Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cette page explique comment développer du code dans des notebooks Databricks, notamment la mise en forme du code, la saisie semi-automatique, le mélange de langages et les commandes magiques.
Pour plus d’informations sur les fonctionnalités avancées disponibles avec l’éditeur, telles que la saisie semi-automatique, la sélection de variables, la gestion de multiples curseurs et la comparaison côte à côte, consultez Parcourir le bloc-notes Databricks et l’éditeur de fichiers.
Lorsque vous utilisez le notebook ou l’éditeur de fichiers, Genie Code est disponible pour vous aider à générer, expliquer et déboguer du code. Pour plus d’informations, consultez Utiliser le code Genie .
Les notebooks Databricks incluent également un débogueur interactif intégré pour les notebooks Python. Voir Déboguer les blocs-notes.
Importante
Le notebook doit être attaché à une session active compute pour les fonctionnalités d’assistance au code, notamment la saisie semi-automatique, la mise en forme de code Python et le débogueur.
Modulariser votre code
Avec Databricks Runtime 11.3 LTS et versions ultérieures, vous pouvez créer et gérer des fichiers de code source dans l’espace de travail Azure Databricks, puis importer ces fichiers dans vos notebooks en fonction des besoins.
Pour plus d’informations sur l’utilisation des fichiers de code source, consultez Partager du code entre les notebooks Databricks et Travailler avec des modules Python et R.
Mettre en forme les cellules de code
Azure Databricks fournit des outils qui vous permettent de formater le code Python et SQL dans les cellules du notebook. Ces outils réduisent l’effort de mise en forme de votre code et d’application des mêmes normes de codage dans vos notebooks.
bibliothèque de formateur noir Python
Importante
Cette fonctionnalité est disponible en préversion publique.
Azure Databricks prend en charge la mise en forme de code Python à l’aide de black dans le notebook. Le notebook doit être attaché à un cluster avec des packages black et tokenize-rt Python installés.
Sur Databricks Runtime 11.3 LTS et versions ultérieures, Azure Databricks préinstalle black et tokenize-rt. Vous pouvez utiliser le formateur directement sans qu’il soit nécessaire d’installer ces bibliothèques.
Sur Databricks Runtime 10.4 LTS et ci-dessous, vous devez installer black==22.3.0 et tokenize-rt==4.2.1 à partir de PyPI sur votre notebook ou cluster pour utiliser le formateur Python. Vous pouvez exécuter la commande suivante dans votre notebook :
%pip install black==22.3.0 tokenize-rt==4.2.1
ou Installer la bibliothèque sur votre cluster.
Pour plus d’informations sur l’installation des bibliothèques, consultez Python gestion de l’environnement.
Pour les fichiers et les notebooks dans les répertoires Git de Databricks, vous pouvez configurer le formateur Python en fonction du fichier pyproject.toml. Pour utiliser cette fonctionnalité, créez un fichier pyproject.toml dans le répertoire racine du dossier Git et configurez-le en suivant le format de configuration Black. Modifiez la section [tool.black] dans le fichier. La configuration est appliquée lorsque vous mettez en forme un fichier ou un notebook dans ce dossier Git.
Comment formater les cellules Python et SQL
Vous devez avoir l'autorisation de modification sur le notebook pour mettre en forme le code.
Azure Databricks utilise un formateur SQL personnalisé pour mettre en forme SQL et le formateur de code black pour Python.
Vous pouvez déclencher l’outil de mise en forme des manières suivantes :
Mettre en forme une cellule unique
- Raccourci clavier : appuyez sur Cmd + Maj + F.
- Menu contextuel de commande :
- Mettre en forme la cellule SQL : sélectionnez Mettre en forme le code SQL dans le menu contextuel déroulant de la commande d’une cellule SQL. Cet élément de menu est visible uniquement dans les cellules de notebook SQL ou celles contenant une
%sqlcommande magic de langage. - Format Python cellule : sélectionnez Format Python dans le menu déroulant contextuel de commande d’une cellule Python. Cet élément de menu n’est visible que dans les cellules de bloc-notes Python ou celles avec une
%pythonmagie du langage.
- Mettre en forme la cellule SQL : sélectionnez Mettre en forme le code SQL dans le menu contextuel déroulant de la commande d’une cellule SQL. Cet élément de menu est visible uniquement dans les cellules de notebook SQL ou celles contenant une
- Menu Edit : sélectionnez une cellule Python ou SQL, puis sélectionnez Edit > Format de cellule(s) .
Mettre en forme plusieurs cellules
Sélectionnez plusieurs cellules, puis sélectionnez Modifier > Mettre en forme les cellules. Si vous sélectionnez des cellules de plusieurs langues, seules SQL et Python cellules sont mises en forme. Il s’agit notamment de celles qui utilisent
%sqlet%python.Formater toutes les cellules Python et SQL dans le notebook
Sélectionnez >. Si votre bloc-notes contient plusieurs langues, seules SQL et Python cellules sont mises en forme. Il s’agit notamment de celles qui utilisent
%sqlet%python.
Pour personnaliser la mise en forme de vos requêtes SQL, consultez les instructions SQL de format personnalisé.
Limitations de la mise en forme du code
- Black applique les normes PEP 8 pour la mise en retrait à 4 espaces. La mise en retrait n’est pas configurable.
- La mise en forme des chaînes de Python incorporées à l’intérieur d’une fonction UDF SQL n’est pas prise en charge. De même, la mise en forme de chaînes SQL à l’intérieur d’une fonction UDF Python n’est pas prise en charge.
Langages de programmation dans les blocs-notes
Configurer la langue par défaut
La langue par défaut du bloc-notes apparaît sous le nom du bloc-notes.

Pour modifier le langage par défaut, cliquez sur le bouton langage et sélectionnez le nouveau langage dans le menu déroulant. Pour vous assurer que les commandes existantes continuent de fonctionner, les commandes de la langue par défaut précédente sont automatiquement précédées d'une commande magique de langue.
Mélanger les langages
Par défaut, les cellules utilisent le langage par défaut du notebook. Vous pouvez modifier le langage par défaut dans une cellule en cliquant sur le bouton Langage et en sélectionnant un langage dans la liste déroulante.
Vous pouvez également utiliser la commande %<language> magique de langue au début d’une cellule. Les commandes magic prises en charge sont les suivantes : %python, %r, %scala et %sql.
Remarque
Lorsque vous appelez une commande magic de langage, la commande est distribuée à la REPL dans le contexte d’exécution du notebook. Les variables définies dans un langage (et par conséquent dans la REPL pour ce langage) ne sont pas disponibles dans la REPL d’un autre langage. Les REPLS peuvent partager l’état uniquement via des ressources externes telles que des fichiers dans DBFS ou des objets dans le stockage d’objets.
Les notebooks prennent également en charge quelques commandes magiques auxiliaires :
-
%sh: vous permet d’exécuter du code Shell dans votre notebook. Pour faire échouer la cellule si la commande de l’interpréteur de commandes a un état de sortie différent de zéro, ajoutez l’option-e. Cette commande s’exécute uniquement sur le pilote Apache Spark, et non sur les threads de travail. Pour exécuter une commande d’interpréteur de commandes sur tous les nœuds, utilisez un script init. -
%fs: vous permet d’utiliser les commandes du système de fichiersdbutils. Par exemple, pour exécuter la commandedbutils.fs.lspour répertorier les fichiers, vous pouvez spécifier%fs lsà la place. Pour plus d'informations, consultez Travailler avec des fichiers sur Azure Databricks. -
%md: vous permet d’inclure différents types de documentation, notamment du texte, des images, des formules mathématiques et des équations. Voir la section suivante.
Mise en surbrillance de la syntaxe SQL et saisie semi-automatique dans les commandes Python
La mise en surbrillance de la syntaxe et SQL autocomplete sont disponibles lorsque vous utilisez SQL à l’intérieur d’une commande Python, par exemple dans une commande spark.sql.
Explorer les résultats des cellules SQL
Dans un notebook Databricks, les résultats d’une cellule de langage SQL sont automatiquement mis à disposition en tant que DataFrame implicite affecté à la variable _sqldf. Vous pouvez ensuite utiliser cette variable dans n'importe quelle cellule Python et SQL que vous exécutez ultérieurement, quelle que soit leur position dans le notebook.
Remarque
Cette fonctionnalité présente les limitations suivantes :
- La
_sqldfvariable n’est pas disponible dans les notebooks qui utilisent un entrepôt de données SQL pour réaliser des calculs. - L’utilisation de
_sqldfdans les cellules de Python suivantes est prise en charge dans Databricks Runtime 13.3 et versions ultérieures. - L’utilisation
_sqldfdans les cellules SQL suivantes n’est prise en charge que sur Databricks Runtime 14.3 et versions ultérieures. - Si la requête utilise les mots clés
CACHE TABLEouUNCACHE TABLEque la_sqldfvariable n’est pas disponible.
La capture d’écran ci-dessous montre comment _sqldf pouvez être utilisé dans les cellules Python et SQL suivantes :
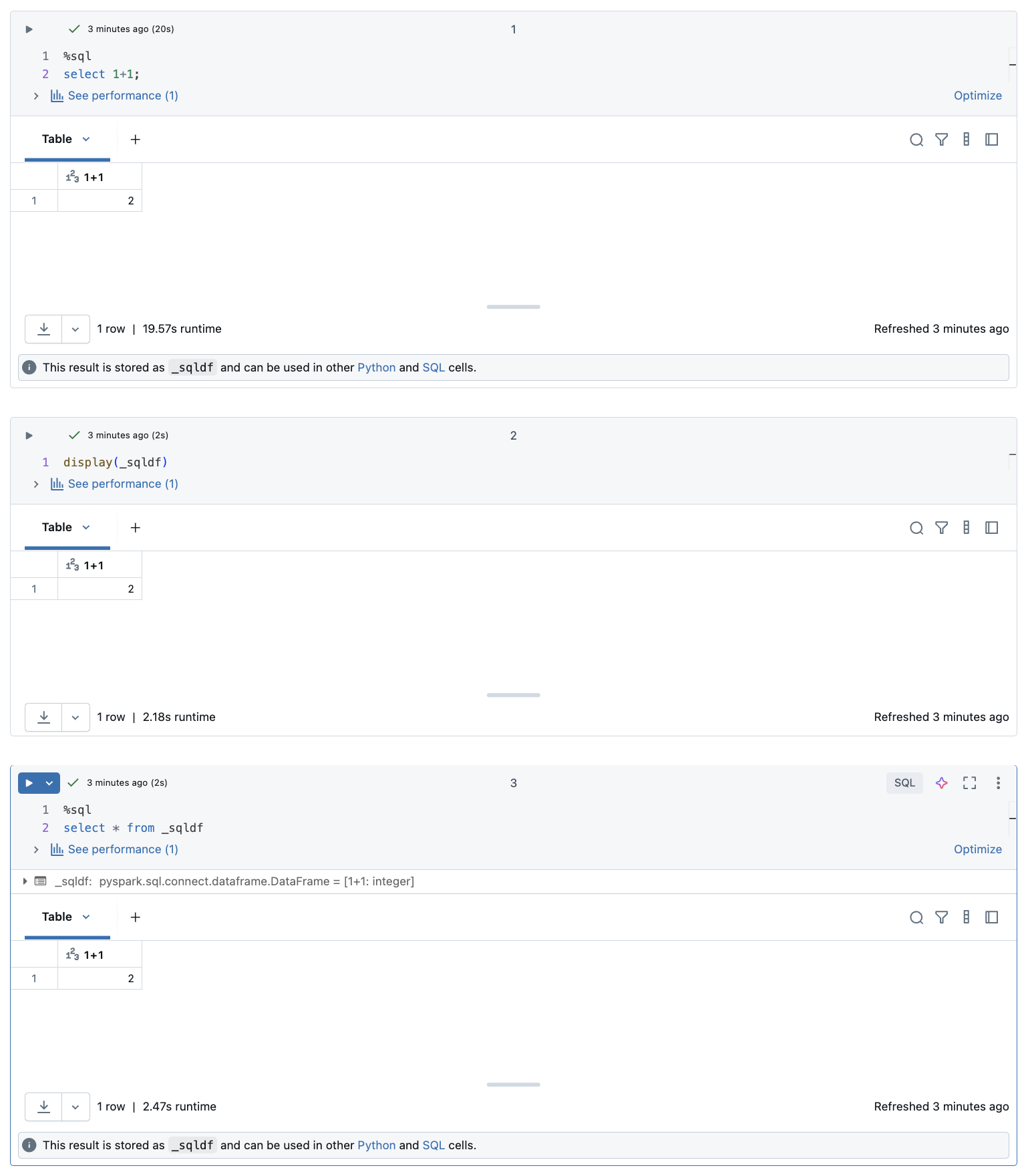
Importante
La variable _sqldf est réaffectée chaque fois qu’une cellule SQL est exécutée. Pour éviter de perdre la référence à un résultat dataFrame spécifique, affectez-le à un nouveau nom de variable avant d’exécuter la cellule SQL suivante :
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
Exécuter des cellules SQL en parallèle
Lorsqu’une commande est en cours d’exécution et que votre notebook est attaché à un cluster interactif, vous pouvez exécuter une cellule SQL simultanément avec la commande active. La cellule SQL est exécutée dans une nouvelle session parallèle.
Pour exécuter une cellule en parallèle :
Cliquez sur Exécuter maintenant. La cellule est immédiatement exécutée.
Étant donné que la cellule est exécutée dans une nouvelle session, les vues temporaires, les fonctions définies par l’utilisateur et les DataFrames Python implicites () ne sont pas pris en charge pour les cellules exécutées en parallèle. En outre, les noms de catalogue et de base de données par défaut sont utilisés pendant l’exécution parallèle. Si votre code fait référence à une table dans un autre catalogue ou une autre base de données, vous devez spécifier le nom de la table à l’aide d’un espace de noms à trois niveaux (catalog.schema.table).
Exécuter des cellules SQL sur un entrepôt SQL
Vous pouvez exécuter des commandes SQL dans un notebook Databricks dans un entrepôt SQL, un type de calcul optimisé pour l’analytique SQL. Consultez l’article Utiliser un notebook avec un entrepôt SQL.
Utiliser des commandes magiques
Les notebooks Databricks prennent en charge différentes commandes magiques qui étendent les fonctionnalités au-delà de la syntaxe standard pour simplifier les tâches courantes. Les magies de ligne sont préfixées % et s’appliquent à une seule ligne. Les magies des cellules sont préfixées par %% et s’appliquent à l’ensemble du corps de la cellule.
| Commande magique | Exemple | Description |
|---|---|---|
%python |
%pythonprint("Hello") |
Basculez la langue de cellule vers Python. Exécute le code Python dans la cellule. |
%r |
%rprint("Hello") |
Basculez le langage de cellule vers R. Exécute le code R dans la cellule. |
%scala |
%scalaprintln("Hello") |
Changez la langue de cellule en Scala. Exécute le code Scala dans la cellule. |
%sql |
%sqlSELECT * FROM table |
Changez la langue de la cellule en SQL. Les résultats sont disponibles sous forme de _sqldf dans les cellules Python/SQL. |
%md |
%md# TitleContent here |
Changez la langue de cellule en Markdown. Affiche le contenu Markdown dans la cellule. Prend en charge le texte, les images, les formules et LaTeX. |
%pip |
%pip install pandas |
Installez des paquets Python (à l'échelle du notebook). Consultez les bibliothèques Python à l'échelle du notebook. |
%run |
%run /path/to/notebook |
Exécutez un autre notebook, en important ses fonctions et variables. Consultez les processus de travail des notebooks. |
%fs |
%fs ls /path |
Exécutez les commandes du système de fichiers dbutils. Raccourci de commandes dbutils.fs. Consultez Utiliser des fichiers. |
%sh |
%sh ls -la |
Exécutez des commandes shell. S’exécute uniquement sur le nœud du pilote. Utilisez -e pour échouer en cas d'erreur. |
%tensorboard |
%tensorboard --logdir /logs |
Afficher l’interface utilisateur TensorBoard inline. Disponible uniquement sur Databricks Runtime ML. Voir TensorBoard. |
%set_cell_max_output_size_in_mb |
%set_cell_max_output_size_in_mb 10 |
Définissez la taille maximale de sortie de cellule. Plage : 1 à 20 Mo. S’applique à toutes les cellules suivantes du bloc-notes. |
%skip |
%skipprint("This won't run") |
Ignorez l’exécution des cellules. Empêche la cellule de s'exécuter lorsque le notebook est exécuté. |
%%profile |
%%profilemy_function() |
Profiler l'exécution du code Python. Affiche une arborescence d’appels hiérarchiques avec des informations de minutage. Nécessite Databricks Runtime 17.2 et versions ultérieures. |
%%oprofile |
%%oprofilemy_function() |
Création d’objets de profil pendant l’exécution des cellules. Affiche une table des nouveaux objets nets créés, regroupés par type. Nécessite Databricks Runtime 17.2 et versions ultérieures. |
%uv pip |
%uv pip install simplejson |
Installez et gérez des paquets Python (limités au notebook) avec uv et les sous-commandes pip standard (install, uninstall, list, show, freeze, check, tree). Voir les installations plus rapides avec %uv pip. |
Remarque
IPython Automagic : Les notebooks Databricks ont IPython automagic activé par défaut, ce qui permet à certaines commandes de pip fonctionner sans le % préfixe. Par exemple, pip install pandas fonctionne de la même façon que %pip install pandas.
Importante
- Les variables et l’état sont isolés entre les différentes langues REPL. Par exemple, les variables Python ne sont pas accessibles dans les cellules Scala.
- Une cellule de bloc-notes ne peut avoir qu'une seule commande magique, qui doit être placée en première ligne de la cellule.
-
%rundoit se trouver seul dans une cellule, car il exécute l’intégralité du bloc-notes en ligne. - Lorsque vous utilisez
%pipsur Databricks Runtime 12.2 LTS ou antérieure, assurez-vous de placer toutes les commandes d'installation des paquets au début de votre notebook, car l'état Python est réinitialisé après l'installation.