Tutoriel : Prévoir la demande avec un machine learning automatisé sans code dans le studio Azure Machine Learning
Découvrez comment créer un modèle de prévision de série chronologique sans écrire une seule ligne de code, en utilisant le machine learning automatisé dans Azure Machine Learning Studio. Ce modèle prédit la demande de location pour un service de partage de vélos.
Dans ce tutoriel, vous n’écrivez pas de code. Vous utilisez l’interface du studio pour effectuer la formation. Vous apprenez à effectuer les tâches suivantes :
- Créer et charger un jeu de données
- Configurer et exécuter une expérience de ML automatisé
- Indiquez les paramètres de prévision.
- Explorer les résultats de l’expérience
- Déployer le meilleur modèle
Essayez également le machine learning automatisé pour ces autres types de modèles :
- Pour obtenir un exemple sans code de modèle de classification, consultez Tutoriel : Créer un modèle de classification avec le machine learning (ML) automatisé dans Azure Machine Learning.
- Pour obtenir un premier exemple de code d’un modèle de détection d’objet, consultez le Tutoriel : Effectuer l’apprentissage d’un modèle de détection d’objet avec AutoML et Python.
Prérequis
Un espace de travail Azure Machine Learning. Consultez Créer des ressources d’espace de travail.
Télécharger le fichier de données bike-no.csv
Se connecter à Studio
Pour ce tutoriel, vous allez créer l’exécution de votre expérience de ML automatisé dans Azure Machine Learning Studio, une interface web centralisée qui comprend des outils de machine learning permettant de mettre en œuvre des scénarios de science des données pour des utilisateurs de science des données de tous niveaux de compétence. Ce studio n’est pas pris en charge par les navigateurs Internet Explorer.
Connectez-vous au studio Azure Machine Learning.
Sélectionnez votre abonnement et l’espace de travail que vous avez créé.
Sélectionnez Prise en main.
Dans le volet gauche, sélectionnez Automated ML (ML automatisé) sous la section Author (Créer).
Sélectionnez +Nouvelle tâche de ML automatisé.
Créer et charger un jeu de données
Avant de configurer votre expérience, chargez votre fichier de données dans votre espace de travail sous la forme d’un jeu de données Azure Machine Learning. De cette façon, vous pouvez vérifier que la mise en forme de vos données convient à votre expérience.
Dans le formulaire Sélectionner un jeu de données, sélectionnez À partir de fichiers locaux dans la liste déroulante +Créer un jeu de données.
Dans le formulaire Informations de base, donnez un nom unique à votre jeu de données et indiquez éventuellement une description. Le type de jeu de données par défaut est Tabulaire dans la mesure où le ML automatisé dans Azure Machine Learning Studio ne prend actuellement en charge que les jeux de données tabulaires.
Sélectionnez Suivant en bas à gauche.
Dans le formulaire Sélection d’un magasin de données et de fichiers, sélectionnez le magasin de données par défaut qui a été automatiquement configuré durant la création de votre espace de travail : workspaceblobstore (Stockage Blob Azure) . Il s’agit de l’emplacement de stockage où vous chargerez votre fichier de données.
Sélectionnez Charger des fichiers dans le menu déroulant Charger.
Choisissez le fichier bike-no.csv sur votre ordinateur local. Il s’agit du fichier que vous avez téléchargé en tant que prérequis.
Sélectionnez Suivant.
Une fois le chargement terminé, le formulaire Settings and preview (Paramètres et aperçu) est prérenseigné en fonction du type de fichier.
Vérifiez que le formulaire Settings and preview est renseigné comme ci-dessous, puis sélectionnez Next (Suivant).
Champ Description Valeur pour le tutoriel Format de fichier Définit la disposition et le type des données stockées dans un fichier. Delimited Délimiteur Un ou plusieurs caractères utilisés pour spécifier la limite entre des régions indépendantes et séparées dans du texte brut ou d’autres flux de données. Comma Encodage Identifie la table de schéma bits/caractères à utiliser pour lire votre jeu de données. UTF-8 En-têtes de colonne Indique la façon dont les éventuels en-têtes du jeu de données sont traités. Seul le premier fichier comporte des en-têtes Ignorer les lignes Indique le nombre éventuel de lignes ignorées dans le jeu de données. None Le formulaire Schema permet de configurer davantage vos données pour cette expérience.
Pour cet exemple, choisissez d’ignorer les colonnes casual et registered. Ces colonnes étant une décomposition de la colonne cnt, nous ne les incluons pas.
Dans cet exemple, conservez également les valeurs par défaut pour Propriétés et Type.
Sélectionnez Suivant.
Dans le formulaire Confirmer les détails, vérifiez que les informations correspondent à celles qui ont été précédemment renseignées sur les formulaires Informations de base et Paramètres et aperçu.
Sélectionnez Créer pour terminer la création de votre jeu de données.
Sélectionnez votre jeu de données une fois qu’il apparaît dans la liste.
Sélectionnez Suivant.
Configurer le travail
Une fois vos données chargées et configurées, configurez votre cible de calcul à distance et sélectionnez dans vos données la colonne que vous souhaitez prédire.
- Remplissez le formulaire Configurer la tâche comme suit :
Entrez un nom d’expérience :
automl-bikeshareSélectionnez cnt comme colonne cible, ce que vous souhaitez prédire. Cette colonne indique le nombre total de locations de vélos en libre-service.
Sélectionnez Cluster de calcul comme type de calcul.
Sélectionnez +Nouveau pour configurer votre cible de calcul. Le ML automatisé prend uniquement en charge la capacité de calcul Azure Machine Learning.
Remplissez le formulaire Sélectionner une machine virtuelle pour configurer votre calcul.
Champ Description Valeur pour le tutoriel Niveau de machine virtuelle Sélectionnez la priorité que doit avoir votre expérience Dédié Type de machine virtuelle Sélectionnez le type de machine virtuelle pour votre calcul. Processeur (CPU) Taille de la machine virtuelle Sélectionnez la taille de la machine virtuelle pour votre calcul. La liste des tailles recommandées qui est fournie dépend de vos données et du type de l’expérience. Standard_DS12_V2 Sélectionnez Suivant pour renseigner le formulaire Configurer les paramètres.
Champ Description Valeur pour le tutoriel Nom du calcul Nom unique qui identifie votre contexte de calcul. bike-compute Nombre minimal/maximal de nœuds Pour profiler des données, vous devez spécifier un ou plusieurs nœuds. Nœuds min. : 1
Nœuds max. : 6Secondes d’inactivité avant le scale-down Durée d’inactivité avant que le cluster ne fasse l’objet d’un scale-down vers le nombre de nœuds minimal. 120 (par défaut) Paramètres avancés Paramètres pour configurer et autoriser un réseau virtuel pour votre expérience. None Sélectionnez Créer pour accéder à la cible de calcul.
Quelques minutes sont nécessaires pour achever l’opération.
Une fois la création terminée, sélectionnez votre nouvelle cible de calcul dans la liste déroulante.
Sélectionnez Suivant.
Sélectionner les paramètres de prévision
Terminez la configuration de votre expérience de ML automatisé en spécifiant le type de tâche de Machine Learning et les paramètres de configuration.
Dans le formulaire Type de tâche et paramètres, sélectionnez Prévisions de série chronologique comme type de tâche de Machine Learning.
Sélectionnez date comme Colonne Heure et laissez Identificateurs de séries chronologiques vide.
La Fréquence correspond à la fréquence de collecte de vos données historiques. Laissez Détection automatique sélectionné.
L’horizon de prévision est la période dans le futur pour laquelle vous voulez faire des prédictions. Décochez Détection automatique et tapez 14 dans le champ.
Sélectionnez Afficher des paramètres de configuration supplémentaires et renseignez les champs comme suit. Ces paramètres permettent de mieux contrôler le travail d’entraînement, et de spécifier les paramètres de votre prévision. Sinon, les valeurs par défaut sont appliquées en fonction de la sélection de l’expérience et des données.
Configurations supplémentaires Description Valeur pour le tutoriel Métrique principale Métrique d’évaluation selon laquelle l’algorithme de Machine Learning sera mesuré. Erreur quadratique moyenne normalisée Expliquer le meilleur modèle Montre automatiquement l’explicabilité sur le meilleur modèle créé par le ML automatisé. Activer Algorithmes bloqués Algorithmes que vous souhaitez exclure du travail de formation Arbres aléatoires extrêmes Paramètres de prévision supplémentaires Ces paramètres contribuent à améliorer la justesse de votre modèle.
Décalages de cibles de prévision : antériorité avec laquelle vous voulez construire les décalages d’une variable cible
Fenêtre dynamique cible : spécifie la taille de la fenêtre dynamique sur laquelle des caractéristiques telles que max, min et somme sont générées.
Décalages de cibles de prévision : aucun
Taille de la fenêtre dynamique cible : aucunCritère de sortie Lorsqu’une condition est remplie, la tâche d’entraînement est arrêtée. Durée du travail de formation (heures) : 3
Seuil de score de métrique : AucunAccès concurrentiel Nombre maximal d’itérations parallèles exécutées par itération Nombre maximal d’itérations simultanées : 6 Sélectionnez Enregistrer.
Sélectionnez Suivant.
Dans le formulaire [Facultatif] Valider et tester,
- Sélectionnez la validation croisée k-fold comme Type de validation.
- Sélectionnez 5 comme Nombre de validations croisées.
Exécuter une expérience
Pour exécuter votre expérience, sélectionnez Terminer. L’écran Détails de la tâche s’ouvre avec État de la tâche en haut à côté du numéro de la tâche. Cet état est mis à jour à mesure que l’expérience progresse. Les notifications s’affichent également en haut à droite de Studio pour vous informer de l’état de votre expérience.
Important
La préparation nécessaire à la tâche de l’expérience prend 10 à 15 minutes.
Une fois que l’exécution a commencé, 2-3 minutes supplémentaires sont nécessaires pour chaque itération.
Dans un environnement de production, ce processus prend du temps. Pendant que vous attendez, nous vous suggérons de commencer à explorer les algorithmes testés sous l’onglet Modèles à mesure qu’ils se terminent.
Explorer les modèles
Accédez à l’onglet Modèles pour voir les algorithmes (modèles) testés. Par défaut, les modèles sont classés par score de métrique à mesure qu’ils se terminent. Pour ce tutoriel, le modèle qui obtient le score le plus élevé d’après la métrique Erreur quadratique moyenne normalisée choisie figure en haut de la liste.
En attendant que toutes les modèles d’expérience se terminent, sélectionnez le Nom de l’algorithme d’un modèle terminé pour explorer ses performances en détail.
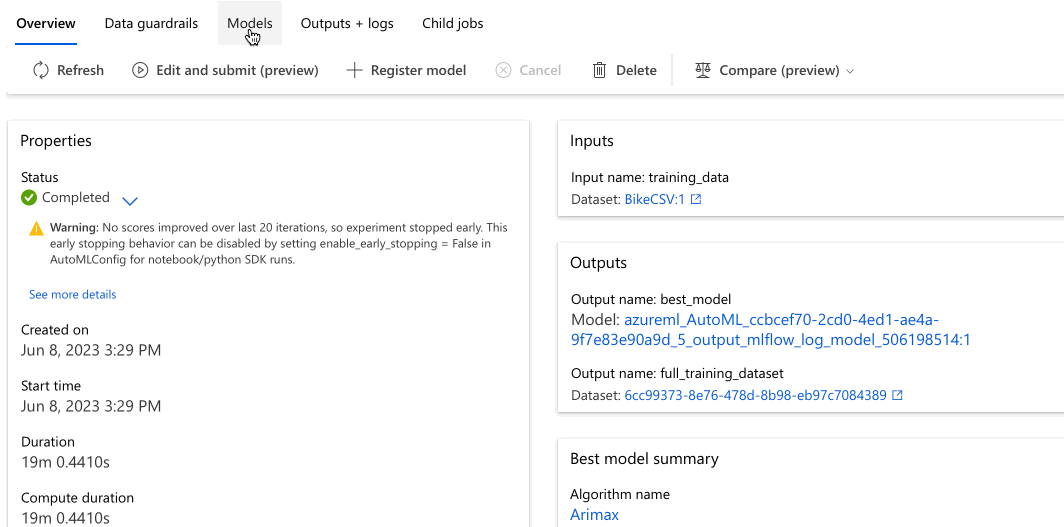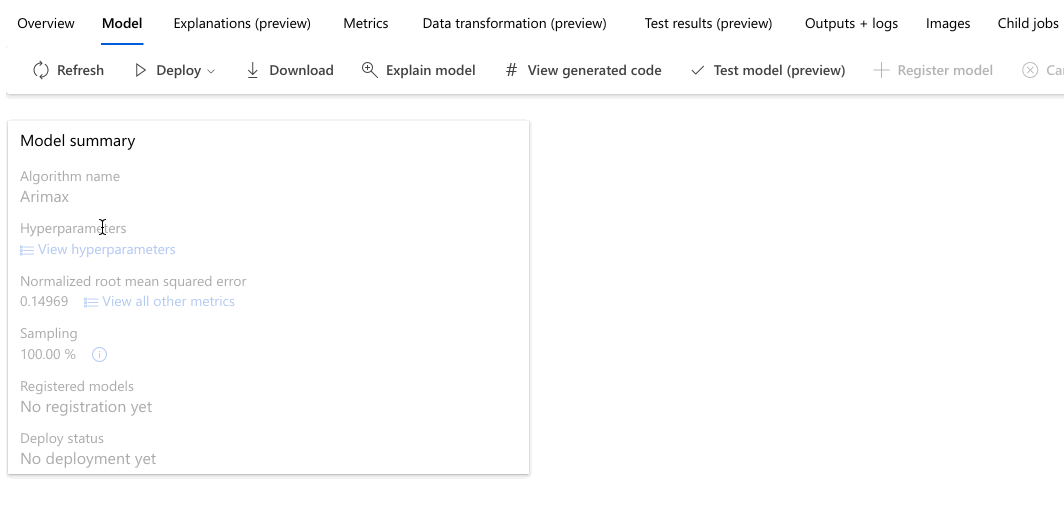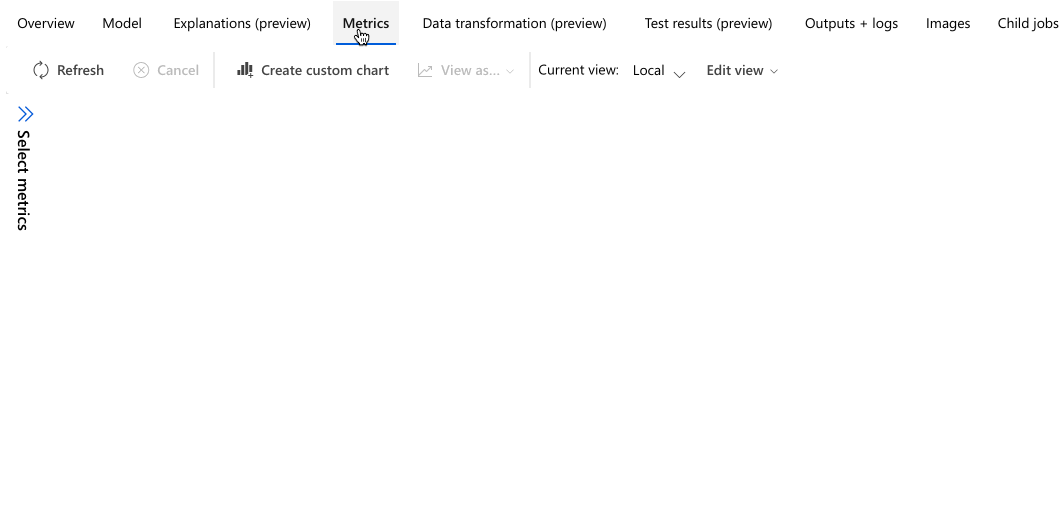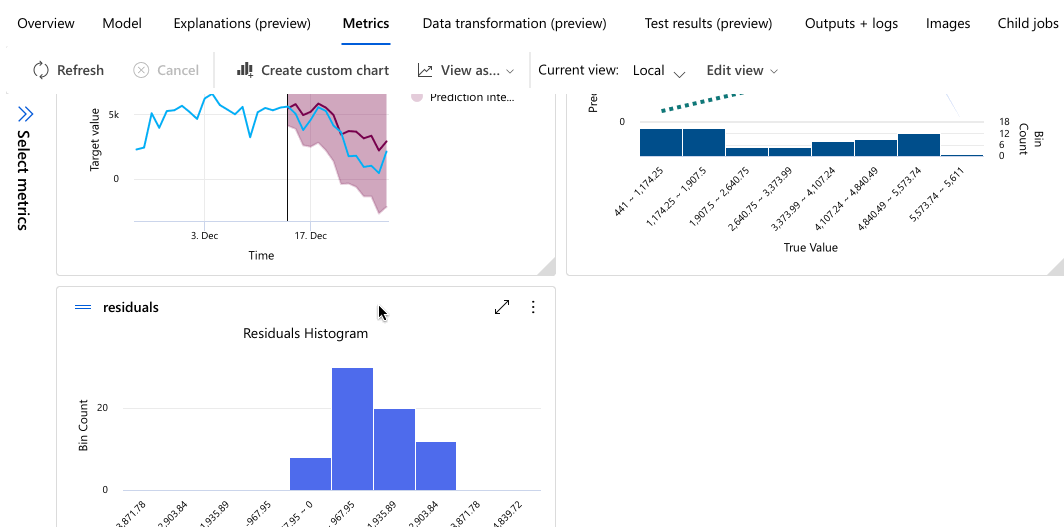
L’exemple suivant permet de sélectionner un modèle dans la liste des modèles créés par le travail. Sélectionnez ensuite la Vue d’ensemble et l’onglet Métriques pour afficher les propriétés, les métriques et les graphiques de performances du modèle sélectionné.
Déployer le modèle
Dans Azure Machine Learning Studio, le Machine Learning automatisé vous permet de déployer le meilleur modèle en tant que service web en quelques étapes. Le déploiement consiste à intégrer le modèle pour qu’il puisse prédire de nouvelles données et identifier les domaines potentiels d’opportunités.
Pour cette expérience, le déploiement sur un service web signifie que la société de vélos en libre-service dispose désormais d’une solution web itérative et scalable pour prévoir la demande de location.
Une fois la tâche terminée, revenez à la page de tâche du parent en sélectionnant Tâche 1 en haut de votre écran.
Dans la section Récapitulatif du meilleur modèle, le meilleur modèle dans le contexte de cette expérience est sélectionné en fonction de la métrique Erreur quadratique moyenne normalisée.
Nous déployons ce modèle, mais nous vous informons que le déploiement prend 20 minutes environ. Le processus de déploiement comporte plusieurs étapes, notamment l’inscription du modèle, la génération de ressources et leur configuration pour le service web.
Sélectionnez le meilleur modèle pour ouvrir la page propre au modèle.
Sélectionnez le bouton Déployer situé dans la partie supérieure gauche de l’écran.
Renseignez le volet Déployer un modèle de la façon suivante :
Champ Valeur Nom du déploiement bikeshare-deploy Description du déploiement déploiement de la demande de vélos en libre-service Type de capacité de calcul Sélectionnez une instance de calcul Azure (ACI) Activer l’authentification Désactivez. Utiliser les ressources d’un déploiement personnalisé Désactivez. La désactivation permet de générer automatiquement le fichier de pilote par défaut (script de scoring) et le fichier d’environnement. Pour cet exemple, nous utilisons les valeurs par défaut fournies dans le menu Avancé.
Sélectionnez Déployer.
Un message vert de réussite apparaît en haut de l’écran Tâche, indiquant que le déploiement a été correctement démarré. Vous pouvez voir la progression du déploiement dans le volet Récapitulatif du modèle sous État du déploiement.
Une fois le déploiement terminé, vous disposez d’un service web opérationnel pour générer des prédictions.
Passez aux Étapes suivantes pour en savoir plus sur la consommation de votre nouveau service web et tester vos prédictions à l’aide de la prise en charge d’Azure Machine Learning intégrée à Power BI.
Nettoyer les ressources
Les fichiers de déploiement sont plus volumineux que les fichiers de données et d’expérimentation. Le coût de leur stockage est donc plus élevé. Supprimez uniquement les fichiers de déploiement pour réduire les coûts associés à votre compte, ou si vous souhaitez conserver vos fichiers d’expérience et d’espace de travail. Dans le cas contraire, supprimez l’intégralité du groupe de ressources, si vous n’envisagez pas d’utiliser les fichiers.
Supprimer l’instance de déploiement
Supprimez uniquement l’instance de déploiement d’Azure Machine Learning Studio si vous souhaitez conserver le groupe de ressources et l’espace de travail pour d’autres tutoriels et à des fins d’exploration.
Accédez à Azure Machine Learning Studio. Accédez à votre espace de travail et, à gauche dans le volet Ressources, sélectionnez Points de terminaison.
Sélectionnez le déploiement à supprimer et sélectionnez Supprimer.
Sélectionnez Continuer.
Supprimer le groupe de ressources
Important
Les ressources que vous avez créées peuvent être utilisées comme prérequis pour d’autres tutoriels d’Azure Machine Learning et des articles de procédure.
Si vous n’avez pas l’intention d’utiliser les ressources que vous avez créées, supprimez-les pour éviter des frais :
Dans la zone de recherche du Portail Azure, saisissez Groupes de ressources, puis sélectionnez-le dans les résultats.
Dans la liste, sélectionnez le groupe de ressources créé.
Dans la page Vue d’ensemble, sélectionnez Supprimer le groupe de ressources.
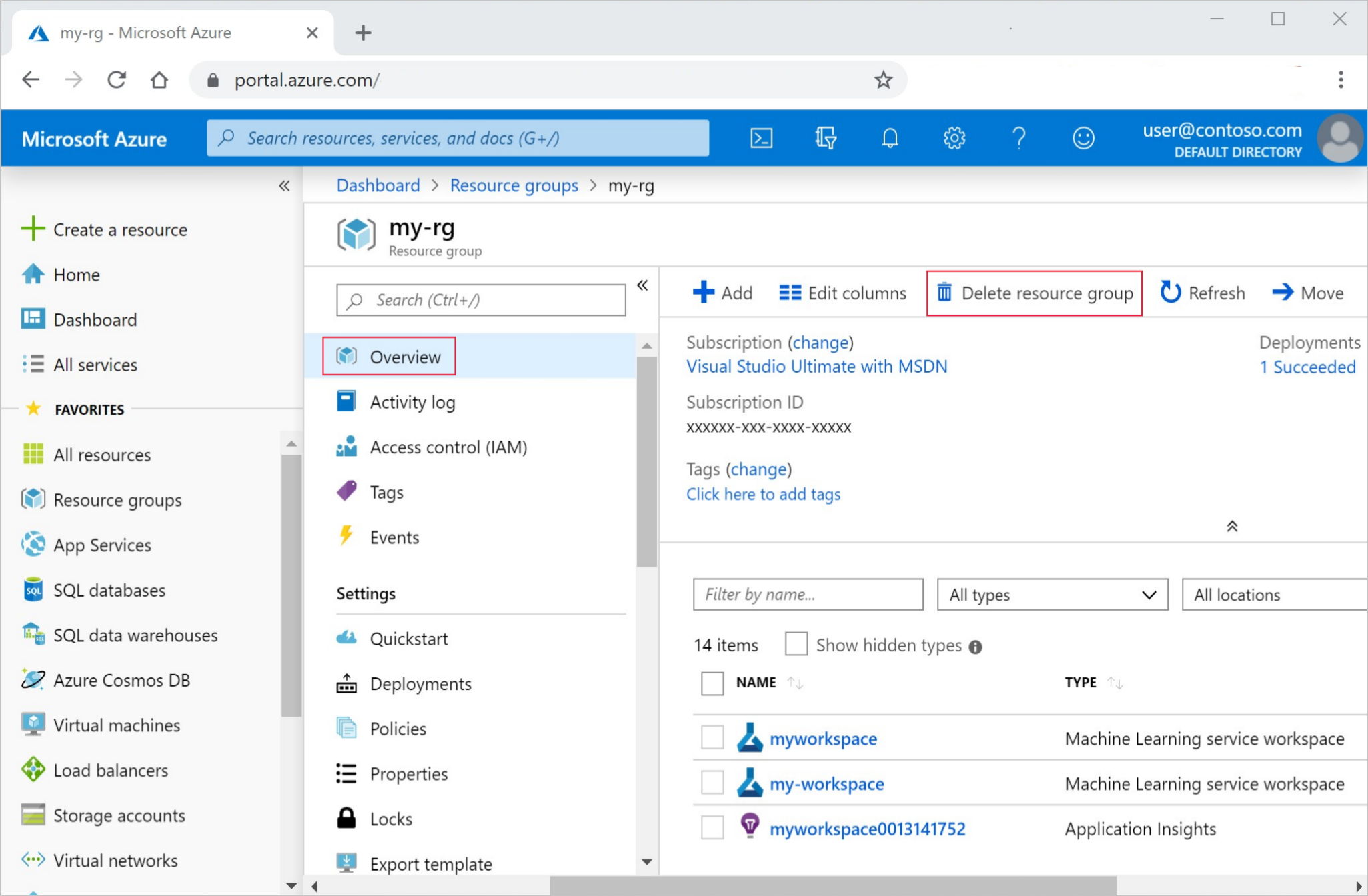
Entrez le nom du groupe de ressources. Puis sélectionnez Supprimer.
Étapes suivantes
Dans ce tutoriel, vous avez utilisé le ML automatisé dans Azure Machine Learning Studio pour créer et déployer un modèle de prévision de série chronologique qui prédit la demande de location de vélos en libre-service.
- En savoir plus sur le Machine Learning automatisé.
- Pour plus d’informations sur les métriques et les graphiques de classification, consultez l’article Comprendre les résultats du Machine Learning automatisé.
- Pour plus d’informations, consultez le FAQ sur la prévision.
Remarque
Ce jeu de données de vélos en libre-service a été modifié pour les besoins de ce tutoriel. Ce jeu de données, mis à disposition dans le cadre d’un concours Kaggle, a été initialement proposé par Capital Bikeshare. Il est également accessible dans la base de données de Machine Learning de l’UCI.
Source : Fanaee-T, Hadi et Gama, Joao, Event labeling combining ensemble detectors and background knowledge, Progress in Artificial Intelligence (2013) : p. 1-15, Springer Berlin Heidelberg.