Basculement de la continuité d’activité et reprise d’activité
Pour optimiser votre temps de fonctionnement, soyez prévoyant pour assurer la continuité de l’activité et faire face à une situation de récupération d’urgence avec Azure Machine Learning.
Microsoft s’efforce de faire en sorte que les services Azure soient toujours disponibles. Toutefois, des interruptions de service non planifiées peuvent se produire. Nous vous recommandons de mettre en place un plan de récupération d’urgence pour gérer les interruptions de service régionales. Dans cet article, vous allez apprendre à :
- Planifier un déploiement à plusieurs régions d’Azure Machine Learning et des ressources associées.
- Optimisez les chances de récupérer les journaux, les blocs-notes, les images Docker et d’autres métadonnées.
- Concevoir pour la haute disponibilité de votre solution.
- Initier un basculement vers une autre région.
Important
Azure Machine Learning lui-même ne fournit pas de basculement automatique ou de récupération d’urgence. La sauvegarde et la restauration des métadonnées de l’espace de travail telles que l’historique des exécutions n’est pas disponible.
Si vous avez accidentellement supprimé votre espace de travail ou les composants correspondants, cet article vous fournit également les options de récupération actuellement prises en charge.
Comprendre les services Azure pour Azure Machine Learning
Azure Machine Learning dépend de plusieurs services Azure. Certains de ces services sont configurés dans votre abonnement (client). Vous êtes responsable de la configuration de la haute disponibilité de ces services. D’autres services sont créés dans un abonnement Microsoft et sont gérés par Microsoft.
Les services Azure incluent :
Infrastructure Azure Machine Learning : un environnement géré par Microsoft pour un espace de travail Azure Machine Learning.
Ressources associées : Ressources approvisionnées dans votre abonnement lors de la création d’un espace de travail Azure Machine Learning. Ces ressources incluent le Stockage Azure, Azure Key Vault, Azure Container Registry et Application Insights.
- Le stockage par défaut contient des données telles que le modèle, les données du journal d’apprentissage et le jeu de données.
- Key Vault possède des informations d’identification pour le Stockage Azure, Container Registry et les banques de données.
- Container Registry dispose d’une image Docker pour les environnements de formation et d’inférence.
- Application Insights est destiné à l’analyse d’Azure Machine Learning.
Ressources de calcul : Ressources que vous créez après le déploiement de l’espace de travail. Par exemple, vous pouvez créer une instance de calcul ou un cluster de calcul pour effectuer l'apprentissage d’un modèle Machine Learning.
- Instance de calcul et cluster de calcul : environnements de développement de modèles gérés par Microsoft.
- Autres ressources : Il s’agit des ressources de calcul Microsoft que vous pouvez joindre à Azure Machine Learning, comme Azure Kubernetes Service (AKS), Azure Databricks, Azure Container Instances et Azure HDInsight. Vous êtes responsable de la configuration des paramètres de haute disponibilité pour ces ressources.
Autres magasins de données : Azure Machine Learning peut monter d’autres magasins de données, comme le stockage Azure, Azure Data Lake Storage et Azure SQL Database pour les données d’apprentissage. Ces banques de données sont configurées dans votre abonnement. Vous êtes responsable de la configuration de leurs paramètres de haute disponibilité.
Le tableau suivant montre que les services Azure gérés par Microsoft et ceux qui sont gérés par vous. Il indique également les services qui sont hautement disponibles par défaut.
| Service | Géré par | Haute disponibilité par défaut |
|---|---|---|
| Infrastructure Azure Machine Learning | Microsoft | |
| Ressources associées | ||
| Stockage Azure | Vous | |
| Key Vault | Vous | ✓ |
| Container Registry | Vous | |
| Application Insights | Vous | N/D |
| Ressources de calcul | ||
| Instance de calcul | Microsoft | |
| Cluster de calcul | Microsoft | |
| Autres ressources de calcul telles que AKS, Azure Databricks, Container Instances, HDInsight |
Vous | |
| Autres magasins de données, comme le Stockage Azure, SQL Database, Azure Database pour PostgreSQL, Azure Database pour MySQL, système de fichiers Azure Databricks |
Vous |
Le reste de cet article décrit les actions que vous devez effectuer pour rendre chacun de ces services hautement disponible.
Planifier le déploiement multi-région
Un déploiement multi-région repose sur la création d’Azure Machine Learning et d’autres ressources (infrastructure) dans deux régions Azure. Si une panne régionale se produit, vous pouvez basculer vers l’autre région. Lors de la planification du déploiement de vos ressources, tenez compte des éléments suivants :
Disponibilité régionale : utilisez des régions proches de vos utilisateurs. Pour vérifier la disponibilité régionale d’Azure Machine Learning, consultez Produits Azure par région.
Régions jumelées Azure : Les régions appairées coordonnent les mises à jour de la plateforme et hiérarchisent les efforts de récupération si nécessaire. Pour plus d’informations, consultez Régions jumelées Azure.
Disponibilité du service : Déterminez si les ressources utilisées par votre solution doivent être de type chaud/chaud, chaud/tiède ou chaud/froid.
- Chaud/chaud : Les deux régions sont actives en même temps, avec une région prête à être utilisée immédiatement.
- Chaud/tiède : La région primaire est active, la région secondaire a les ressources critiques (par exemple des modèles déployés) prêtes à démarrer. Les ressources non critiques doivent être déployées manuellement dans la région secondaire.
- Chaud/froid : La région primaire est active, la région secondaire a Azure Machine Learning et d’autres ressources déployées, ainsi que les données nécessaires. Les ressources telles que les modèles, les déploiements de modèle ou les pipelines doivent être déployées manuellement.
Conseil
Selon les besoins de votre entreprise, vous pouvez décider de traiter différemment les différentes ressources Azure Machine Learning. Par exemple, vous souhaiterez peut-être utiliser chaud/chaud pour les modèles déployés (inférence) et chaud/froid pour les expériences (apprentissage).
Azure Machine Learning s’appuie sur d’autres services. Certains services peuvent être configurés pour être répliqués dans d’autres régions. Pour d’autres, vous devez créer manuellement dans plusieurs régions. Le tableau suivant indique une liste de services, qui est responsable de la réplication, ainsi qu’une vue d’ensemble de la configuration :
| Service Azure | Géo-répliqué par | Configuration |
|---|---|---|
| Espace de travail Machine Learning | Vous | Créez un espace de travail dans les régions sélectionnées. |
| Capacité de calcul Machine Learning | Vous | Créez les ressources de calcul dans les régions sélectionnées. Pour les ressources de calcul pouvant être mises à l’échelle de manière dynamique, assurez-vous que les deux régions fournissent un quota de calcul suffisant pour vos besoins. |
| Key Vault | Microsoft | Utilisez la même instance Key Vault avec les mêmes espace de travail et ressources Azure Machine Learning dans les deux régions. Key Vault bascule automatiquement vers une région secondaire. Pour plus d’informations, consultez Disponibilité et redondance d’Azure Key Vault. |
| Container Registry | Microsoft | Configurez l’instance Container Registry pour la géoréplication des registres dans la région jumelée pour Azure Machine Learning. Utilisez la même instance pour les deux instances de l’espace de travail. Pour plus d’informations, consultez Géoréplication dans Azure Container Registry. |
| Compte de stockage | Vous | Azure Machine Learning ne prend pas en charge le basculement de compte de stockage par défaut à l’aide du stockage géo-redondant (GRS), du stockage géo-redondant interzone (GZRS), du stockage géo-redondant avec accès en lecture (RA-GRS) ou du stockage géo-redondant interzone avec accès en lecture (RA-GZRS). Créez un compte de stockage distinct pour le stockage par défaut de chaque espace de travail. Créer des comptes de stockage ou des services distincts pour les autres stockages de données. Pour plus d’informations, consultez Redondance de Stockage Azure. |
| Application Insights | Vous | Créez Application Insights pour l’espace de travail dans les deux régions. Pour ajuster la période de rétention des données et les détails, consultez Collecte, rétention et stockage des données dans Application Insights. |
Pour activer la récupération et le redémarrage rapides dans la région secondaire, nous vous recommandons les pratiques de développement suivantes :
- Utilisez des modèles Azure Resource Manager. Les modèles sont de type « Infrastructure en tant que code » et vous permettent de déployer rapidement des services dans les deux régions.
- Pour éviter la dérive entre les deux régions, mettez à jour vos pipelines d’intégration et de déploiement continu afin de les déployer dans les deux régions.
- Lors de l’automatisation des déploiements, incluez la configuration des ressources de calcul attachées à l’espace de travail, comme le service Azure Kubernetes.
- Créez des attributions de rôles pour les utilisateurs dans les deux régions.
- Créez des ressources réseau telles que des réseaux virtuels Azure et des points de terminaison privés pour les deux régions. Assurez-vous que les utilisateurs ont accès aux deux environnements réseau. Par exemple, les configurations VPN et DNS pour les deux réseaux virtuels.
Services de calcul et de données
Selon vos besoins, vous pouvez avoir d’autres services de calcul ou de données utilisés par Azure Machine Learning. Par exemple, vous pouvez utiliser Azure Kubernetes Services ou Azure SQL Database. Utilisez les informations suivantes pour savoir comment configurer ces services pour la haute disponibilité.
Ressources de calcul
- Azure Kubernetes Service : Consultez Bonnes pratiques pour la continuité d’activité et la reprise d’activité dans AKS (Azure Kubernetes Services) et Créer un cluster Azure Kubernetes Service (AKS) qui utilise des zones de disponibilité. Si le cluster AKS a été créé à l’aide de Studio Azure Machine Learning, du kit de développement logiciel (SDK) ou de l’interface CLI, la haute disponibilité inter-régions n’est pas prise en charge.
- Azure Databricks : Consultez Récupération d’urgence régionale pour les clusters Azure Databricks.
- Container Instances : Un orchestrateur est responsable du basculement. Consultez Azure Container Instances et les orchestrateurs de conteneurs.
- HDInsight : Consultez Services de haute disponibilité pris en charge par Azure HDInsight.
Services de données
- Conteneur d’objets blob Azure/Azure Files/Data Lake Storage Gen2 : consultez Redondance de Stockage Azure.
- Data Lake Storage Gen1 : Consultez guide pour la haute disponibilité et récupération d'urgence pour Data Lake Storage Gen1.
- SQL Database : Consultez Haute disponibilité pour Azure SQL Database et SQL Managed Instance.
- Azure Database pour PostgreSQL : Consultez Concepts de haute disponibilité dans Azure Database pour PostgreSQL (serveur unique).
- Azure Database pour MySQL : Consultez Comprendre la continuité d’activité dans Azure Database pour MySQL.
- Système de fichiers Azure Databricks : Consultez Récupération d’urgence régionale pour les clusters Azure Databricks.
Conseil
Si vous fournissez votre propre clé gérée par le client pour déployer un espace de travail Azure Machine Learning, Azure Cosmos DB est également configuré dans votre abonnement. Dans ce cas, vous êtes responsable de la configuration de ses paramètres de haute disponibilité. Consultez Haute disponibilité avec Azure Cosmos DB.
Concevoir pour la haute disponibilité
Déployer des composants critiques dans plusieurs régions
Déterminez le niveau de continuité de l’activité que vous recherchez. Le niveau peut varier entre les composants de votre solution. Par exemple, vous pouvez avoir besoin d’une configuration chaud/chaud pour les pipelines de production ou les déploiements de modèle, et chaud/froid pour l’expérimentation.
Gérer les données d’apprentissage sur le stockage isolé
En assurant l’isolation du stockage des données du stockage par défaut utilisé par l’espace de travail pour les journaux, vous pouvez :
- Attacher les mêmes instances de stockage en tant que magasins de données aux espaces de travail primaires et secondaires.
- Utiliser la géoréplication pour les comptes de stockage de données et optimiser votre durée de bon fonctionnement.
Gérer des ressources Machine Learning en tant que code
Notes
La sauvegarde et la restauration des métadonnées d’espace de travail, telles que l’historique des exécutions, les modèles et les environnements, ne sont pas disponibles. La spécification de ressources et de configurations en tant que code utilisant des spécifications YAML vous aidera à recréer des ressources sur l’ensemble des espaces de travail en cas de sinistre.
Les tâches dans Azure Machine Learning sont définies par une spécification de tâche. Cette spécification inclut des dépendances sur les artefacts d’entrée qui sont gérés au niveau de l’instance de l’espace de travail, y compris les environnements, les jeux de données et le calcul. Pour les envois et déploiements de tâches à plusieurs régions, nous vous recommandons de suivre les pratiques suivantes :
Gérez votre base de code localement, avec l’appui d’un référentiel Git.
Exportez les notebooks importants d’Azure Machine Learning Studio.
Exportez les pipelines créés dans Studio en tant que code.
Notes
Les pipelines créés dans le concepteur Studio ne peuvent actuellement pas être exportés en tant que code.
Gérez les configurations en tant que code.
- Évitez les références codées en dur à l’espace de travail. Au lieu de cela, configurez une référence à l’instance de l’espace de travail à l’aide d’un fichier de configuration et utilisez Workspace.from_config() pour initialiser l’espace de travail. Pour automatiser le processus, utilisez la commande az ml folder attach de l’extension Azure CLI pour Machine Learning.
- Utilisez des assistants d’envoi de tâche, tels que ScriptRunConfig et Pipeline.
- Utilisez Environments.save_to_directory() pour enregistrer vos définitions d’environnement.
- Utilisez un Dockerfile si vous utilisez des images Docker personnalisées.
- Utilisez la classe Dataset pour définir la collection de chemins d’accès aux données utilisée par votre solution.
- Utilisez la classe Inferenceconfig pour déployer des modèles en tant que points de terminaison d’inférence.
Initialisation d’un basculement
Continuer à travailler dans l’espace de travail de basculement
Lorsque votre espace de travail principal devient indisponible, vous pouvez basculer vers l’espace de travail secondaire pour poursuivre l’expérimentation et le développement. Azure Machine Learning n’envoie pas automatiquement les tâches à l’espace de travail secondaire en cas de panne. Mettez à jour votre configuration de code pour qu’elle pointe vers la nouvelle ressource d’espace de travail. Nous vous recommandons d’éviter le codage en dur des références d’espace de travail. Utilisez plutôt un fichier de configuration d’espace de travail pour réduire les étapes manuelles des utilisateurs lors du changement d’espace de travail. Veillez également à mettre à jour toutes les automatisations, telles que l’intégration continue et les pipelines de déploiement vers le nouvel espace de travail.
Azure Machine Learning ne peut pas synchroniser ou récupérer des artefacts ou des métadonnées entre des instances d’espace de travail. En fonction de la stratégie de déploiement de votre application, vous devrez peut-être déplacer des artefacts ou recréer des entrées d’expérimentation telles que des objets de jeux de données dans l’espace de travail de basculement afin de continuer l’envoi de tâche. Si vous avez configuré votre espace de travail principal et les ressources de l’espace de travail secondaire pour partager les ressources associées avec la géoréplication activée, certains objets peuvent être directement accessibles à l’espace de travail de basculement. Par exemple, si les deux espaces de travail partagent les mêmes images Docker, magasins de données configurés et ressources Azure Key Vault. Le diagramme suivant illustre une configuration où deux espaces de travail partagent les mêmes images (1), magasins de données (2) et Key Vault (3).
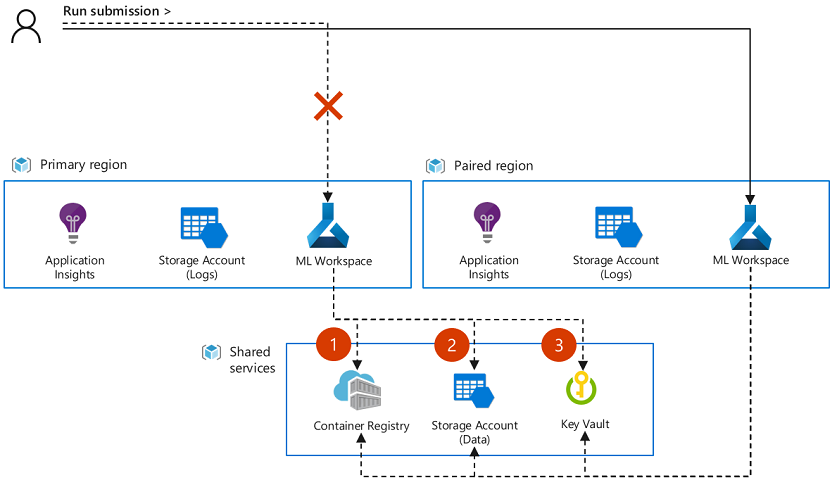
Notes
Les travaux en cours d’exécution lorsqu’une panne de service se produit ne sont pas automatiquement migrés vers l’espace de travail secondaire. Il est également peu probable que les travaux reprennent et se terminent correctement dans l’espace de travail principal une fois la panne résolue. Au lieu de cela, ces travaux doivent être envoyés à nouveau à l’espace de travail secondaire ou au principal (une fois la panne résolue).
Déplacement d’artefacts entre espaces de travail
Selon votre approche de récupération, vous devrez peut-être copier des artefacts tels que les objets de jeu de données et de modèle entre les espaces de travail pour continuer votre travail. Actuellement, la portabilité des artefacts entre les espaces de travail est limitée. Nous vous recommandons de gérer les artefacts en tant que code dans la mesure du possible afin qu’ils puissent être recréés dans l’instance de basculement.
Les artefacts suivants peuvent être exportés et importés entre les espaces de travail à l’aide de l’extension Azure CLI pour Machine Learning :
| Artefact | Exporter | Importer |
|---|---|---|
| Modèles | az ml model download --model-id {ID} --target-dir {PATH} | az ml model register –name {NAME} --path {PATH} |
| Environnements | az ml environment download -n {NAME} -d {PATH} | az ml environment register -d {PATH} |
| Pipelines Azure Machine Learning (générés par code) | az ml pipeline get --path {PATH} | az ml pipeline create --name {NAME} -y {PATH} |
Conseil
- Les jeux de données inscrits ne peuvent pas être téléchargés ou déplacés. Cela comprend les jeux de données générés par Azure Machine Learning, comme les jeux de données de pipeline intermédiaire. Toutefois, les jeux de données qui font référence à un emplacement de fichier partagé auquel les deux espaces de travail peuvent accéder, ou où le stockage de données sous-jacent est répliqué, peuvent être inscrits sur les deux espaces de travail. Utilisez la commande az ml dataset register pour inscrire un jeu de données.
- Les sorties de tâche sont stockées dans le compte de stockage par défaut associé à un espace de travail. Si les sorties de tâche peuvent devenir inaccessibles à partir de l’interface utilisateur de Studio en cas de panne d’un service, vous pouvez accéder directement aux données via le compte de stockage. Pour plus d’informations sur l’utilisation des données stockées dans des objets blob, consultez Créer, télécharger et lister des objets blob avec Azure CLI.
Options de récupération
Suppression de l’espace de travail
Si vous avez accidentellement supprimé votre espace de travail, vous pouvez peut-être le récupérer. Pour connaître les étapes de récupération, consultez Récupérer les données d’un espace de travail après leur suppression accidentelle avec la fonctionnalité de suppression réversible (préversion).
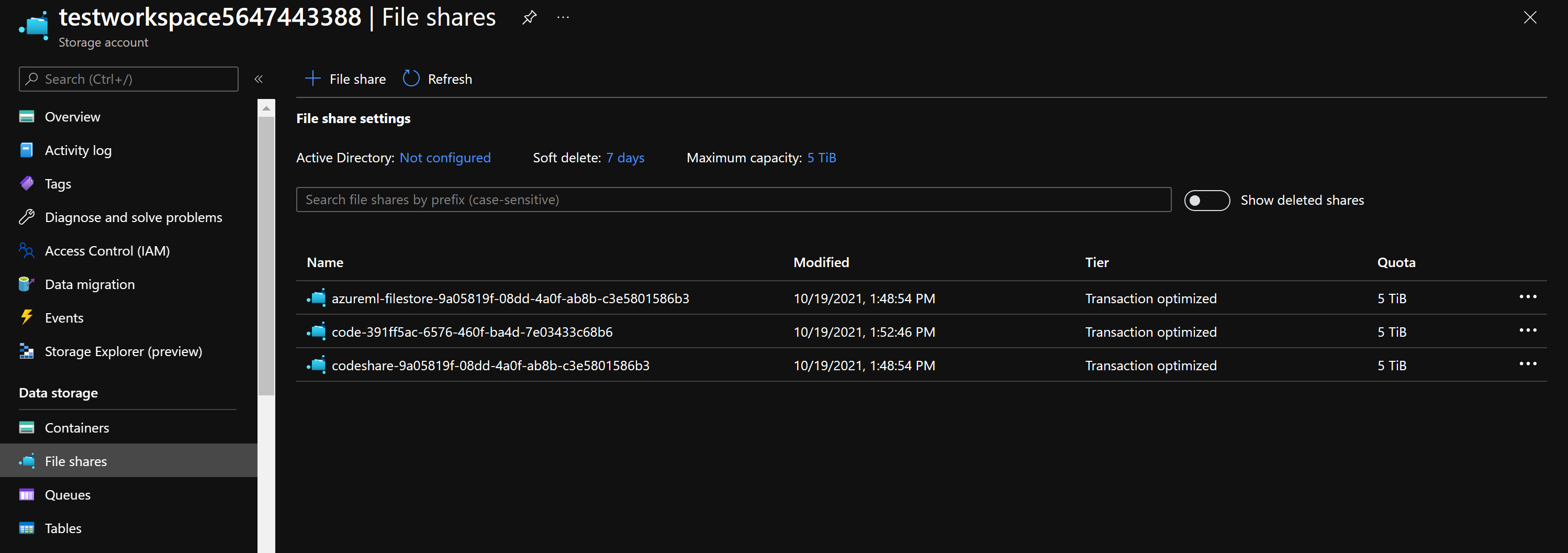
Dans le cas où votre espace de travail ne peut être récupéré, vous pouvez toujours récupérer vos notebooks depuis la ressource de stockage Azure associée à l’espace de travail en procédant comme suit :
- Dans le portail Azure, accédez au compte de stockage qui était lié à l’espace de travail Azure Machine Learning supprimé.
- Dans la section Stockage de données sur la gauche, cliquez sur Partages de fichiers.
- Vos notebooks se trouvent sur le partage de fichiers dont le nom contient l’ID de votre espace de travail.
Étapes suivantes
Pour en savoir plus sur les déploiements d’infrastructure reproductibles avec Azure Machine Learning, utilisez un modèle Azure Resource Manager.