Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Azure Databricks a plusieurs utilitaires et API pour interagir avec les fichiers dans les emplacements suivants :
- Volumes de Catalogue Unity
- Fichiers d’espace de travail
- Stockage d’objets cloud
- Montages DBFS et racine DBFS
- Stockage éphémère attaché au nœud de pilote du cluster
Cet article présente des exemples d’interaction avec des fichiers dans ces emplacements pour les outils suivants :
- Apache Spark
- Spark SQL et Databricks SQL
- Utilitaires de système de fichiers Databricks (
dbutils.fsou%fs) - Interface CLI de Databricks
- Databricks REST API
- Commandes de l’interpréteur de commandes Bash (
%sh) - Installations de bibliothèques à l’échelle du notebook
%pip - Pandas
- Utilitaires de gestion et de traitement des fichiers Python OSS
Importante
Certaines opérations dans Databricks, en particulier celles qui utilisent des bibliothèques Java ou Scala, s’exécutent en tant que processus JVM, par exemple :
- Spécification d’une dépendance de fichier JAR à l’aide de
--jarsdans les configurations Spark - Appeler
catoujava.io.Filedans les notebooks Scala - Sources de données personnalisées, telles que
spark.read.format("com.mycompany.datasource") - Bibliothèques qui chargent des fichiers à l’aide de
FileInputStreamJava ouPaths.get()
Ces opérations ne prennent pas en charge la lecture ou l’écriture sur des volumes Unity Catalog, ni les fichiers d’espace de travail utilisant des chemins de fichiers standard, tels que /Volumes/my-catalog/my-schema/my-volume/my-file.csv. Si vous devez accéder aux fichiers de volume ou aux fichiers d’espace de travail à partir de dépendances JAR ou de bibliothèques JVM, copiez d’abord les fichiers pour calculer le stockage local à l’aide de commandes Python %sh, telles que %sh mv.. N'utilisez pas %fs ni dbutils.fs qui utilisent la machine virtuelle Java. Pour accéder aux fichiers déjà copiés localement, utilisez des commandes spécifiques au langage, comme shutil en Python, ou des commandes %sh. Si un fichier doit être présent au démarrage du cluster, utilisez un script init pour déplacer le fichier en premier. Consultez En quoi consistent les scripts d'initialisation ?.
Dois-je fournir un schéma d’URI pour accéder aux données ?
Les chemins d’accès aux données dans Azure Databricks suivent l’une des normes suivantes :
Les chemins de type URI incluent un schéma URI. Pour les solutions d’accès aux données natives Databricks, les schémas d’URI sont facultatifs pour la plupart des cas d’usage. Lorsque vous accédez directement aux données dans le stockage d’objets cloud, vous devez fournir le schéma d’URI approprié pour le type de stockage.
diagramme de chemins d’URI
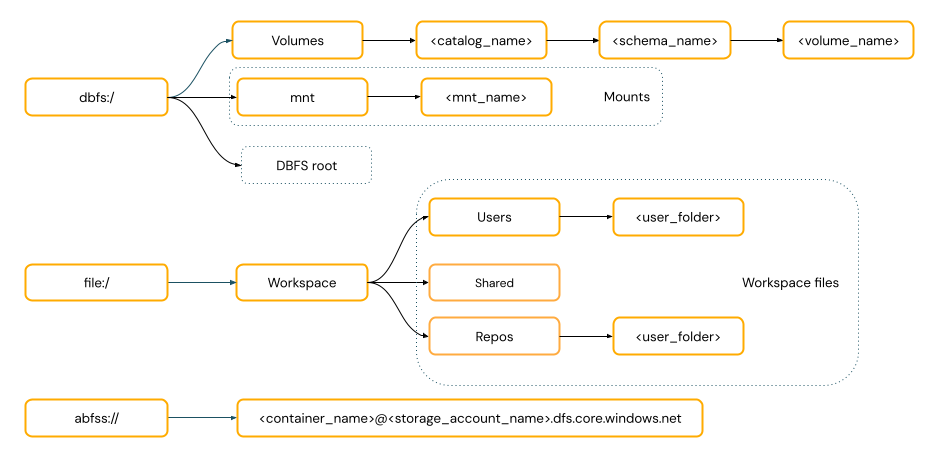
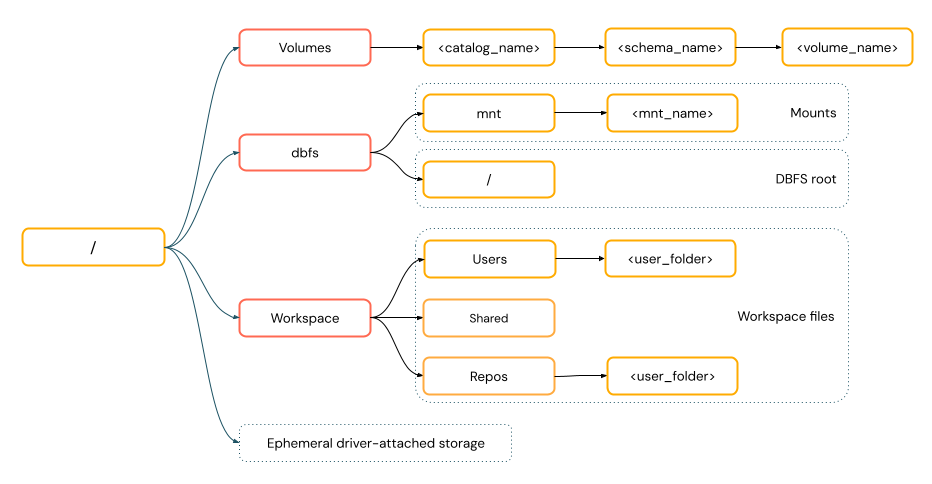
Les chemins de type POSIX fournissent un accès aux données par rapport à la racine du pilote (
/). Les chemins de style POSIX ne nécessitent jamais de schéma. Vous pouvez utiliser des volumes de catalogue Unity ou des montages DBFS pour fournir un accès au style POSIX aux données dans le stockage d’objets cloud. De nombreux frameworks ML et d’autres modules Python OSS nécessitent FUSE et peuvent utiliser uniquement des chemins de style POSIX.diagramme de chemins POSIX
Remarque
Les opérations de fichier nécessitant un accès aux données FUSE ne peuvent pas accéder directement au stockage d’objets cloud à l’aide d’URI. Databricks recommande d’utiliser des volumes de catalogue Unity pour configurer l’accès à ces emplacements pour FUSE.
Sur le calcul configuré avec le mode d’accès dédié (anciennement mode d’accès utilisateur unique) et Databricks Runtime 14.3 et versions ultérieures, Scala prend en charge FUSE pour les volumes catalogue Unity et les fichiers d’espace de travail, à l’exception des sous-processus provenant de Scala, tels que la commande "cat /Volumes/path/to/file".!!Scala.
Travailler avec des fichiers dans des volumes Unity Catalog
Databricks recommande d’utiliser des volumes de catalogue Unity pour configurer l’accès aux fichiers de données non tabulaires stockés dans le stockage d’objets cloud. Pour obtenir une documentation complète sur la gestion des fichiers dans des volumes, notamment des instructions détaillées et des bonnes pratiques, consultez Utiliser des fichiers dans des volumes catalogue Unity.
Les exemples suivants montrent les opérations courantes à l’aide de différents outils et interfaces :
| Outil | Exemple |
|---|---|
| Apache Spark | spark.read.format("json").load("/Volumes/my_catalog/my_schema/my_volume/data.json").show() |
| Spark SQL et Databricks SQL | SELECT * FROM csv.`/Volumes/my_catalog/my_schema/my_volume/data.csv`;LIST '/Volumes/my_catalog/my_schema/my_volume/'; |
| Utilitaires de système de fichiers Databricks | dbutils.fs.ls("/Volumes/my_catalog/my_schema/my_volume/")%fs ls /Volumes/my_catalog/my_schema/my_volume/ |
| Interface CLI de Databricks | databricks fs cp /path/to/local/file dbfs:/Volumes/my_catalog/my_schema/my_volume/ |
| Databricks REST API | POST https://<databricks-instance>/api/2.1/jobs/create{"name": "A multitask job", "tasks": [{..."libraries": [{"jar": "/Volumes/dev/environment/libraries/logging/Logging.jar"}],},...]} |
| Commandes de l’interpréteur de commandes Bash | %sh curl http://<address>/text.zip -o /Volumes/my_catalog/my_schema/my_volume/tmp/text.zip |
| Installations de bibliothèque | %pip install /Volumes/my_catalog/my_schema/my_volume/my_library.whl |
| Pandas | df = pd.read_csv('/Volumes/my_catalog/my_schema/my_volume/data.csv') |
| Logiciel Open Source Python | os.listdir('/Volumes/my_catalog/my_schema/my_volume/path/to/directory') |
Pour plus d’informations sur les limitations des volumes et les solutions de contournement, consultez Limitations de l’utilisation des fichiers dans les volumes.
Travailler avec des fichiers d'espace de travail
Les fichiers d’espace de travail Databricks sont les fichiers d’un espace de travail, stockés dans le compte de stockage de l’espace de travail. Vous pouvez utiliser des fichiers d’espace de travail pour stocker et accéder à des fichiers tels que des notebooks, des fichiers de code source, des fichiers de données et d’autres ressources d’espace de travail.
Importante
Étant donné que les fichiers d’espace de travail ont des restrictions de taille, Databricks recommande uniquement de stocker de petits fichiers de données ici principalement pour le développement et le test. Pour obtenir des recommandations sur l’emplacement où stocker d’autres types de fichiers, consultez Types de fichiers.
| Outil | Exemple |
|---|---|
| Apache Spark | spark.read.format("json").load("file:/Workspace/Users/<user-folder>/data.json").show() |
| Spark SQL et Databricks SQL | SELECT * FROM json.`file:/Workspace/Users/<user-folder>/file.json`; |
| Utilitaires de système de fichiers Databricks | dbutils.fs.ls("file:/Workspace/Users/<user-folder>/")%fs ls file:/Workspace/Users/<user-folder>/ |
| Interface CLI de Databricks | databricks workspace list |
| Databricks REST API | POST https://<databricks-instance>/api/2.0/workspace/delete{"path": "/Workspace/Shared/code.py", "recursive": "false"} |
| Commandes de l’interpréteur de commandes Bash | %sh curl http://<address>/text.zip -o /Workspace/Users/<user-folder>/text.zip |
| Installations de bibliothèque | %pip install /Workspace/Users/<user-folder>/my_library.whl |
| Pandas | df = pd.read_csv('/Workspace/Users/<user-folder>/data.csv') |
| Logiciel Open Source Python | os.listdir('/Workspace/Users/<user-folder>/path/to/directory') |
Remarque
Le schéma file:/ est requis lors de l’utilisation des utilitaires Databricks, Apache Spark ou SQL.
Dans les espaces de travail où la racine et les montages DBFS sont désactivés, vous pouvez également utiliser dbfs:/Workspace pour accéder aux fichiers d’espace de travail avec les utilitaires Databricks. Cela nécessite Databricks Runtime 13.3 LTS ou versions ultérieures. Consultez Désactiver l’accès à la racine DBFS et aux points de montage dans vos espaces de travail Azure Databricks existants.
Pour connaître les limitations de l’utilisation des fichiers d’espace de travail, consultez Limitations.
Où vont les fichiers d’espace de travail supprimés ?
La suppression d’un fichier d’espace de travail l’envoie à la corbeille. Vous pouvez récupérer ou supprimer définitivement des fichiers de la corbeille à l’aide de l’interface utilisateur.
Consultez Supprimer un objet.
Utiliser des fichiers dans le stockage d’objets cloud
Databricks recommande d’utiliser des volumes de catalogue Unity pour configurer l’accès sécurisé aux fichiers dans le stockage d’objets cloud. Vous devez configurer des autorisations si vous choisissez d’accéder aux données directement dans le stockage d’objets cloud à l’aide d’URI. Consultez les volumes managés et externes.
Les exemples suivants utilisent des URI pour accéder aux données dans le stockage d’objets cloud :
| Outil | Exemple |
|---|---|
| Apache Spark | spark.read.format("json").load("abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json").show() |
| Spark SQL et Databricks SQL |
SELECT * FROM csv.`abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json`;
LIST 'abfss://container-name@storage-account-name.dfs.core.windows.net/path';
|
| Utilitaires de système de fichiers Databricks |
dbutils.fs.ls("abfss://container-name@storage-account-name.dfs.core.windows.net/path/")
%fs ls abfss://container-name@storage-account-name.dfs.core.windows.net/path/
|
| Interface CLI de Databricks | Non pris en charge |
| Databricks REST API | Non pris en charge |
| Commandes de l’interpréteur de commandes Bash | Non pris en charge |
| Installations de bibliothèque | %pip install abfss://container-name@storage-account-name.dfs.core.windows.net/path/to/library.whl |
| Pandas | Non pris en charge |
| Logiciel Open Source Python | Non pris en charge |
Travailler avec des fichiers dans des montages DBFS et une racine DBFS
Importante
La racine DBFS et les montages DBFS sont obsolètes et déconseillés par Databricks. Les nouveaux comptes sont provisionnés sans accéder à ces fonctionnalités. Databricks recommande d’utiliser des volumes de catalogue Unity, des emplacements externes ou desfichiers d’espace de travail à la place.
| Outil | Exemple |
|---|---|
| Apache Spark | spark.read.format("json").load("/mnt/path/to/data.json").show() |
| Spark SQL et Databricks SQL | SELECT * FROM json.`/mnt/path/to/data.json`; |
| Utilitaires de système de fichiers Databricks | dbutils.fs.ls("/mnt/path")%fs ls /mnt/path |
| Interface CLI de Databricks | databricks fs cp dbfs:/mnt/path/to/remote/file /path/to/local/file |
| Databricks REST API | POST https://<host>/api/2.0/dbfs/delete --data '{ "path": "/tmp/HelloWorld.txt" }' |
| Commandes de l’interpréteur de commandes Bash | %sh curl http://<address>/text.zip > /dbfs/mnt/tmp/text.zip |
| Installations de bibliothèque | %pip install /dbfs/mnt/path/to/my_library.whl |
| Pandas | df = pd.read_csv('/dbfs/mnt/path/to/data.csv') |
| Logiciel Open Source Python | os.listdir('/dbfs/mnt/path/to/directory') |
Remarque
Le schéma dbfs:/ est requis lors de l’utilisation de l’interface CLI Databricks.
Travailler avec des fichiers dans le stockage éphémère attaché au nœud de pilote
Le stockage éphémère attaché au nœud du pilote est un stockage en blocs avec accès par chemin de type POSIX intégré. Toutes les données stockées dans cet emplacement disparaissent lorsqu’un cluster se termine ou redémarre.
| Outil | Exemple |
|---|---|
| Apache Spark | Non pris en charge |
| Spark SQL et Databricks SQL | Non pris en charge |
| Utilitaires de système de fichiers Databricks | dbutils.fs.ls("file:/path")%fs ls file:/path |
| Interface CLI de Databricks | Non pris en charge |
| Databricks REST API | Non pris en charge |
| Commandes de l’interpréteur de commandes Bash | %sh curl http://<address>/text.zip > /tmp/text.zip |
| Installations de bibliothèque | Non pris en charge |
| Pandas | df = pd.read_csv('/path/to/data.csv') |
| Logiciel Open Source Python | os.listdir('/path/to/directory') |
Remarque
Le schéma file:/ est requis lors de l’utilisation des utilitaires Databricks.
Déplacer des données d’un stockage éphémère vers des volumes
Vous pouvez accéder aux données téléchargées ou enregistrées dans un stockage éphémère à l’aide d’Apache Spark. Étant donné que le stockage éphémère est attaché au pilote et que Spark est un moteur de traitement distribué, toutes les opérations ne peuvent pas accéder directement aux données ici. Supposons que vous devez déplacer des données du système de fichiers du pilote vers des volumes de catalogue Unity. Dans ce cas, vous pouvez copier des fichiers à l’aide de commandes magiques ou des utilitaires Databricks, comme dans les exemples suivants :
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>