Configurer un environnement de développement avec Azure Databricks et AutoML dans Azure Machine Learning
Découvrez comment configurer un environnement de développement dans Azure Machine Learning qui utilise des Azure Databricks et ML automatisé.
Azure Databricks est parfait pour l'exécution de flux de travail de Machine Learning intensifs à grande échelle sur la plateforme Apache Spark évolutive dans le cloud Azure. Il fournit un environnement basé sur Notebook collaboratif avec un cluster de calcul basé sur l’UC ou le GPU.
Pour plus d’informations sur les autres environnements de développement Machine Learning, consultez Configurer l’environnement de développement Python.
Configuration requise
Espace de travail Azure Machine Learning. Pour en créer un, suivez la procédure décrite dans l’article Créer des ressources d’espace de travail.
Azure Databricks avec Azure Machine Learning et AutoML
Azure Databricks s’intègre à Azure Machine Learning et à ses fonctionnalités AutoML.
Vous pouvez utiliser Azure Databricks :
- Pour l’apprentissage d’un modèle à l’aide de Spark MLlib et déployer le modèle sur ACI/AKS.
- Avec les fonctionnalités de Machine Learning automatisé utilisant un kit de développement logiciel (SDK) Azure Machine Learning.
- Comme cible de calcul à partir d’un pipeline Azure Machine Learning.
Configurer un cluster Databricks
Créez un cluster Databricks. Certains paramètres s’appliquent uniquement si vous installez le Kit de développement logiciel (SDK) pour l’apprentissage automatique automatisé sur Databricks.
La création du cluster ne prend que quelques minutes.
Utilisez les paramètres suivants :
| Paramètre | S’applique à | Valeur |
|---|---|---|
| Nom du cluster | toujours | Nom de votre cluster |
| Version de Databricks Runtime | toujours | 9.1 LTS |
| Version Python | toujours | 3 |
| Type de Worker (détermine le nombre maximal d’itérations concurrentes) |
ML automatisé uniquement |
Machine virtuelle à mémoire optimisé, de préférence |
| Workers | toujours | 2 ou plus |
| Activer la mise à l’échelle automatique | ML automatisé uniquement |
Décochez la case |
Attendez que le cluster s’exécute avant de continuer.
Ajouter le Kit de développement logiciel (SDK) Azure Machine Learning à Databricks
Une fois que le cluster est en cours d’exécution, créez une bibliothèque pour associer le package du Kit de développement logiciel (SDK) Azure Machine Learning approprié à votre cluster.
Pour utiliser le ML automatisé, passez à Ajouter le kit de développement logiciel SDK Azure Machine Learning avec AutoML.
Cliquez avec le bouton de droite sur le dossier de l’espace de travail actuel dans lequel vous souhaitez stocker la bibliothèque. Sélectionnez Créer>Bibliothèque.
Conseil
Si vous avez une ancienne version du Kit de développement logiciel (SDK), désélectionnez-la des bibliothèques installées du cluster et déplacez-la vers la corbeille. Installez la nouvelle version du SDK et redémarrez le cluster. En cas de problème après le redémarrage, détachez et rattachez votre cluster.
Choisissez l’option suivante (aucune autre installation de Kit de développement logiciel (SDK) n’est prise en charge)
Suppléments du package du Kit de développement logiciel (SDK) Source Nom PyPi Pour Databricks Charger Python Egg ou PyPI azureml-sdk[databricks] Avertissement
Aucun autre supplément de Kit de développement logiciel (SDK) ne peut être installé. Choisissez uniquement l’option [
databricks].- Ne sélectionnez pas Attacher automatiquement à tous les clusters.
- Sélectionnez Attacher en regard du nom de votre cluster.
Surveillez les erreurs jusqu’à ce que l’état soit défini sur Attaché, ce qui peut prendre plusieurs minutes. Si cette étape échoue :
Essayez de redémarrer votre cluster en procédant comme suit :
- Dans le volet gauche, sélectionnez Clusters.
- Sélectionnez le nom de votre cluster dans le tableau.
- Sous l’onglet Bibliothèques, sélectionnez Redémarrer.
Une installation réalisée correctement ressemble à ceci :
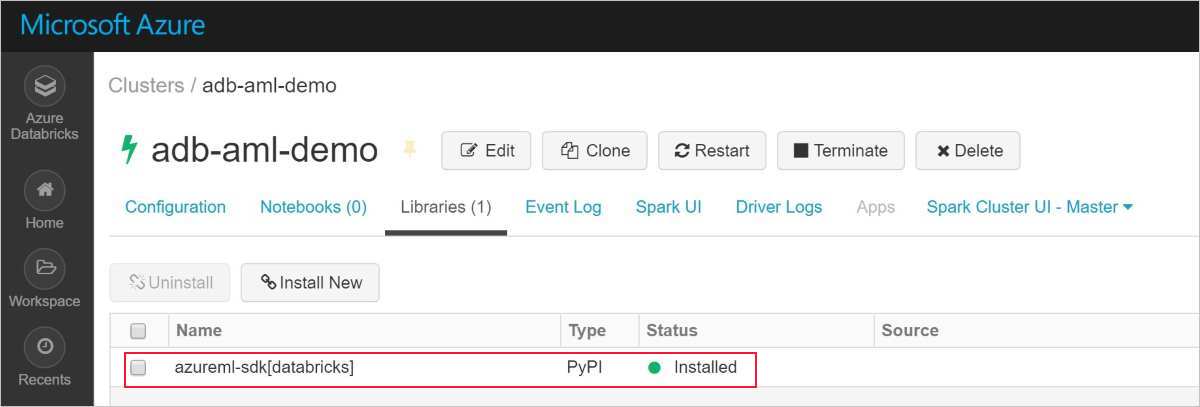
Ajouter le Kit de développement logiciel (SDK) Azure Machine Learning avec AutoML à Databricks
Si le cluster a été créé avec Databricks Runtime 7.3 LTS (non ML), exécutez la commande suivante dans la première cellule de votre notebook pour installer le Kit SDK Azure Machine Learning.
%pip install --upgrade --force-reinstall -r https://aka.ms/automl_linux_requirements.txt
Paramètres de configuration AutoML
Dans la configuration d'AutoML, lorsque vous utilisez Azure Databricks, ajoutez les paramètres suivants :
max_concurrent_iterationsest basé sur le nombre de nœuds Worker dans votre cluster.spark_context=scest basé sur le contexte spark par défaut.
Notebooks ML compatible avec Azure Databricks
Lancez-vous :
Bien que de nombreux exemples de notebooks soient disponibles, seuls ces exemples fonctionnent avec Azure Databricks.
Importez ces exemples directement à partir de votre espace de travail. Voir ci-dessous :
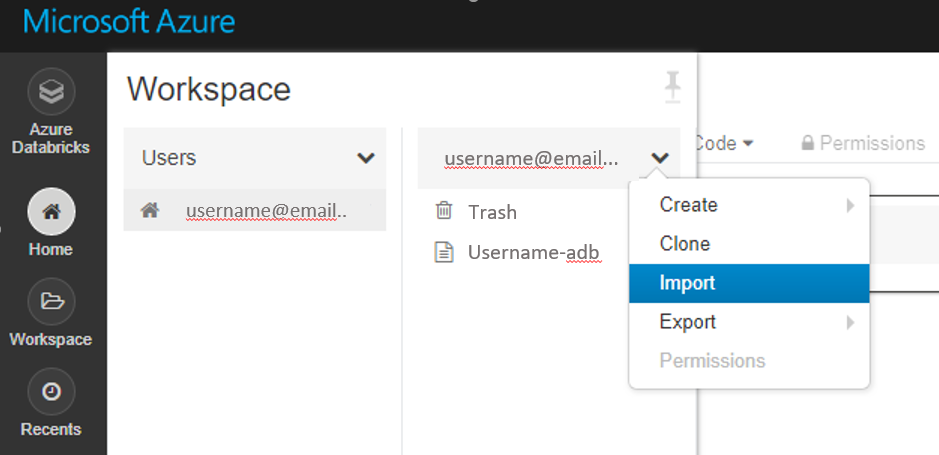
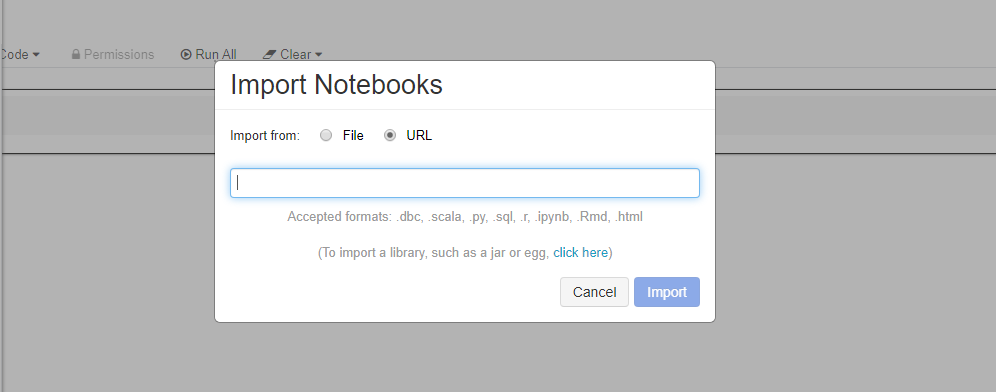
Découvrez comment créer un pipeline avec Databricks en tant que cible de calcul de formation.
Résolution des problèmes
Annuler l’exécution d’un machine learning automatisé Databricks : Si vous utilisez les fonctionnalités de machine learning automatisé sur Azure Databricks et souhaitez annuler une exécution pour en démarrer une nouvelle à des fins d’expérimentation, redémarrez votre cluster Azure Databricks.
Databricks > 10 itérations de Machine Learning automatisé : Dans les paramètres de Machine Learning automatisé, si vous avez plus de 10 itérations, définissez
show_outputsurFalselorsque vous soumettez l’exécution.Widget Databricks pour le Kit de développement logiciel (SDK) Azure Machine Learning et le Machine Learning automatisé : Le widget du Kit de développement logiciel (SDK) Azure Machine Learning n’est pas pris en charge dans un notebook Azure Databricks, car les notebooks ne peuvent pas analyser les widgets HTML. Vous pouvez afficher le widget dans le portail à l’aide de ce code Python dans la cellule du notebook Azure Databricks :
displayHTML("<a href={} target='_blank'>Azure Portal: {}</a>".format(local_run.get_portal_url(), local_run.id))Échec lors de l’installation des packages
L’installation du Kit de développement logiciel (SDK) Azure Machine Learning échoue sur Azure Databricks lorsque plusieurs packages sont installés. Certains packages, comme
psutil, peuvent provoquer des conflits. Pour éviter les erreurs d’installation, installez les packages en bloquant la version des bibliothèques. Ce problème est lié à Azure Databricks et non au Kit de développement logiciel (SDK) Azure Machine Learning. Vous pouvez également rencontrer ce problème avec d’autres bibliothèques. Exemple :psutil cryptography==1.5 pyopenssl==16.0.0 ipython==2.2.0Vous pouvez également utiliser des scripts init si les problèmes d’installation persistent avec les bibliothèques Python. Cette approche n’est pas officiellement prise en charge. Pour plus d’informations, consultez Scripts init à étendue au réseau en cluster.
Erreur d’importation : impossible d’importer le nom
Timedeltaà partir depandas._libs.tslibs: Si cette erreur apparaît lorsque vous utilisez le Machine Learning automatisé, exécutez les deux lignes suivantes dans votre notebook :%sh rm -rf /databricks/python/lib/python3.7/site-packages/pandas-0.23.4.dist-info /databricks/python/lib/python3.7/site-packages/pandas %sh /databricks/python/bin/pip install pandas==0.23.4Erreur d’importation : Aucun module nommé « pandas.core.indexes » : Si cette erreur s’affiche lorsque vous utilisez le machine learning automatisé :
Exécutez cette commande pour installer deux packages dans votre cluster Azure Databricks :
scikit-learn==0.19.1 pandas==0.22.0Détachez, puis réattachez le cluster à votre notebook.
Si ces étapes ne résolvent pas le problème, essayez de redémarrer le cluster.
FailToSendFeather : Si vous voyez une erreur
FailToSendFeatherlors de la lecture de données sur le cluster Azure Databricks, reportez-vous aux solutions suivantes :- Effectuez une mise à niveau du package
azureml-sdk[automl]vers la dernière version. - Ajoutez la version 1.1.8 ou une version supérieure de
azureml-dataprep. - Ajoutez la version 0.11 ou une version supérieure de
pyarrow.
- Effectuez une mise à niveau du package
Étapes suivantes
- Entraînez et déployez un modèle sur Azure Machine Learning avec le jeu de données MNIST.
- Voir les informations de référence sur le Kit de développement logiciel (SDK) Azure Machine Learning pour Python.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour