Connecter un service de recherche à d’autres ressources Azure à l’aide d’une identité managée
Vous pouvez configurer un service Azure AI Recherche pour vous connecter à d’autres ressources Azure à l’aide d’une identité managée affectée par l’utilisateur ou par le système et d’une attribution de rôle Azure. Les identités managées et les attributions de rôles éliminent le besoin de transmettre des secrets et des informations d’identification dans une chaîne de connexion ou un code.
Prérequis
Un service de recherche au niveau De base ou supérieur.
Une ressource Azure qui accepte les requêtes entrantes d’une connexion Microsoft Entra ayant une attribution de rôle valide.
Scénarios pris en charge
Azure AI Recherche peut utiliser une identité managée affectée par l’utilisateur ou par le système sur les connexions sortantes aux ressources Azure. Une identité managée affectée par le système est indiquée lorsqu’une chaîne de connexion est l’ID de ressource unique d’un service ou d’une application prenant en charge Microsoft Entra ID. Une identité managée affectée par l’utilisateur est spécifiée par le biais d’une propriété « identity ».
Un service de recherche utilise le Stockage Azure en tant que source de données d’indexeur et en tant que récepteur de données pour les sessions de débogage, la mise en cache d’enrichissement et la base de connaissances. Pour les fonctionnalités de recherche qui écrivent dans le stockage, l’identité managée a besoin d’une attribution de rôle Contributeur, comme décrit dans la section « Attribuer un rôle ».
| Scénario | Identité managée par le système | Identité managée affectée par l’utilisateur (préversion) |
|---|---|---|
| Connexions de l’indexeur aux sources de données Azure prises en charge13 | Oui | Oui |
| Azure Key Vault pour les clés gérées par le client | Oui | Oui |
| Sessions de débogage (hébergées dans Stockage Azure)1 | Oui | No |
| Cache d’enrichissement (hébergé dans Stockage Azure)1,2 | Oui | Oui |
| Base de connaissances (hébergée dans Stockage Azure)1 | Oui | Oui |
| Compétences personnalisées (hébergées dans Azure Functions ou équivalent) | Oui | Oui |
| Compétence d’incorporations Azure OpenAI | Oui | Oui |
| Vectoriseur Azure OpenAI | Oui | Oui |
1 Pour la connectivité entre la recherche et le stockage, votre configuration de sécurité réseau impose des contraintes sur le type d’identité managée que vous pouvez utiliser. Seule une identité managée système peut être utilisée pour une connexion de même région au stockage via l’exception de service approuvé ou la règle d’instance de ressource. Pour plus d’informations, consultez Accès à un compte de stockage protégé par le réseau.
2 Méthode de spécification d’un cache d’enrichissement dans l’assistant Importer des données. Actuellement, l’assistant n’accepte pas de chaîne de connexion d’identité managée pour le cache d’enrichissement. Toutefois, une fois l’assistant terminé, vous pouvez mettre à jour la chaîne de connexion dans la définition JSON de l’indexeur pour spécifier une identité managée affectée par le système ou l’utilisateur, puis réexécuter l’indexeur.
3 Notez que la désactivation des clés dans le compte de stockage Azure n’est actuellement pas prise en charge pour la table Azure utilisée comme source de données. Bien que l’identité managée ne fournisse pas explicitement les clés de stockage, le service de recherche IA utilise toujours les clés pour cette implémentation.
Créer une identité managée par le système
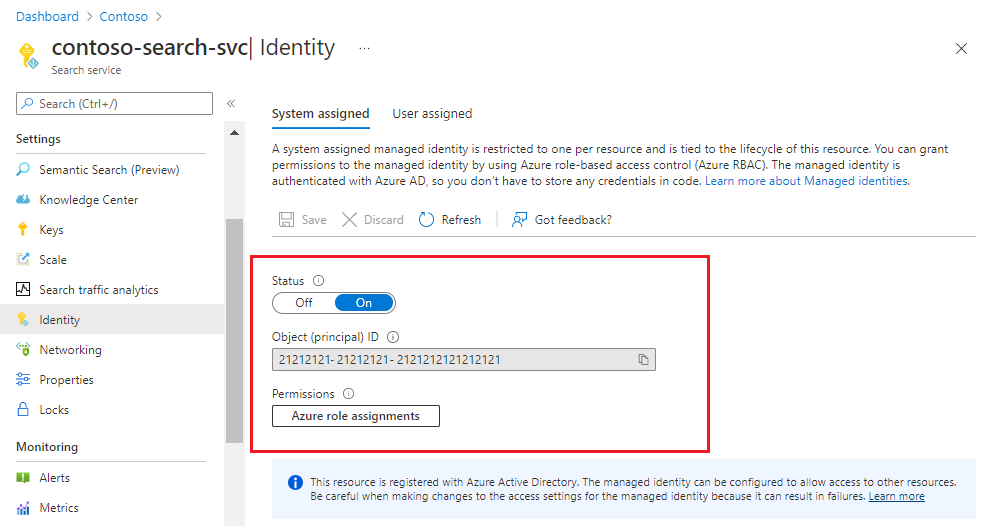
Quand une identité managée affectée par le système est activée, Azure crée une identité pour votre service de recherche qui peut être utilisée pour vous authentifier auprès d’autres services Azure au sein du même locataire et du même abonnement. Vous pouvez ensuite utiliser cette identité dans les attributions de contrôle d’accès en fonction du rôle Azure (Azure RBAC) qui autorisent l’accès aux données pendant l’indexation.
Une identité managée affectée par le système est unique à votre service de recherche et liée au service pendant sa durée de vie.
Connectez-vous au Portail Azure, puis trouvez votre service de recherche.
Sous Paramètres, sélectionnez Identité.
Dans l’onglet Affecté(e) par le système, sous État, sélectionnez Activé.
Sélectionnez Enregistrer.
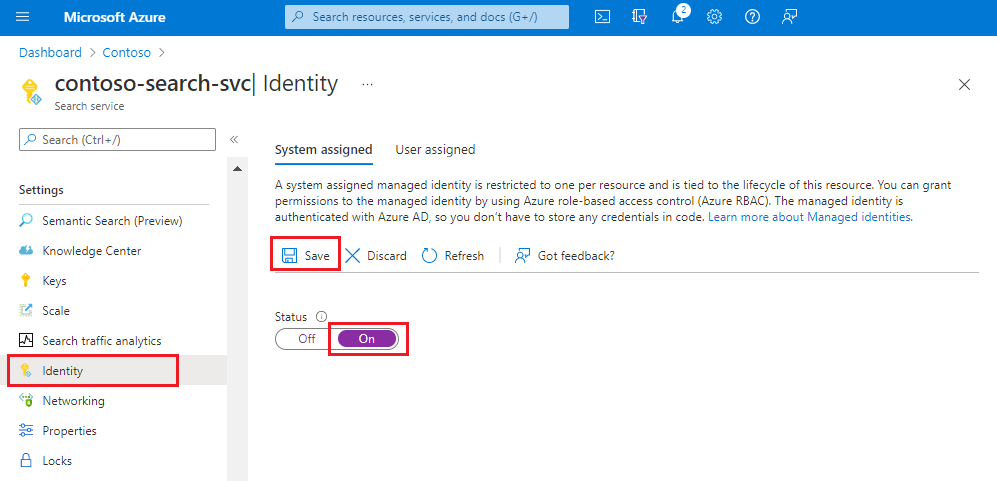
Après l’enregistrement, vous verrez qu’un identificateur d’objet a été affecté à votre service de recherche.
Créer une identité managée affectée par l’utilisateur (préversion)
Une identité managée affectée par l’utilisateur est une ressource Azure. Elle est utile si vous avez besoin d’une plus grande granularité dans les attributions de rôles, car vous pouvez créer des identités distinctes pour des applications et des scénarios différents.
Important
Cette fonctionnalité est en préversion publique sous les conditions d’utilisation supplémentaires. Les identités managées affectées par l’utilisateur ne sont pas prises en charge pour les connexions à un compte de stockage protégé par le réseau. La requête de recherche nécessite actuellement une adresse IP publique.
Connectez-vous au portail Azure
Sélectionnez + Créer une ressource.
Dans la barre de recherche « Services de recherche et marketplace », recherchez « Identité managée affectée par l’utilisateur », puis sélectionnez Créer.
Sélectionnez l’abonnement, le groupe de ressources et la région. Donnez à l’identité un nom descriptif.
Sélectionnez Créer et attendez que la fin du déploiement de la ressource.
Dans les étapes suivantes, vous allez attribuer l’identité managée affectée par l’utilisateur à votre service de recherche.
Dans la page de votre service de recherche, sous Paramètres, sélectionnez Identité.
Dans l’onglet Attribuée par l’utilisateur, sélectionnez Ajouter.
Choisissez l’abonnement, puis sélectionnez la ressource managée affectée par l’utilisateur que vous avez créée à l’étape précédente.
Autoriser l’accès au pare-feu
Si votre ressource Azure se trouve derrière un pare-feu, assurez-vous qu’il existe une règle de trafic entrant qui admet les demandes de votre service de recherche.
Pour les connexions d’une même région à Stockage Blob Azure ou Azure Data Lake Storage Gen2, utilisez une identité managée affectée par le système et l’exception de service approuvé. Si vous le souhaitez, vous pouvez configurer une règle d’instance de ressource pour admettre les requêtes.
Pour toutes les autres ressources et connexions, configurez une règle de pare-feu IP qui admet les requêtes provenant de Search. Pour plus d’informations, reportez-vous à Accès de l’indexeur au contenu protégé par les fonctionnalités de sécurité réseau Azure.
Attribuer un rôle
Une identité managée doit être associée à un rôle Azure qui détermine les autorisations sur la ressource Azure.
Des autorisations de lecteur de données sont nécessaires pour les connexions de données d’indexeur et pour accéder à une clé gérée par le client dans Azure Key Vault.
Les autorisations Contributeur (écriture) sont nécessaires pour les fonctionnalités d’enrichissement par AI qui utilisent Stockage Azure pour l’hébergement des données de session de débogage, la mise en cache d’enrichissement et le stockage de contenu à long terme dans une base de connaissances.
Les étapes suivantes concernent Stockage Azure. Si votre ressource est Azure Cosmos DB ou Azure SQL, les étapes sont similaires.
Connectez-vous au Portail Azure et recherchez votre ressource Azure à laquelle le service de recherche doit avoir accès.
Dans Stockage Azure, sélectionnez Contrôle d’accès (AIM) dans le volet de navigation gauche.
Sélectionnez Ajouter une attribution de rôle.
Dans la page Rôle, sélectionnez les rôles nécessaires pour votre service de recherche :
Tâche Attribution de rôle Indexation d’objets blob à l’aide d’un indexeur Ajouter Lecteur des données Blob du stockage Indexation d’ADLS Gen2 à l’aide d’un indexeur Ajouter Lecteur des données Blob du stockage Indexation de tables à l’aide d’un indexeur Ajouter Lecteur et accès aux données Indexation de fichiers à l’aide d’un indexeur Ajouter Lecteur et accès aux données Écrire dans une base de connaissances Ajouter Contributeur aux données Blob du stockage pour les projections d’objets et de fichiers, et Lecteur et accès aux données pour les projections de tables Écrire dans un cache d’enrichissement Ajouter Contributeur aux données Blob du stockage Enregistrer l’état de la session de débogage Ajouter Contributeur aux données Blob du stockage Incorporation de données (vectorisation) à l’aide de modèles d’incorporation Azure OpenAI Ajouter Utilisateur OpenAI Cognitive Services Dans la page Membres, sélectionnez Identité managée.
Sélectionnez des membres. Dans la page Sélectionner une identité managée, choisissez votre abonnement, puis filtrez par type de service, puis sélectionnez le service. Seuls les services qui ont une identité managée seront disponibles pour sélection.
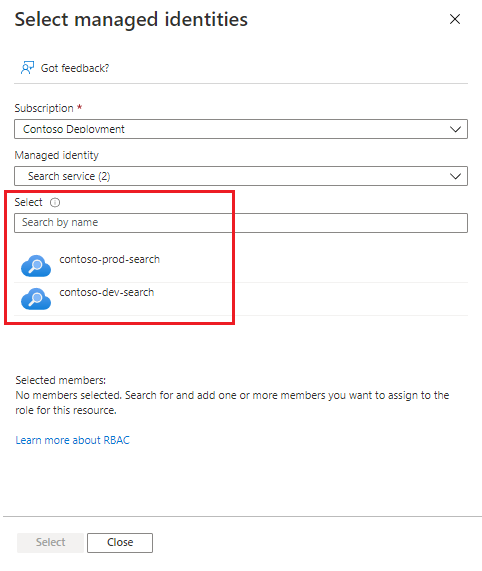
Sélectionnez Vérifier + attribuer.
Exemples de chaîne de connexion
Une fois qu’une identité gérée est définie pour le service de recherche et une attribution de rôle donnée, les connexions sortantes peuvent être modifiées pour utiliser l’ID de ressource unique de l’autre ressource Azure. Voici quelques exemples de chaînes de connexion pour différents scénarios.
Source de données blob (système) :
Une source de données d’indexeur inclut une propriété « credentials » qui détermine la façon dont la connexion est établie à la source de données. L’exemple suivant montre une chaîne de connexion qui spécifie l’ID de ressource unique d’un compte de stockage. Microsoft Entra ID authentifiera la requête à l’aide de l’identité managée affectée par le système du service de recherche. Notez que la chaîne de connexion n’inclut pas de conteneur. Dans une définition de source de données, un nom de conteneur est spécifié dans la propriété « container » (non illustrée), et non dans la chaîne de connexion.
"credentials": {
"connectionString": "ResourceId=/subscriptions/{subscription-ID}/resourceGroups/{resource-group-name}/providers/Microsoft.Storage/storageAccounts/{storage-account-name};"
}
Source de données blob (utilisateur) :
Une requête de recherche au Stockage Azure peut également être effectuée sous une identité managée affectée par l’utilisateur, actuellement en préversion. L’identité de l’utilisateur du service de recherche est spécifiée dans la propriété « identity ». Vous pouvez utiliser le portail ou la préversion de l’API REST 2021-04-30-Preview pour définir l’identité.
"credentials": {
"connectionString": "ResourceId=/subscriptions/{subscription-ID}/resourceGroups/{resource-group-name}/providers/Microsoft.Storage/storageAccounts/{storage-account-name};"
},
. . .
"identity": {
"@odata.type": "#Microsoft.Azure.Search.DataUserAssignedIdentity",
"userAssignedIdentity": "/subscriptions/{subscription-ID}/resourceGroups/{resource-group-name}/providers/Microsoft.ManagedIdentity/userAssignedIdentities/{user-assigned-managed-identity-name}"
}
Une définition de base de connaissances contient une chaîne de connexion à Stockage Azure. Dans Stockage Azure, une base de connaissances crée des projections sous forme d’objets blob et de tables. La chaîne de connexion est l’ID de ressource unique de votre compte de stockage. Notez que la chaîne n’inclut pas de conteneurs ou de tables dans le chemin d’accès. Ceux-ci sont définis dans la définition de projection incorporée, et non dans la chaîne de connexion.
"knowledgeStore": {
"storageConnectionString": "ResourceId=/subscriptions/{subscription-ID}/resourceGroups/{resource-group-name}/providers/Microsoft.Storage/storageAccounts/storage-account-name};"
}
Un indexeur crée, utilise et mémorise le conteneur utilisé pour les enrichissements mis en cache. Il n’est pas nécessaire d’inclure le conteneur dans la chaîne de connexion du cache. Vous pouvez trouver l’ID d’objet sur la page Identité de votre service de recherche dans le portail.
"cache": {
"enableReprocessing": true,
"storageConnectionString": "ResourceId=/subscriptions/{subscription-ID}/resourceGroups/{resource-group-name}/providers/Microsoft.Storage/storageAccounts/{storage-account-name};"
}
Une session de débogage s’exécute dans le portail et prend une chaîne de connexion lorsque vous démarrez la session. Vous pouvez coller une chaîne semblable à l’exemple suivant.
"ResourceId=/subscriptions/{subscription-ID}/resourceGroups/{resource-group-name}/providers/Microsoft.Storage/storageAccounts/{storage-account-name}/{container-name};",
Une compétence personnalisée cible le point de terminaison d’une fonction ou d’une application Azure qui héberge du code personnalisé. Le point de terminaison est spécifié dans la définition de compétence personnalisée. La présence de « authResourceId » indique au service de recherche qu’il doit se connecter en utilisant une identité managée, en transmettant l’ID de l’application de la fonction ou de l’application cible dans la propriété.
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"description": "A custom skill that can identify positions of different phrases in the source text",
"uri": "https://contoso.count-things.com",
"authResourceId": "<Azure-AD-registered-application-ID>",
"batchSize": 4,
"context": "/document",
"inputs": [ ... ],
"outputs": [ ...]
}
Compétence d’incorporation Azure OpenAI et vectoriseur Azure OpenAI :
Une compétence et un vectoriseur d’incorporation Azure OpenAI dans AI Search ciblent le point de terminaison d’un service Azure OpenAI hébergeant un modèle d’incorporation. Le point de terminaison est spécifié dans la définition de compétence d’incorporation Azure OpenAI et/ou dans la définition de vectoriseur Azure OpenAI. L’identité managée par le système est utilisée si configurée et si l’apikey et « authIdentity » sont vides. La propriété « authIdentity » est utilisée uniquement pour l’identité managée affectée par l’utilisateur.
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"description": "Connects a deployed embedding model.",
"resourceUri": "https://url.openai.azure.com/",
"deploymentId": "text-embedding-ada-002",
"inputs": [
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "embedding"
}
]
}
"vectorizers": [
{
"name": "my_azure_open_ai_vectorizer",
"kind": "azureOpenAI",
"azureOpenAIParameters": {
"resourceUri": "https://url.openai.azure.com",
"deploymentId": "text-embedding-ada-002"
}
}
]