Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans la Recherche Azure AI, un indexeur est un analyseur qui extrait des données textuelles pouvant faire l’objet d’une recherche à partir de sources de données Internet, et renseigne un index de recherche en utilisant des mappages champ à champ entre une source de données et un index de recherche. Cette approche est parfois appelée « modèle d’extraction », car le service de recherche extrait des données sans que vous ayez à écrire de code ajoutant des données à un index.
Les indexeurs pilotent également l’exécution des ensembles de compétences et l’enrichissement par IA, où vous pouvez configurer des compétences pour intégrer un traitement supplémentaire du contenu en route vers un index. La reconnaissance optique de caractères (OCR) sur des fichiers image, la compétence de fractionnement de texte pour la segmentation des données et l’appel de modèles d’incorporation afin de générer des vecteurs pour la recherche vectorielle sont des exemples.
Les indexeurs ciblent les sources de données prises en charge. Une configuration d’indexeur spécifie une source de données (origine) et un index de recherche (destination). Plusieurs sources, comme Stockage Blob Azure, ont d’autres propriétés de configuration d’indexeur spécifiques à ce type de contenu.
Vous pouvez exécuter des indexeurs à la demande ou en fonction d’une planification d’actualisation des données périodique qui s’exécute jusqu’à une fois toutes les cinq minutes. Des mises à jour plus fréquentes empêchent l’utilisation d’indexeurs, nécessitant l’implémentation d’un « modèle d’envoi (push) » qui envoie simultanément des données à Recherche Azure AI et à votre source de données externe pour la synchronisation des données.
Un service de recherche exécute un travail d’indexeur par unité de recherche. Si vous avez besoin d’un traitement simultané, assurez-vous d’avoir suffisamment de réplicas. Les indexeurs ne s’exécutent pas en arrière-plan. Vous pouvez donc détecter plus de limitation des requêtes que d’habitude si le service est sous pression.
Scénarios d’indexation et cas d’usage
Vous pouvez utiliser un indexeur comme seul moyen d’ingestion de données ou en association avec d’autres techniques. Le tableau suivant récapitule les scénarios principaux.
| Scénario | Stratégie |
|---|---|
| Source de données unique | Ce modèle est le plus simple : une source de données est le seul fournisseur de contenu pour un index de recherche. La plupart des sources de données prises en charge offrent une certaine forme de détection des modifications, de sorte que les exécutions ultérieures de l’indexeur détectent la différence lorsque du contenu est ajouté ou mis à jour dans la source. |
| Sources de données multiples | Une spécification d’indexeur ne peut avoir qu’une seule source de données, mais l’index de recherche lui-même peut accepter du contenu provenant de plusieurs sources, où chaque travail de l’indexeur apporte du contenu nouveau provenant d’un fournisseur de données différent. Chaque source peut apporter sa contribution de documents complets ou remplir des champs sélectionnés dans chaque document. Pour un examen plus approfondi de ce scénario, consultez Tutoriel : Indexer à partir de plusieurs sources de données. |
| Plusieurs Indexeurs | Plusieurs sources de données sont généralement associées à plusieurs indexeurs si vous devez faire varier les paramètres d’exécution, la planification ou les mappages de champs. Effectuer un scale-out inter-région de Recherche Azure AI est une variante de ce scénario. Vous pouvez avoir des copies du même index de recherche dans différentes régions. Pour synchroniser le contenu de l’index de recherche, vous pouvez faire en sorte que plusieurs indexeurs effectuent une extraction de la même source de données, où chaque indexeur cible un index de recherche différent. L’indexation parallèle de jeux de données très volumineux nécessite également une stratégie multi-indexeur, où chaque indexeur cible un sous-ensemble des données. |
| Transformation du contenu | Les indexeurs pilotent l’exécution de l’ensemble de compétences et l’enrichissement par IA. Les transformations de contenu sont définies dans un ensemble de compétences que vous attachez à l’indexeur. Vous pouvez utiliser des compétences pour incorporer la segmentation et la vectorisation des données. |
Vous devez prévoir de créer un indexeur pour chaque association source de données/index cible. Vous pouvez avoir plusieurs indexeurs écrivant dans le même index et réutiliser la même source de données pour plusieurs indexeurs. Toutefois, un indexeur ne peut consommer qu'une source de données à la fois, et ne peut écrire que dans un seul index. Comme l’illustre le graphique suivant, une source de données fournit l’entrée à un indexeur, qui remplit ensuite un index unique :

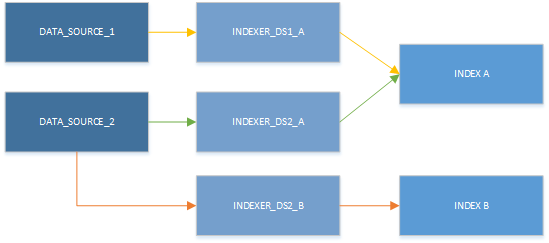
Bien que vous ne puissiez utiliser qu’un indexeur à la fois, les ressources peuvent être utilisées dans des combinaisons différentes. Le principal enseignement de l’illustration suivante est qu’elle montre qu’une source de données peut être appariée à plusieurs indexeurs, et que plusieurs indexeurs peuvent écrire dans le même index.
Sources de données prises en charge
Les indexeurs analysent les magasins de données sur Azure et hors d’Azure.
- Stockage Blob Azure
- Azure Cosmos DB
- Azure Data Lake Storage Gen2
- Azure SQL Database
- Stockage de tables Azure
- Azure SQL Managed Instance
- SQL Server sur les machines virtuelles Azure
- Azure Files (en préversion)
- Azure MySQL (en préversion)
- SharePoint dans Microsoft 365 (en préversion)
- Azure Cosmos DB for MongoDB (en préversion)
- Azure Cosmos DB for Apache Gremlin (en préversion)
- OneLake (en préversion)
Azure Cosmos DB pour Cassandra n’est pas pris en charge.
Les indexeurs acceptent des ensembles de lignes aplatis, comme une table ou une vue, ou des éléments dans un conteneur ou un dossier. Dans la plupart des cas, un document de recherche est créé par ligne, enregistrement ou élément.
Les connexions de l’indexeur aux sources de données distantes peuvent être effectuées à l’aide de connexions Internet standard (publiques) ou de connexions privées chiffrées quand vous utilisez une liaison privée partagée. Vous pouvez également configurer des connexions pour authentifier à l’aide d’une identité managée. Pour plus d’informations sur les connexions sécurisées, consultez Accès de l’indexeur au contenu protégé par les fonctionnalités de sécurité réseau Azure et Se connecter à une source de données en utilisant une identité managée.
Étapes de l’indexation
Lors d’une exécution initiale, lorsque l’index est vide, un indexeur lit toutes les données fournies dans la table ou le conteneur. Lors des exécutions suivantes, l’indexeur peut généralement détecter et récupérer uniquement les données qui ont été modifiées. Pour les données blob, la détection des modifications est automatique. Pour d’autres sources de données comme Azure SQL ou Azure Cosmos DB, la détection des modifications doit être activée.
Pour chaque document qu’il reçoit, un indexeur implémente ou coordonne plusieurs étapes, de la récupération du document à un « transfert » vers un moteur de recherche final pour indexation. Si vous le souhaitez, un indexeur peut également opérer pour gérer l’exécution d’un ensemble de compétences et des sorties, en supposant qu’un ensemble de compétences est défini.

Phase 1 : craquage de document
Le décodage de document est le processus d’ouverture de fichiers et d’extraction du contenu. Le contenu textuel peut être extrait de fichiers sur un service, de lignes dans une table ou d’éléments dans un conteneur ou une collection.
Vous pouvez également activer l’extraction d’images pendant le craquage de document pour des frais supplémentaires. Cela est désactivé par défaut et peut être activé via la imageAction propriété dans la configuration des paramètres de l’indexeur. Passez en revue certains scénarios d’image pour la gestion des images de l’indexeur.
Selon la source de données, l’indexeur essaiera différentes opérations pour extraire le contenu potentiellement indexable :
Lorsque le document est un fichier avec des images incorporées, telles qu’un fichier PDF, l’indexeur extrait du texte, des images et des métadonnées. Les indexeurs peuvent ouvrir des fichiers à partir de Stockage Blob Azure, Azure Data Lake Storage Gen2 et SharePoint.
Lorsque le document est un enregistrement dans Azure SQL, l’indexeur extrait le contenu non binaire de chaque champ de chaque enregistrement.
Si le document est un enregistrement dans Azure Cosmos DB, l’indexeur extrait le contenu non binaire des champs et les sous-champs du document Azure Cosmos DB.
Notez que le processus de craquage de document peut également être déclenché ultérieurement pendant la phase d’exécution de l’ensemble de compétences facultative, à l’aide d’ensembles de compétences, pour la transformation des données. L’ajout d’un ensemble de capacités avec des compétences en image permet l’analyse des documents pour extraire des images et les mettre en file d’attente pour le traitement.
Phase 2 : mappages de champs
Un indexeur extrait le texte d’un champ source et l’envoie à un champ de destination dans un index ou une base de connaissances. Quand les noms de champ et les types de données coïncident, le chemin est clair. Toutefois, vous pouvez utiliser des noms ou des types différents dans la sortie, auquel cas vous devez indiquer à l’indexeur comment mapper le champ.
Pour spécifier des mappages de champs, entrez les champs source et de destination dans la définition de l’indexeur.
Le mappage de champs se produit après le craquage de document, mais avant les transformations, quand l’indexeur lit les données des documents sources. Lorsque vous définissez un mappage de champs, la valeur du champ source est envoyée telle quelle au champ de destination, sans aucune modification.
Phase 3 : exécution d’un ensemble de compétences
L’exécution d’un ensemble de compétences est une étape facultative qui appelle un traitement IA intégré ou personnalisé. Les ensembles de compétences peuvent ajouter la reconnaissance optique de caractères (OCR) ou d’autres formes d’analyse d’image si le contenu est binaire. Les ensembles de compétences peuvent également ajouter un traitement en langage naturel. Par exemple, vous pouvez ajouter une traduction de texte ou une extraction de phrases clés.
Quelle que soit la transformation, l’exécution d’un ensemble de compétences est l’endroit où l’enrichissement se produit. Si un indexeur est un pipeline, vous pouvez considérer un ensemble de compétences comme un « pipeline dans le pipeline ».
Phase 4 : mappages de champs de sortie
Si vous ajoutez un ensemble de compétences, vous devez spécifier des mappages de champs de sortie dans la définition de l’indexeur. La sortie d’un ensemble de compétences est manifestée en interne sous la forme d’une arborescence appelée document enrichi. Les mappages de champs de sortie vous permettent de sélectionner les parties de cette arborescence à mapper dans les champs de votre index.
En dépit de la similarité des noms, les mappages de champs de sortie et les mappages de champs génèrent des associations de sources différentes. Les mappages de champs associent le contenu du champ source à celui d’un champ de destination dans un index de recherche. Les mappages de champs de sortie associent le contenu d’un document enrichi interne (sorties de compétence) à celui des champs de destination dans l’index. Contrairement aux mappages de champs, qui sont considérés comme facultatifs, un mappage de champs de sortie est requis pour tout contenu transformé qui doit figurer dans l’index.
L’image suivante montre un exemple de session de débogage représentant les étapes de l’indexeur : le décodage de document, les mappages de champs, l’exécution d’un ensemble de compétences, et les mappages de champs de sortie.

Flux de travail de base
Les indexeurs peuvent offrir des fonctionnalités propres à la source de données. À cet égard, certains aspects de la configuration de l’indexeur ou de la source de données varient en fonction du type d’indexeur. Cependant, tous les indexeurs présentent une composition et des exigences de base identiques. Les étapes communes à tous les indexeurs sont décrites ci-dessous.
Étape 1 : Création d'une source de données
Les indexeurs nécessitent un objet source de données qui fournit une chaîne de connexion et éventuellement des informations d’identification. Les sources de données sont des objets indépendants. Plusieurs indexeurs peuvent utiliser le même objet de source de données pour charger plusieurs index à la fois.
Vous pouvez créer une source de données à l’aide de l’une des approches suivantes :
- À l’aide du Portail Azure, sous l’onglet Sources de données de vos pages de service de recherche, sélectionnez Ajouter une source de données pour spécifier la définition de la source de données.
- À l’aide du Portail Azure, l’Assistant d’importation de données génère une source de données.
- À l’aide des API REST, appelez Créer une source de données.
- À l’aide du Kit de développement logiciel (SDK) Azure pour .NET, appelez la classe SearchIndexerDataSourceConnection.
Étape 2 : Création d'un index
Un indexeur automatise certaines tâches liées à l’ingestion des données, mais la création d’un index n’en fait généralement pas partie. Vous devez au préalable disposer d’un index prédéfini qui contient des champs cibles correspondants pour tous les champs sources de votre source de données externe. Les champs doivent correspondre par nom et type de données. Si ce n’est pas le cas, vous pouvez définir des mappages de champs pour établir l’association.
Pour plus d’informations, consultez Créer un indexeur.
Étape 3 : créer et exécuter (ou planifier) l’indexeur
Une définition d’indexeur se compose de propriétés qui identifient de manière unique l’indexeur, spécifient la source de données et l’index à utiliser et fournissent d’autres options de configuration qui influencent les comportements de temps d’exécution, notamment si l’indexeur s’exécute à la demande ou selon une planification.
Tous les erreurs ou avertissements relatifs à l’accès aux données ou à la validation de l’ensemble de compétences se produisent pendant l’exécution de l’indexeur. Avant l’exécution de l’indexeur, les objets dépendants comme les sources de données, les indexeurs et les ensembles de compétences sont passifs sur le service de recherche.
Pour plus d’informations, consultez Créer un indexeur.
Après la première exécution de l’indexeur, vous pouvez répéter l’exécution à la demande ou configurer une planification.
Vous pouvez surveiller l’état de l’indexeur dans le portail Azure ou en utilisant l’API Obtenir l’état de l’indexeur. Vous devez également exécuter des requêtes sur l’index pour vérifier que le résultat correspond à ce que vous attendiez.
Les indexeurs ne disposent pas de ressources de traitement dédiées. Dès lors, l’état des indexeurs peut s’afficher comme inactif avant l’exécution (en fonction d’autres travaux de la file d’attente) et les durées d’exécution peuvent ne pas être prévisibles. D’autres facteurs définissent également les performances des indexeurs, parmi lesquels la taille du document, la complexité du document, l’analyse des images.
Étapes suivantes
Maintenant que vous connaissez les indexeurs, vous pouvez passer en revue les propriétés et paramètres des indexeurs, la planification et le monitoring des indexeurs. Vous pouvez également revenir à la liste des sources de données prises en charge pour plus d’informations sur une source spécifique.