Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cette page couvre les options des ressources de calcul de notebook. Vous pouvez exécuter un notebook sur une ressource de calcul polyvalente, un calcul sans serveur ou, pour les commandes SQL, utiliser un entrepôt SQL, un type de calcul optimisé pour l’analytique SQL. Pour plus d’informations sur les types de calcul, consultez Calcul.
Calcul par défaut
Dans les espaces de travail activés pour le catalogue Unity, les nouveaux notebooks sont configurés par défaut pour le calcul serverless. Si vous ne sélectionnez pas manuellement une ressource de calcul et que vous exécutez une cellule, le notebook se connecte automatiquement au calcul sans serveur.
Connexion automatique des ressources de calcul
Dans les paramètres de votre développeur, vous pouvez configurer des notebooks pour qu’ils s’attachent automatiquement à une ressource de calcul et démarrent une session lorsque vous interagissez avec l’éditeur :
Cliquez sur l’icône de votre utilisateur en haut à gauche.
Cliquez sur Paramètres.
Cliquez sur Développeur pour accéder aux paramètres de votre développeur.
Basculez sur Créer automatiquement une session sur l’interaction de l’éditeur pour démarrer automatiquement une session de calcul sur l’interaction de l’éditeur. Databricks utilise par défaut une ressource de calcul en fonction de vos préférences (serverless ou SQL Warehouse) et de la dernière ressource de calcul utilisée.
OR
Désactivez ce paramètre si vous ne souhaitez pas que le notebook se connecte automatiquement et démarre une ressource de calcul.
Les fonctionnalités d’assistance au code, notamment la saisie semi-automatique, la mise en forme du code et le débogueur, nécessitent que le notebook soit attaché à une session de calcul active. Si le notebook n’a pas démarré une session de calcul, les fonctionnalités d’assistance au code sont inactives.
Calcul serverless pour les notebooks
Le calcul serverless vous permet de vous connecter rapidement votre notebook à des ressources informatiques à la demande.
Pour vous attacher au calcul serverless, cliquez sur le menu déroulant calcul dans le bloc-notes, puis sélectionnez Serverless.
Pour en savoir plus, consultez Calcul serverless pour les notebooks.
Restauration de session automatisée pour les cahiers sans serveur
L'arrêt pour cause d'inactivité du calcul serverless peut vous entraîner à perdre le travail en cours, telles que les valeurs de variables Python dans vos notebooks. Pour éviter cela, activez la restauration de session automatisée pour les notebooks serverless.
- Cliquez sur votre nom d’utilisateur en haut à droite de votre espace de travail, puis cliquez sur Paramètres dans la liste déroulante.
- Dans la barre latérale des Paramètres, sélectionnez Développeur.
- Sous Fonctionnalités expérimentales, activez la restauration de session automatisée pour les notebooks sans serveur.
L’activation de ce paramètre permet à Databricks de prendre un instantané de l’état de mémoire du notebook sans serveur avant l’arrêt pour inactivité. Lorsque vous revenez à un bloc-notes après une déconnexion inactive, une bannière apparaît en haut de la page. Cliquez sur Reconnecter pour restaurer votre état de travail.
Lorsque vous vous reconnectez, Databricks rétablit l’ensemble de votre environnement de travail, notamment :
- Variables, fonctions et définitions de classes Python : l'état de Python est sérialisé à l'intérieur du processus à l’aide de pickle/cloudpickle et restauré dans un nouveau REPL. Vous n’avez donc pas besoin de réimporter ou de redéclarer.
- DataFrames Spark, vues mises en cache et temporaires : les données que vous avez chargées, transformées ou mises en cache (y compris les vues temporaires) sont conservées. Vous évitez donc le rechargement coûteux ou la recomputation.
- État de session Spark : les paramètres de configuration au niveau spark, les vues temporaires, les modifications de catalogue et les fonctions définies par l’utilisateur sont restaurés via la migration de session Spark Connect. Vous n’avez donc pas besoin de les réinitialiser.
Si l’environnement a changé d’une manière qui rend la désérialisation non sécurisée, par exemple, des versions incompatibles de Python ou de package, l’instantané est invalidé et le notebook revient à une nouvelle session.
Stockage des données d’instantané
Les données d’instantané sont stockées dans le stockage par défaut de votre espace de travail. Le notebook lui-même stocke uniquement les métadonnées, y compris un pointeur avec l’ID de bloc-notes, un horodatage et des informations de session. La charge utile des données n’est pas stockée dans le notebook. Les chemins d’accès d’objets blob sont chiffrés avant d’être stockés dans des attributs de notebook, et les chemins d’instantané sont exclus de l’exportation et de l’importation de notebook pour empêcher la restauration de l’état dans un autre espace de travail.
Les instantanés suivent les valeurs par défaut de votre durée de vie de stockage cloud (environ un mois) et expirent automatiquement. La suppression d’un bloc-notes supprime également ses instantanés. Votre compte cloud entraîne des coûts de stockage dans le cadre de l’utilisation standard du stockage de l’espace de travail. La fonctionnalité utilise la sérialisation de processus Python au lieu de la sauvegarde au niveau du conteneur, ce qui permet de réduire la taille des instantanés et d'accélérer leur création.
Sécurité et contrôle d'accès
La restauration d’instantané respecte les autorisations de bloc-notes. La restauration de l’état nécessite l’autorisation RUN sur le notebook. Les métadonnées chiffrées empêchent les utilisateurs de récupérer directement des blobs d’instantanés, et les vérifications d’autorisation sont appliquées lors de la restauration.
Limites
Cette fonctionnalité présente des limitations et ne prend pas en charge la restauration des éléments suivants :
- États Spark antérieurs à 4 jours
- États Spark supérieurs à 50 Mo
- Données relatives à l’écriture de scripts SQL
- Descripteurs de fichiers
- Verrous et autres primitives de concurrence
- Connexions réseau
Attacher un notebook à une ressource de calcul à usage général
Pour attacher un notebook à une ressource de calcul à usage unique, vous avez besoin de l’autorisation CAN ATTACH TO sur la ressource de calcul.
Important
Tant qu’un bloc-notes est attaché à une ressource de calcul, tout utilisateur disposant de l’autorisation CAN RUN sur le notebook dispose d’une autorisation implicite pour accéder à la ressource de calcul.
Pour attacher un bloc-notes à une ressource de calcul, cliquez sur le sélecteur de calcul dans la barre d’outils du bloc-notes et sélectionnez la ressource dans le menu déroulant.
Le menu affiche une sélection de calcul à usage unique et d’entrepôts SQL que vous avez utilisés récemment ou qui sont en cours d’exécution.
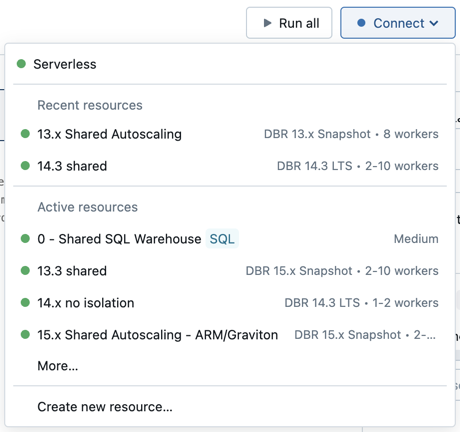
Pour sélectionner parmi toutes les ressources de calcul disponibles, cliquez sur Plus.... Sélectionnez parmi les entrepôts de calcul généraux ou SQL disponibles.
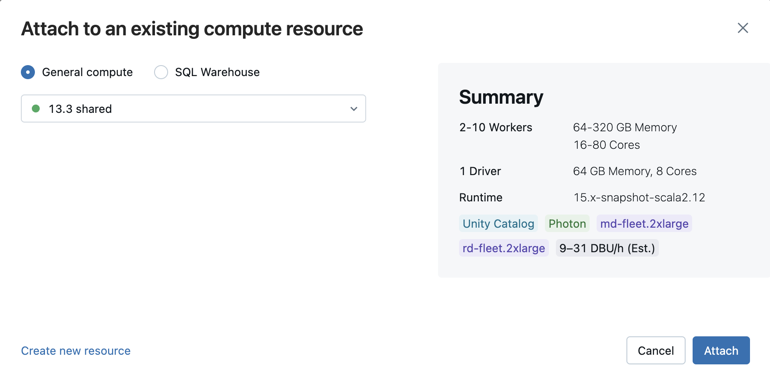
Vous pouvez également créer une ressource de calcul à usage général en sélectionnant Créer une ressource... dans le menu déroulant.
Important
Les variables Apache Spark suivantes sont définies pour un notebook attaché.
| Classe | Nom de la variable |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
Ne créez pas un SparkSession, SparkContextou SQLContext. Cela conduit à un comportement incohérent.
Utiliser un notebook avec un entrepôt SQL
Lorsqu’un notebook est attaché à un entrepôt SQL, vous pouvez exécuter des cellules SQL et Markdown. L’exécution d’une cellule dans n’importe quel autre langage (tel que Python ou R) génère une erreur. Les cellules SQL exécutées sur un entrepôt SQL apparaissent dans l’historique des requêtes de l’entrepôt SQL. L’utilisateur qui a exécuté une requête peut afficher le profil de requête à partir du notebook en cliquant sur la durée écoulée en bas de la sortie.
Les notebooks attachés aux entrepôts SQL prennent en charge les sessions SQL Warehouse, où vous pouvez définir des variables, créer des vues temporaires et conserver l’état sur plusieurs exécutions de requête. Vous pouvez générer une logique SQL de manière itérative sans avoir à exécuter toutes les instructions en même temps. Découvrez quelles sont les sessions SQL Warehouse ?.
L’exécution d’un notebook nécessite un entrepôt SQL professionnel ou serverless. Vous devez avoir accès à l’espace de travail et à l’entrepôt SQL.
Pour attacher un notebook à un entrepôt SQL, procédez comme suit :
Cliquez sur le sélecteur de calcul dans la barre d’outils du notebook. Le menu déroulant affiche les ressources de calcul en cours d’exécution ou que vous avez utilisées récemment. Les entrepôts SQL sont marqués comme suit :
 .
.Dans le menu, sélectionnez un entrepôt SQL.
Pour afficher tous les entrepôts SQL disponibles, sélectionnez Plus... dans le menu déroulant. Une boîte de dialogue indique les ressources de calcul disponibles pour le notebook. Sélectionnez SQL Warehouse, sélectionnez l’entrepôt que vous souhaitez utiliser, puis cliquez sur Attacher.
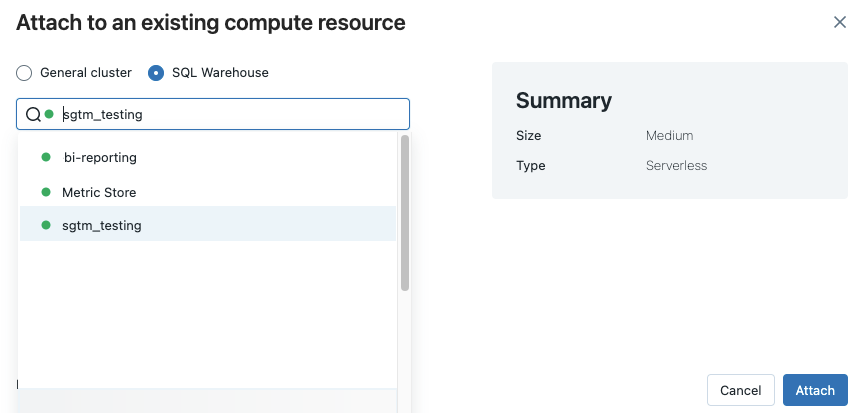
Vous pouvez également sélectionner un entrepôt SQL comme ressource de calcul pour un notebook SQL à la création d’un workflow ou d’un travail planifié.
Limitations des entrepôts SQL
Pour plus d’informations, consultez les limitations connues des notebooks Databricks.