lorsqu’il y a des erreurs et que certains fichiers n’ont pas pu être copiés à partir d’Azure.
<ErroredEntity CloudFormat="AppendBlob" Path="export-ut-appendblob/wastorage.v140.3.0.2.nupkg"> <Category>UploadErrorCloudHttp</Category> <ErrorCode>400</ErrorCode> <ErrorMessage>UnsupportBlobType</ErrorMessage> <Type>File</Type> </ErroredEntity><ErroredEntity CloudFormat="AppendBlob" Path="export-ut-appendblob/xunit.console.Primary_2020-05-07_03-54-42-PM_27444.hcsml"> <Category>UploadErrorCloudHttp</Category> <ErrorCode>400</ErrorCode> <ErrorMessage>UnsupportBlobType</ErrorMessage> <Type>File</Type> </ErroredEntity><ErroredEntity CloudFormat="AppendBlob" Path="export-ut-appendblob/xunit.console.Primary_2020-05-07_03-54-42-PM_27444 (1).hcsml"> <Category>UploadErrorCloudHttp</Category> <ErrorCode>400</ErrorCode> <ErrorMessage>UnsupportBlobType</ErrorMessage> <Type>File</Type> </ErroredEntity><CopyLog Summary="Summary"> <Status>Failed</Status> <TotalFiles_Blobs>4</TotalFiles_Blobs> <FilesErrored>3</FilesErrored> </CopyLog>Vous disposez des options suivantes pour exporter ces fichiers :
- Vous pouvez transférer les fichiers qui n’ont pas pu être copiés sur le réseau.
- Si la taille de vos données est supérieure à la capacité utilisable de l’appareil, une copie partielle est effectuée et tous les fichiers qui n’ont pas été copiés sont listés dans ce journal. Vous pouvez utiliser ce journal comme un fichier XML d’entrée pour créer une nouvelle commande Data Box, puis copier ces fichiers.
Vous pouvez maintenant commencer la copie des données. Si vous utilisez un ordinateur hôte Linux, utilisez un utilitaire de copie similaire à Robocopy. Plusieurs solutions alternatives sont disponibles pour Linux, par exemple, rsync, FreeFileSync, Unison et Ultracopier.
La commande cp constitue l’une des meilleures options pour copier un répertoire. Pour plus d’informations sur son utilisation, reportez-vous aux pages man sur cp.
Si vous utilisez l’option rsync pour une copie multithread, suivez ces instructions :
Installez le package CIFS Utils ou NFS Utils selon le système de fichiers utilisé par votre client Linux.
sudo apt-get install cifs-utilssudo apt-get install nfs-utilsInstallez
rsyncet Parallel (selon la version distribuée de Linux).sudo apt-get install rsyncsudo apt-get install parallelCréez un point de montage.
sudo mkdir /mnt/databoxMontez le volume.
sudo mount -t NFS4 //Databox IP Address/share_name /mnt/databoxFaites une mise en miroir de la structure de répertoires du dossier.
rsync -za --include='*/' --exclude='*' /local_path/ /mnt/databoxCopiez les fichiers.
cd /local_path/; find -L . -type f | parallel -j X rsync -za {} /mnt/databox/{}où j spécifie le nombre de parallélisations, X = le nombre de copies parallèles
Nous vous recommandons de commencer avec 16 copies parallèles et d’augmenter le nombre de threads selon les ressources disponibles.
Important
Les types de fichiers Linux suivants ne sont pas pris en charge : liens symboliques, fichiers de caractères, fichiers de blocs, sockets et pipes. Ces types de fichiers entraînent des échecs au cours de l’étape Préparer l’expédition.
Une fois la copie terminée, accédez au Tableau de bord, puis vérifiez l’espace utilisé et l’espace libre sur votre appareil.
Vous pouvez maintenant procéder à l’expédition de votre Data Box à Microsoft.
Étapes suivantes
Ce tutoriel vous a apporté des connaissances concernant Azure Data Box, notamment concernant les points suivants :
- Prérequis
- Se connecter à Data Box
- Copier des données à partir de la Data Box
Passez au tutoriel suivant pour découvrir comment renvoyer votre Data Box à Microsoft.
Ship your Azure Data Box to Microsoft (Expédier votre Azure Data Box à Microsoft)