Juillet 2019
Ces fonctionnalités et améliorations de la plateforme Azure Databricks ont été publiées en juillet 2019.
Notes
Les publications se font par étapes. Votre compte Azure Databricks peut ne pas être mis à jour jusqu’à une semaine après la date de publication initiale.
Bientôt : Databricks 6.0 ne prendra plus en charge Python 2
En prévision de la fin de vie prochaine de Python 2, annoncée en 2020, Python 2 ne sera pas pris en charge dans Databricks Runtime 6.0. Les versions antérieures de Databricks Runtime continuent à prendre en charge Python 2. Nous prévoyons de publier Databricks Runtime 6.0 plus tard en 2019.
Précharger la version de Databricks Runtime sur les instances inactives du pool
30 juillet - 6 août 2019 : version 2.103
Vous pouvez maintenant accélérer les lancements du cluster sauvegardé en pool en sélectionnant une version de Databricks Runtime à charger sur les instances inactives dans le pool. Le champ dans l’interface utilisateur du pool est appelé Version Spark préchargée.

Les étiquettes de cluster personnalisées et les étiquettes de pool sont plus efficaces ensemble
30 juillet - 6 août 2019 : version 2.103
Plus tôt ce mois-ci, Azure Databricks a présenté des pools, un ensemble d’instances inactives qui vous aideront à créer rapidement des clusters. Dans la version originale, les clusters sauvegardés en pool ont hérité des étiquettes par défaut et personnalisées de la configuration du pool, et vous ne pouvez pas modifier ces étiquettes au niveau du cluster. Vous pouvez maintenant configurer des étiquettes personnalisées spécifiques à un cluster sauvegardé en pool, et ce cluster appliquera toutes les étiquettes personnalisées, qu’elles soient héritées du pool ou affectées spécifiquement à ce cluster. Vous ne pouvez pas ajouter une étiquette personnalisée spécifique au cluster avec le même nom de clé qu’une étiquette personnalisée héritée d’un pool (autrement dit, vous ne pouvez pas substituer une étiquette personnalisée qui est héritée du pool). Pour plus d’informations, consultez Étiquettes de pool.
MLflow 1.1 apporte plusieurs améliorations au niveau de l’interface utilisateur et des API
30 juillet - 6 août 2019 : version 2.103
MLflow 1.1 introduit plusieurs nouvelles fonctionnalités pour améliorer l’interface utilisateur et l’utilisation de l’API :
L’interface utilisateur avec vue d’ensemble des exécutions vous permet désormais de parcourir plusieurs pages d’exécutions si le nombre d’exécutions est supérieur à 100. Après la 100 e exécution, cliquez sur le bouton Charger plus pour charger les 100 exécutions suivantes.
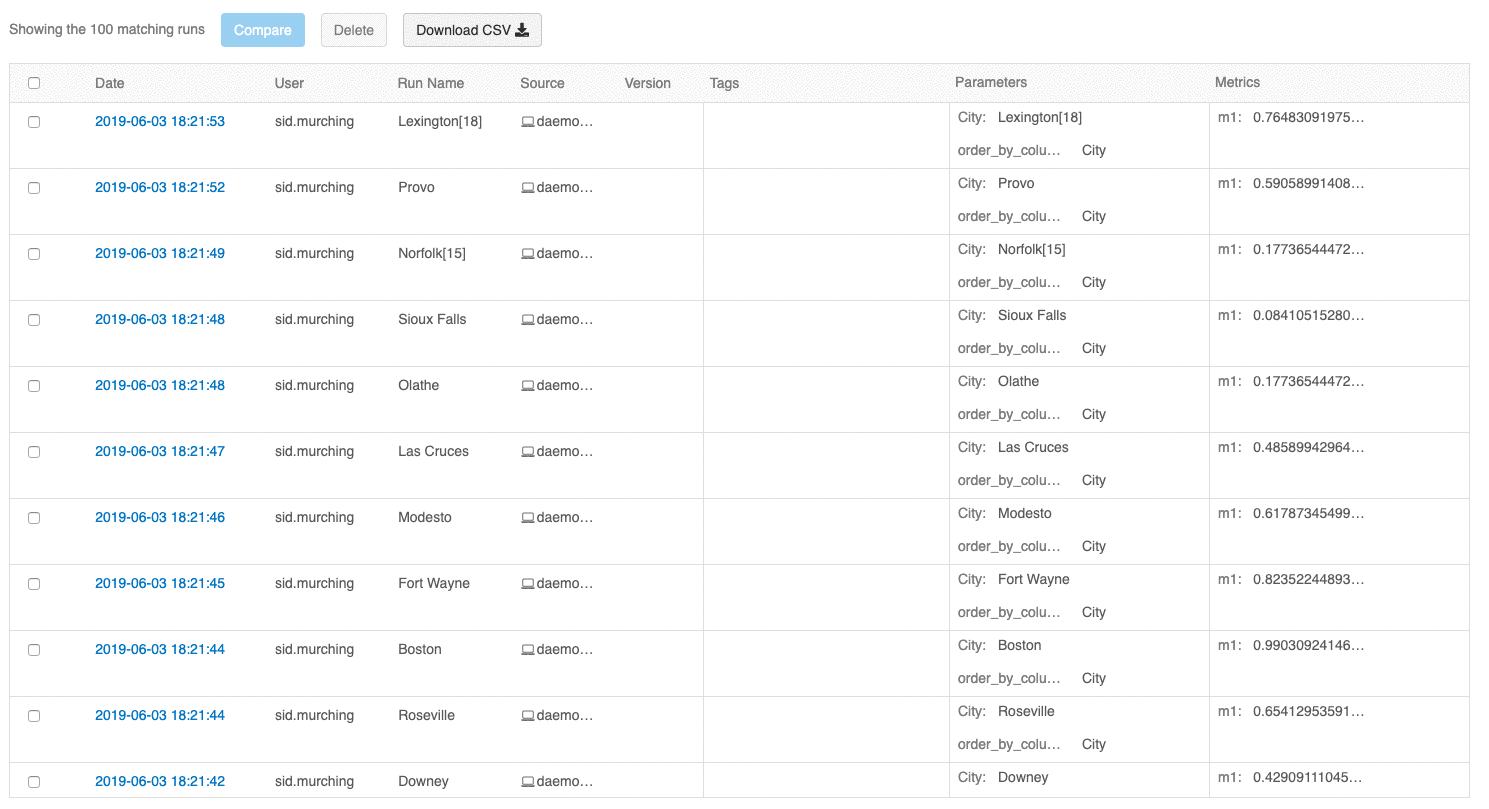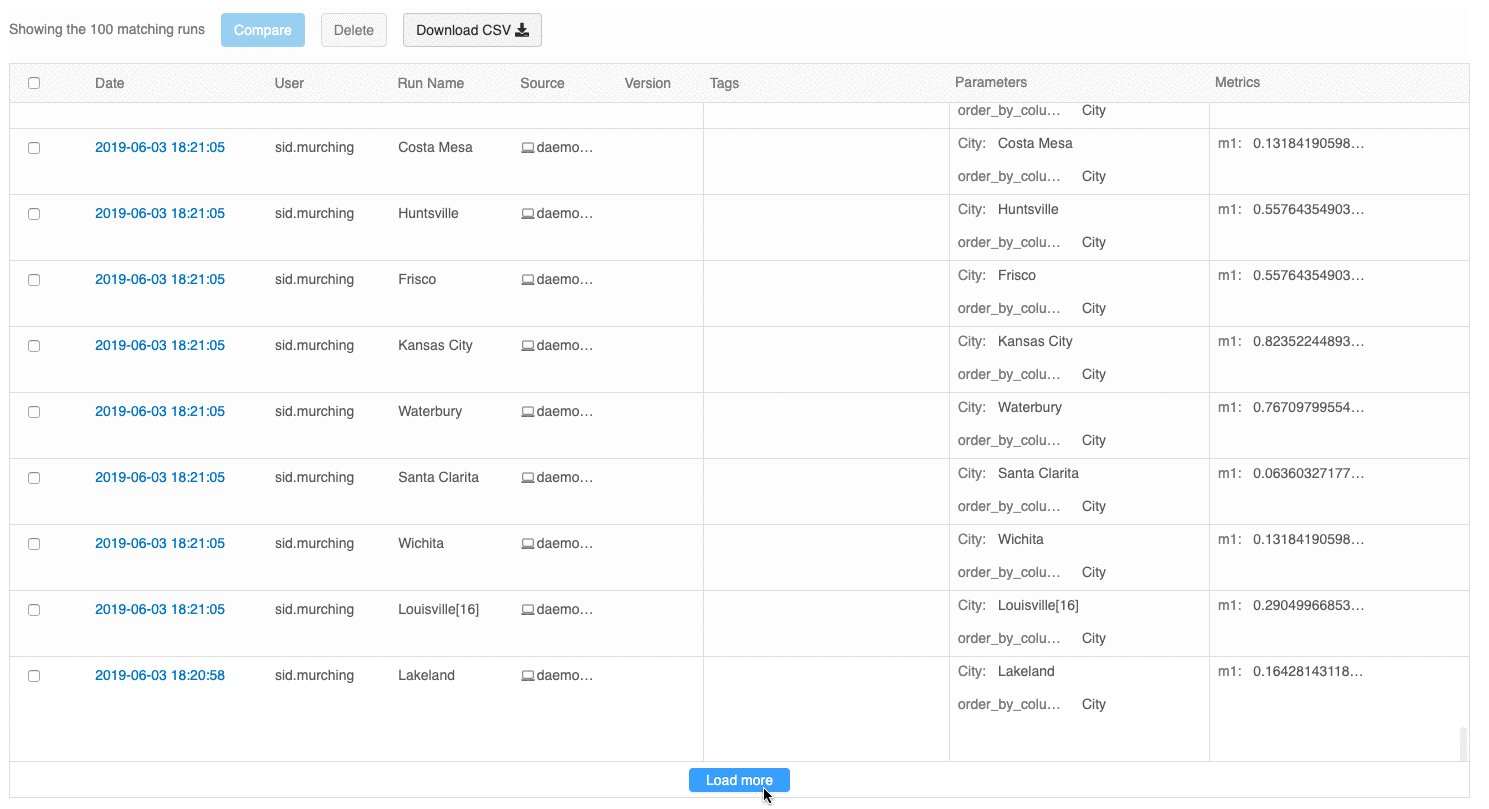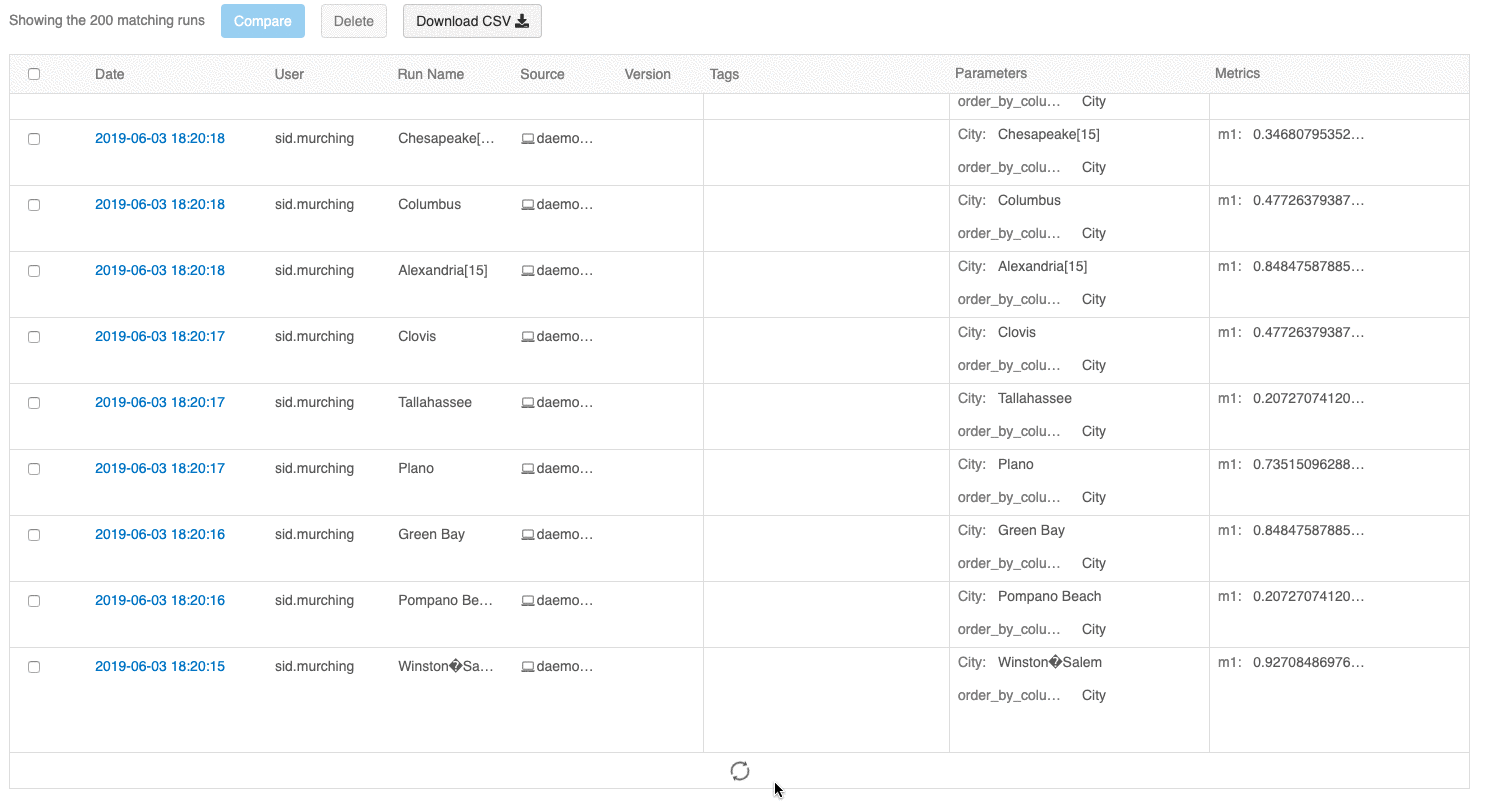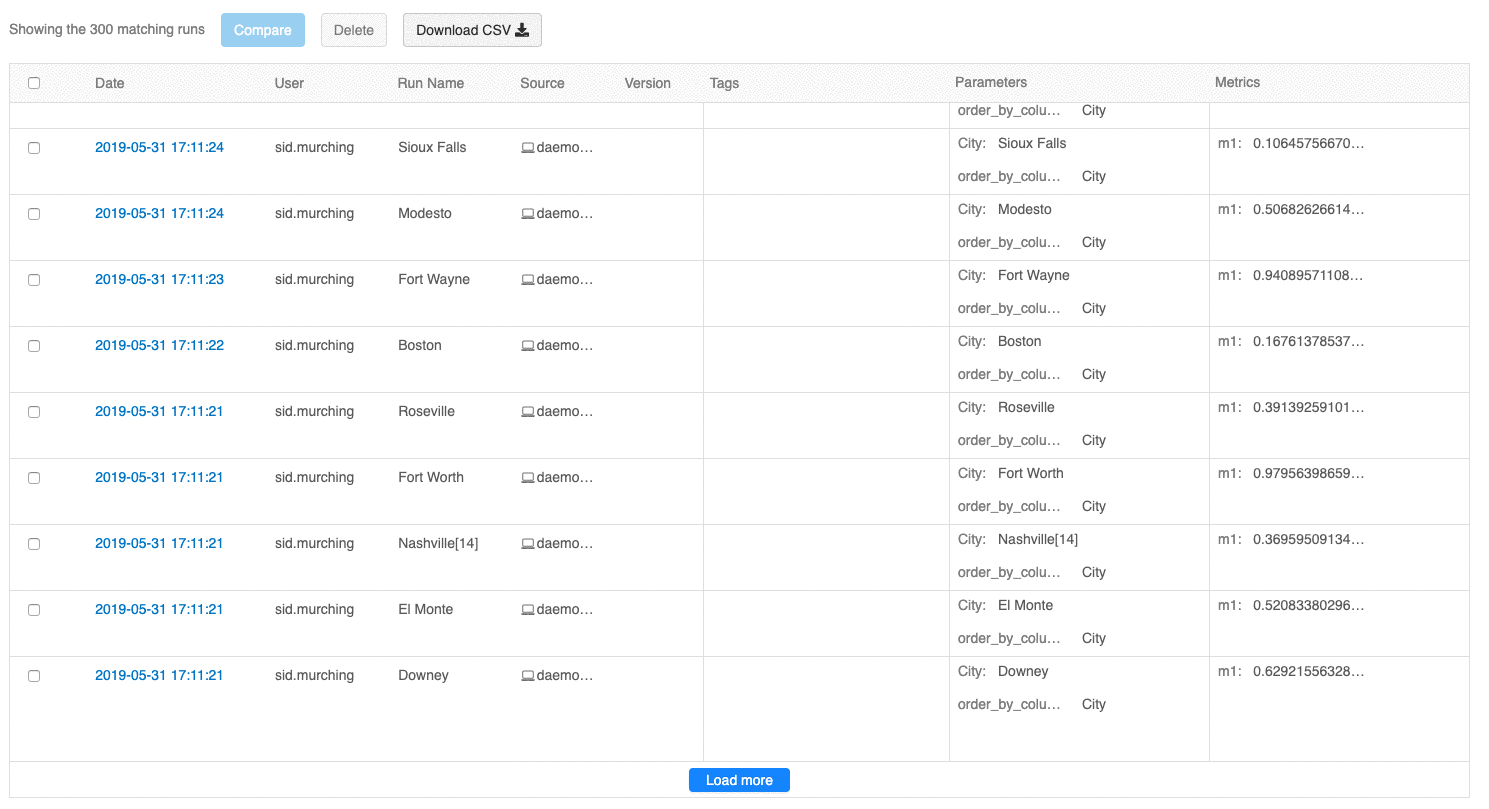
L’interface utilisateur de comparaison des exécutions fournit maintenant un tracé de coordonnées parallèles. Le tracé vous permet d’observer les relations entre un ensemble de paramètres et de métriques à n dimensions. Il visualise toutes les exécutions sous forme de lignes codées par couleur en fonction de la valeur d’une métrique (par exemple, la précision) et affiche les valeurs de paramètre sur lesquelles chaque exécution s’est produite.

Vous pouvez maintenant ajouter et modifier des étiquettes à partir de l’interface utilisateur de vue d’ensemble des exécutions et afficher les étiquettes dans la vue de recherche des expériences.
La nouvelle API MLflowContext vous permet de créer et de consigner les exécutions d'une manière similaire à l'API Python. Cette API contraste avec l'API de bas niveau
MlflowClientexistante, qui se contente d'encapsuler les API REST.Vous pouvez désormais supprimer les étiquettes des exécutions MLflow en utilisant l'API DeleteTag.
Pour plus de détails, voir le billet de blog MLflow 1.1. Pour voir la liste complète des fonctionnalités et des correctifs, consultez le Journal des modifications MLflow.
Les tramedonnées pandas s’affichent comme dans Jupyter
30 juillet - 6 août 2019 : version 2.103
Désormais, lorsque vous appelez une table pandas, celle-ci s’affiche de la même façon que dans Jupyter.
Nouvelles régions
30 juillet 2019
Azure Databricks est désormais disponible dans les régions supplémentaires suivantes :
- Centre de la Corée
- Afrique du Sud Nord
Databricks Runtime 5.5 avec Conda (version bêta)
23 juillet 2019
Important
Databricks Runtime avec Conda est en version bêta. Le contenu des environnements pris en charge peut varier dans les prochaines versions bêta. Les modifications peuvent inclure la liste des packages ou des versions de packages installés. Databricks Runtime 5.5 avec Conda s’appuie sur Databricks Runtime 5.5 LTS (non pris en charge).
La version 5.5 de Databricks Runtime avec Conda ajoute une nouvelle API de bibliothèque adaptée au notebook pour prendre en charge la mise à jour de l'environnement Conda du notebook avec une spécification YAML (voir la documentation Conda).
Consultez les notes de publication complètes sur Databricks Runtime 5.5 avec Conda (non pris en charge).
Mise à jour de la limite de connexions au metastore
16-23 juillet 2019 : version 2.102
Les nouveaux espaces de travail Azure Databricks dans eastus, eastus2, centralus, westus, westus2, westeurope, northeurope auront une limite de connexion de metastore supérieure (250). Les espaces de travail existants continuent à utiliser le metastore actuel sans interruption, avec une limite de connexion de 100.
Définir des autorisations sur les pools (préversion publique)
16-23 juillet 2019 : version 2.102
L’interface utilisateur du pool permet désormais de désigner les personnes autorisées à gérer les pools et celles qui peuvent joindre des clusters à des pools.
Pour plus d’informations, consultez Autorisations du pool.
Databricks Runtime 5.5 pour le Machine Learning
15 juillet 2019
Databricks Runtime 5.5 ML s’appuie sur Databricks Runtime 5.5 LTS (non pris en charge). Il contient de nombreuses bibliothèques de Machine Learning courantes, notamment TensorFlow, PyTorch, keras et XGBoost, et fournit une formation TensorFlow distribuée à l’aide de Horovod.
Cette version inclut les nouvelles fonctionnalités et améliorations suivantes :
- Ajout du package Python MLflow 1.0
- Mise à niveau des bibliothèques de Machine Learning
- TensorFlow mise à niveau de 1.12.0 vers 1.13.1
- PyTorch mise à niveau de 0.4.1 vers 1.1.0
- scikit-learn mise à niveau de 0.19.1 vers 0.20.3
- Opération à un seul nœud pour HorovodRunner
Pour plus de détails, voir Databricks Runtime 5.5 LTS pour ML (non pris en charge).
Databricks Runtime 5.5
15 juillet 2019
Databricks Runtime 5.5 est maintenant disponible. Databricks Runtime 5.5 inclut Apache Spark 2.4.3, les bibliothèques Python, R, Java et Scala, ainsi que les nouvelles fonctionnalités suivantes :
- Disponibilité générale de l’optimisation automatique Delta Lake sur Azure Databricks
- Delta Lake sur Azure Databricks a amélioré les performances des requêtes d'agrégation min, max et count
- Pipelines d'inférence de modèles plus rapides avec une source de données de fichiers binaires améliorée et un itérateur scalaire UDF pandas (préversion publique)
- API Secrets dans les blocs-notes R
Pour plus de détails, voir Databricks Runtime 5.5 LTS (non pris en charge).
Conserver un pool d’instances en veille pour un lancement rapide du cluster (préversion publique)
9-11 juillet 2019 : version 2.101
Pour réduire l’heure de début du cluster, Azure Databricks prend désormais en charge l’attachement d’un cluster à un pool prédéfini d’instances inactives. Quand un cluster est attaché à un pool, il alloue ses nœuds de pilote et worker à partir du pool. Si le pool ne dispose pas des ressources inactives suffisantes pour répondre à la demande du cluster, il se développe en allouant de nouvelles instances à partir du fournisseur de cloud. Quand un cluster attaché est arrêté, les instances qu’il utilisait sont retournées au pool et peuvent être réutilisées par un autre cluster.
Azure Databricks ne facture pas de DBU durant le temps d’inactivité des instances dans le pool. La facturation du fournisseur d’instances s’applique par contre. Consultez les tarifs.
Pour plus de détails, consultez Informations de référence sur la configuration de pool.
Mesures Ganglia
9-11 juillet 2019 : version 2.101
Ganglia est un système de supervision distribué et évolutif qui est désormais disponible sur les clusters Azure Databricks. Les métriques Ganglia vous aident à superviser les performances et l’intégrité du cluster. Vous pouvez accéder aux métriques Ganglia depuis la page des détails du cluster :
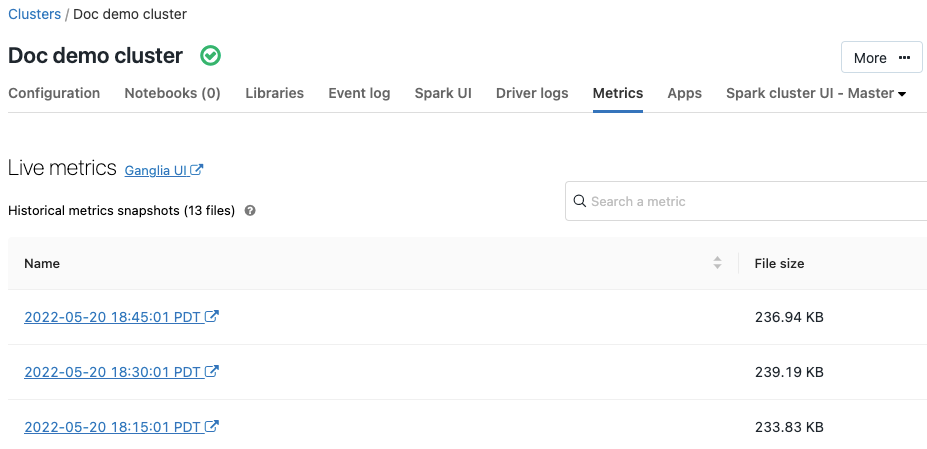
Pour plus de détails sur l'utilisation et la configuration des mesures, voir Mesures Ganglia.
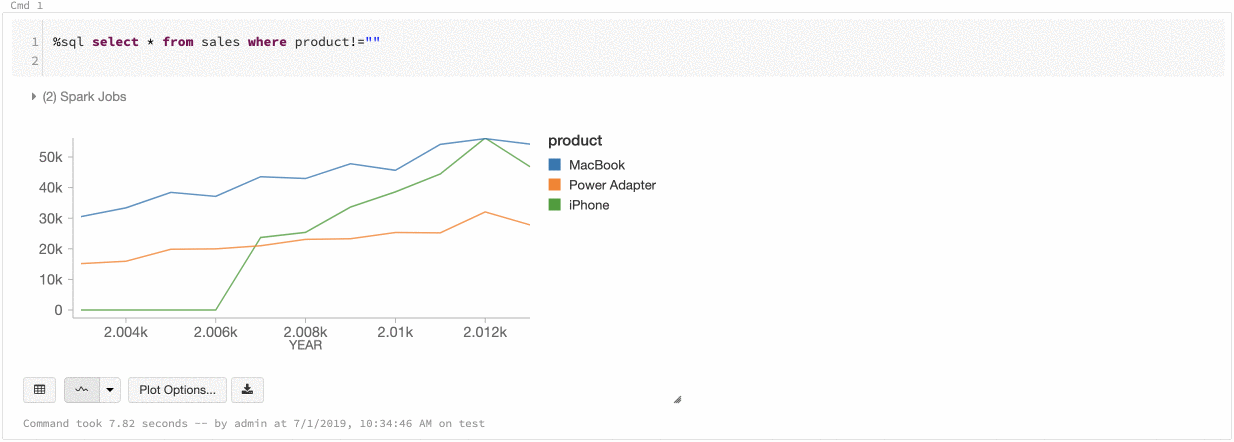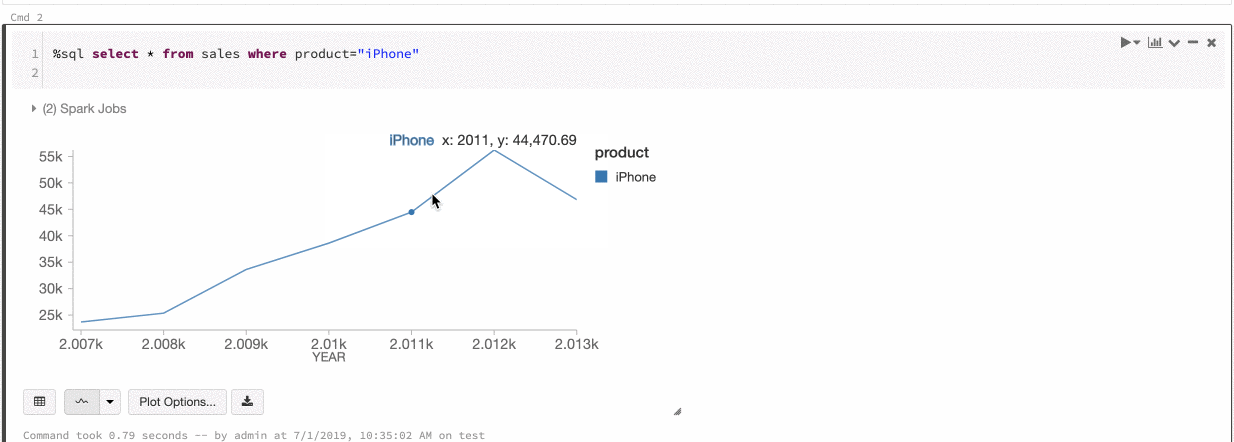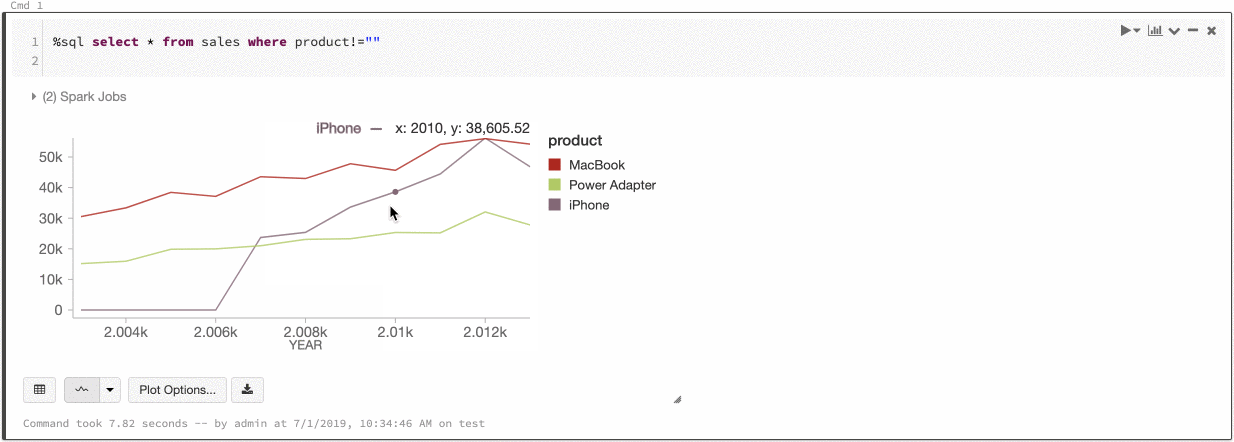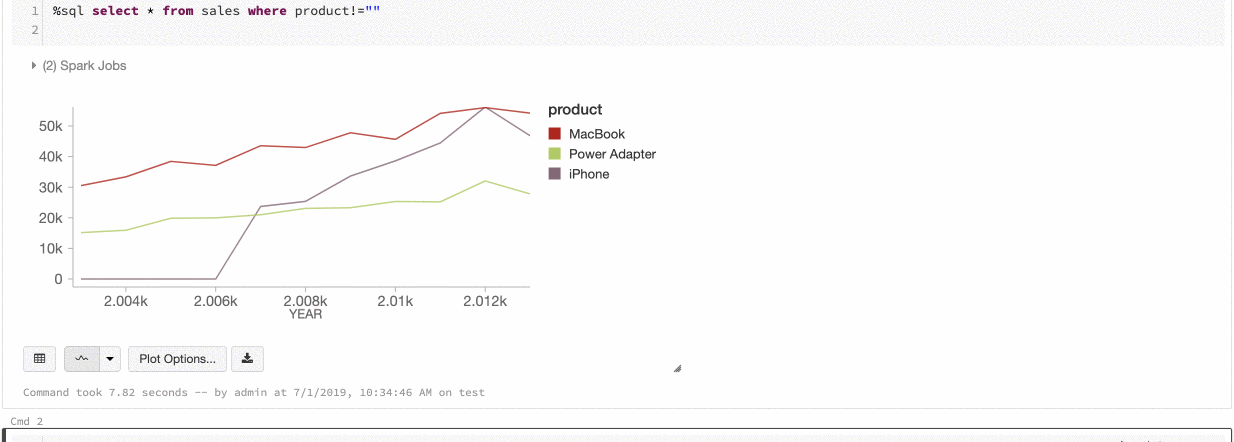
Couleur de série globale
9-11 juillet 2019 : version 2.101
Vous pouvez maintenant spécifier que les couleurs d’une série doivent être cohérentes entre tous les graphiques de votre notebook. Voir Cohérence des couleurs entre les graphiques.