Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans ce guide de démarrage rapide, vous utilisez l’Assistant Importation et vectorisation des données dans le portail Azure pour commencer à utiliser la vectorisation intégrée. L'assistant découpe votre contenu en morceaux et appelle un modèle d'intégration pour vectoriser les morceaux au moment de l'indexation et de l'interrogation.
Ce guide de démarrage rapide utilise des fichiers PDF basés sur du texte à partir du référentiel azure-search-sample-data . Toutefois, vous pouvez utiliser des images et suivre ce guide de démarrage rapide.
Prérequis
Un compte Azure avec un abonnement actif. Créez un compte gratuitement.
Un service Recherche d’IA Azure. Nous vous recommandons le niveau Essentiel ou un niveau supérieur.
Source de données prise en charge.
Être familiarisé avec l’Assistant. Consultez Assistant Importation de données dans le portail Azure.
Sources de données prises en charge
L’Assistant Importation et vectorisation des donnéesprend en charge un large éventail de sources de données Azure. Toutefois, ce guide de démarrage rapide couvre uniquement les sources de données qui fonctionnent avec des fichiers entiers, qui sont décrits dans le tableau suivant.
| Source de données prise en charge | Descriptif |
|---|---|
| Stockage Blob Azure | Cette source de données fonctionne avec des objets blob et des tables. Vous devez utiliser un compte de performances standard (v2 universel). Les niveaux d'accès peuvent être chauds, tièdes ou froids. |
| Azure Data Lake Storage (ADLS) Gen2 | Il s’agit d’un compte stockage Azure avec un espace de noms hiérarchique activé. Pour vérifier que vous disposez de Data Lake Storage, cochez l’onglet Propriétés de la page Vue d’ensemble .
|
| OneLake | Cette source de données est actuellement en préversion. Pour plus d’informations sur les limitations et les raccourcis pris en charge, consultez l’indexation OneLake. |
Modèles d’incorporation pris en charge
Pour la vectorisation intégrée, vous devez utiliser l’un des modèles d’incorporation suivants sur une plateforme Azure AI. Les instructions de déploiement sont fournies dans une section ultérieure.
| Fournisseur | Modèles pris en charge |
|---|---|
| Azure OpenAI dans les modèles Azure AI Foundry1, 2 | text-embedding-ada-002 (modèle de création d'embeddings textuels) intégration de texte - 3 - petit text-embedding-3-large |
| Ressource multiservices Azure AI Services3 | Pour le texte et les images : Azure AI Vision multimodal4 |
| Catalogue de modèles Azure AI Foundry | Pour le texte : Cohere-embed-v3-english Cohere-embed-v3-multilingue Pour les images : Facebook-DinoV2-Image-Embeddings-ViT-Base Facebook-DinoV2-Image-Embeddings-ViT-Giant |
1 Le point de terminaison de votre ressource Azure OpenAI doit avoir un sous-domaine personnalisé, tel que https://my-unique-name.openai.azure.com. Si vous avez créé votre ressource dans le portail Azure, ce sous-domaine a été généré automatiquement lors de la configuration de la ressource.
2 ressources Azure OpenAI (avec accès aux modèles incorporés) créées dans le portail Azure AI Foundry ne sont pas prises en charge. Seules les ressources Azure OpenAI créées dans le portail Azure sont compatibles avec la compétence d’incorporation Azure OpenAI.
3 À des fins de facturation, vous devez attacher votre ressource multiservices Azure AI à l’ensemble de compétences de votre service Recherche d’IA Azure. À moins que vous n'utilisiez une connexion sans clé (aperçu) pour créer l'ensemble de compétences, les deux ressources doivent se trouver dans la même région.
4 Le modèle d’incorporation modale Azure AI Vision est disponible dans certaines régions.
Exigences relatives aux points de terminaison publics
Dans le cadre de ce guide de démarrage rapide, l’accès public doit être activé pour toutes les ressources précédentes afin que les nœuds du portail Azure puissent y accéder. Sinon, l’Assistant échoue. Une fois l’Assistant exécuté, vous pouvez activer des pare-feux et des points de terminaison privés sur les composants d’intégration à des fins de sécurité. Pour plus d’informations, consultez Connexions sécurisées dans les Assistants d’importation.
Si des points de terminaison privés sont déjà présents et que vous ne pouvez pas les désactiver, une autre option consiste à exécuter le flux respectif de bout en bout à partir d’un script ou d’un programme sur une machine virtuelle. La machine virtuelle doit se trouver sur le même réseau virtuel que le point de terminaison privé. Voici un exemple de code Python pour la vectorisation intégrée. Le même référentiel GitHub contient des exemples dans d’autres langages de programmation.
Accès en fonction du rôle
Vous pouvez utiliser l’ID Microsoft Entra avec les attributions de rôles ou l’authentification basée sur des clés avec des chaînes de connexion à accès complet. Pour les connexions Azure AI Search à d’autres ressources, nous vous recommandons d’attribuer des rôles. Ce guide de démarrage rapide part du principe que vous disposez de certains rôles.
Les services de recherche gratuits prennent en charge les connexions basées sur les rôles à Azure AI Search. Toutefois, ils ne prennent pas en charge les identités managées sur les connexions sortantes vers stockage Azure ou Azure AI Vision. Ce manque de prise en charge nécessite une authentification basée sur des clés sur les connexions entre les services de recherche gratuits et d’autres ressources Azure. Pour des connexions plus sécurisées, utilisez le niveau De base ou supérieur, puis activez les rôles et configurez une identité managée.
Pour configurer l’accès en fonction du rôle recommandé :
Sur votre service de recherche, activez les rôles et configurez une identité managée affectée par le système.
Attribuez les rôles suivants à vous-même :
Contributeur du service de recherche
Contributeur de données d’index de la Recherche
Lecteur de données d’index de la Recherche
Sur votre plateforme de source de données et votre fournisseur de modèles d’incorporation, créez des attributions de rôles qui permettent à votre service de recherche d’accéder aux données et aux modèles. Consultez Préparer des exemples de données et préparer des modèles d’incorporation.
Remarque
Si vous ne pouvez pas avancer dans l’Assistant parce que les options ne sont pas disponibles (par exemple, vous ne pouvez pas sélectionner une source de données ou un modèle d’incorporation), revenez aux attributions de rôle. Les messages d’erreur indiquent que les modèles ou les déploiements n’existent pas, lorsque la cause réelle est que le service de recherche n’a pas l’autorisation d’y accéder.
Vérifier l’espace disponible
Si vous commencez par le niveau Gratuit, vous êtes limité à trois index, aux sources de données, aux ensembles de compétences et aux indexeurs. Le niveau De base vous limite à 15. Ce guide de démarrage rapide crée l’un de chaque objet. Veillez donc à disposer d’une place pour les éléments supplémentaires avant de commencer.
Préparer l’exemple de données
Cette section traite du contenu qui fonctionne pour ce guide de démarrage rapide. Avant de continuer, vérifiez que vous avez rempli les conditions préalables pour l’accès en fonction du rôle.
Connectez-vous au portail Azure et sélectionnez votre compte stockage Azure.
Dans le volet gauche, sélectionnezstockage de données>Conteneurs.
Créez un conteneur, puis chargez les documents PDF du plan de santé utilisés pour ce guide de démarrage.
Pour attribuer des rôles :
Dans le volet gauche, sélectionnez Contrôle d’accès (IAM) .
Sélectionnez Ajouter>Ajouter une attribution de rôle.
Sous Rôles de fonction de travail, sélectionnez Lecteur de données Blob de stockage, puis sélectionnez Suivant.
Sous Membres, sélectionnez Identité managée, puis sélectionnez Sélectionner des membres.
Sélectionnez votre abonnement et l’identité managée de votre service de recherche.
(Facultatif) Synchronisez les suppressions dans votre conteneur avec des suppressions dans l’index de recherche. Pour configurer votre indexeur pour la détection de suppression :
Activer la suppression réversible sur votre compte de stockage. Si vous utilisez la suppression réversible native, l’étape suivante n’est pas requise.
Ajoutez des métadonnées personnalisées qu’un indexeur peut analyser pour déterminer quels objets blob sont marqués pour suppression. Donnez à votre propriété personnalisée un nom descriptif. Par exemple, vous pouvez nommer la propriété « IsDeleted » et la définir sur false. Répétez cette étape pour chaque blob dans le conteneur. Lorsque vous souhaitez supprimer l’objet blob, remplacez la propriété par `true`. Pour plus d’informations, consultez Modifier et supprimer la détection lors de l’indexation à partir du stockage Azure.
Préparer le modèle d’incorporation
L’Assistant peut utiliser des modèles incorporés déployés à partir d’Azure OpenAI, d’Azure AI Vision ou du catalogue de modèles dans le portail Azure AI Foundry. Avant de continuer, vérifiez que vous avez rempli les conditions préalables pour l’accès en fonction du rôle.
L’Assistant prend en charge text-embedding-ada-002, text-embedding-3-large et text-embedding-3-small. En interne, l’Assistant appelle la compétence AzureOpenAIEmbedding pour se connecter à Azure OpenAI.
Connectez-vous au portail Azure et sélectionnez votre ressource Azure OpenAI.
Pour attribuer des rôles :
Dans le volet gauche, sélectionnez Contrôle d’accès (IAM) .
Sélectionnez Ajouter>Ajouter une attribution de rôle.
Sous Rôles de fonction de tâche, sélectionnez Utilisateur Cognitive Services OpenAI, puis Suivant.
Sous Membres, sélectionnez Identité managée, puis sélectionnez Sélectionner des membres.
Sélectionnez votre abonnement et l’identité managée de votre service de recherche.
Pour déployer un modèle d’incorporation :
Connectez-vous au portail Azure AI Foundry et sélectionnez votre ressource Azure OpenAI.
Dans le volet gauche, sélectionnez Catalogue de modèles.
Déployez un modèle d’incorporation pris en charge.
Démarrer l’Assistant
Pour démarrer l’assistant pour la recherche vectorielle :
Connectez-vous au portail Azure et sélectionnez votre service Recherche d’IA Azure.
Dans la page Vue d’ensemble, sélectionnez Importation et vectorisation des données.

Sélectionnez votre source de données : Stockage Blob Azure, ADLS Gen2 ou OneLake.
Sélectionnez RAG.


Connexion à vos données
L’étape suivante consiste à se connecter à une source de données à utiliser pour l’index de recherche.
Dans la page Se connecter à vos données , spécifiez l’abonnement Azure.
Sélectionnez le compte de stockage et le conteneur qui fournissent les exemples de données.
Si vous avez activé la suppression réversible et éventuellement ajouté des métadonnées personnalisées dans Préparer des exemples de données, cochez la case Activer le suivi de suppression .
Lors des exécutions d’indexation suivantes, l’index de recherche est mis à jour pour supprimer tous les documents de recherche basés sur des objets blob supprimés de manière réversible sur stockage Azure.
Les blobs supportent soit la suppression réversible des blobs natifs, soit la suppression réversible à l’aide de métadonnées personnalisées.
Si vous avez configuré vos blobs pour la suppression réversible, indiquez la paire nom-valeur de la propriété de métadonnées. Nous vous recommandons IsDeleted. Si IsDeleted a la valeur true sur un objet blob, l’indexeur supprime le document de recherche correspondant lors de l’exécution suivante de l’indexeur.
L’Assistant ne vérifie pas le stockage Azure pour connaître les paramètres valides ou génère une erreur si les exigences ne sont pas remplies. Au lieu de cela, la détection de suppression ne fonctionne pas et votre index de recherche est susceptible de collecter des documents orphelins au fil du temps.
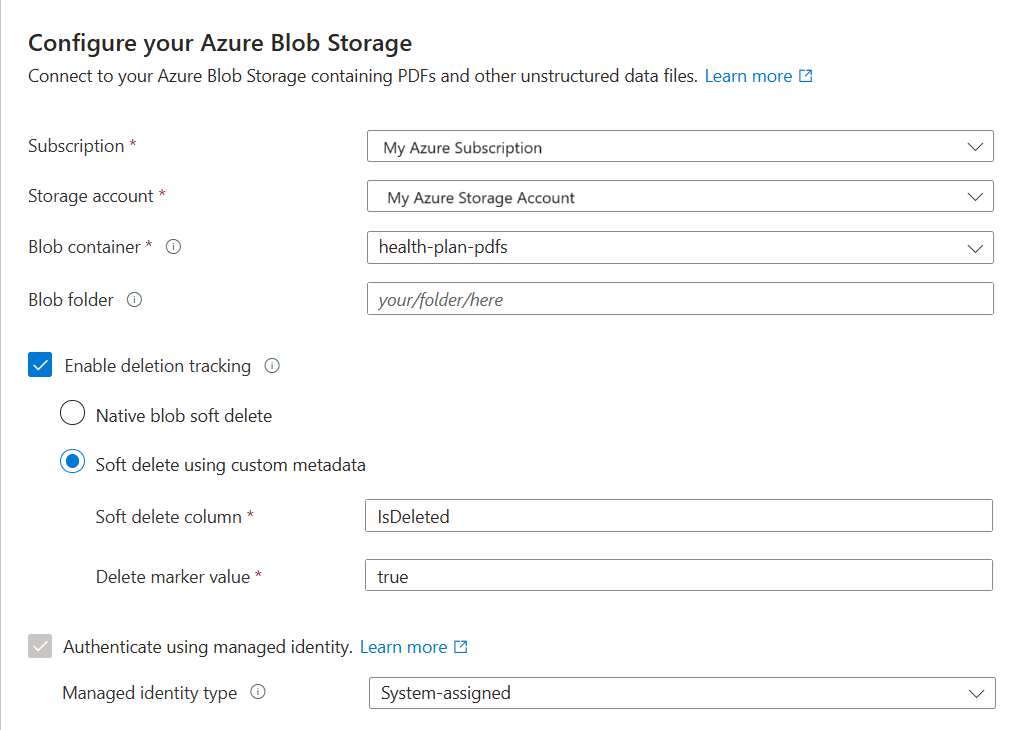
Cochez la case Authentifier à l’aide de l’identité managée .
Pour le type d’identité managée, sélectionnez Affecté par le système.
L’identité doit avoir un rôle Lecteur de données blob de stockage sur Stockage Azure.
N’ignorez pas cette étape. Une erreur de connexion se produit lors de l’indexation si l’Assistant ne peut pas se connecter au stockage Azure.
Cliquez sur Suivant.
Vectoriser votre texte
Dans cette étape, vous spécifiez un modèle d’incorporation pour vectoriser les données segmentées. La segmentation est intégrée et non configurable. Les paramètres effectifs sont les suivants :
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 500,
"maximumPagesToTake": 0, #unlimited
"unit": "characters"
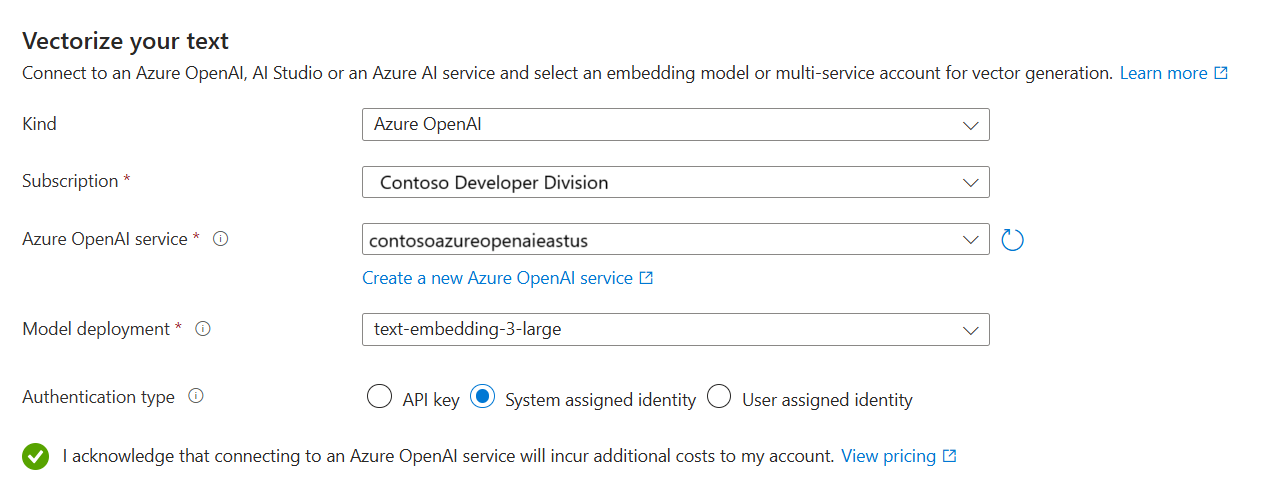
Dans la page Vectoriser votre texte , sélectionnez la source de votre modèle d’incorporation :
Azure OpenAI
Catalogue de modèles Azure AI Foundry
Azure AI Vision (via une ressource multiservices Azure AI services dans la même région que Recherche Azure AI)
Spécifiez l’abonnement Azure.
Selon votre ressource, effectuez la sélection suivante :
Pour Azure OpenAI, sélectionnez le modèle que vous avez déployé dans préparer le modèle d’incorporation.
Pour le catalogue de modèles AI Foundry, sélectionnez le modèle que vous avez déployé dans le modèle de préparation de l’incorporation.
Pour les incorporations modales d’AI Vision, sélectionnez votre ressource multiservices.
Pour le type d’authentification, sélectionnez Identité affectée par le système.
- L’identité doit avoir un rôle Utilisateur Cognitive Services sur la ressource multiservices Azure AI services.
Cochez la case indiquant que vous avez connaissance des effets de l’utilisation de ces ressources sur la facturation.
Cliquez sur Suivant.
Vectoriser et enrichir vos images
Les fichiers PDF du plan de santé incluent un logo d’entreprise, mais il n’y a pas d’autres images. Vous pouvez ignorer cette étape si vous utilisez les exemples de documents.
Cependant, si vous travaillez avec du contenu qui inclut des images utiles, vous pouvez appliquer l’IA de deux manières :
Utilisez un modèle d’incorporation d’images pris en charge à partir du catalogue ou de l’API d’incorporations modales Azure AI Vision pour vectoriser des images.
Utilisez la reconnaissance optique de caractères (OCR) pour reconnaître du texte dans des images. Cette option appelle la compétence OCR pour lire du texte à partir d’images.
La Recherche Azure AI et votre ressource Azure AI doivent se trouver dans la même région ou être configurées pour les connexions de facturation sans clé.
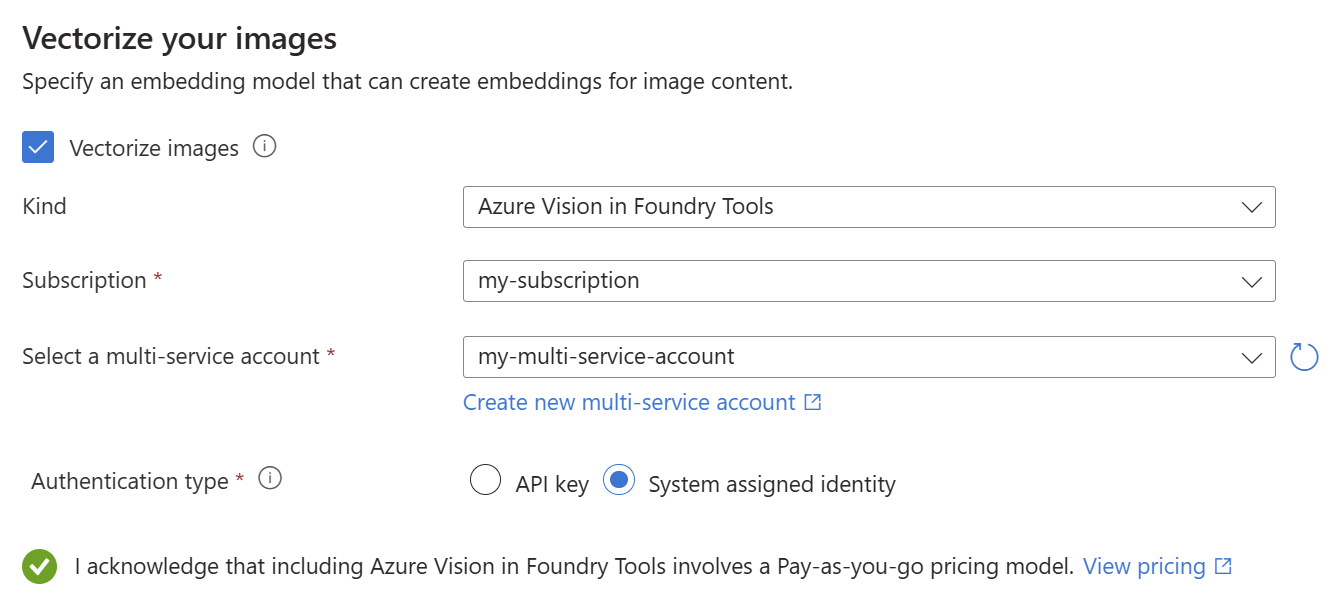
Dans la page Vectoriser vos images, spécifiez le type de connexion que l’Assistant doit établir. Pour la vectorisation d’images, l’assistant peut se connecter à des modèles d'intégration dans le portail Azure AI Foundry ou Azure AI Vision.
Spécifiez l’abonnement.
Pour le catalogue de modèles Azure AI Foundry, spécifiez le projet et le déploiement. Pour plus d’informations, consultez Préparer les modèles d’incorporation.
Si vous le souhaitez, vous pouvez fissurer des images binaires (par exemple, des fichiers de documents analysés) et utiliser des OCR pour reconnaître du texte.
Cochez la case indiquant que vous avez connaissance des effets de l’utilisation de ces ressources sur la facturation.
Cliquez sur Suivant.
Ajouter le classement sémantique
Dans la page Paramètres avancés, vous pouvez éventuellement ajouter un classement sémantique pour reclasser les résultats à la fin de l’exécution de la requête. La reclassement place les correspondances les plus sémantiquement pertinentes en haut.
Mapper de nouveaux champs
Points clés de cette étape :
Le schéma d’index fournit des champs vectoriels et non vecteurs pour les données segmentées.
Vous pouvez ajouter des champs, mais vous ne pouvez pas supprimer ou modifier des champs générés.
Le mode d’analyse syntaxique crée des segments (un document de recherche par segment).
Dans la page Paramètres avancés , vous pouvez éventuellement ajouter de nouveaux champs, en supposant que la source de données fournit des métadonnées ou des champs qui ne sont pas récupérés lors du premier passage. Par défaut, l’Assistant génère les champs décrits dans le tableau suivant.
| Champ | S’applique à | Descriptif |
|---|---|---|
| chunk_id | Vecteurs texte et image | Champ de chaîne généré. Pouvant faire l’objet d’une recherche, récupérable et triable. Il s’agit de la clé de document de l’index. |
| parent_id | Vecteurs texte | Champ de chaîne généré. Récupérable et filtrable. Identifie le document parent d’où provient le bloc. |
| segment | Vecteurs texte et image | Champ de chaîne. Version du bloc de données lisible par l’utilisateur. Interrogeable et récupérable, mais non filtrable, à choix multiples ou triable. |
| titre | Vecteurs texte et image | Champ de chaîne. Titre du document ou titre de page ou numéro de page lisible par l’utilisateur. Interrogeable et récupérable, mais non filtrable, à choix multiples ou triable. |
| vecteur_texte | Vecteurs texte | Collection(Edm.single). Représentation vectorielle du bloc. Interrogeable et récupérable, mais non filtrable, à choix multiples ou triable. |
Vous ne pouvez pas modifier les champs générés ou leurs attributs, mais vous pouvez ajouter de nouveaux champs si votre source de données les fournit. Par exemple, Stockage Blob Azure fournit une collection de champs de métadonnées.
Cliquez sur Ajouter un champ.
Sélectionnez un champ source dans les champs disponibles, entrez un nom de champ pour l’index et acceptez (ou remplacez) le type de données par défaut.
Remarque
Les champs de métadonnées peuvent faire l’objet d’une recherche, mais ne peuvent pas être récupérés, filtrables, facetables ou triables.
Si vous souhaitez restaurer le schéma dans sa version d’origine, sélectionnez Réinitialiser.
Planifier l’indexation
Dans la page Paramètres avancés , vous pouvez également spécifier une planification d’exécution facultative pour l’indexeur. Après avoir choisi un intervalle dans la liste déroulante, sélectionnez Suivant.
Terminez l’Assistant.
Dans la page Passer en revue votre configuration, spécifiez un préfixe pour les objets créés par l’Assistant. Un préfixe courant vous aide à rester organisé.
Sélectionnez Créer.
Au terme de la configuration, l’Assistant crée les objets suivants :
Connexion à la source de données.
Index avec des champs vectoriels, des vectoriseurs, des profils vectoriels et des algorithmes vectoriels. Vous ne pouvez pas concevoir ou modifier l’index par défaut pendant le flux de travail de l’Assistant. Les index sont conformes à l’API REST 2024-05-01-preview.
Ensemble de compétences avec la compétence Fractionnement de texte pour la segmentation et une compétence d’incorporation pour la vectorisation. La compétence d’incorporation est la compétence AzureOpenAIEmbeddingModel pour Azure OpenAI ou la compétence AML pour le catalogue de modèles Azure AI Foundry. L’ensemble de compétences comprend également la configuration projections d’index, qui permet de mapper les données d’un document dans la source de données à ses blocs correspondants dans un index « enfant ».
Indexeur avec mappages de champs et mappages de champs de sortie (le cas échéant).
Conseil / Astuce
Les objets créés par l’Assistant ont des définitions JSON configurables. Pour afficher ou modifier ces définitions, sélectionnez Gestion de la recherche dans le volet gauche, où vous pouvez afficher vos index, indexeurs, sources de données et ensembles de compétences.
Vérifier les résultats
L’Explorateur de recherche accepte les chaînes de texte comme entrée, puis vectorise le texte pour l’exécution de requête vectorielle.
Dans le portail Azure, accédez à Gestion de la recherche>Index, puis sélectionnez votre index.
Sélectionnez les options de requête, puis sélectionnez Masquer les valeurs vectorielles dans les résultats de recherche. Cette étape rend les résultats plus lisibles.
Dans le menu Affichage , sélectionnez la vue JSON afin de pouvoir entrer du texte pour votre requête vectorielle dans le
textparamètre de requête vectorielle.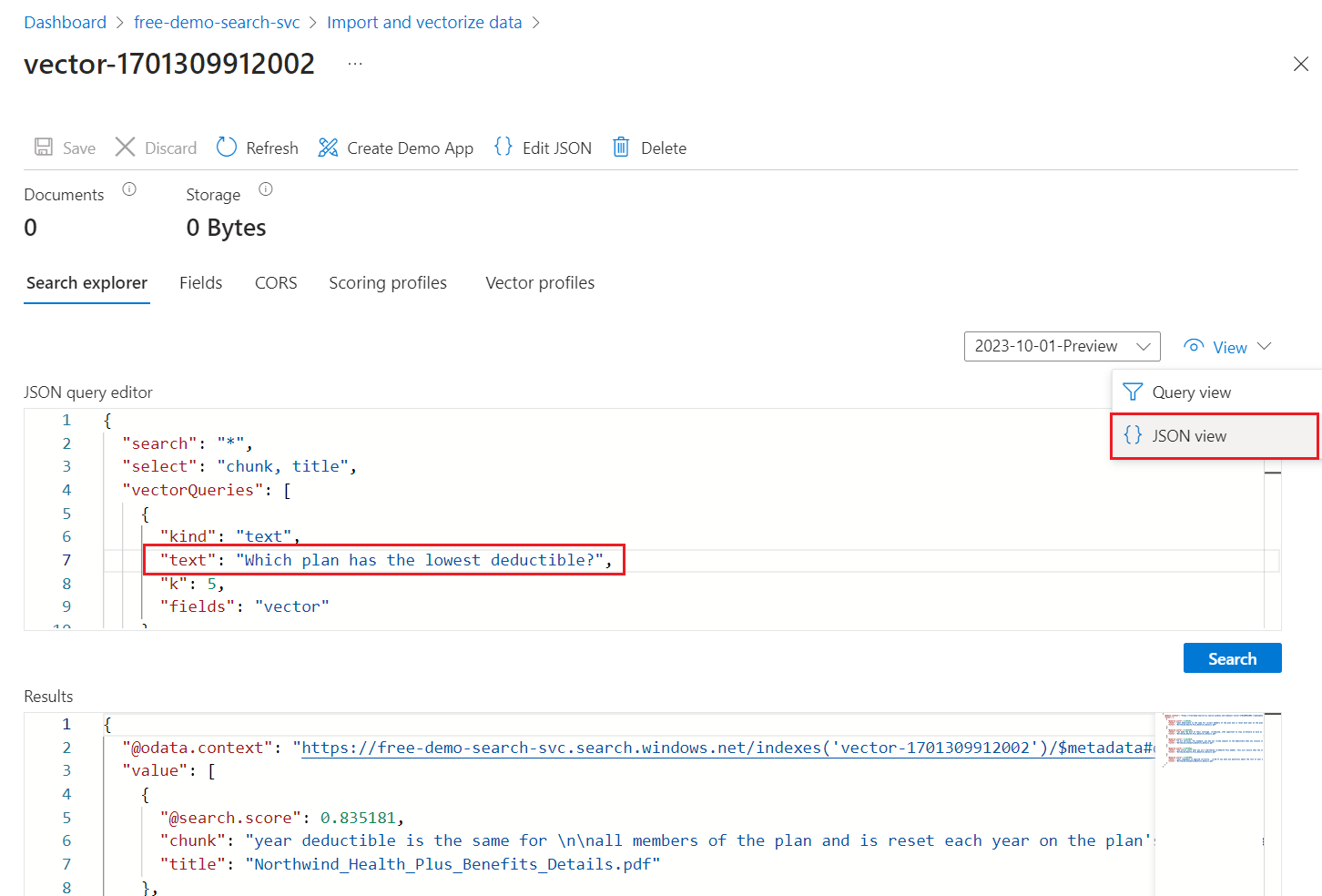
La requête par défaut est une recherche vide (
"*") mais inclut des paramètres pour retourner les correspondances de nombre. Il s’agit d’une requête hybride qui exécute des requêtes textuelles et vectorielles en parallèle. Il inclut également le classement sémantique et spécifie les champs à retourner dans les résultats via l’instructionselect.{ "search": "*", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title,image_parent_id" }Remplacez les espaces réservés astérisques (
*) par une question relative aux plans d’intégrité, telle queWhich plan has the lowest deductible?.{ "search": "Which plan has the lowest deductible?", "count": true, "vectorQueries": [ { "kind": "text", "text": "Which plan has the lowest deductible?", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title" }Pour exécuter la requête, sélectionnez Rechercher.
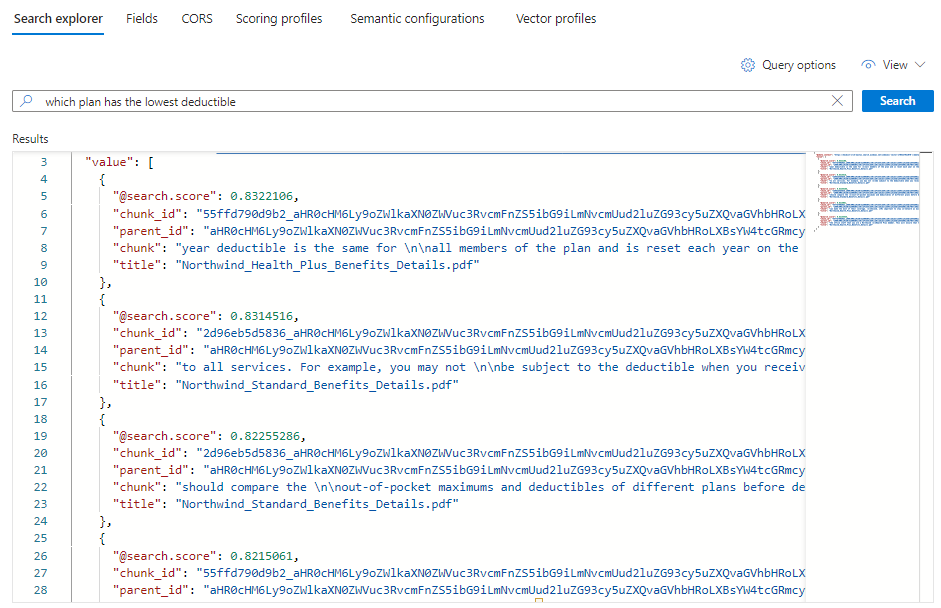
Chaque document est un bloc du fichier PDF d’origine. Le champ
titleindique le fichier PDF du bloc. Chacunchunkest long. Vous pouvez le copier puis le coller dans un éditeur de texte pour lire la valeur entière.Pour voir tous les blocs d’un document spécifique, ajoutez un filtre sur le champ
title_parent_idpour un fichier PDF spécifique. Vous pouvez vérifier l’onglet Champs de votre index pour confirmer que le champ est filtrable.{ "select": "chunk_id,text_parent_id,chunk,title", "filter": "text_parent_id eq 'aHR0cHM6Ly9oZWlkaXN0c3RvcmFnZWRlbW9lYXN0dXMuYmxvYi5jb3JlLndpbmRvd3MubmV0L2hlYWx0aC1wbGFuLXBkZnMvTm9ydGh3aW5kX1N0YW5kYXJkX0JlbmVmaXRzX0RldGFpbHMucGRm0'", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "text_vector" } ] }
Nettoyage
Azure AI Search est une ressource facturable. Si elle n’est plus nécessaire, supprimez-la de votre abonnement pour éviter des frais.
Étape suivante
Ce guide de démarrage rapide vous a présenté l’Assistant Importation et vectorisation des données, qui crée tous les objets nécessaires pour la vectorisation intégrée. Pour explorer chaque étape en détail, consultez Configurer la vectorisation intégrée dans Recherche IA Azure.