Démarrage rapide : data wrangling interactif avec Apache Spark dans Azure Machine Learning
Pour gérer le data wrangling des notebooks d’Azure Machine Learning interactifs, l’intégration d’Azure Machine Learning à Azure Synapse Analytics permet d’accéder facilement à l’infrastructure Apache Spark. Cet accès permet le data wrangling interactif Azure Machine Learning Notebook.
Dans ce guide de démarrage rapide, vous découvrez comment effectuer du data wrangling interactif avec un calcul Spark serverless Azure Machine Learning, un compte de stockage Azure Data Lake Storage (ADLS) Gen2 et le passthrough d’identité utilisateur.
Prérequis
- Un abonnement Azure ; si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
- Un espace de travail Azure Machine Learning. Consultez Créer des ressources d’espace de travail.
- Un compte de stockage Azure Data Lake Storage (ADLS) Gen2. Consultez Créer un compte de stockage Azure Data Lake Storage (ADLS) Gen 2.
Stocker les informations d’identification du compte de stockage Azure en tant que secrets dans Azure Key Vault
Pour stocker les informations d’identification du compte de stockage Azure en tant que secrets dans le coffre de clés Azure avec l’interface utilisateur du portail Azure :
Accédez à votre coffre de clés Azure dans le portail Azure.
Dans le volet gauche, sélectionnez Secrets.
Sélectionnez + Générer/importer.
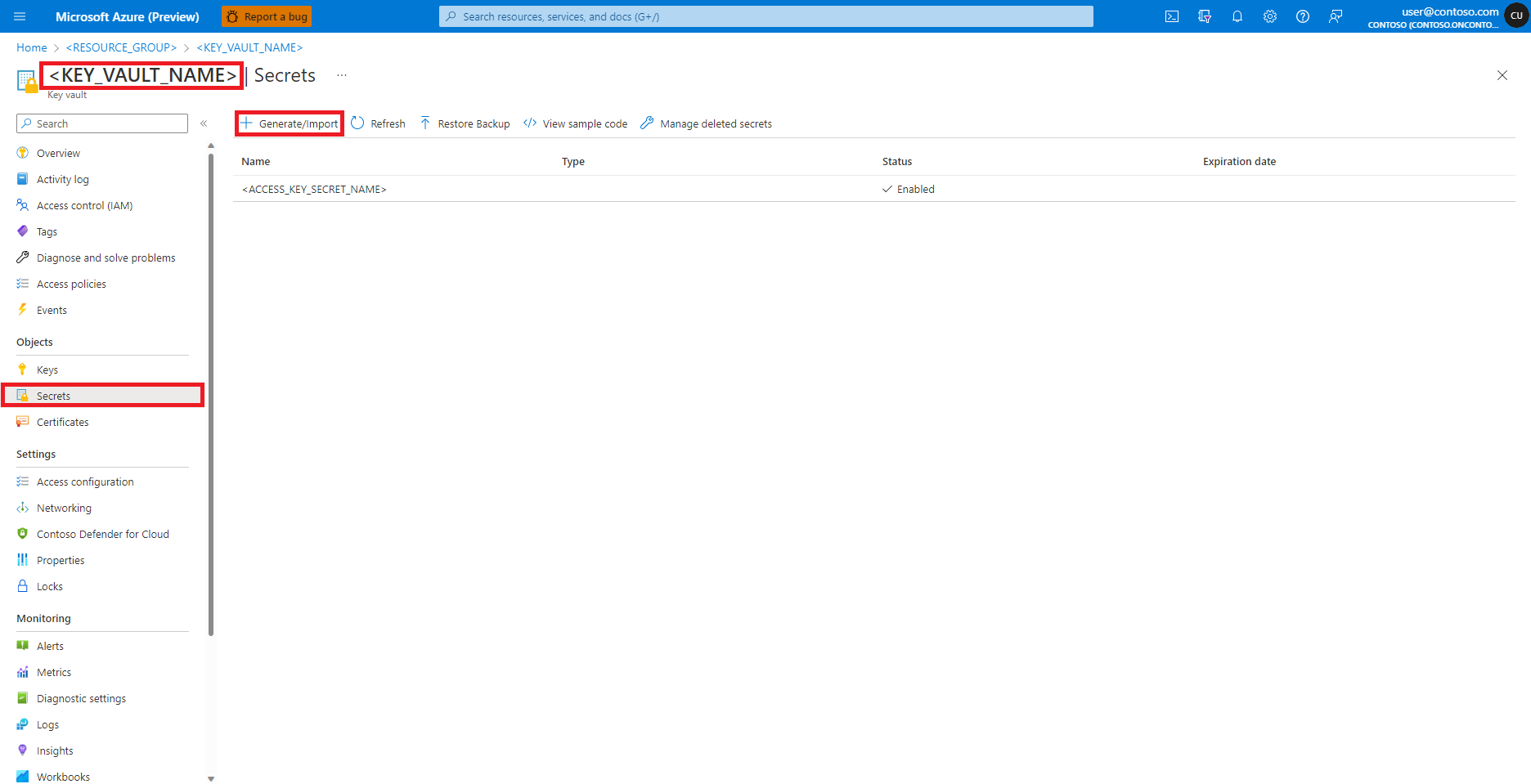
Dans l’écran Créer un secret, entrez un Nom pour le secret que vous voulez créer.
Dans le portail Azure, accédez au compte Stockage Blob Azure, comme illustré dans cette image :
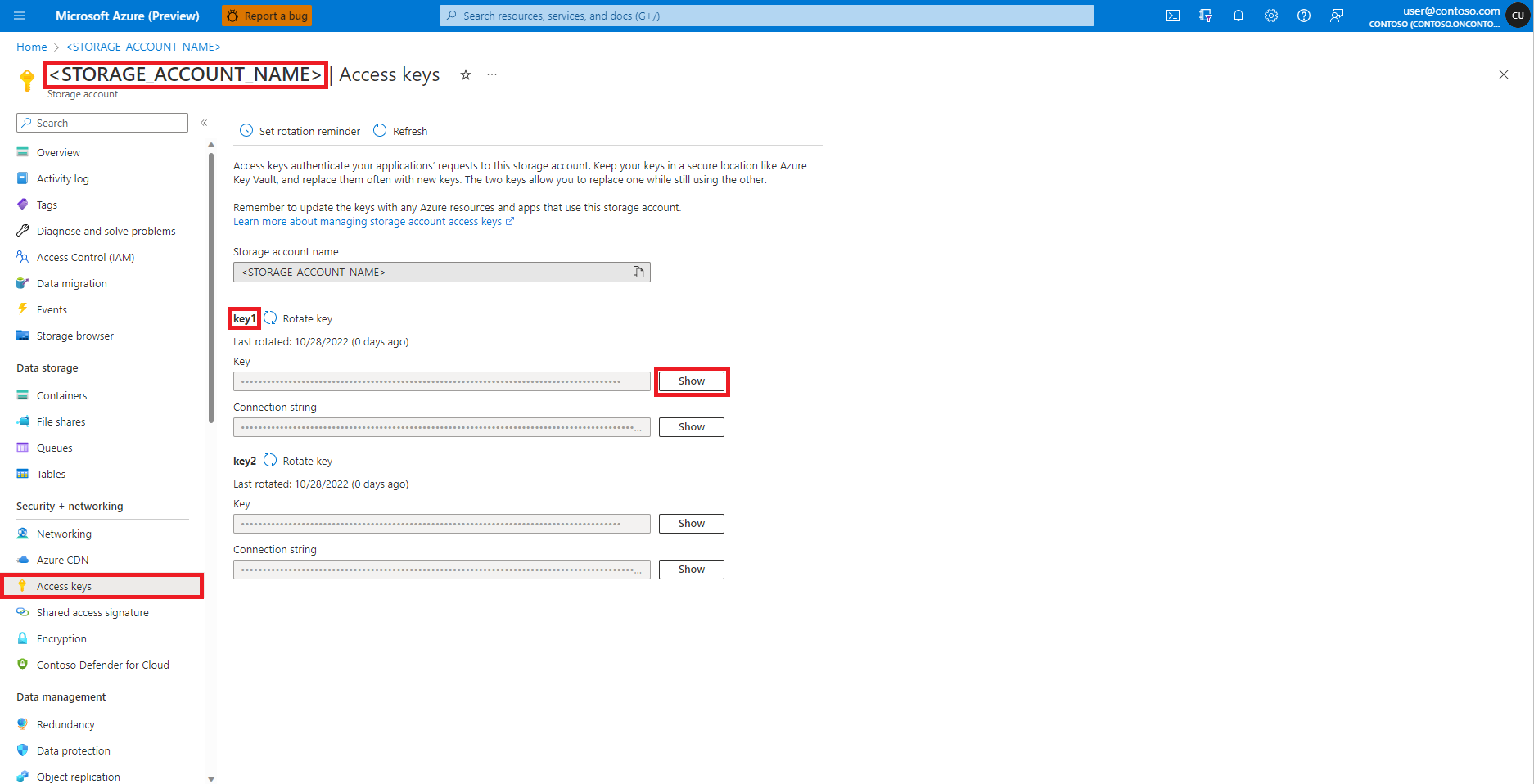
Sélectionnez Clés d’accès dans le volet gauche de la page du compte Stockage Blob Azure.
Sélectionnez Afficher en regard de Clé 1, puis Copier dans le Presse-papiers pour obtenir la clé d’accès du compte de stockage.
Remarque
Sélectionnez les options appropriées pour copier
- Jetons de signature d’accès partagé (SAP) du conteneur de stockage Blob Azure
- Informations d’identification du principal de service de compte de stockage Azure Data Lake Storage (ADLS) Gen 2
- ID client
- ID client et
- secret
dans les interfaces utilisateur respectives lors de la création des secrets Azure Key Vault pour ceux-ci.
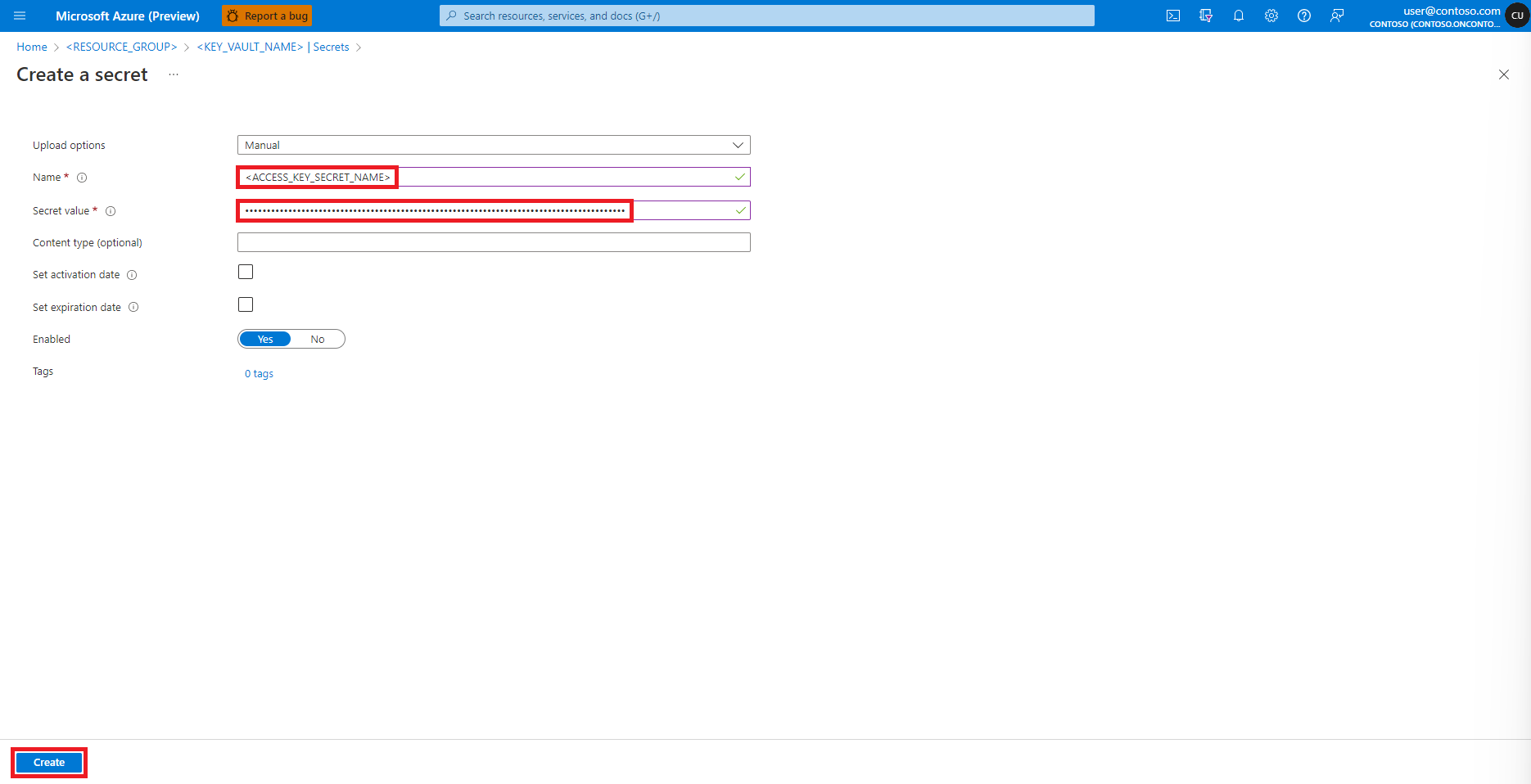
Revenez à l’écran Créer un secret.
Dans la zone de texte Valeur du secret, entrez les informations d’identification de la clé d’accès pour le compte de stockage Azure, qui ont été copiées dans le Presse-papiers à l’étape précédente.
Sélectionnez Créer
Conseil
Azure CLI et Azure Key Vault bibliothèque de client de secrets pour Python peuvent également créer des secrets Azure Key Vault.
Ajouter des attributions de rôles dans des comptes de stockage Azure
Nous devons nous assurer que les chemins d’accès aux données d’entrée et de sortie sont accessibles avant de commencer le data wrangling interactif. Tout d’abord, pour
L’identité utilisateur de l’utilisateur connecté à la session Notebooks
or
un principal du service
Attribuez des rôles Lecteur et Lecteur des données BLOB du stockage à l’identité de l’utilisateur connecté. Toutefois, dans certains scénarios, nous pourrions vouloir réécrire les données étranglées dans le compte de stockage Azure. Les rôles Lecteur et Lecteur de données Blob de stockage fournissent un accès en lecture seule à l’identité de l’utilisateur ou au principal de service. Pour activer l’accès en lecture et en écriture, attribuez les rôles Contributeur et Contributeur aux données blob de stockage à l’identité utilisateur ou au principal de service. Pour attribuer des rôles appropriés à l’identité d’utilisateur :
Ouvrez le portail Microsoft Azure.
Recherchez et sélectionnez le service Comptes de stockage.

Dans la page Comptes de stockage, sélectionnez le compte de stockage Azure Data Lake Storage (ADLS) Gen 2 dans la liste. Une page montrant la Vue d’ensemble du compte de stockage s’ouvre.

Dans le volet de gauche, sélectionnez Contrôle d’accès (IAM).
Sélectionnez Ajouter une attribution de rôle.

Recherchez et sélectionnez le rôle Contributeur aux données blob du stockage
Sélectionnez Suivant.
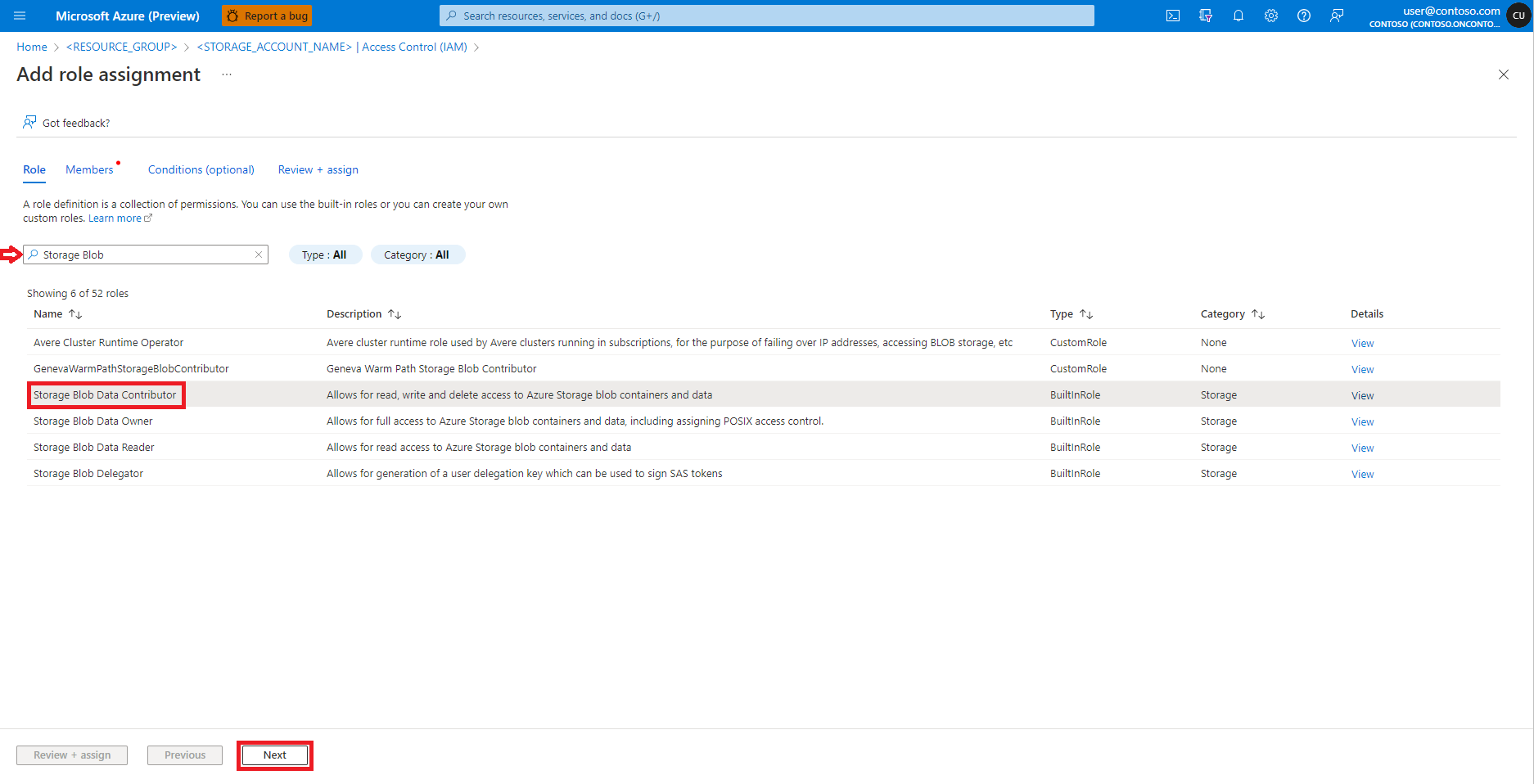
Sélectionnez Utilisateur, groupe ou principal de service.
Sélectionnez + Sélectionner des membres.
Recherchez l’identité de l’utilisateur sous Sélectionner
Sélectionnez l’identité de l’utilisateur dans la liste afin qu’elle s’affiche sous Membres sélectionnés
Sélectionner l’identité d’utilisateur appropriée
Sélectionnez Suivant.
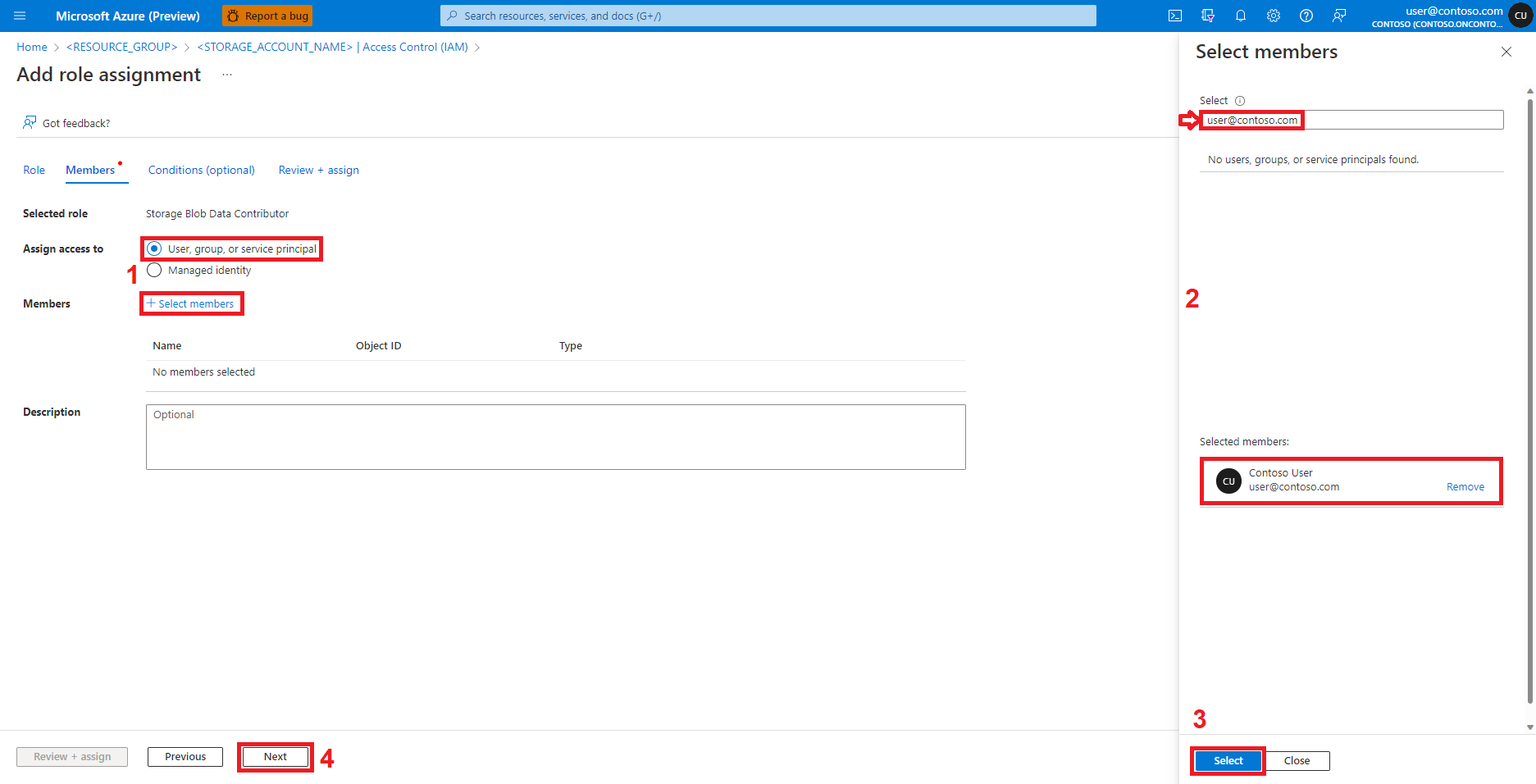
Sélectionnez Vérifier + attribuer

Répétez les étapes 2 à 13 pour l’attribution du rôle Contributeur.






Une fois que les rôles appropriés ont été attribués à l’identité de l’utilisateur, les données du compte de stockage Azure doivent devenir accessibles.
Remarque
Si un pool Synapse Spark attaché pointe vers un pool Synapse Spark dans un espace de travail Azure Synapse auquel est associé un réseau virtuel managé, vous devez configurer un point de terminaison privé managé pour un compte de stockage de façon à garantir l’accès aux données.
Garantir l’accès aux ressources pour les travaux Spark
Pour accéder aux données et aux autres ressources, les tâches Spark peuvent utiliser une identité managée ou un passthrough d’identité utilisateur. Le tableau suivant résume les différents mécanismes d’accès aux ressources quand vous utilisez un calcul Spark serverless Azure Machine Learning et un pool Spark Synapse attaché.
| Pool Spark | Identités prises en charge | Identité par défaut |
|---|---|---|
| Calcul Spark serverless | Identité utilisateur, identité managée affectée par l’utilisateur attachée à l’espace de travail | Identité de l’utilisateur |
| Pool Spark Synapse attaché | Identité utilisateur, identité managée affectée par l’utilisateur attachée au pool Synapse Spark attaché, identité managée affectée par le système du pool Synapse Spark attaché | Identité managée affectée par le système du pool Spark Synapse attaché |
Si le code de l’interface CLI ou du kit de développement logiciel (SDK) définit une option pour utiliser l’identité managée, le calcul Spark serverless d’Azure Machine Learning repose sur une identité managée affectée par l’utilisateur attachée à l’espace de travail. Vous pouvez attacher une identité managée affectée par l’utilisateur à un espace de travail Azure Machine Learning existant avec Azure Machine Learning CLI v2 ou avec ARMClient.
Étapes suivantes
- Utiliser Apache Spark dans Azure Machine Learning
- Attachement et gestion d’un pool Spark Synapse dans Azure Machine Learning
- Data Wrangling interactif avec Apache Spark dans Azure Machine Learning
- Soumettre des travaux Spark dans Azure Machine Learning
- Exemples de code pour des travaux Spark avec l’interface CLI Azure Machine Learning
- Exemples de code pour des travaux Spark avec le SDK Python Azure Machine Learning