Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans ce tutoriel, vous allez apprendre à utiliser Jupyter Notebook afin de créer une application d’apprentissage automatique Apache Spark pour Azure HDInsight.
MLlib est une bibliothèque Machine Learning adaptable de Spark constituée d’utilitaires et d’algorithmes d’apprentissage courants (notamment la classification, la régression, le clustering, le filtrage collaboratif, la réduction de dimensionnalité, ainsi que les primitives d’optimisation sous-jacentes).
Dans ce tutoriel, vous allez apprendre à :
- Développer une application d’apprentissage automatique Apache Spark
Prérequis
Un cluster Apache Spark sur HDInsight. Consultez Créer un cluster Apache Spark.
Connaissances sur l’utilisation des blocs-notes Jupyter Notebook avec Spark sur HDInsight. Pour plus d’informations, consultez Charger des données et exécuter des requêtes sur un cluster Apache Spark dans Azure HDInsight.
Comprendre le jeu de données
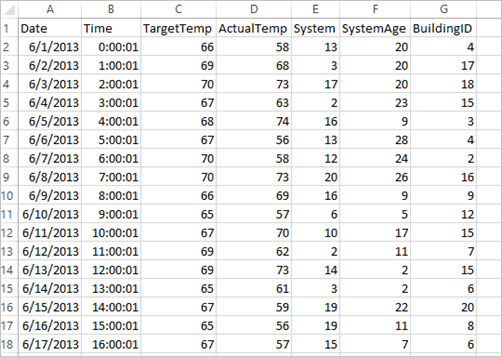
L’application utilise l’exemple de données HVAC.csv, qui est disponible par défaut sur tous les clusters. Le fichier se trouve sous \HdiSamples\HdiSamples\SensorSampleData\hvac. Les données indiquent la température cible et la température réelle de bâtiments dans lesquels un système HVAC est installé. La colonne System représente l’ID système et la colonne SystemAge représente le nombre d’années écoulées depuis la mise en place du système HVAC dans le bâtiment. Vous pouvez prédire si un bâtiment sera plus chaud ou plus froid en fonction de la température cible, selon un ID système et l’ancienneté du système.
Développer une application de Machine Learning Spark à l’aide de Spark MLlib
Cette application utilise un pipeline Spark ML pour effectuer une classification de documents. Les pipelines ML fournissent un ensemble uniforme d’API générales reposant sur des DataFrames. Les DataFrames permettent aux utilisateurs de créer et d’ajuster des pipelines Machine Learning pratiques. Dans le pipeline, vous fractionnez le document en mots, convertissez ces mots en un vecteur de fonctionnalité numérique avant de créer un modèle de prédiction utilisant les étiquettes et vecteurs de fonctionnalité. Procédez comme suit pour créer l’application.
Créez un fichier Jupyter Notebook en utilisant le noyau PySpark. Pour obtenir des instructions, consultez Créer un fichier Jupyter Notebook.
Importez les types requis pour ce scénario. Collez l’extrait de code suivant dans une cellule vide, puis appuyez sur MAJ + ENTRÉE.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row import os import sys from pyspark.sql.types import * from pyspark.mllib.classification import LogisticRegressionWithLBFGS from pyspark.mllib.regression import LabeledPoint from numpy import arrayChargez les données (hvac.csv), analysez-les et utilisez-les pour effectuer l’apprentissage du modèle.
# Define a type called LabelDocument LabeledDocument = Row("BuildingID", "SystemInfo", "label") # Define a function that parses the raw CSV file and returns an object of type LabeledDocument def parseDocument(line): values = [str(x) for x in line.split(',')] if (values[3] > values[2]): hot = 1.0 else: hot = 0.0 textValue = str(values[4]) + " " + str(values[5]) return LabeledDocument((values[6]), textValue, hot) # Load the raw HVAC.csv file, parse it using the function data = sc.textFile("/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") documents = data.filter(lambda s: "Date" not in s).map(parseDocument) training = documents.toDF()Dans l’extrait de code, vous définissez une fonction qui compare la température réelle avec la température cible. Si la température actuelle est supérieure, le bâtiment est chaud, ce qui est indiqué par la valeur 1,0. Sinon, le bâtiment est froid, ce qui est indiqué par la valeur 0.0.
Configurez le pipeline Machine Learning Spark, qui comprend trois phases :
tokenizer,hashingTFetlr.tokenizer = Tokenizer(inputCol="SystemInfo", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])Pour plus d’informations sur le pipeline et son fonctionnement, consultez le pipeline de Machine Learning Apache Spark.
Ajustez le pipeline au document d’apprentissage.
model = pipeline.fit(training)Vérifiez le document d’apprentissage pour contrôler votre progression dans l’application.
training.show()Le résultat ressemble à ce qui suit :
+----------+----------+-----+ |BuildingID|SystemInfo|label| +----------+----------+-----+ | 4| 13 20| 0.0| | 17| 3 20| 0.0| | 18| 17 20| 1.0| | 15| 2 23| 0.0| | 3| 16 9| 1.0| | 4| 13 28| 0.0| | 2| 12 24| 0.0| | 16| 20 26| 1.0| | 9| 16 9| 1.0| | 12| 6 5| 0.0| | 15| 10 17| 1.0| | 7| 2 11| 0.0| | 15| 14 2| 1.0| | 6| 3 2| 0.0| | 20| 19 22| 0.0| | 8| 19 11| 0.0| | 6| 15 7| 0.0| | 13| 12 5| 0.0| | 4| 8 22| 0.0| | 7| 17 5| 0.0| +----------+----------+-----+Comparaison de la sortie et du fichier CSV brut. Par exemple, la première ligne du fichier CSV contient les données suivantes :

Notez que la température réelle est inférieure à la température cible, suggérant que le bâtiment est froid. La valeur de label dans la première ligne est 0.0, ce qui signifie que le bâtiment n’est pas chaud.
Préparez un jeu de données sur lequel exécuter le modèle d’apprentissage. Pour ce faire, vous transmettez un ID système et l’ancienneté du système (indiqués par SystemInfo dans le résultat de l’entraînement). Le modèle prédit si le bâtiment ayant cet ID système et cette ancienneté de système sera plus chaud (indiqué par la valeur 1.0) ou plus froid (indiqué par la valeur 0.0).
# SystemInfo here is a combination of system ID followed by system age Document = Row("id", "SystemInfo") test = sc.parallelize([("1L", "20 25"), ("2L", "4 15"), ("3L", "16 9"), ("4L", "9 22"), ("5L", "17 10"), ("6L", "7 22")]) \ .map(lambda x: Document(*x)).toDF()Pour finir, effectuez des prédictions sur les données de test.
# Make predictions on test documents and print columns of interest prediction = model.transform(test) selected = prediction.select("SystemInfo", "prediction", "probability") for row in selected.collect(): print (row)Le résultat ressemble à ce qui suit :
Row(SystemInfo=u'20 25', prediction=1.0, probability=DenseVector([0.4999, 0.5001])) Row(SystemInfo=u'4 15', prediction=0.0, probability=DenseVector([0.5016, 0.4984])) Row(SystemInfo=u'16 9', prediction=1.0, probability=DenseVector([0.4785, 0.5215])) Row(SystemInfo=u'9 22', prediction=1.0, probability=DenseVector([0.4549, 0.5451])) Row(SystemInfo=u'17 10', prediction=1.0, probability=DenseVector([0.4925, 0.5075])) Row(SystemInfo=u'7 22', prediction=0.0, probability=DenseVector([0.5015, 0.4985]))Examinez la première ligne dans la prédiction. Pour un système HVAC avec l’ID 20 et une ancienneté de 25 ans, le bâtiment est chaud (prediction=1.0). La première valeur de DenseVector (0.49999) correspond à la prédiction 0.0, et la seconde valeur (0.5001) correspond à la prédiction 1.0. Dans le résultat, même si la seconde valeur n’est que légèrement supérieure, le modèle indique prediction=1,0.
Arrêtez le bloc-notes pour libérer les ressources. Pour ce faire, dans le menu Fichier du bloc-notes, sélectionnez Fermer et arrêter. Cela a pour effet d’arrêter et de fermer le bloc-notes.
Utiliser une bibliothèque scikit-learn Anaconda pour le Machine Learning Spark
Les clusters Apache Spark sur HDInsight incluent des bibliothèques Anaconda, notamment la bibliothèque scikit-learn pour le Machine Learning. Cette bibliothèque contient également différents jeux de données qui vous permettent de créer des exemples d’application directement à partir de Jupyter Notebook. Pour voir des exemples d’utilisation de la bibliothèque scikit-learn, consultez https://scikit-learn.org/stable/auto_examples/index.html.
Nettoyer les ressources
Si vous ne comptez pas continuer à utiliser cette application, effectuez les étapes suivantes pour supprimer le cluster que vous avez créé :
Connectez-vous au portail Azure.
Dans la zone Recherche située en haut, tapez HDInsight.
Sous Services, sélectionnez Clusters HDInsight.
Dans la liste des clusters HDInsight qui s’affiche, sélectionnez les points de suspension ... à côté du cluster que vous avez créé pour ce tutoriel.
Sélectionnez Supprimer. Sélectionnez Oui.
Étapes suivantes
Dans ce tutoriel, vous avez vu comment utiliser Jupyter Notebook afin de créer une application de machine learning Apache Spark pour Azure HDInsight. Passez au didacticiel suivant afin de découvrir comment utiliser IntelliJ IDEA pour les travaux Spark.