Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Note
Les magasins de connaissances sont un stockage secondaire qui existe dans le stockage Azure et contiennent les résultats des skillsets de recherche d'Azure AI. Elles sont distinctes des sources de connaissances et des bases de connaissances, qui sont utilisées dans les flux de travail de récupération agentique .
La base de connaissances est un stockage secondaire pour le contenu enrichi par l’IA créé par un ensemble de compétences dans Recherche Azure AI. Dans Recherche Azure AI, un travail d’indexation envoie toujours la sortie à un index de recherche, mais si vous attachez un ensemble de compétences à un indexeur, vous pouvez également et de manière facultative envoyer une sortie enrichie par l’IA à un conteneur ou une table dans Stockage Azure. Une base de connaissances peut être utilisée pour une analyse indépendante ou un traitement en aval dans des scénarios de non-recherche tels que l’exploration de connaissances.
Les deux résultats de l’indexation, index de recherche et base de connaissances, sont des produits mutuellement exclusifs du même pipeline. Ils sont dérivés des mêmes entrées et contiennent les mêmes données, mais leur contenu est structuré, stocké et utilisé dans différentes applications.

Physiquement, une base de connaissances représente un Stockage Azure, soit le Stockage Table Azure, soit le Stockage Blob Azure, ou les deux. Tout outil ou processus pouvant se connecter au Stockage Azure peut utiliser le contenu d’un magasin de connaissances. Il n’existe aucune prise en charge des requêtes dans Recherche Azure AI pour récupérer du contenu à partir d’une base de connaissances.
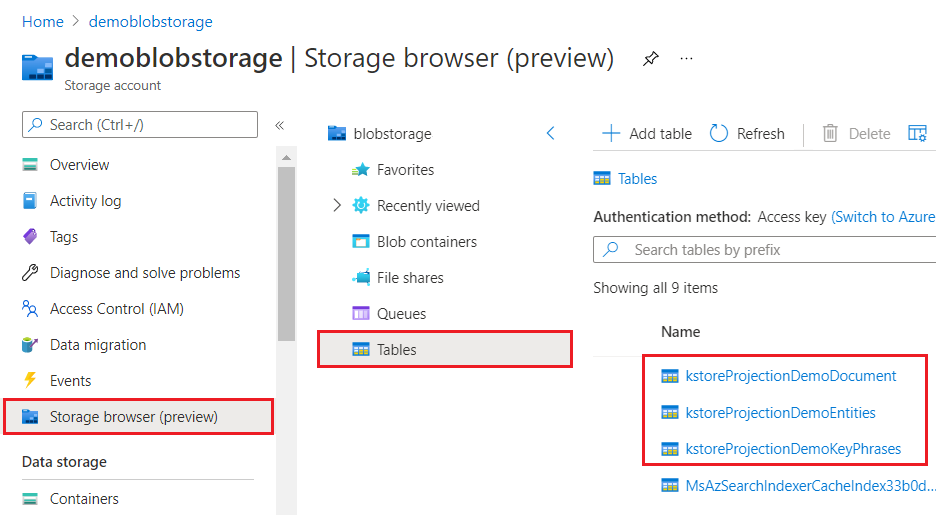
Vue à travers le portail Azure, une base de connaissances ressemble à n’importe quelle collection de tables, d’objets ou de fichiers. La capture d’écran suivante montre un magasin de connaissances composé de trois tables. Vous pouvez adopter une convention d’affectation de noms, telle qu’un préfixe kstore, pour conserver votre contenu groupé.
Avantages de la base de connaissances
Les principaux avantages d’une base de connaissances sont deux fois plus nombreux : un accès flexible au contenu et la possibilité de mettre en forme les données.
Contrairement à un index de recherche accessible uniquement par le biais de requêtes dans Recherche Azure AI, une base de connaissances est accessible par tout outil, application ou processus qui prend en charge les connexions vers le Stockage Azure. Cette flexibilité ouvre de nouveaux scénarios pour la consommation du contenu analysé et enrichi produit par un pipeline d’enrichissement.
Les mêmes compétences qui enrichissent les données peuvent également être utilisées pour mettre en forme les données. Certains outils comme Power BI fonctionnent mieux avec les tables, alors qu’une charge de travail de science des données peut nécessiter une structure de données complexe dans un format blob. L’ajout d’une compétence Modélisateur à un ensemble de compétences vous permet de contrôler la forme de vos données. Vous pouvez ensuite passer ces formes à des projections, tables ou objets Blob, pour créer des structures de données physiques qui s’alignent sur l’utilisation prévue des données.
La vidéo suivante explique ces deux avantages, et bien plus encore.
Définition de la base de connaissances
Une base de connaissances est définie à l’intérieur d’une définition de compétences et possède deux composants :
Une chaîne de connexion au service Stockage Azure
Projections qui déterminent si la base de connaissances est constitué de tables, d’objets ou de fichiers. L’élément de projections est un tableau. Vous pouvez créer plusieurs ensembles de combinaisons table-objet-fichier au sein d’une base de connaissances.
"knowledgeStore": { "storageConnectionString":"<YOUR-AZURE-STORAGE-ACCOUNT-CONNECTION-STRING>", "projections":[ { "tables":[ ], "objects":[ ], "files":[ ] } ] }
Le type de projection que vous spécifiez dans cette structure détermine le type de stockage utilisé par la base de connaissances, mais pas sa structure. Les champs des tables, des objets et des fichiers sont déterminés par la sortie de compétence Shaper si vous créez la base de connaissances par programmation, ou par l’Assistant Importation de données si vous utilisez le portail Azure.
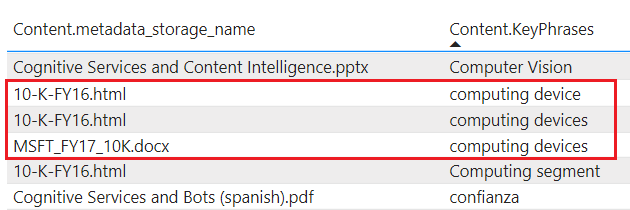
tablespermet de projeter du contenu enrichi dans le service Stockage Table. Définissez une projection de table lorsque vous avez besoin de structures de rapports tabulaires pour des entrées dans des outils analytiques, ou les exporter en tant que trames de données dans d’autres magasins de données. Vous pouvez spécifier plusieurstablesdans le même groupe de projections pour obtenir un sous-ensemble ou une coupe transversale des documents enrichis. Dans le même groupe de projection, les relations entre tables sont conservées afin que vous puissiez les utiliser toutes.Le contenu projeté n’est pas agrégé ou normalisé. La capture d’écran suivante montre un tableau, trié par phrases clés, avec le document parent indiqué dans la colonne adjacente. Contrairement à l’ingestion des données durant l’indexation, il n’existe aucune analyse linguistique ou agrégation de contenu. Les formes plurielles et les différences de casse sont considérées comme des instances uniques.
objectspermet de projeter un document JSON dans le service Stockage Blob. La représentation physique d’unobjectest une structure JSON hiérarchique représentant un document enrichi.filespermet de projeter des fichiers image dans le service Stockage Blob. Unfileest une image extraite d’un document, transférée intacte vers un stockage Blob. Bien qu’il soit nommé « fichiers », il s’affiche dans le Stockage Blob et non dans le stockage de fichiers.
Créer une base de connaissances
Utilisez le portail Azure, les API REST ou un package du Kit de développement logiciel (SDK) Azure pour créer une base de connaissances. Toutes les méthodes nécessitent stockage Azure, un ensemble de compétences et un indexeur. Étant donné que les indexeurs nécessitent un index de recherche, vous devez également fournir une définition d’index.
Les API REST et les kits SDK fournissent un contrôle total sur les projections : tables, objets et fichiers. Le portail Azure crée automatiquement une base de connaissances dans le cadre du flux de travail RAG modal, qui est limité aux projections de fichiers pour les images extraites.
L’Assistant Importation de données crée un entrepôt de connaissances uniquement pour le scénario RAG multimodal. Pour commencer, consultez Démarrage rapide : Recherche modale dans le portail Azure.
Se connecter avec des applications
Lorsque du contenu enrichi se trouve dans le stockage, n'importe quel outil ou technologie capable de se connecter à Stockage Blob peut être utilisé pour explorer, analyser ou utiliser le contenu. La liste suivante est un début :
Explorateur Stockage ou navigateur de stockage sur le Portail Azure pour afficher la structure et le contenu enrichis du document. Considérez-le comme votre outil de référence pour afficher le contenu de la base de connaissances.
Power BI pour la création de rapports et l’analyse.
Azure Data Factory permet d'effectuer d'autres manipulations.
Cycle de vie du contenu
Chaque fois que vous exécutez l’indexeur et l’ensemble de compétences, la base de connaissances est mise à jour si l’ensemble de compétences ou les données sources sous-jacentes ont changé. Les changements détectés par l’indexeur sont propagés via le processus d’enrichissement aux projections dans la base de connaissances, ce qui permet de garantir que les données projetées sont une représentation actualisée du contenu de la source de données d’origine.
Note
Bien que vous puissiez modifier les données dans les projections, les mises à jour sont remplacées au prochain appel du pipeline, en supposant que le document présent dans les données sources soit mis à jour.
Changements dans les données sources
Pour les sources de données qui prennent en charge le suivi des modifications, un indexeur traite les nouveaux documents ainsi que ceux auxquels des changements ont été apportés, tout en ignorant les documents existants déjà traités. Les informations d’horodatage varient en fonction de la source de données. Toutefois, dans un conteneur d’objets blob, l’indexeur examine la date lastmodified pour déterminer quels sont les objets blob à ingérer.
Changements apportés à un ensemble de compétences
Si vous apportez des changements à un ensemble de compétences, vous devez activer la mise en cache des documents enrichis pour réutiliser les enrichissements existants dans la mesure du possible.
En l’absence de mise en cache incrémentielle, l’indexeur traite toujours les documents dans l’ordre de la limite supérieure, sans revenir en arrière. L’indexeur traite les objets blob triés par lastModified, quels que soient les changements apportés aux paramètres de l’indexeur ou à l’ensemble de compétences. Si vous changez un ensemble de compétences, les documents traités ne sont pas mis à jour pour refléter le nouvel ensemble de compétences. Les documents traités après l’ajout de changements à l’ensemble de compétences utilisent le nouvel ensemble de compétences. Ainsi, les documents d’index sont un mélange d’anciens et de nouveaux ensembles de compétences.
Avec la mise en cache incrémentielle et après la mise à jour d’un ensemble de compétences, l’indexeur réutilise les enrichissements non affectés par les changements apportés à l’ensemble de compétences. Les enrichissements en amont sont extraits du cache, tout comme les enrichissements indépendants et isolés de la compétence à laquelle des changements ont été apportés.
Deletions
Bien qu’un indexeur crée et mette à jour des structures et du contenu dans le service Stockage Azure, il ne les supprime pas. Les projections continuent d’exister même quand l’indexeur ou l’ensemble de compétences est supprimé. En tant que propriétaire du compte de stockage, vous devez supprimer une projection si elle n’est plus nécessaire.
Étapes suivantes
La base de connaissances offre la persistance de documents enrichis, utile lors de la conception d’un ensemble de compétences, ou la création de structures et de contenu pour une consommation par les applications clientes qui peuvent accéder à un compte de stockage Azure.
L’approche la plus simple pour créer des documents enrichis par programmation consiste à utiliser des API REST.