Data Wrangling interactif avec Apache Spark dans Azure Machine Learning
Le data wrangling devient l’une des étapes les plus importantes des projets machine learning. L’intégration d’Azure Machine Learning à Azure Synapse Analytics permet d’accéder à un pool Apache Spark ( avec Azure Synapse ) pour Data wrangling interactif à l’aide de notebooks Azure Machine Learning.
Dans cet article, vous allez apprendre à procéder à un data wrangling.
- Calcul Spark serverless
- Pool Spark Synapse attaché
Prérequis
- Un abonnement Azure : si vous n’en possédez pas, créez un compte gratuit avant de commencer.
- Un espace de travail Azure Machine Learning. Consultez Créer des ressources d’espace de travail.
- Un compte de stockage Azure Data Lake Storage (ADLS) Gen2. Consultez Créer un compte de stockage Azure Data Lake Storage (ADLS) Gen 2.
- (Facultatif) : Un coffre de clés Azure. Consultez Créer un Key Vault Azure.
- (Facultatif) : Un principal de service. Consultez Créer un principal de service.
- (Facultatif) : Pool Synapse Spark attaché dans l’espace de travail Azure Machine Learning.
Avant de démarrer vos tâches de data wrangling, découvrez le processus de stockage des secrets
- Clé d’accès au compte de stockage Azure
- Utilisez un jeton de signature d’accès partagé (SAP)
- Informations sur le principal de service Azure Data Lake Storage (ADLS) Gen 2
dans le Key Vault Azure. Vous devez également savoir comment gérer les attributions de rôles dans les comptes de stockage Azure. Les sections suivantes passe en revue ces concepts. Ensuite, nous allons explorer les détails du data wrangling interactif en utilisant des pools Spark dans des notebooks Azure Machine Learning.
Conseil
Pour en savoir plus sur la configuration de l’attribution de rôles de compte de stockage Azure ou si vous accédez aux données de vos comptes de stockage à l’aide d’un passthrough d’identité utilisateur, consultez Ajouter des attributions de rôles dans des comptes de stockage Azure.
Data wrangling interactif avec Apache Spark
Azure Machine Learning offre un calcul Spark serverless et un pool Spark Synapse attaché pour un data wrangling interactif avec Apache Spark dans les notebooks d’Azure Machine Learning. Le calcul Spark serverless ne nécessite pas la création de ressources dans l’espace de travail Azure Synapse. Au lieu de cela, un calcul Spark serverless entièrement managé devient directement disponible dans les notebooks Azure Machine Learning. L’utilisation d’un calcul Spark serverless constitue l’approche la plus simple pour accéder à un cluster Spark dans Azure Machine Learning.
Calcul Spark serverless dans les notebooks d’Azure Machine Learning
Un calcul Spark serverless est disponible par défaut dans les Notebooks d’Azure Machine Learning. Pour y accéder dans un notebook, sélectionnez Calcul Spark Serverless, sous Spark Servelerss d’Azure Machine Learning Serverless Spark dans le menu de sélection Calcul.
L’interface utilisateur Notebooks offre également des options de configuration de session Spark, pour le calcul Spark serverless. Pour configurer une session Spark :
- Sélectionner Configurer la session en haut de l’écran.
- Sélectionnez version d’Apache Spark dans le menu déroulant.
Important
Azure Synapse Runtime pour Apache Spark : annonces
- Runtime Azure Synapse pour Apache Spark 3.2 :
- Date d'annonce EOLA : 8 juillet 2023
- Date de fin de support : 8 juillet 2024. Après cette date, le runtime sera désactivé.
- Pour bénéficier d’un support continu et de performances optimales, nous vous conseillons de migrer vers Apache Spark 3.3.
- Runtime Azure Synapse pour Apache Spark 3.2 :
- Sélectionnez Type d’instance dans le menu déroulant. Actuellement, les types d’instance suivants sont pris en charge :
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
- Entrez une valeur de délai d’expiration de session Spark, en minutes.
- Sélectionnez s’il faut allouer dynamiquement des exécuteurs
- Sélectionnez le nombre d’exécuteurs pour la session Spark.
- Sélectionnez Taille d’exécuteur dans le menu déroulant.
- Sélectionnez Taille du pilote dans le menu déroulant.
- Pour utiliser un fichier Conda visant à configurer une session Spark, cochez la case Charger le fichier conda. Ensuite, sélectionnez Parcourir, puis choisissez le fichier Conda avec la configuration de session Spark souhaitée.
- Ajoutez les Propriétés des paramètres de configuration, les valeurs d’entrée dans les zones de texte Propriété et Valeur , puis sélectionnez Ajouter.
- Sélectionnez Appliquer.
- Sélectionnez Arrêter la session dans la fenêtre contextuelle Configurer une nouvelle session ?.
Les modifications de configuration de session persistent et sont mises à la disposition d’une autre session notebook démarrée à partir du calcul Spark serverless.
Conseil
Si vous utilisez des packages Conda au niveau de la session, vous pouvez améliorer le temps de démarrage à froid des sessions Spark si vous définissez la variable de configuration spark.hadoop.aml.enable_cache avec la valeur true. Le démarrage à froid d’une session avec les packages Conda au niveau de la session prend généralement 10 à 15 minutes lorsque la session démarre pour la première fois. Par contre, les démarrages à froid suivants avec la variable de configuration définie avec la valeur true prennent généralement trois à cinq minutes.
Importer et étrangler des données à partir de Azure Data Lake Storage (ADLS) Gen 2
Vous pouvez accéder aux données stockées dans des comptes de stockage Azure Data Lake Storage (ADLS) Gen 2 avec abfss:// des URI de données en suivant l’un des deux mécanismes d’accès aux données :
- Passthrough d’identité utilisateur
- Accès aux données basées sur le principal de service
Conseil
Le data wrangling avec un calcul Spark serverless et une transmission directe des identités utilisateur pour accéder aux données d’un compte de stockage Azure Data Lake Storage (ADLS) Gen 2 nécessite le moins d’étapes de configuration.
Pour démarrer le wrangling de données interactif avec le passthrough d’identité utilisateur :
Vérifiez que l’identité de l’utilisateur a des attributions de rôlesContributeuretContributeur aux données Blob de stockage dans le compte de stockage Azure Data Lake Storage (ADLS) Gen 2.
Pour utiliser le calcul Spark serverless, sélectionnez Calcul Spark serverless, sous Spark serverless Azure Machine Learning dans le menu de sélectionCalcul.
Pour utiliser un pool Synapse Spark attaché, sélectionnez un pool Synapse Spark attaché sous Pools Synapse Spark dans le menu de sélection Calcul.
Cet exemple de code de wrangling de données Titanic montre l’utilisation d’un URI de données au format
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>avecpyspark.pandasetpyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled", index_col="PassengerId", )Remarque
Cet exemple de code Python utilise
pyspark.pandas. Seul le runtime Spark version 3.2 ou ultérieure le prend en charge.
Pour étrangler des données par accès via un principal de service :
Vérifiez que le principal de service a des attributions de rôlesContributeuretContributeur aux données Blob de stockage dans le compte de stockage Azure Data Lake Storage (ADLS) Gen 2.
Créez des secrets Azure Key Vault pour l’ID de locataire du principal de service, l’ID client et les valeurs de clé secrète client.
Sélectionnez Calcul Spark Serverless, sous Spark Serverless d’Azure Machine Learning dans le menu de sélection Calcul, ou sélectionnez un pool Spark Synapse attaché sous Pools Spark Synapse dans le menu de sélection Calcul.
Pour définir l’ID de locataire du principal de service, ainsi que l’ID client et la clé secrète client dans la configuration, exécutez l’exemple de code suivant.
L’appel de
get_secret()dans le code dépend du nom du coffre de clés Azure et des noms des secrets Azure Key Vault créés pour l’ID de locataire, l’ID de client et le secret client du principal de service. Définissez ces noms/valeurs de propriété correspondants dans la configuration :- Propriété ID client :
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Propriété de clé secrète client :
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Propriété ID de locataire :
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Valeur de l’ID de locataire :
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary # Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>") # Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set( "fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_id, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_secret, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", )- Propriété ID client :
Importez et structurez des données avec l’URI de données au format
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>, comme indiqué dans l’exemple de code en utilisant des données Titanic.
Importez et étranglez les données à partir du stockage Blob Azure
Vous pouvez accéder aux données du stockage Blob Azure avec la clé d’accès du compte de stockage ou un jeton de signature d’accès partagé (SAP). Vous devez stocker ces informations d’identification dans le Key Vault Azure en tant que secret et les définir en tant que propriétés dans la configuration de session.
Pour démarrer le wrangling de données interactif :
Dans le volet Azure Machine Learning studio gauche, sélectionnez Blocs-notes.
Sélectionnez Calcul Spark Serverless, sous Spark Serverless d’Azure Machine Learning dans le menu de sélection Calcul, ou sélectionnez un pool Spark Synapse attaché sous Pools Spark Synapse dans le menu de sélection Calcul.
Pour configurer la clé d’accès du compte de stockage ou un jeton de signature d’accès partagé (SAP) pour l’accès aux données dans Azure Machine Learning Notebooks :
Pour la clé d’accès, définissez la propriété
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netcomme indiqué dans cet extrait de code :from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key )Pour le jeton SAS, définissez la propriété
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netcomme indiqué dans cet extrait de code :from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", sas_token, )Notes
Les appels
get_secret()dans les extraits de code ci-dessus nécessitent le nom du Key Vault Azure et les noms des secrets créés pour la clé d’accès du compte de stockage Blob Azure ou le jeton SAP
Exécutez le code de data wrangling dans le même notebook. Créez l’URI de données sous la forme
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>, semblable à ce que montre cet extrait de code :import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled", index_col="PassengerId", )Remarque
Cet exemple de code Python utilise
pyspark.pandas. Seul le runtime Spark version 3.2 ou ultérieure le prend en charge.
Importer et wrangler des données à partir d’un magasin de données Azure Machine Learning
Pour accéder aux données du magasin de données Azure Machine Learning, définissez un chemin d’accès aux données du magasin de données au format URIazureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA>. Pour wrangle des données à partir d’un magasin de données Azure Machine Learning dans une session Notebooks de manière interactive :
Sélectionnez Calcul Spark Serverless, sous Spark Serverless d’Azure Machine Learning dans le menu de sélection Calcul, ou sélectionnez un pool Spark Synapse attaché sous Pools Spark Synapse dans le menu de sélection Calcul.
Cet exemple de code montre comment lire et extraire des données Titanic à partir d’un magasin de données Azure Machine Learning, à l’aide
azureml://de l’URI du magasin de données etpyspark.pandaspyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "azureml://datastores/workspaceblobstore/paths/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "azureml://datastores/workspaceblobstore/paths/data/wrangled", index_col="PassengerId", )Remarque
Cet exemple de code Python utilise
pyspark.pandas. Seul le runtime Spark version 3.2 ou ultérieure le prend en charge.
Les magasins de données Azure Machine Learning peuvent accéder aux données à l’aide des informations d’identification du compte de stockage Azure
- Clé d’accès
- Jeton SAS
- principal du service
ou fournir un accès aux données sans informations d’identification. Selon le type de magasin de données et le type de compte de stockage Azure sous-jacent, sélectionnez un mécanisme d’authentification approprié pour garantir l’accès aux données. Ce tableau récapitule les mécanismes d’authentification permettant d’accéder aux données dans les magasins de données Azure Machine Learning :
| Type de compte de stockage | Accès aux données sans informations d’identification | Mécanisme d’accès aux données | Affectations de rôles |
|---|---|---|---|
| Objets blob Azure | Non | Clé d’accès ou jeton SAP | Aucune attribution de rôle n’est nécessaire |
| Objets blob Azure | Oui | Passthrough d’identité utilisateur* | L’identité de l’utilisateur doit avoir des attributions de rôles appropriées dans le compte de stockage Blob Azure |
| Azure Data Lake Storage (ADLS) Gen 2 | Non | Principal du service | Le principal de service doit avoir des attributions de rôle appropriées dans le compte de stockage Azure Data Lake Storage (ADLS) Gen2 |
| Azure Data Lake Storage (ADLS) Gen 2 | Oui | Passthrough d’identité utilisateur | L’identité de l’utilisateur doit avoir des attributions de rôle appropriées dans le compte de stockage Azure Data Lake Storage (ADLS) Gen2 |
* La transmission directe d’identités utilisateur fonctionne pour les magasins de données sans informations d’identification qui pointent vers des comptes de stockage Blob Azure, seulement si la suppression réversible n’est pas activée.
Accès aux données sur le partage de fichiers par défaut
Le partage de fichiers par défaut est monté à la fois sur le calcul Spark serverless et sur les pools Spark Synapse attachés.
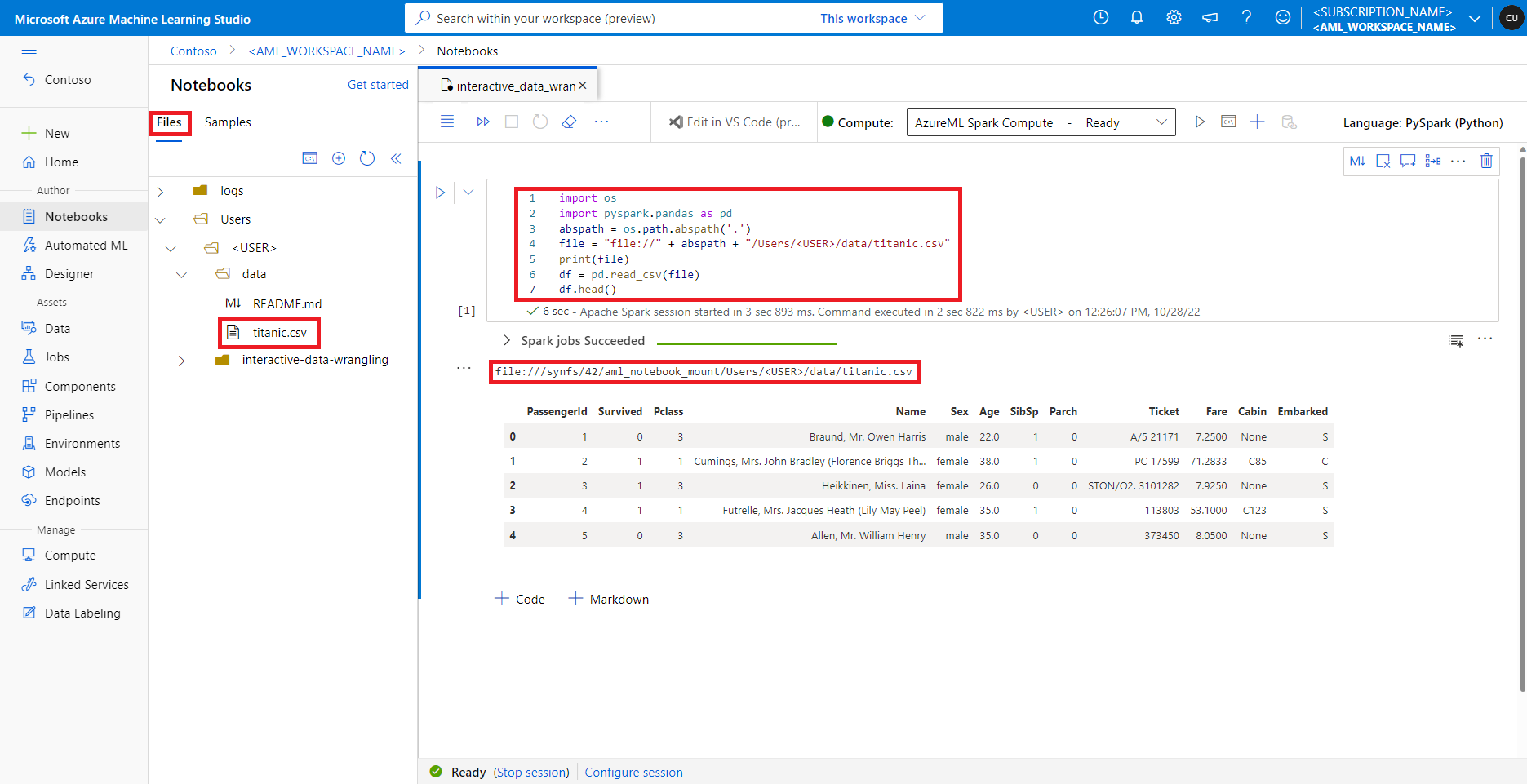
Dans Azure Machine Learning studio, les fichiers du partage de fichiers par défaut sont affichés dans l’arborescence de répertoires sous l’onglet Fichiers. Le code du notebook peut accéder directement aux fichiers stockés dans ce partage de fichiers avec le protocole file://, ainsi que le chemin absolu du fichier, sans autre configuration. Cet extrait de code montre comment accéder à un fichier stocké sur le partage de fichiers par défaut :
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
abspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(
inputCols=["Age"],
outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
Remarque
Cet exemple de code Python utilise pyspark.pandas. Seul le runtime Spark version 3.2 ou ultérieure le prend en charge.