Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les fabricants souhaitent déployer une solution d’IoT industriel globale à l’échelle mondiale et connecter tous leurs sites de production à cette solution afin d’accroître l’efficacité de chaque site de production individuel.
Ces gains d’efficacité permettent d’augmenter la production et de réduire la consommation d’énergie, ce qui baisse le coût des biens produits tout en améliorant leur qualité dans la plupart des cas.
La solution doit être aussi efficace que possible et prendre en charge tous les cas d’utilisation nécessaires, tels que le monitoring des conditions, le calcul du taux de rendement global (TRG), les prévisions et la détection d’anomalie. Grâce aux insights de ces cas d’utilisation, vous pouvez ensuite créer une boucle de rétroaction numérique qui peut ensuite appliquer des optimisations et d’autres modifications aux processus de production.
L’interopérabilité est essentielle pour parvenir à lancer rapidement l’architecture de la solution. L’utilisation de normes ouvertes comme OPC UA contribue grandement à l’obtention de cette interopérabilité.
Ce tutoriel vous montre comment déployer une solution d’IoT industriel en utilisant des services Azure. Cette solution utilise la norme CEI 62541, OPC (Open Platform Communications) UA (Unified Architecture) pour toutes les données de technologie opérationnelle (OT).
Prérequis
Pour effectuer les étapes de ce tutoriel, vous avez besoin d’un abonnement Azure. Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Architecture de la solution de référence
Les diagrammes suivants montrent l’architecture de la solution d’IoT industriel :
Architecture simplifiée qui présente les deux options, Azure et Microsoft Fabric :

Architecture détaillée qui présente l’option Azure :

Le tableau suivant décrit les composants clés de cette solution :
| Composant | Description |
|---|---|
| Ressources industrielles | Ensemble de lignes de production simulées avec OPC UA hébergées dans des conteneurs Docker. |
| Opérations Azure IoT | Azure IoT Operations est un plan de données unifié pour l'edge. Il comprend un ensemble de services de données modulaires, évolutifs et hautement disponibles qui s’exécutent sur des clusters Kubernetes de périphérie avec Azure Arc. |
| Passerelle de données | Cette passerelle connecte vos sources de données locale, telles que SAP, à Azure Logic Apps dans le cloud. |
| Azure Event Hubs | Répartiteur de messages cloud qui reçoit les messages pub/sub OPC UA à partir de passerelles de périphérie et les stocke jusqu’à ce qu’ils soient récupérés par les abonnés. |
| Explorateur de données Azure | La base de données de série chronologique et le service de tableau de bord frontal pour l’analytique cloud avancée, y compris la détection et les prédictions d’anomalies intégrées. |
| Azure Logic Apps | Azure Logic Apps est une plateforme cloud que vous pouvez utiliser pour créer et exécuter des workflows automatisés avec peu ou pas de code. |
| Azure Arc | Ce service cloud est utilisé pour gérer le cluster Kubernetes local à la périphérie. |
| Grafana géré par Azure | Azure Managed Grafana est une plateforme de visualisation des données basée sur le logiciel Grafana de Grafana Labs. Grafana est un service entièrement géré que Microsoft héberge et prend en charge. |
| Microsoft Power BI | Microsoft Power BI est un ensemble de services logiciels, d’applications et de connecteurs SaaS qui travaillent de concert pour transformer vos sources de données disparates en insights cohérents, visuellement immersifs et interactifs. |
| Microsoft Dynamics 365 Field Service | Microsoft Dynamics 365 Field Service est une solution SaaS clé en main pour la gestion de demandes de service sur le terrain. |
| UA Cloud Commander | Cette application de référence open source convertit les messages envoyés à un répartiteur MQTT ou Kafka (éventuellement dans le cloud) en requêtes client/serveur OPC UA pour un serveur OPC UA connecté. L’application s’exécute dans un conteneur Docker. |
| UA Cloud Action | Cette application cloud de référence open source interroge Azure Data Explorer pour obtenir une valeur de données spécifique. La valeur de données correspond à la pression de l’une des machines simulées de la ligne de production. Elle appelle UA Cloud Commander via Azure Event Hubs lorsqu’un certain seuil est atteint (4 000 mbar). UA Cloud Commander appelle ensuite la méthode OpenPressureReliefValve sur la machine via OPC UA. |
| Bibliothèque cloud UA | La bibliothèque UA Cloud Library est un magasin en ligne de modèles d’information OPC UA, hébergé par la fondation OPC. |
| UA Edge Translator | Cette application de référence pour la connectivité industrielle open source traduit les interfaces d'actifs propriétaires en OPC UA. La solution utilise des descriptions WoT (Web of Things) du W3C comme schéma pour décrire l’interface des ressources industrielles. |
Remarque
Dans un vrai déploiement, une opération aussi critique que l’ouverture d’une soupape de sécurité serait effectuée localement. Cet exemple montre simplement comment réaliser la boucle de rétroaction numérique.
Simulation de ligne de production
La solution utilise une simulation de ligne de production composée de plusieurs postes en ayant recours à un modèle d’information OPC UA de poste et à un système d’exécution de fabrication (MES, Manufacturing Execution System) simple. Les postes et le système MES sont conteneurisés pour faciliter le déploiement.
La simulation est configurée pour inclure deux lignes de production. La configuration par défaut est :
| Ligne de production | Durée idéale du cycle (en secondes) |
|---|---|
| Munich | 6 |
| Seattle | 10 |
| Nom du shift | Démarrer | Fin |
|---|---|---|
| Matin | 07:00 | 14h00 |
| Après-midi | 15h00 | 22:00 |
| Nuit | 23:00 | 06:00 |
Remarque
Les horaires des services (« shifts ») sont en heure locale, plus précisément dans le fuseau horaire dans lequel la machine virtuelle hébergeant la simulation de ligne de production est définie.
Le serveur OPC UA de poste utilise les ID de nœud OPC UA suivants pour la télémétrie vers le cloud :
- i=379 – numéro de série des produits manufacturés
- i=385 – numéro des produits manufacturés
- i=391 – nombre de produits éliminés
- i=398 – durée d’exécution
- i=399 – temps défectueux
- i=400 – état (0=poste prêt à travailler, 1=travail en cours, 2=travail effectué et grande partie manufacturée, 3=travail terminé et petite partie manufacturée, 4=poste en état d’erreur)
- i=406 – consommation d’énergie
- i=412 – durée idéale du cycle
- i=418 – durée effective du cycle
- i=434 – pression
Boucle de rétroaction numérique avec UA Cloud Commander et UA Cloud Action
La solution utilise une boucle de rétroaction numérique pour gérer la pression dans un poste simulé. Pour implémenter la boucle de rétroaction, la solution déclenche une commande depuis le cloud sur l’un des serveurs OPC UA dans la simulation. Le déclencheur s’active lorsque les données de pression de la série chronologique simulées atteignent un certain seuil. Vous pouvez voir la pression de la machine d’assembly dans le tableau de bord Azure Data Explorer. La pression est libérée à intervalles réguliers pour la ligne de production de Seattle.
Installer la simulation de ligne de production et les services cloud
Sélectionnez le bouton Déployer pour déployer toutes les ressources requises sur votre abonnement Azure :
Le processus de déploiement vous invite à fournir un mot de passe pour la machine virtuelle qui héberge la simulation de ligne de production et l’infrastructure Edge. Le mot de passe doit avoir trois des attributs suivants : un caractère minuscule, un caractère majuscule, un chiffre et un caractère spécial. La longueur du mot de passe doit être comprise entre 12 et 72 caractères.
Remarque
Pour réduire les coûts, le déploiement crée une seule machine virtuelle Linux pour la simulation de ligne de production et l’infrastructure de périphérie. Dans un scénario de production, la simulation de ligne de production n’est pas nécessaire et pour le système d’exploitation de base, vous devez utiliser Azure Local.
Exécuter la simulation de ligne de production
Utilisez SSH pour vous connecter à la machine virtuelle déployée à l’aide des informations d’identification que vous avez fournies pendant le déploiement (vous devrez peut-être d’abord activer l’accès juste-à-temps dans le portail Azure). Accédez au répertoire /opt/ManufacturingOntologies-main/Tools/FactorySimulation et exécutez le script de l’interpréteur de commandes StartSimulation :
sudo ./StartSimulation.sh "<Your Event Hubs connection string>"
<Your Event Hubs connection string> est la chaîne de connexion à votre espace de noms Event Hubs. Pour plus d'informations, consultez Obtenir une string de connexion Event Hubs. Une chaîne de connexion ressemble à ceci : Endpoint=sb://ontologies.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=abcdefgh=
Conseil
Si l’adresse IP externe de certains services Kubernetes s’affiche comme <pending>suit, utilisez la commande suivante pour affecter l’adresse IP externe du traefik service : sudo kubectl patch service <theService> -n <the service's namespace> -p '{"spec": {"type": "LoadBalancer", "externalIPs":["<the traefik external IP address>"]}}'.
Bibliothèque cloud UA
Pour lire les modèles d’informations OPC UA directement à partir d’Azure Data Explorer, vous pouvez importer les nœuds OPC UA définis dans un modèle d’informations OPC UA dans une table. Vous pouvez utiliser les informations importées pour rechercher davantage de métadonnées dans les requêtes.
Tout d’abord, configurez une stratégie d'appel Azure Data Explorer pour la bibliothèque UA Cloud Library en exécutant la requête suivante sur votre cluster Azure Data Explorer. Avant de commencer, vérifiez que vous êtes membre du rôle AllDatabasesAdmin dans le cluster, que vous pouvez configurer dans le Portail Azure en accédant à la page Autorisations de votre cluster Azure Data Explorer.
.alter cluster policy callout @'[{"CalloutType": "webapi","CalloutUriRegex": "uacloudlibrary.opcfoundation.org","CanCall": true}]'
Exécutez ensuite la requête Azure Data Explorer suivante à partir du Portail Azure. Dans la requête :
- Remplacez
<INFORMATION_MODEL_IDENTIFIER_FROM_THE_UA_CLOUD_LIBRARY>par l’ID unique du modèle d’informations que vous souhaitez importer à partir de la bibliothèque UA Cloud Library. Vous trouverez cet ID dans l’URL de la page du modèle d’informations dans la bibliothèque UA Cloud Library. Par exemple, l’ID de l’ensemble de nœuds de la station que ce tutoriel utilise est1627266626. - Remplacez
<HASHED_CLOUD_LIBRARY_CREDENTIALS>par un en-tête d'autorisation basique avec vos informations d'identification UA Cloud Library. Utilisez un outil tel que https://www.debugbear.com/basic-auth-header-generator pour générer le hachage. Vous pouvez également utiliser la commande Bash suivante :echo -n 'username:password' | base64.
let uri='https://uacloudlibrary.opcfoundation.org/infomodel/download/<INFORMATION_MODEL_IDENTIFIER_FROM_THE_UA_CLOUD_LIBRARY>';
let headers=dynamic({'accept':'text/plain', 'Authorization':'Basic <HASHED_CLOUD_LIBRARY_CREDENTIALS>'});
evaluate http_request(uri, headers)
| project title = tostring(ResponseBody.['title']), contributor = tostring(ResponseBody.contributor.name), nodeset = parse_xml(tostring(ResponseBody.nodeset.nodesetXml))
| mv-expand UAVariable=nodeset.UANodeSet.UAVariable
| project-away nodeset
| extend NodeId = UAVariable.['@NodeId'], DisplayName = tostring(UAVariable.DisplayName.['#text']), BrowseName = tostring(UAVariable.['@BrowseName']), DataType = tostring(UAVariable.['@DataType'])
| project-away UAVariable
| take 10000
Pour afficher une représentation graphique d’un modèle d’informations OPC UA, vous pouvez utiliser l’outil Kusto Explorer. Pour afficher le modèle du poste, exécutez la requête suivante dans Kusto Explorer. Pour obtenir des résultats optimaux, remplacez l’option Layout par Grouped et Labels par name :
let uri='https://uacloudlibrary.opcfoundation.org/infomodel/download/1627266626';
let headers=dynamic({'accept':'text/plain', 'Authorization':'Basic <HASHED_CLOUD_LIBRARY_CREDENTIALS>'});
let variables = evaluate http_request(uri, headers)
| project title = tostring(ResponseBody.['title']), contributor = tostring(ResponseBody.contributor.name), nodeset = parse_xml(tostring(ResponseBody.nodeset.nodesetXml))
| mv-expand UAVariable = nodeset.UANodeSet.UAVariable
| extend NodeId = UAVariable.['@NodeId'], ParentNodeId = UAVariable.['@ParentNodeId'], DisplayName = tostring(UAVariable['DisplayName']), DataType = tostring(UAVariable.['@DataType']), References = tostring(UAVariable.['References'])
| where References !contains "HasModellingRule"
| where DisplayName != "InputArguments"
| project-away nodeset, UAVariable, References;
let objects = evaluate http_request(uri, headers)
| project title = tostring(ResponseBody.['title']), contributor = tostring(ResponseBody.contributor.name), nodeset = parse_xml(tostring(ResponseBody.nodeset.nodesetXml))
| mv-expand UAObject = nodeset.UANodeSet.UAObject
| extend NodeId = UAObject.['@NodeId'], ParentNodeId = UAObject.['@ParentNodeId'], DisplayName = tostring(UAObject['DisplayName']), References = tostring(UAObject.['References'])
| where References !contains "HasModellingRule"
| project-away nodeset, UAObject, References;
let nodes = variables
| project source = tostring(NodeId), target = tostring(ParentNodeId), name = tostring(DisplayName)
| join kind=fullouter (objects
| project source = tostring(NodeId), target = tostring(ParentNodeId), name = tostring(DisplayName)) on source
| project source = coalesce(source, source1), target = coalesce(target, target1), name = coalesce(name, name1);
let edges = nodes;
edges
| make-graph source --> target with nodes on source

Déployer optionnellement Opérations Azure IoT en périphérie
Vous pouvez utiliser des opérations Azure IoT sur la périphérie. Azure IoT Operations est un plan de données unifié pour l'edge. Il comprend un ensemble de services de données modulaires, évolutifs et hautement disponibles qui s’exécutent sur des clusters Kubernetes de périphérie avec Azure Arc.
Suivez ces étapes dans les détails du déploiement d’Azure IoT Operations.
Vous pouvez configurer votre déploiement Azure IoT Operations à l’aide de l'interface Experience Operations web UI. Ajoutez les points de terminaison d'actifs, les actifs et les flux de données pour traiter les données issues de la simulation de la ligne de production et les acheminer vers le hub de données dans votre espace de noms Event Hubs.
Dans votre déploiement Azure IoT Operations, créez des points de terminaison d'actifs qui établissent des connexions avec les serveurs OPC UA suivants dans la simulation de production :
opc.tcp://assembly.munich/opc.tcp://test.munich/opc.tcp://packaging.munich/opc.tcp://assembly.seattle/opc.tcp://test.seattle/opc.tcp://packaging.seattle/
Monitoring des conditions de cas d’utilisation, calcul du TRG, détection d’anomalie et prédictions dans Azure Data Explorer
Pour savoir comment créer des tableaux de bord sans code pour le monitoring des conditions, les prédictions de rendement ou de maintenance, ou la détection d’anomalie, consultez la documentation Azure Data Explorer. Vous pouvez également déployer un exemple de tableau de bord. Pour savoir comment déployer un tableau de bord, consultez Visualiser des données avec des tableaux de bord Azure Data Explorer > créer à partir d’un fichier. Une fois que vous avez importé le tableau de bord, mettez à jour sa source de données. Spécifiez le point de terminaison HTTPS de votre cluster de serveurs Azure Data Explorer dans le coin supérieur droit du tableau de bord. Le point de terminaison HTTPS ressemble à ceci : https://<ADXInstanceName>.<AzureRegion>.kusto.windows.net/.

Remarque
Pour afficher le TRG pour un shift spécifique, sélectionnez Intervalle de temps personnalisé dans la liste déroulante Intervalle de temps en haut à gauche du tableau de bord Azure Data Explorer, puis entrez la date et l’heure de début et de fin du shift qui vous intéresse.
Afficher l’UNS (Unified NameSpace) intégré et le graphe de modèle ISA-95 dans Kusto Explorer
Cette solution de référence implémente un espace de noms unifié (UNS) basé sur les métadonnées OPC UA envoyées à la base de données de série chronologique Azure Data Explorer dans le cloud. Ces métadonnées OPC UA incluent la hiérarchie des ressources ISA-95. Vous pouvez visualiser le graphique résultant dans l’outil Kusto Explorer.
Ajoutez une nouvelle connexion à votre instance Azure Data Explorer, puis exécutez la requête suivante dans Kusto Explorer :
let edges = opcua_metadata_lkv
| project source = DisplayName, target = Workcell
| join kind=fullouter (opcua_metadata_lkv
| project source = Workcell, target = Line) on source
| join kind=fullouter (opcua_metadata_lkv
| project source = Line, target = Area) on source
| join kind=fullouter (opcua_metadata_lkv
| project source = Area, target = Site) on source
| join kind=fullouter (opcua_metadata_lkv
| project source = Site, target = Enterprise) on source
| project source = coalesce(source, source1, source2, source3, source4), target = coalesce(target, target1, target2, target3, target4);
let nodes = opcua_metadata_lkv;
edges | make-graph source --> target with nodes on DisplayName
Pour obtenir des résultats optimaux, remplacez l’option Layout par Grouped.

Utiliser Azure Managed Grafana
Vous pouvez également utiliser Azure Managed Grafana pour créer un tableau de bord sur Azure pour la solution décrite dans cet article. Utilisez Grafana dans le secteur industriel pour créer des tableaux de bord qui affichent des données en temps réel. Les étapes suivantes vous montrent comment activer Grafana sur Azure et créer un tableau de bord avec les données de ligne de production simulées à partir d’Azure Data Explorer.
Activer le service Azure Managed Grafana
Pour créer un service Azure Managed Grafana et le configurer avec des autorisations pour accéder à la base de données des ontologies :
Dans le Portail Azure, recherchez Grafana, puis sélectionnez le service Azure Managed Grafana.
Pour créer le service, dans la page Créer un espace de travail Grafana, entrez un nom pour votre instance. Choisissez toutes les options par défaut.
Une fois le service créé, vérifiez que votre instance Grafana dispose d’une identité managée affectée par le système, en accédant au panneau Identité de votre instance Azure Managed Grafana dans le Portail Azure. Si l’identité managée affectée par le système n’est pas activée, activez-la. Notez la valeur de l’ID d’objet (principal), vous en aurez besoin ultérieurement.
Pour accorder à l’identité managée l’autorisation d’accéder à la base de données des ontologies dans Azure Data Explorer :
- Accédez au panneau Autorisations dans votre instance Azure Data Explorer dans le Portail Azure.
- Sélectionnez Ajouter > AllDatabasesViewer.
- Recherchez et sélectionnez la valeur de l’ID d’objet (principal) que vous avez notée précédemment.
Ajouter une nouvelle source de données dans Grafana
Ajoutez une nouvelle source de données pour vous connecter à Azure Data Explorer. Dans cet exemple, vous utilisez une identité managée affectée par le système pour vous connecter à Azure Data Explorer. Pour configurer l’authentification, procédez comme suit :
Pour ajouter la source de données dans Grafana, procédez comme suit :
Accédez à l’URL du point de terminaison de votre instance Grafana. Vous trouverez l’URL du point de terminaison dans la page Azure Managed Grafana de votre instance dans le Portail Azure. Connectez-vous ensuite à votre instance Grafana.
Dans le tableau de bord Grafana, sélectionnez Connexions > Sources de données, puis sélectionnez Ajouter une nouvelle source de données. Défilez vers le bas et sélectionnez Source de données Azure Data Explorer.
Choisissez Identité managée comme menu d’authentification. Ajoutez ensuite l’URL de votre cluster Azure Data Explorer. Vous trouverez l’URL dans le menu d’instance d’Azure Data Explorer dans le Portail Azure sous URI.
Sélectionnez Enregistrer et tester pour vérifier la connexion de la source de données.
Importer un exemple de tableau de bord
Maintenant, vous êtes prêt à importer l’exemple de tableau de bord.
Téléchargez le tableau de bord Exemple de tableau de bord Fabrication Grafana.
Dans le menu Grafana, accédez à Tableaux de bord, puis sélectionnez Nouveau > Importer.
Sélectionnez Charger le fichier JSON du tableau de bord, puis sélectionnez le fichier samplegrafanadashboard.json que vous avez téléchargé précédemment. Cliquez sur Importer.
Dans le panneau Station TRG, sélectionnez Modifier, puis sélectionnez la Source de données Azure Data Explorer que vous avez configurée précédemment. Sélectionnez ensuite KQL dans le volet de requête et ajoutez la requête suivante :
print round (CalculateOEEForStation('${Station}', '${Location}', '${CycleTime}', '${__from:date:iso}', '${__to:date:iso}') * 100, 2). Sélectionnez Appliquer pour appliquer vos modifications et revenir au tableau de bord.Dans le panneau Ligne TRG, sélectionnez Modifier, puis sélectionnez la Source de données Azure Data Explorer que vous avez configurée précédemment. Sélectionnez ensuite KQL dans le volet de requête et ajoutez la requête suivante :
print round(CalculateOEEForLine('${Location}', '${CycleTime}', '${__from:date:iso}', '${__to:date:iso}') * 100, 2). Sélectionnez Appliquer pour appliquer vos modifications et revenir au tableau de bord.Dans le panneau Produits ignorés, sélectionnez Modifier, puis sélectionnez la Source de données Azure Data Explorer que vous avez configurée précédemment. Sélectionnez ensuite KQL dans le volet de requête et ajoutez la requête suivante :
opcua_metadata_lkv| where Name contains '${Station}'| where Name contains '${Location}'| join kind=inner (opcua_telemetry| where Name == "NumberOfDiscardedProducts"| where Timestamp > todatetime('${__from:date:iso}') and Timestamp < todatetime('${__to:date:iso}')) on DataSetWriterID| extend numProd = toint(Value)| summarize max(numProd). Sélectionnez Appliquer pour appliquer vos modifications et revenir au tableau de bord.Dans le panneau Produits fabriqués, sélectionnez Modifier, puis sélectionnez la Source de données Azure Data Explorer que vous avez configurée précédemment. Sélectionnez ensuite KQL dans le volet de requête et ajoutez la requête suivante :
opcua_metadata_lkv| where Name contains '${Station}'| where Name contains '${Location}'| join kind=inner (opcua_telemetry| where Name == "NumberOfManufacturedProducts"| where Timestamp > todatetime('${__from:date:iso}') and Timestamp < todatetime('${__to:date:iso}')) on DataSetWriterID| extend numProd = toint(Value)| summarize max(numProd). Sélectionnez Appliquer pour appliquer vos modifications et revenir au tableau de bord.Dans le panneau Consommation d’énergie, sélectionnez Modifier, puis sélectionnez la Source de données Azure Data Explorer que vous avez configurée précédemment. Sélectionnez ensuite KQL dans le volet de requête et ajoutez la requête suivante :
opcua_metadata_lkv| where Name contains '${Station}'| where Name contains '${Location}'| join kind=inner (opcua_telemetry | where Name == "Pressure" | where Timestamp > todatetime('${__from:date:iso}') and Timestamp < todatetime('${__to:date:iso}')) on DataSetWriterID| extend energy = todouble(Value)| summarize avg(energy)); print round(toscalar(averageEnergyConsumption) * 1000, 2). Sélectionnez Appliquer pour appliquer vos modifications et revenir au tableau de bord.Dans le panneau Pression, sélectionnez Modifier, puis sélectionnez la Source de données Azure Data Explorer que vous avez configurée précédemment. Sélectionnez ensuite KQL dans le volet de requête et ajoutez la requête suivante :
opcua_metadata_lkv| where Name contains '${Station}'| where Name contains '${Location}'| join kind=inner (opcua_telemetry | where Name == "Pressure" | where Timestamp > todatetime('${__from:date:iso}') and Timestamp < todatetime('${__to:date:iso}')) on DataSetWriterID| extend NodeValue = toint(Value)| project Timestamp1, NodeValue. Sélectionnez Appliquer pour appliquer vos modifications et revenir au tableau de bord.
Configurer les alertes
Dans Grafana, vous pouvez également créer des alertes. Dans cet exemple, vous créez une alerte TRG faible pour l’une des lignes de production.
Dans le menu Grafana, accédez à **Génération d’alertes>Règles d’alerte.
Sélectionnez Nouvelle règle d’alerte.
Donnez un nom à votre alerte et sélectionnez Azure Data Explorer comme source de données. Sélectionnez KQL dans le panneau Définir une requête et une condition d’alerte.
Dans le champ de requête, entrez la requête suivante. Cet exemple utilise la ligne de production Seattle :
let oee = CalculateOEEForStation("assembly", "seattle", 10000, now(), now(-1h)); print round(oee * 100, 2)Sélectionnez Définir comme condition d’alerte.
Faites défiler vers le bas jusqu’à la section Expressions. Supprimez l’expression Réduire, vous n’en avez pas besoin.
Pour le seuil d’alerte, sélectionnez A en tant qu’Entrée. Sélectionnez IS BELOW et saisissez 10.
Faites défiler jusqu’à la section Définir le comportement d’évaluation. Créez un Dossier pour enregistrer vos alertes. Créez un Groupe d’évaluation et spécifiez 2 m.
Sélectionnez le bouton Enregistrer la règle et quitter en haut à droite.
Dans la vue d’ensemble de vos alertes, vous pouvez maintenant voir qu’une alerte est déclenchée lorsque votre TRG est inférieur à 10.
Connecter la solution de référence à Microsoft Power BI
Pour connecter la solution de référence Power BI, vous devez accéder à un abonnement Power BI.
Pour créer le tableau de bord Power BI, effectuez les étapes suivantes :
Installez l’application Power BI Desktop.
Connectez-vous à l’application Power BI Desktop avec l’utilisateur qui a accès à l’abonnement Power BI.
Dans le Portail Azure, accédez à votre base de données Azure Data Explorer appelée ontologies et ajoutez les autorisations Administrateur de base de données à un utilisateur Microsoft Entra ID ayant accès uniquement à l’abonnement utilisé pour votre instance déployée de cette solution de référence. Si nécessaire, créez un utilisateur dans Microsoft Entra ID.
À partir de Power BI, créez un rapport et sélectionnez des données de série chronologique Azure Data Explorer comme source de données : Obtenir des données > Azure > Data Explorer (Kusto).
Dans la fenêtre contextuelle, entrez le point de terminaison Azure Data Explorer de votre cluster (
https://<your cluster name>.<location>.kusto.windows.net), le nom de la base de données (ontologies) et la requête suivante :let _startTime = ago(1h); let _endTime = now(); opcua_metadata_lkv | where Name contains "assembly" | where Name contains "munich" | join kind=inner (opcua_telemetry | where Name == "ActualCycleTime" | where Timestamp > _startTime and Timestamp < _endTime ) on DataSetWriterID | extend NodeValue = todouble(Value) | project Timestamp, NodeValueConnectez-vous à Azure Data Explorer avec l’utilisateur Microsoft Entra ID que vous avez précédemment autorisé à accéder à la base de données Azure Data Explorer.
Remarque
Si la colonne Timestamp contient la même valeur pour toutes les lignes, modifiez la dernière ligne de la requête comme suit :
| project Timestamp1, NodeValue.Sélectionnez Charger. Cette action permet d’importer la durée effective du cycle du poste Assemblage de la ligne de production de Munich pendant la dernière heure.
Depuis
Table viewsélectionnez la colonne NodeValue et sélectionnez Ne pas résumer dans l’élément de menu Summarization.Basculez sur
Report view.Sous Visualisations, sélectionnez la visualisation Graphique en courbes.
Sous Visualisations, déplacez
Timestampde la sourceDataversX-axis, sélectionnez-la , puis sélectionnez Timestamp.Sous Visualisations, déplacez
NodeValuede la sourceDataversY-axis, sélectionnez-la et sélectionnez Médiane.Enregistrez votre nouveau rapport.
Conseil
Suivez la même approche pour ajouter d’autres données d’Azure Data Explorer à votre rapport.

Connecter la solution de référence à Microsoft Dynamics 365 Field Service
Cette intégration présente les scénarios suivants :
- Chargez des ressources de la solution de référence des ontologies de fabrication sur Dynamics 365 Field Service.
- Création d’alertes dans Dynamics 365 Field Service lorsqu’un certain seuil sur les données de télémétrie de la solution de référence des ontologies de fabrication est atteint.
L’intégration utilise Azure Logics Apps. Avec Logic Apps, vous pouvez utiliser des flux de travail sans code pour connecter des applications et des services critiques pour l’entreprise. Cet exemple montre comment extraire des données à partir d’Azure Data Explorer et déclencher des actions dans Dynamics 365 Field Service.
Si vous n’êtes pas déjà un client Dynamics 365 Field Service, activez une version d’évaluation de 30 jours.
Conseil
Pour éviter la nécessité de configurer l’authentification entre locataires, utilisez le même Microsoft Entra ID que celui que vous avez utilisé pour déployer la solution de référence des ontologies de fabrication.
Créer un flux de travail Azure Logic Apps pour créer des ressources dans Dynamics 365 Field Service
Pour charger des ressources de la solution de référence des ontologies de fabrication dans Dynamics 365 Field Service :
Accédez au Portail Azure et créez une ressource d’application logique.
Donnez un nom à Azure Logic Apps et placez-la dans le même groupe de ressources que la solution de référence des ontologies de fabrication.
Sélectionnez Workflows.
Donnez un nom à votre flux de travail. Pour ce scénario, utilisez le type avec état, car les ressources ne sont pas des flux de données.
Dans le concepteur de flux de travail, sélectionnez Ajouter un déclencheur. Créez un déclencheur Récurrence à exécuter tous les jours. Vous pouvez modifier le déclencheur pour qu’il se produise plus fréquemment.
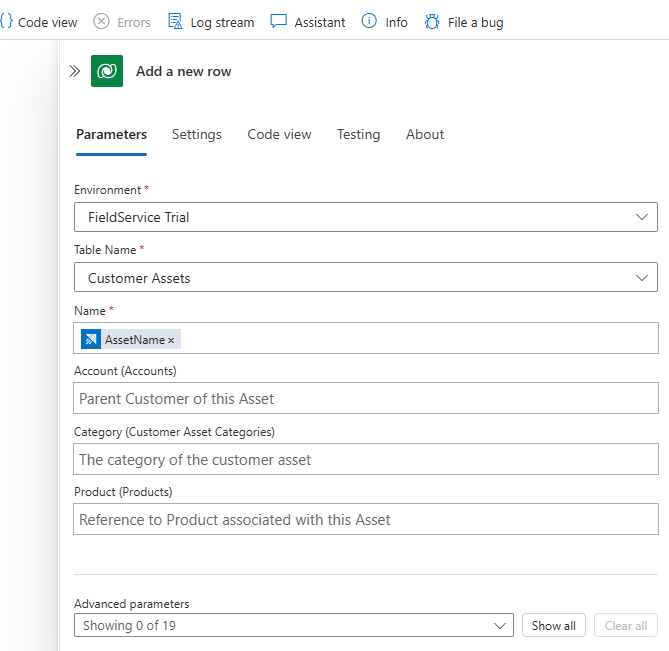
Ajoutez une action après le déclencheur de récurrence. Dans Ajouter une action, recherchez
Azure Data Exploreret sélectionnez la commande Exécuter la requête KQL. Laissez l’authentification par défaut OAuth. Entrez l’URL de votre cluster Azure Data Explorer etontologiescomme nom de base de données. Dans cette requête, vous vérifiez le type de ressources dont vous disposez. Utilisez la requête suivante pour obtenir des ressources de la solution de référence des ontologies de fabrication :opcua_telemetry | join kind=inner ( opcua_metadata | distinct Name, DataSetWriterID | extend AssetList = split(Name, ';') | extend AssetName = tostring(AssetList[0]) ) on DataSetWriterID | project AssetName | summarize by AssetNamePour obtenir vos données de ressources dans Dynamics 365 Field Service, vous devez vous connecter à Microsoft Dataverse. Dans Ajouter une action, recherchez
Dataverseet sélectionnez la commande Ajouter une nouvelle ligne. Laissez l’authentification par défaut OAuth. Connectez-vous à votre instance Dynamics 365 Field Service et utilisez la configuration suivante :- Dans le champ Nom de la table, sélectionnez Ressources client
- Dans le champ Nom, sélectionnez Entrer des données à partir d’une étape précédente, puis sélectionnez AssetName.
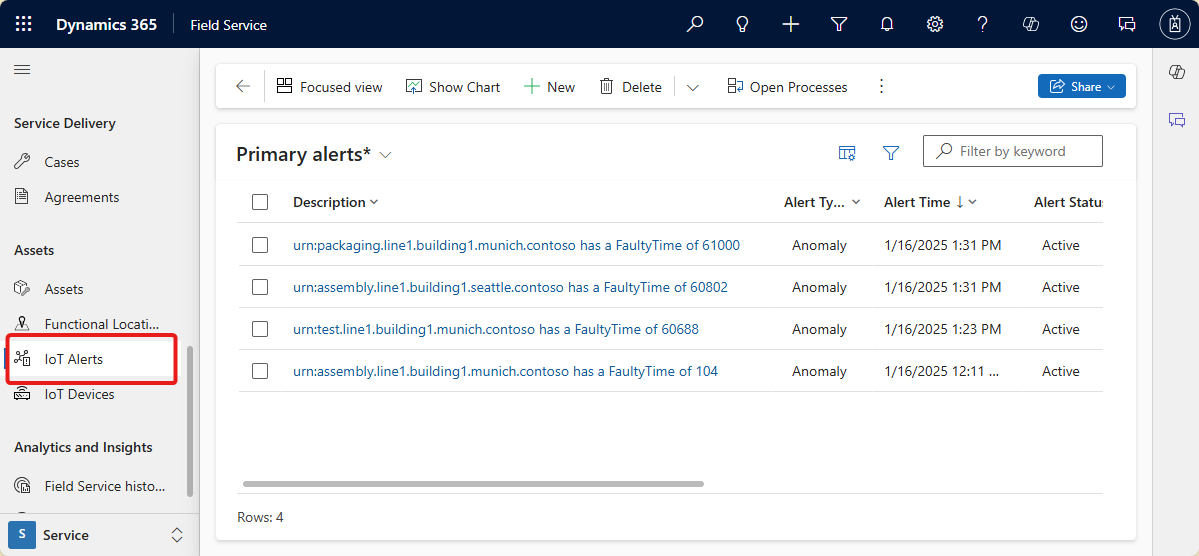
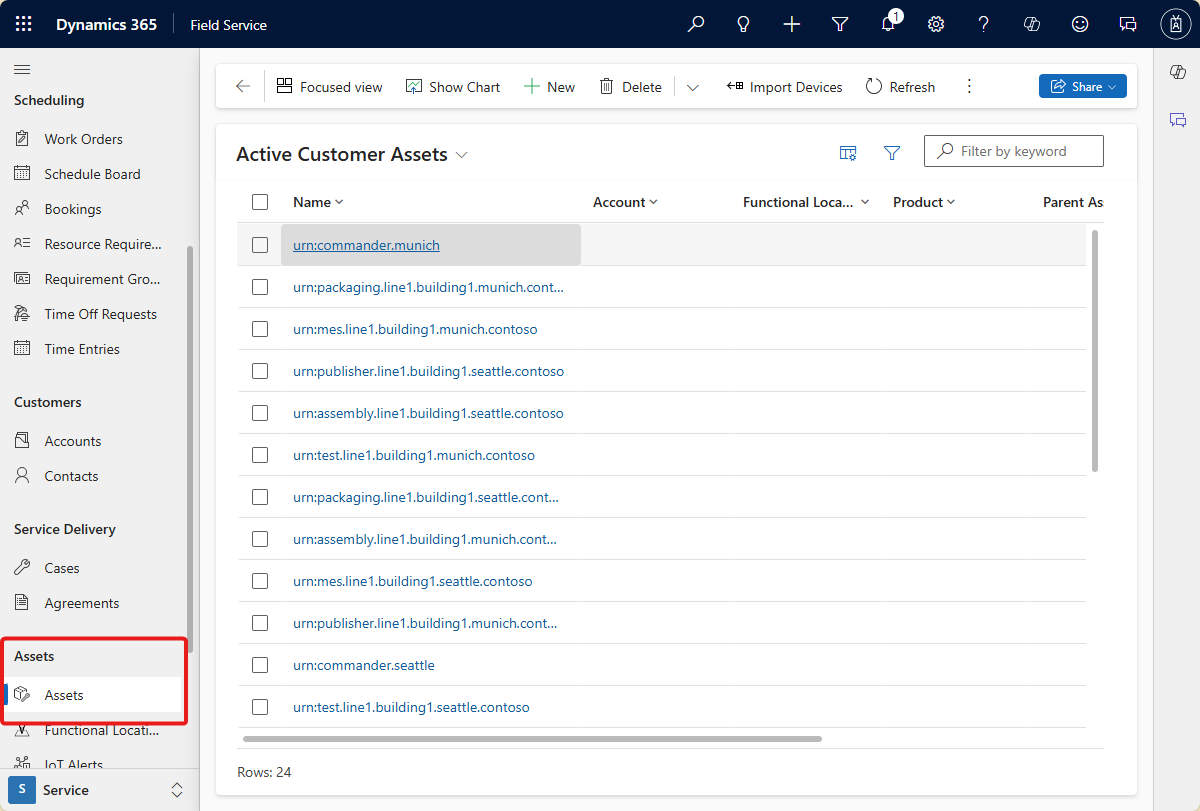
Enregistrez votre workflow et exécutez-le. Vous pouvez voir que les nouvelles ressources sont créées dans Dynamics 365 Field Service :
Créer un flux de travail Azure Logic Apps pour créer des alertes dans Dynamics 365 Field Service
Ce flux de travail crée des alertes dans Dynamics 365 Field Service, lorsque le FaultyTime d’une ressource dans la solution de référence des ontologies de fabrication atteint un seuil.
Pour extraire les données, créez une fonction Azure Data Explorer. Dans le volet de requête Azure Data Explorer dans le Portail Azure, exécutez le code suivant pour créer une fonction
FaultyFieldAssetsdans les bases de données des ontologies :.create-or-alter function FaultyFieldAssets() { let Lw_start = ago(3d); opcua_telemetry | where Name == 'FaultyTime' and Value > 0 and Timestamp between (Lw_start .. now()) | join kind=inner ( opcua_metadata | extend AssetList =split (Name, ';') | extend AssetName=AssetList[0] ) on DataSetWriterID | project AssetName, Name, Value, Timestamp}Créez un flux de travail avec état dans votre application logique.
Dans le concepteur de flux de travail, créez un déclencheur de périodicité qui s’exécute toutes les trois minutes. Ensuite, ajoutez une action et sélectionnez l’action Exécuter la requête KQL.
Entrez votre URL de cluster Azure Data Explorer, puis entrez ontologies comme nom de base de données et utilisez le nom de la fonction
FaultyFieldAssetscomme requête.Pour obtenir vos données de ressources dans Dynamics 365 Field Service, vous devez vous connecter à Microsoft Dataverse. Dans Ajouter une action, recherchez
Dataverseet sélectionnez la commande Ajouter une nouvelle ligne. Laissez l’authentification par défaut OAuth. Connectez-vous à votre instance Dynamics 365 Field Service et utilisez la configuration suivante :- Dans le champ Nom de la table, sélectionnez Alertes IoT
- Dans le champ Description, utilisez Entrer des données depuis une étape précédente, pour générer un message « [AssetName] a un(e) [Name] de [Value] ». AssetName, Name et Value sont les champs de l’étape précédente.
- Dans le champ Heure d’alerte, sélectionnez Entrer des données à partir d’une étape précédente, puis sélectionnez Timestamp.
- Dans le champ Type d’alerte, sélectionnez Anomalie.
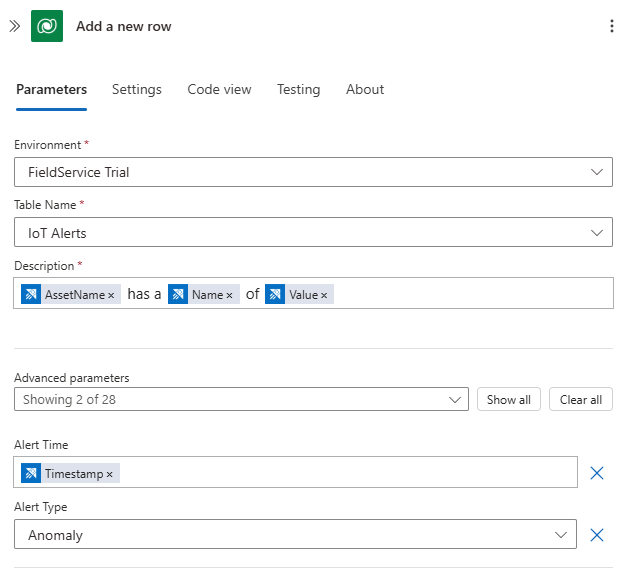
Exécutez le flux de travail pour voir les nouvelles alertes générées dans votre tableau de bord Dynamics 365 Field Service Alertes IoT :