Créer et exécuter des travaux Azure Databricks
Cet article explique comment créer et exécuter des tâches Azure Databricks à l’aide de l’interface utilisateur Jobs.
Pour en savoir plus sur les options de configuration des travaux et sur la façon de modifier vos travaux existants, consultez Configurer les paramètres des travaux Azure Databricks.
Pour savoir comment gérer et surveiller les exécutions de travaux, consultez Afficher et gérer les exécutions de travaux.
Pour créer votre premier workflow avec un travail Azure Databricks, consultez le guide de démarrage rapide.
Important
- Un espace de travail est limité à 1 000 exécutions de tâches simultanées. Une réponse
429 Too Many Requestsest retournée lorsque vous demandez une exécution qui ne peut pas démarrer immédiatement. - Le nombre de travaux qu’un espace de travail peut créer en une heure est limité à 10 000 (« envoi d’exécutions » inclus). Cette limite affecte également les travaux créés par les workflows de l’API REST et des notebooks.
Créez et exécutez des travaux à l’aide de l’interface CLI, de l’API ou des notebooks
- Pour en savoir plus sur l’utilisation de l’interface CLI Databricks pour créer et exécuter des tâches, consultez l’article Qu’est-ce que la CLI Databricks ?.
- Pour en savoir plus sur l’utilisation de l’API Travaux pour créer et exécuter des travaux, consultez Travaux dans la référence de l’API REST.
- Pour savoir comment exécuter et planifier des travaux directement dans un notebook Databricks, consultez Créer et gérer des travaux de notebook planifiés.
Créer un travail
Effectuez l’une des opérations suivantes :
- Cliquez sur
 Workflows dans la barre latérale et cliquez sur
Workflows dans la barre latérale et cliquez sur  .
. - Dans la barre latérale, cliquez sur
 Nouveau, puis sélectionnez Travail.
Nouveau, puis sélectionnez Travail.
L’onglet Tâches s’affiche avec la boîte de dialogue Créer une tâche, ainsi que le panneau latéral Détails du travail contenant les paramètres au niveau du travail.
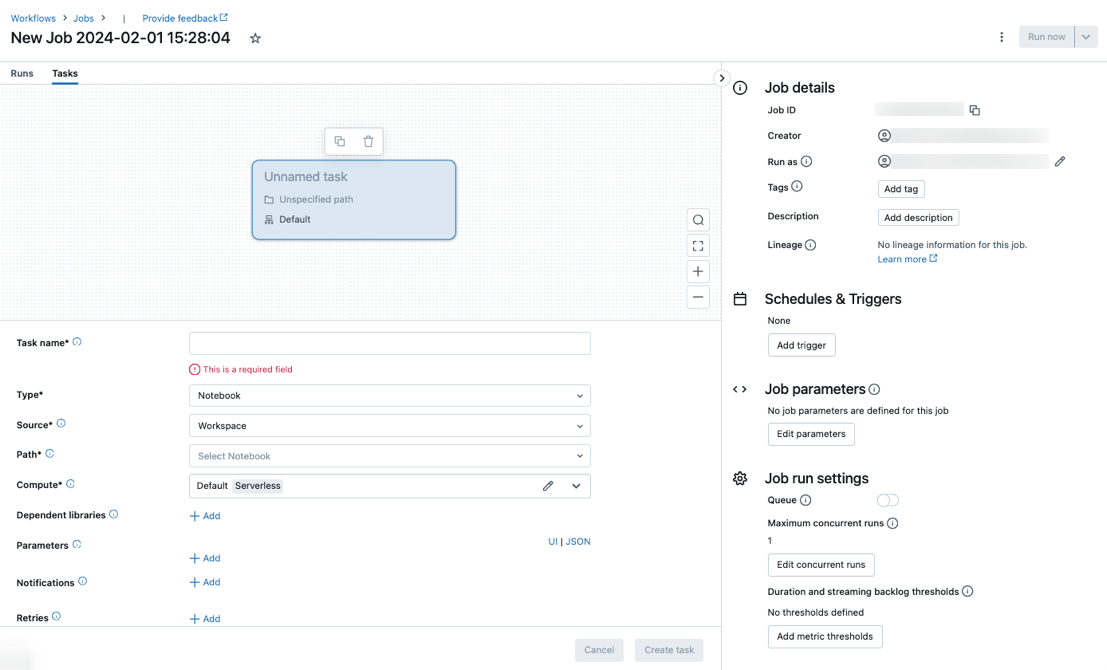
- Cliquez sur
Remplacez Nouveau travail... par le nom de votre travail.
Dans le champ Nom de la tâche, entrez un nom pour la tâche.
Dans le menu déroulant Type, sélectionnez le type de tâche à exécuter. Consultez Options du type de tâche.
Configurez le cluster sur lequel la tâche s’exécute. Par défaut, le calcul serverless est sélectionné si votre espace de travail se trouve dans un espace de travail avec Unity Catalog et que vous avez sélectionné une tâche prise en charge par le calcul serverless pour les flux de travail. Consultez Exécuter votre tâche Azure Databricks avec un calcul serverless pour les flux de travail. Si le calcul serverless n’est pas disponible ou que vous souhaitez utiliser un autre type de calcul, vous pouvez sélectionner un nouveau cluster de travaux ou un cluster tout usage existant dans le menu déroulant Calcul.
- Nouveau cluster de travail : cliquez sur Modifier dans le menu déroulant Cluster et terminez la configuration du cluster.
- Cluster à usage général existant : sélectionnez un cluster existant dans le menu déroulant Cluster. Pour ouvrir le cluster sur une nouvelle page, cliquez sur l'icône
 à droite du nom et de la description du cluster.
à droite du nom et de la description du cluster.
Pour en savoir plus sur la sélection et la configuration de clusters pour exécuter des tâches, consultez Utiliser le calcul Azure Databricks avec vos travaux.
Pour ajouter des bibliothèques dépendantes, cliquez sur + Ajouter en regard de Bibliothèques dépendantes. Consultez Configurer des bibliothèques dépendantes.
Vous pouvez passer des paramètres pour votre tâche. Pour plus d’informations sur la configuration requise pour la mise en forme et la transmission des paramètres, consultez Passer des paramètres à une tâche de travail Azure Databricks.
Pour éventuellement recevoir des notifications en cas de démarrage, de réussite ou d’échec de la tâche, cliquez sur + Ajouter en regard de E-mails. Les notifications d’échec sont envoyées lors de l’échec initial de la tâche et toutes les nouvelles tentatives suivantes. Pour filtrer les notifications et réduire le nombre d’e-mails envoyés, vérifiez Désactiver les notifications pour les exécutions ignorées, Désactiver les notifications pour les exécutions annulées ou Désactiver les notifications jusqu’à la dernière tentative.
Pour configurer éventuellement une stratégie de nouvelles tentatives pour la tâche, cliquez sur + Ajouter en regard de Nouvelles tentatives. Consultez Configurer une stratégie de nouvelles tentatives pour une tâche.
Pour configurer éventuellement la durée attendue ou le délai d’expiration de la tâche, cliquez sur + Ajouter en regard de Seuil de durée. Consultez Configurer un délai d’achèvement ou un délai d’attente pour une tâche.
Cliquez sur Créer.
Après avoir créé la première tâche, vous pouvez configurer les paramètres au niveau du travail, tels que les notifications, les déclencheurs de travail et les autorisations. Consultez Modifier un travail.
Pour ajouter une autre tâche, cliquez sur  dans l’affichage DAG. Une option de cluster partagé est fournie si vous avez sélectionné Calcul serverless ou configuré un Nouveau cluster de travaux pour une tâche précédente. Vous pouvez également configurer un cluster pour chaque tâche lorsque vous créez ou modifiez une tâche. Pour en savoir plus sur la sélection et la configuration de clusters pour exécuter des tâches, consultez Utiliser le calcul Azure Databricks avec vos travaux.
dans l’affichage DAG. Une option de cluster partagé est fournie si vous avez sélectionné Calcul serverless ou configuré un Nouveau cluster de travaux pour une tâche précédente. Vous pouvez également configurer un cluster pour chaque tâche lorsque vous créez ou modifiez une tâche. Pour en savoir plus sur la sélection et la configuration de clusters pour exécuter des tâches, consultez Utiliser le calcul Azure Databricks avec vos travaux.
Vous pouvez éventuellement configurer des paramètres au niveau de la tâche tels que les notifications, les déclencheurs de tâche et les autorisations. Consultez Modifier un travail. Vous pouvez également configurer les paramètres au niveau du travail qui sont partagés avec les tâches du travail. Voir Ajouter des paramètres pour toutes les tâches de travail.
Options de type de tâche
Voici les types de tâches que vous pouvez ajouter à votre travail Azure Databricks et les options disponibles pour les différents types de tâches :
Notebook : dans le menu déroulant Source, sélectionnez un emplacement Espace de travail pour utiliser un notebook situé dans un dossier d’espace de travail Azure Databricks ou Fournisseur Git pour un notebook situé dans un référentiel Git distant.
Espace de travail : utilisez l’Explorateur de fichiers pour rechercher le notebook, cliquez sur le nom du notebook, puis cliquez sur Confirmer.
Fournisseur Git : cliquez sur Modifier ou sur Ajouter une référence Git et entrez les informations du référentiel Git. Consultez Utiliser un notebook à partir d’un référentiel Git distant.
Notes
La sortie totale des cellules du notebook (la sortie combinée de toutes les cellules du notebook) est soumise à une limite de taille de 20 Mo. En outre, la sortie de cellule individuelle est soumise à une limite de taille de 8 Mo. Si la sortie totale des cellules dépasse 20 Mo, ou si la sortie d’une cellule individuelle est supérieure à 8 Mo, l’exécution est annulée et marquée comme ayant échoué.
Si vous avez besoin d’aide pour trouver les cellules proches ou au-delà de la limite, exécutez le notebook sur un cluster à usage général et utilisez cette technique d’enregistrement automatique du notebook.
JAR : spécifiez la Classe principale. Utilisez le nom complet de la classe contenant la méthode main, par exemple
org.apache.spark.examples.SparkPi. Cliquez ensuite sur Ajouter sous Dependent Libraries (Bibliothèques dépendantes) pour ajouter les bibliothèques nécessaires à l’exécution de la tâche. L’une de ces bibliothèques doit contenir la classe principale.Pour en savoir plus sur les tâches JAR, consultez Utiliser un fichier JAR dans un travail Azure Databricks.
Spark Submit : dans la zone de texte Paramètres, spécifiez la classe principale, le chemin d’accès à la bibliothèque JAR et tous les arguments, mis en forme en tant que tableau de chaînes JSON. L’exemple suivant configure une tâche spark-submit pour qu’elle exécute
DFSReadWriteTestà partir des exemples Apache Spark :["--class","org.apache.spark.examples.DFSReadWriteTest","dbfs:/FileStore/libraries/spark_examples_2_12_3_1_1.jar","/discover/databricks-datasets/README.md","/FileStore/examples/output/"]Important
Il existe plusieurs limitations pour les tâches spark-submit :
- Vous pouvez exécuter des tâches spark-submit uniquement sur les nouveaux clusters.
- Spark-submit ne prend pas en charge la mise à l’échelle automatique du cluster. Pour en savoir plus sur la mise à l’échelle automatique, consultez Mise à l’échelle automatique du cluster.
- Spark-submit ne prend pas en charge la référence Databricks Utilities (dbutils). Pour utiliser Databricks Utilities, utilisez des tâches JAR à la place.
- Si vous utilisez un cluster Unity Catalog, spark-submit est pris en charge uniquement si le cluster utilise le mode d’accès affecté. Le mode d’accès partagé n’est pas pris en charge.
- Les travaux de streaming Spark ne doivent jamais avoir un nombre maximal d’exécutions simultanées défini sur une valeur supérieure à 1. Les travaux de streaming doivent être configurés pour s’exécuter à l’aide de l’expression cron
"* * * * * ?"(toutes les minutes). Étant donné qu’une tâche de streaming s’exécute en continu, elle doit toujours être la dernière tâche d’un travail.
Script Python : dans le menu déroulant Source, sélectionnez un emplacement pour le script Python, soit Espace de travail pour un script dans l’espace de travail local, DBFS pour un script situé sur DBFS, soit Fournisseur Git pour un script situé dans un référentiel Git. Dans la zone de texte Chemin d’accès, entrez le chemin d’accès au script Python :
Espace de travail: dans la boîte de dialogue Sélectionner un fichier Python, accédez au script Python, puis cliquez sur Confirmer.
DBFS: entrez l’URI d’un script Python sur DBFS ou sur le stockage cloud. par exemple,
dbfs:/FileStore/myscript.py.Fournisseur Git : cliquez sur Modifier et entrez les informations du référentiel Git. Consultez Utiliser du code Python à partir d’un référentiel Git distant.
Pipeline Delta Live Tables : dans le menu déroulant Pipeline, sélectionnez un pipeline Delta Live Tables existant.
Important
Vous pouvez utiliser uniquement des pipelines déclenchés avec la tâche Pipeline. Les pipelines continus ne sont pas pris en charge en tant que tâche de travail. Pour en savoir plus sur les pipelines déclenchés et continus, consultez Exécution de pipelines continus et déclenchés.
Python Wheel : dans la zone de texte Nom du package, entrez le package à importer, par exemple
myWheel-1.0-py2.py3-none-any.whl. Dans la zone de texte Point d’entrée, entrez la fonction à appeler lors du démarrage du fichier wheel Python. Cliquez sur Ajouter sous Dependent Libraries (Bibliothèques dépendantes) pour ajouter les bibliothèques nécessaires à l’exécution de la tâche.SQL : dans le menu déroulant Tâche SQL, sélectionnez Requête, Tableau de bord hérité, Alerte ou Fichier.
Remarque
- La tâche SQL nécessite Databricks SQL et un entrepôt serverless ou pro SQL.
Requête : dans le menu déroulant Requête SQL, sélectionnez la requête à exécuter lorsque la tâche s’exécute.
Tableau de bord hérité : dans le menu déroulant du tableau de bord SQL, sélectionnez un tableau de bord à mettre à jour lorsque la tâche s’exécute.
Alerte : dans le menu déroulant Alerte SQL, sélectionnez une alerte à déclencher pour l’évaluation.
Fichier : pour utiliser un fichier SQL situé dans un dossier d’espace de travail Azure Databricks, dans le menu déroulant Source, sélectionnez Espace de travail, utilisez le navigateur de fichiers pour rechercher le fichier SQL, cliquez sur son nom, puis cliquez sur Confirmer. Pour utiliser un fichier SQL situé dans un référentiel Git distant, sélectionnez Fournisseur Git, cliquez sur Modifier ou sur Ajouter une référence Git, puis entrez les détails du référentiel Git. Consultez Utiliser des requêtes SQL à partir d’un référentiel Git distant.
Dans le menu déroulant Entrepôt SQL, sélectionnez un entrepôt serverless ou pro SQL pour exécuter la tâche.
dbt : consultez Utiliser des transformations dbt dans un travail Azure Databricks pour obtenir un exemple détaillé de configuration d’une tâche dbt.
Exécuter un travail : dans le menu déroulant Travail, sélectionnez un travail que la tâche doit exécuter. Pour rechercher la tâche à exécuter, commencez à taper le nom de la tâche dans le menu Tâche.
Important
Vous ne devez pas créer de travaux avec des dépendances circulaires lors de l’utilisation de la tâche
Run Jobou des travaux qui imbriquent plus de trois tâchesRun Job. Les dépendances circulaires sont des tâchesRun Jobqui se déclenchent directement ou indirectement. Par exemple, la tâche A déclenche la tâche B et la tâche B déclenche la tâche A. Databricks ne prend pas en charge les travaux avec des dépendances circulaires ou qui imbriquent plus de trois tâchesRun Jobet peuvent ne pas autoriser l’exécution de ces travaux dans les versions ultérieures.If/else : pour savoir comment utiliser la tâche
If/else condition, consultez Ajouter une logique de branchement à votre travail avec la tâche de condition If/else.
Passer des paramètres à une tâche de travail Azure Databricks
Vous pouvez passer des paramètres à de nombreux types de tâches de travail. Chaque type de tâche a des exigences différentes de mise en forme et de passage des paramètres.
Pour accéder aux informations sur la tâche actuelle, comme le nom de la tâche, ou passer le contexte de l’exécution actuelle entre les tâches du travail, comme l’heure de début du travail ou l’identificateur de l’exécution de travail actuelle, utilisez des références de valeurs dynamiques. Pour afficher une liste des références de valeurs dynamiques disponibles, cliquez sur Parcourir les valeurs dynamiques.
Si les paramètres de tâche sont configurés sur la tâche à laquelle appartient une tâche, ces paramètres s'affichent lorsque vous ajoutez des paramètres de tâche. Si les paramètres de tâche et de tâche partagent une clé, le paramètre de tâche est prioritaire. Un avertissement s'affiche dans l'interface utilisateur si vous tentez d'ajouter un paramètre de tâche avec la même clé qu'un paramètre de tâche. Pour transmettre des paramètres de tâche à des tâches qui ne sont pas configurées avec des paramètres clé-valeur tels que des tâches JAR ou Spark Submit, formatez les arguments comme {{job.parameters.[name]}}, en les remplaçant [name] par key celui qui identifie le paramètre.
Notebook : cliquez sur Ajouter et spécifiez la clé et la valeur de chaque paramètre à passer à la tâche. Vous pouvez remplacer ou ajouter des paramètres supplémentaires lorsque vous exécutez manuellement une tâche à l’aide de l’option Exécuter un travail avec des paramètres différents. Les paramètres définissent la valeur du widget du notebook spécifié par la clé du paramètre.
JAR : utilisez un tableau de chaînes au format JSON pour spécifier des paramètres. Ces chaînes sont passées en tant qu’arguments à la méthode main de la classe principale. Consultez Configuration des paramètres d’un travail JAR.
Spark Submit : Les paramètres sont spécifiés sous la forme d’un tableau de chaînes au format JSON. Conformément à la convention d'Apache Spark spark-submit, les paramètres après le chemin d’accès JAR sont passés à la méthode main de la classe principale.
Python Wheel : dans le menu déroulant Paramètres, sélectionnez Arguments positionnels pour entrer des paramètres sous la forme d’un tableau de chaînes au format JSON ou sélectionnez Arguments de mot clé > Ajouter pour entrer la clé et la valeur de chaque paramètre. Les arguments positionnels et de mots clés sont transférés vers la tâche de roue Python en tant qu’arguments de ligne de commande. Pour voir un exemple de lecture d’arguments dans un script Python empaqueté dans un fichier wheel Python, consultez Utiliser un fichier wheel Python dans une tâche Azure Databricks.
Exécuter le travail : Entrez la clé et la valeur de chaque paramètre de tâche à transmettre au travail.
Script Python : utilisez un tableau de chaînes au format JSON pour spécifier des paramètres. Ces chaînes sont transmises en tant qu’arguments et peuvent être lues en tant qu’arguments positionnels ou analysées à l’aide du module argparse de Python. Pour voir un exemple de lecture d’arguments positionnels dans un script Python, consultez Étape 2 : Créer un script pour extraire des données GitHub.
SQL : si votre tâche exécute une requête paramétrable ou un tableau de bord paramétrable, entrez des valeurs pour les paramètres dans les zones de texte fournies.
Copier un chemin d'accès de tâche
Certains types de tâches, par exemple les tâches de notebook, vous permettent de copier le chemin d’accès au code source de la tâche :
- Cliquez sur l'onglet Tâches.
- Sélectionnez la tâche contenant le chemin d’accès à copier.
- Cliquez sur
 en regard du chemin d’accès de tâche pour copier le chemin d’accès dans le Presse-papiers.
en regard du chemin d’accès de tâche pour copier le chemin d’accès dans le Presse-papiers.
Créer un travail à partir d’un travail existant
Vous pouvez créer rapidement un nouveau travail en clonant un travail existant. Le clonage d’un travail crée une copie identique du travail, à l’exception de l’ID du travail. Sur la page du travail, cliquez sur Plus... en regard du nom du travail, puis sélectionnez Cloner dans le menu déroulant.
Créer une tâche à partir d’une tâche existante
Vous pouvez créer rapidement une nouvelle tâche en clonant une tâche existante :
- Sur la page du travail, cliquez sur l’onglet Tâches.
- Sélectionnez la tâche à cloner.
- Cliquez sur
 , puis sélectionnez Clone task (Cloner la tâche).
, puis sélectionnez Clone task (Cloner la tâche).
Supprimer une tâche
Pour supprimer un travail, sur la page du travail, cliquez sur Plus... en regard du nom du travail, puis sélectionnez Supprimer dans le menu déroulant.
Supprimer une tâche
Pour supprimer une tâche :
- Cliquez sur l'onglet Tâches.
- Sélectionnez la tâche à supprimer.
- Cliquez sur , puis sélectionnez Supprimer la tâche.
Exécuter un travail
- Cliquez sur Workflows dans la barre latérale.
- Sélectionnez un travail, puis cliquez sur l’onglet Exécutions. Vous pouvez exécuter un travail immédiatement ou planifier le travail pour une exécution ultérieure.
Si une ou plusieurs tâches d’un travail multitâche ne réussissent pas, vous pouvez réexécuter le sous-ensemble des tâches qui ont échoué. Consultez la section Réexécuter les tâches ayant échoué et ignorées.
Exécuter un travail immédiatement
Pour exécuter le travail immédiatement, cliquez sur  .
.
Conseil
Vous pouvez effectuer une série de tests d’un travail avec une tâche de notebook en cliquant sur Exécuter maintenant. Si vous devez apporter des modifications au notebook, cliquez à nouveau sur Exécuter maintenant après avoir modifié le notebook pour exécuter automatiquement la nouvelle version du notebook.
Exécuter un travail avec des paramètres différents
Vous pouvez utiliser Run Now with Different Parameters (Exécuter maintenant avec des paramètres différents) pour réexécuter un travail avec des paramètres différents ou des valeurs différentes pour les paramètres existants.
Remarque
Vous ne pouvez pas remplacer les paramètres de tâche si une tâche exécutée avant l'introduction des paramètres de tâche a remplacé les paramètres de tâche avec la même clé.
- Cliquez sur
 en regard de Exécuter maintenant et sélectionnez Run Now with Different Parameters (Exécuter maintenant avec des paramètres différents) ou, dans la table Exécutions actives, cliquez sur Run Now with Different Parameters (Exécuter maintenant avec des paramètres différents). Entrez les nouveaux paramètres en fonction du type de tâche. Consultez Transmettre les paramètres à une tâche de travail Azure Databricks.
en regard de Exécuter maintenant et sélectionnez Run Now with Different Parameters (Exécuter maintenant avec des paramètres différents) ou, dans la table Exécutions actives, cliquez sur Run Now with Different Parameters (Exécuter maintenant avec des paramètres différents). Entrez les nouveaux paramètres en fonction du type de tâche. Consultez Transmettre les paramètres à une tâche de travail Azure Databricks. - Cliquez sur Exécuter.
Exécutez des travaux en principal de service
Remarque
Si votre travail exécute des requêtes SQL à l’aide de la tâche SQL, l’identité utilisée pour exécuter les requêtes est déterminée par les paramètres de partage de chaque requête, même si le travail s’exécute en tant que principal de service. Si une requête est configurée sur Run as owner, elle s’exécute toujours en utilisant l’identité du propriétaire et non celle du principal de service. Si une requête est configurée sur Run as viewer, elle s’exécute en utilisant l’identité du principal de service. Pour en savoir plus sur les paramètres de partage de requêtes, consultez Configurer les autorisations de requête.
Par défaut, les travaux s’exécutent en tant qu’identité du propriétaire de la tâche. Cela signifie que la tâche suppose les autorisations du propriétaire de la tâche. La tâche peut uniquement accéder aux données et aux objets Azure Databricks auxquels le propriétaire de la tâche a les autorisations. Vous pouvez modifier l’identité que la tâche exécute en tant que à un principal de service. Ensuite, la tâche suppose les autorisations de ce principal de service au lieu du propriétaire.
Pour modifier le paramètre Exécuter en tant que, vous devez disposer de l’autorisation PEUT GÉRER ou EST PROPRIÉTAIRE sur le travail. Vous pouvez définir le paramètre Exécuter en tant que sur vous-même ou sur n’importe quel principal de service dans l’espace de travail sur lequel vous disposez du rôle Utilisateur de principal de service. Pour plus d'informations, consultez Rôles pour la gestion des principaux de service.
Remarque
Quand le paramètre RestrictWorkspaceAdmins sur un espace de travail est défini sur ALLOW ALL, les administrateurs d’espace de travail peuvent également modifier le paramètre Exécuter en tant que sur n’importe quel utilisateur de leur espace de travail. Pour restreindre les administrateurs d’espace de travail à modifier seulement le paramètre Exécuter en tant que en le définissant sur eux-mêmes ou sur des principaux de service pour lesquels ils ont le rôle Utilisateur de principal de service, consultez Restreindre les administrateurs d’espace de travail.
Pour modifier le champ d’exécution en tant que, procédez comme suit :
- Cliquez sur Workflows dans la barre latérale.
- Dans la colonne Nom, cliquez sur le nom d’un travail.
- Dans le panneau latéral Détails de la tâche , cliquez sur l’icône en forme de crayon en regard du champ Exécuter en tant que.
- Recherchez, puis sélectionnez le principal de service.
- Cliquez sur Enregistrer.
Vous pouvez également répertorier les principaux de service sur lesquels vous avez le rôle Utilisateur à l’aide de l’API des principaux de service d’espace de travail. Pour plus d’informations, consultez Répertorier les principaux de service que vous pouvez utiliser.
Exécuter une tâche selon une planification
Vous pouvez utiliser une planification pour exécuter automatiquement votre tâche Azure Databricks à des heures et des périodes spécifiées. Consultez Ajouter une planification de tâche.
Exécutez une tâche continue
Vous pouvez vous assurer qu’il y a toujours une exécution active de votre tâche. Consultez Exécuter une tâche continue.
Exécuter un travail lorsque de nouveaux fichiers arrivent
Pour déclencher une exécution de travail lorsque de nouveaux fichiers arrivent dans un emplacement ou un volume externe Unity Catalog, utilisez un déclencheur d’arrivée de fichier.
Afficher et exécuter une tâche créée à l’aide d’un pack de ressources Databricks
Vous pouvez utiliser l’interface utilisateur des travaux Azure Databricks pour afficher et exécuter des travaux déployés par un Pack de ressources Databricks. Par défaut, ces travaux sont en lecture seule dans l’interface utilisateur des travaux. Pour modifier un travail déployé par un pack, modifiez le fichier de configuration du pack et redéployez le travail. Appliquer des modifications uniquement à la configuration du bundle garantit que les fichiers sources du pack capturent toujours la configuration actuelle du travail.
Toutefois, si vous devez apporter des modifications immédiates à un travail, vous pouvez déconnecter le travail de la configuration du pack pour activer la modification des paramètres de travail dans l’interface utilisateur. Pour déconnecter le travail, cliquez sur Déconnecter de la source. Dans la boîte de dialogue Déconnecter de la source, cliquez sur Déconnecter pour confirmer.
Les modifications que vous apportez au travail dans l’interface utilisateur ne sont pas appliquées à la configuration du pack. Pour appliquer les modifications que vous apportez au pack dans l’interface utilisateur, vous devez mettre à jour manuellement la configuration du pack. Pour reconnecter le travail à la configuration du pack, redéployez le travail à l’aide du pack.
Que se passe-t-il si mon travail ne peut pas s’exécuter en raison de limites de concurrence ?
Remarque
La mise en file d’attente est activée par défaut lorsque des travaux sont créés dans l’interface utilisateur.
Pour empêcher les exécutions d’un travail d’être ignorées en raison de limites de concurrence, vous pouvez désormais activer la mise en file d’attente pour le travail. Quand la mise en file d’attente est activée, si des ressources ne sont pas disponibles pour une exécution de travail, l’exécution est mise en file d’attente pendant 48 heures maximum. Quand la capacité est disponible, l’exécution de travail est annulée de la file d’attente et est exécutée. Les exécutions mises en file d’attente s’affichent dans la liste des exécutions pour le travail et la liste des exécutions du travail récent.
Une exécution est mise en file d’attente lorsque l’une des limites est atteinte :
- Exécutions actives simultanées maximales dans l’espace de travail.
- Exécutions de tâche simultanées maximales
Run Jobdans l’espace de travail. - Exécutions simultanées maximales du travail.
La mise en file d’attente est une propriété au niveau du travail dont les files d’attente s’exécutent uniquement pour ce travail.
Pour activer ou désactiver la file d’attente, cliquez sur Paramètres avancés, puis cliquez sur le bouton bascule File d’attente dans le volet latéral Travail.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour