Entraîner des modèles TensorFlow à grande échelle avec Azure Machine Learning
S’APPLIQUE À :  Kit de développement logiciel (SDK) Python azure-ai-mlv2 (préversion)
Kit de développement logiciel (SDK) Python azure-ai-mlv2 (préversion)
Dans cet article, découvrez comment exécuter vos scripts d’entraînement TensorFlow à grande échelle avec le SDK Python v2 Azure Machine Learning.
L’exemple de code de cet article entraîne un modèle TensorFlow pour classifier des chiffres manuscrits à l’aide d’un réseau neuronal profond (DNN) ; inscrire le modèle ; et le déployer sur un point de terminaison en ligne.
Que vous soyez en train de développer un modèle TensorFlow ou que vous déposez un modèle existant dans le Cloud, vous pouvez utiliser Azure Machine Learning pour effectuer un scale-out des tâches de formation Open source à l’aide des ressources de calcul de Cloud élastique. Vous pouvez créer, déployer, mettre à jour et surveiller des modèles de niveau production avec Azure Machine Learning.
Prérequis
Pour tirer parti de cet article, vous devez :
- Avoir accès à un abonnement Azure. Si vous n’en avez pas encore, créez un compte gratuit.
- Exécutez le code de cet article en utilisant une instance de calcul Azure Machine Learning ou dans votre propre notebook Jupyter.
- Instance de calcul Azure Machine Learning ; ni téléchargement ni installation nécessaires
- Suivez le tutoriel décrit dans l’article Créer des ressources pour démarrer afin de créer un serveur de notebook dédié dans lequel le kit de développement logiciel (SDK) et l’exemple de référentiel sont préchargés.
- Dans le dossier des exemples de Deep Learning sur le serveur de notebooks, recherchez un notebook finalisé et développé en accédant à ce répertoire : v2 > sdk > python > jobs > single-step > tensorflow > train-hyperparameter-tune-deploy-with-tensorflow.
- Votre serveur de notebooks Jupyter
- Instance de calcul Azure Machine Learning ; ni téléchargement ni installation nécessaires
- Téléchargez les fichiers suivants :
- script d’entraînement tf_mnist.py
- script de scoring score.py
- exemple de fichier de requête sample-request.json
Vous trouverez également une version Jupyter Notebook complète de ce guide sur la page des exemples GitHub.
Avant de pouvoir exécuter le code de cet article pour créer un cluster GPU, vous devez demander une augmentation de quota pour votre espace de travail.
Configuration du travail
Cette section configure le travail pour l’entraînement en chargeant les packages Python requis, en se connectant à un espace de travail, en créant une ressource de calcul pour exécuter un travail de commande et en créant un environnement pour exécuter le travail.
Se connecter à l’espace de travail
Vous devez d’abord vous connecter à votre espace de travail Azure Machine Learning. L’espace de travail Azure Machine Learning est la ressource de niveau supérieur du service. Il vous fournit un emplacement centralisé dans lequel utiliser tous les artefacts que vous créez quand vous utilisez Azure Machine Learning.
Nous allons utiliser DefaultAzureCredential pour accéder à l’espace de travail. Ces infos de connexion doivent être capables de gérer la plupart des scénarios d’authentification du kit SDK Azure.
Si DefaultAzureCredential ce n’est pas le cas, consultez azure-identity reference documentation ou Set up authentication pour plus d’informations d’identification disponibles.
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()Si vous préférez utiliser un navigateur pour vous connecter et vous authentifier, vous devez supprimer les commentaires dans le code suivant et l’utiliser à la place.
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
Ensuite, obtenez un descripteur pour l’espace de travail en fournissant votre ID d’abonnement, le nom du groupe de ressources et le nom de l’espace de travail. Pour rechercher ces paramètres :
- Recherchez le nom de votre espace de travail dans le coin supérieur droit de la barre d’outils Azure Machine Learning studio.
- Sélectionnez le nom de votre espace de travail pour afficher votre groupe de ressources et votre ID d’abonnement.
- Copiez les valeurs du groupe de ressources et de l’ID d’abonnement dans le code.
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)Le résultat de l’exécution de ce script est un descripteur d’espace de travail qui vous permet de gérer d’autres ressources et travaux.
Remarque
- La création de
MLClientn’établit pas de connexion du client à l’espace de travail. L’initialisation du client est lente et elle attendra la première fois qu’il aura besoin de faire un appel. Dans cet article, cela se produit lors de la création du calcul.
Créer une ressource de calcul
Azure Machine Learning a besoin d’une ressource de calcul pour exécuter un travail. La ressource peut être constituée de machines à nœud unique ou à plusieurs nœuds avec un système d’exploitation Linux ou Windows, ou d’une structure de calcul spécifique comme Spark.
Dans l’exemple de script suivant, nous approvisionnons un compute cluster Linux. Vous pouvez voir la page Azure Machine Learning pricing pour obtenir la liste complète des tailles et des prix des machines virtuelles. Étant donné que nous avons besoin d’un cluster GPU pour cet exemple, nous allons choisir un modèle STANDARD_NC6 et créer un calcul Azure Machine Learning.
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)Créer un environnement de travail
Pour exécuter un travail Azure Machine Learning, vous avez besoin d’un environnement. Un environnement Azure Machine Learning encapsule les dépendances (telles que le runtime logiciel et les bibliothèques) nécessaires pour exécuter votre script de formation Machine Learning sur votre ressource de calcul. Cet environnement est similaire à un environnement Python sur votre ordinateur local.
Azure Machine Learning vous permet d’utiliser un environnement curé (ou prêt à l’emploi) utile pour des scénarios courants d’apprentissage et d’inférence, ou de créer un environnement personnalisé à l’aide d’une image Docker ou d’une configuration Conda.
Dans cet article, vous réutilisez l’environnement organisé Azure Machine Learning AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu. Vous utilisez la dernière version de cet environnement à l’aide de la directive @latest.
curated_env_name = "AzureML-tensorflow-2.12-cuda11@latest"Configurer et soumettre un travail de formation
Dans cette section, nous commençons par présenter les données pour la formation. Nous verrons ensuite comment exécuter un travail de formation à l’aide d’un script de formation que nous avons fourni. Vous apprenez à générer le travail de formation en configurant la commande d’exécution du script de formation. Ensuite, vous envoyez le travail de formation à exécuter dans Azure Machine Learning.
Obtenir les données d’entraînement
Vous allez utiliser des données de la base de données Modified National Institute of Standards and Technology (MNIST) de chiffres manuscrits. Ces données proviennent du site web de Yan LeCun et stockées dans un compte de stockage Azure.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"Pour plus d’informations sur le jeu de données MNIST, visitez le site web de Yan LeCun.
Préparer le script d’apprentissage
Dans cet article, nous avons fourni le script d’entraînement tf_mnist.py. Dans la pratique, vous devez être capable de prendre n’importe quel script de formation personnalisé et de l’exécuter avec Azure Machine Learning sans avoir à modifier votre code.
Le script de formation fourni réalise les opérations suivantes :
- Il gère le prétraitement des données, fractionnant les données en données de test et d’apprentissage.
- Il effectue l’apprentissage d’un modèle à l’aide des données ; Et
- Il retourne le modèle de sortie.
Pendant l’exécution du pipeline, vous utilisez MLFlow pour consigner les paramètres et les métriques. Pour savoir comment activer le suivi MLFlow, consultez Suivre des expériences et des modèles ML avec MLflow.
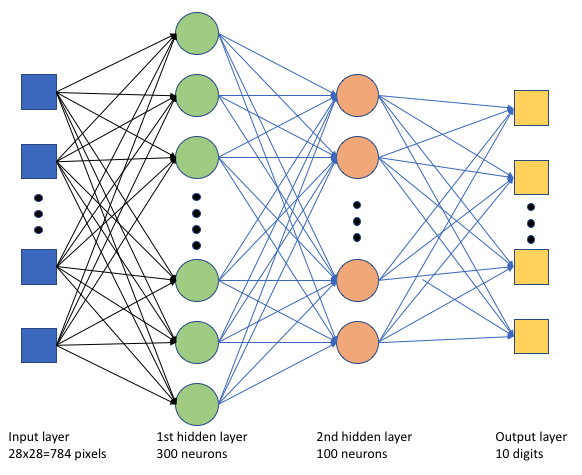
Dans le script d’entraînement tf_mnist.py, nous créons un simple réseau neuronal profond (DNN). Ce réseau neuronal profond contient :
- Une couche d’entrée avec 28 * 28 = 784 neurones. Chaque neurone représente un pixel d’image.
- Deux couches masquées. La première couche masquée a 300 neurones et la deuxième couche masquée a 100 neurones.
- Une couche de sortie avec 10 neurones. Chaque neurone représente une étiquette ciblée comprise entre 0 et 9.
Créer le travail d’entraînement
Maintenant que vous disposez de toutes les ressources nécessaires pour exécuter votre travail, il est temps de le générer à l’aide du SDK Python Azure Machine Learning v2. Pour cet exemple, nous créons un command.
Un command Azure Machine Learning est une ressource qui spécifie tous les détails nécessaires pour exécuter votre code d’entraînement dans le cloud. Ces détails incluent les entrées et sorties, le type de matériel à utiliser, le logiciel à installer et la façon d’exécuter votre code. command contient des informations pour exécuter une seule commande.
Configurer la commande
Vous utilisez le command à usage général pour exécuter le script de formation, puis effectuer vos tâches souhaitées. Créez un objet Command pour spécifier les détails de configuration de votre travail de formation.
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=64,
first_layer_neurons=256,
second_layer_neurons=128,
learning_rate=0.01,
),
compute=gpu_compute_target,
environment=curated_env_name,
code="./src/",
command="python tf_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="tf-dnn-image-classify",
display_name="tensorflow-classify-mnist-digit-images-with-dnn",
)Les entrées de cette commande incluent l’emplacement des données, la taille du lot, le nombre de neurones dans la première et la deuxième couche et le taux d’apprentissage. Notez que nous avons passé le chemin d’accès web directement en tant qu’entrée.
Pour les valeurs de paramètre :
- fournissez le cluster
gpu_compute_target = "gpu-cluster"de calcul que vous avez créé pour exécuter cette commande ; - fournissez l’environnement
curated_env_nameorganisé que vous avez déclaré précédemment ; - configurez l’action de ligne de commande elle-même — dans ce cas, la commande est
python tf_mnist.py. Vous pouvez accéder aux entrées et sorties dans la commande via la notation${{ ... }}; et - configurez les métadonnées telles que le nom d’affichage et le nom de l’expérience ; où une expérience est un conteneur pour toutes les itérations qu’il effectue sur un certain projet. Tous les travaux soumis sous le même nom d’expérience sont listés les uns à côtés des autres dans Azure Machine Learning Studio.
- fournissez le cluster
Dans cet exemple, vous allez utiliser la commande
UserIdentitypour exécuter la commande. L’utilisation d’une identité utilisateur signifie que la commande utilisera votre identité pour exécuter le travail et accéder aux données à partir de l’objet blob.
Envoi du travail
Il est maintenant temps de soumettre le travail à exécuter dans Azure Machine Learning. Cette fois, vous allez utiliser create_or_update sur ml_client.jobs.
ml_client.jobs.create_or_update(job)Une fois terminé, le travail inscrit un modèle dans votre espace de travail (suite à la formation) et génère un lien pour afficher le travail dans Azure Machine Learning Studio.
Avertissement
Azure Machine Learning exécute des scripts d’apprentissage en copiant l’intégralité du répertoire source. Si vous avez des données sensibles que vous ne souhaitez pas charger, utilisez un fichier .ignore ou ne l’incluez pas dans le répertoire source.
Ce qui se passe lors de l’exécution
Quand le travail est exécuté, elle passe par les phases suivantes :
Préparation : une image docker est créée en fonction de l’environnement défini. L’image est chargée dans le registre de conteneurs de l’espace de travail et mise en cache pour des exécutions ultérieures. Les journaux sont également transmis en continu à l’historique des travaux et peuvent être affichés afin de surveiller la progression. Si un environnement organisé est spécifié, l’image mise en cache qui stocke cet environnement organisé est utilisée.
Mise à l’échelle : le cluster tente de monter en puissance si le cluster nécessite plus de nœuds pour l’exécution que la quantité disponible actuellement.
En cours d’exécution : tous les scripts dans le dossier de script src sont chargés dans la cible de calcul, les magasins de données sont montés ou copiés, puis le script est exécuté. Les sorties issues de stdout et du dossier ./logs sont transmises en continu à l’historique des travaux et peuvent être utilisées pour surveiller le travail.
Régler les hyperparamètres du modèle
Maintenant que vous avez vu comment effectuer une simple exécution de formation TensorFlow à l’aide du Kit de développement logiciel (SDK), voyons si vous pouvez améliorer davantage la précision de votre modèle. Vous pouvez paramétrer et optimiser les hyperparamètres de notre modèle à l’aide des fonctionnalités d’Azure sweep Machine Learning.
Pour paramétrer les hyperparamètres du modèle, définissez l’espace de paramètres dans lequel effectuer une recherche pendant la formation. Pour ce faire, remplacez certains des paramètres (batch_size, first_layer_neurons, second_layer_neurons et learning_rate) transmis au travail de formation par des entrées spéciales du package azure.ml.sweep.
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[32, 64, 128]),
first_layer_neurons=Choice(values=[16, 64, 128, 256, 512]),
second_layer_neurons=Choice(values=[16, 64, 256, 512]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)Ensuite, vous configurez le balayage sur le travail de commande, en utilisant certains paramètres spécifiques au balayage, tels que la métrique principale à surveiller et l’algorithme d’échantillonnage à utiliser.
Dans le code suivant, nous utilisons l’échantillonnage aléatoire pour essayer différents jeux de configuration d’hyperparamètres dans une tentative d’optimisation de notre métrique principale, validation_acc.
Nous définissons également une stratégie d’arrêt anticipé : BanditPolicy. Cette stratégie fonctionne en vérifiant le travail toutes les deux itérations. Si la métrique principale, validation_acc, se situe en dehors de la plage de 10 % supérieure, Azure Machine Learning met fin au travail. Cela permet au modèle de continuer à explorer les hyperparamètres qui n’affichent aucune promesse d’aider à atteindre la métrique cible.
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="validation_acc",
goal="Maximize",
max_total_trials=8,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)Maintenant, vous pouvez soumettre ce travail comme avant. Cette fois, vous exécuterez un travail de balayage qui balaye votre travail de train.
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)Vous pouvez surveiller le travail à l’aide du lien d’interface utilisateur studio qui est présenté pendant l’exécution du travail.
Rechercher et inscrire le meilleur modèle
Une fois toutes les exécutions terminées, vous pouvez trouver l’exécution qui a produit le modèle avec la plus grande précision.
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "model"
path="azureml://jobs/{}/outputs/artifacts/paths/outputs/model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="custom_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)Vous pouvez ensuite inscrire ce modèle.
registered_model = ml_client.models.create_or_update(model=model)Déployer le modèle en tant que point de terminaison en ligne
Après avoir inscrit votre modèle, vous pouvez le déployer en tant que point de terminaison en ligne, c’est-à-dire en tant que service web dans le cloud Azure.
Pour déployer un service Machine Learning Service, vous avez généralement besoin des éléments suivants :
- Les ressources de modèle que vous souhaitez déployer. Ces ressources incluent le fichier et les métadonnées du modèle que vous avez déjà inscrits dans votre travail d’entraînement.
- Du code à exécuter en tant que service. Le code exécute le modèle lors d’une requête d’entrée donnée (script d’entrée). Ce script d’entrée reçoit les données envoyées à un service web déployé, puis les passe au modèle. Une fois que le modèle a traité les données, le script retourne la réponse du modèle au client. Le script est propre à votre modèle et doit comprendre les données que le modèle attend et retourne. Lorsque vous utilisez un modèle MLFlow, Azure Machine Learning crée automatiquement ce script pour vous.
Pour plus d’informations sur le déploiement, consultez Déployer et noter un modèle Machine Learning avec un point de terminaison en ligne managé à l’aide du Kit de développement logiciel (SDK) Python v2.
Créer un point de terminaison en ligne
Pour commencer à déployer votre modèle, vous devez créer votre point de terminaison en ligne. Le nom du point de terminaison doit être unique dans toute la région Azure. Dans le cadre de cet article, vous allez créer un nom unique à l’aide d’un UUID (identificateur unique universel).
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "tff-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using TensorFlow",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")Une fois le point de terminaison créé, vous pouvez le récupérer comme suit :
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)Déployer le modèle sur le point de terminaison
Une fois que vous avez créé le point de terminaison, vous pouvez déployer le modèle avec le script d’entrée. Un point de terminaison peut avoir plusieurs déploiements. À l’aide de règles, le point de terminaison peut ensuite diriger le trafic vers ces déploiements.
Dans le code suivant, vous créez un déploiement unique qui gère 100 % du trafic entrant. Nous utilisons un nom de couleur arbitraire (tff-blue) pour le déploiement. Vous pouvez également utiliser n’importe quel autre nom tel que tff-green ou tff-red pour le déploiement. Le code permettant de déployer le modèle sur le point de terminaison effectue les opérations suivantes :
- déploie la meilleure version du modèle que vous avez inscrit précédemment ;
- évalue le modèle, à l’aide du fichier
score.py; et - utilise le même environnement curé (que vous avez déclaré précédemment) pour effectuer une inférence.
model = registered_model
from azure.ai.ml.entities import CodeConfiguration
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="tff-blue",
endpoint_name=online_endpoint_name,
model=model,
code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
environment=curated_env_name,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()Notes
Attendez-vous à ce que ce déploiement prenne un peu de temps.
Tester le déploiement avec un exemple de requête
Après avoir déployé le modèle sur le point de terminaison, vous pouvez prédire la sortie du modèle déployé à l’aide de la méthode invoke sur le point de terminaison. Pour exécuter l’inférence, utilisez l’exemple de fichier de requête sample-request.json à partir du dossier de requête.
# # predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request/sample-request.json",
deployment_name="tff-blue",
)Vous pouvez ensuite afficher les prédictions retournées et tracez-les avec les images d’entrée. Utilisez une police rouge et une image inverse (blanc sur fond noir) pour mettre en évidence les exemples mal classifiés.
# compare actual value vs. the predicted values:
import matplotlib.pyplot as plt
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()Notes
La précision du modèle étant élevée, il peut être nécessaire d’exécuter la cellule plusieurs fois avant de voir un exemple mal classifié.
Nettoyer les ressources
Si vous n’utilisez pas le point de terminaison, supprimez-le pour arrêter d’utiliser la ressource. Vérifiez qu’aucun autre déploiement n’utilise le point de terminaison avant de le supprimer.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)Notes
Attendez-vous à ce que ce nettoyage prenne un peu de temps.
Étapes suivantes
Dans cet article, vous avez entraîné et inscrit un modèle TensorFlow. Vous avez également déployé le modèle sur un point de terminaison en ligne. Consultez ces autres articles pour en savoir plus sur Azure Machine Learning.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour