Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans cet article, découvrez les étapes de définition d’un schéma pour un index de recherche et l’envoyer (push) vers un service de recherche. La création d’un index établit la structure de données physiques sur votre service de recherche. Une fois l’index créé, l’étape suivante consiste à charger l’index.
Prérequis
Écrivez des autorisations en tant que contributeur de service de recherche ou une clé API d’administration pour l’authentification basée sur des clés.
Connaissance des données que vous souhaitez indexer. Un index de recherche est basé sur du contenu externe que vous souhaitez rendre consultable. Le contenu pouvant faire l’objet d’une recherche est stocké sous forme de champs dans un index. Vous devriez avoir une idée claire des champs sources pouvant être consultés, récupérés, filtrés, à choix multiples et triés dans la Recherche Azure AI. Consultez la liste de contrôle du schéma pour obtenir de l’aide.
Vous devez avoir un champ unique dans les données sources qui peut être utilisé comme clé (ou ID) de document dans l’index.
Un emplacement d’index stable. Le déplacement d’un index existant vers un autre service de recherche n’est pas pris en charge instantanément. Consultez à nouveau les spécifications de l’application et vérifiez que votre service de recherche existant (capacité et région) sont suffisants pour répondre à vos besoins. Si vous vous appuyez sur Azure AI Services ou Azure OpenAI, choisissez une région qui fournit toutes les ressources nécessaires.
Enfin, tous les niveaux de service ont des limites d’index sur le nombre d’objets que vous pouvez créer. Par exemple, si vous expérimentez le niveau Gratuit, vous ne pouvez avoir que trois index à la fois. Dans l’index même, il existe des limites sur les vecteurs et des limites d’index sur le nombre de champs simples et complexes.
Clés de document
La création d'un index de recherche repose sur deux exigences : l'index doit avoir un nom unique dans le service de recherche et doit comporter une clé de document. L’attribut booléen key sur un champ peut être défini sur true pour indiquer quel champ fournit la clé de document.
Une clé de document est l’identificateur unique d’un document de recherche et un document de recherche est une collection de champs qui décrivent complètement quelque chose. Par exemple, si vous indexez un jeu de données de films, un document de recherche contient le titre, le genre et la durée d’un seul film. Les noms de films étant uniques dans cet ensemble de données, vous pourriez utiliser le nom du film comme clé de document.
Dans la Recherche Azure AI, une clé de document est une chaîne provenant de valeurs uniques dans la source de données qui fournit le contenu à indexer. En règle générale, un service de recherche ne génère pas de valeurs de clé. Toutefois, dans certains scénarios (comme l’indexeur de tables Azure), il synthétise des valeurs existantes afin de créer une clé unique pour les documents indexés. Un autre scénario est l’indexation un-à-plusieurs pour les données segmentées ou partitionnée, auquel cas les clés de document sont générées pour chaque bloc.
Durant l’indexation incrémentielle, où les contenus nouveaux et mis à jour sont indexés, les documents entrants avec de nouvelles clés sont ajoutés, tandis que les documents entrants avec des clés existantes sont fusionnés ou remplacés, selon que les champs d’index sont Null ou remplis.
Les points importants relatifs aux clés de document sont les suivants :
- La longueur maximale des valeurs d’un champ clé est de 1 024 caractères.
- Exactement un champ de niveau supérieur dans chaque index doit être choisi comme champ clé et doit être de type
Edm.String. - Par défaut, l'attribut
keyest défini sur false pour les champs simples et sur null pour les champs complexes.
Les champs clés peuvent être utilisés pour rechercher des documents directement et mettre à jour ou supprimer des documents spécifiques. Les valeurs des champs clés sont sensibles à la casse lors de la recherche ou de l'indexation des documents. Pour plus d’informations, consultez Get Document (REST) et Index Documents (REST).
Check-list du schéma
Utilisez cette check-list pour vous aider à prendre les décisions de conception concernant votre index de recherche.
Examinez les conventions d’affectation de noms afin que les noms d’index et de champs soient conformes aux règles d’affectation de noms.
Consultez les types de données pris en charge. Le type de données affecte la façon dont le champ est utilisé. Par exemple, le contenu numérique peut être filtré, mais ne peut pas faire l’objet d’une recherche en texte intégral. Le type de données le plus courant est
Edm.Stringpour le texte pouvant faire l’objet d’une recherche, qui est mis en jeton et interrogé à l’aide du moteur de recherche en texte intégral. Le type de données le plus courant pour un champ vectoriel estEdm.Single, mais vous pouvez également utiliser d’autres types.Identifiez une clé de document. Une clé de document est une condition requise pour les index. Il s’agit d’un seul champ de chaîne renseigné à partir d’un champ de données sources qui contient des valeurs uniques. Par exemple, si vous indexez à partir de Stockage Blob, le chemin de stockage des métadonnées est souvent utilisé comme clé de document parce qu’il identifie de manière unique chaque objet blob dans le conteneur.
Identifiez les champs dans votre source de données qui contribuent au contenu pouvant faire l’objet d’une recherche dans l’index.
Le contenu non vectoriel pouvant faire l’objet d’une recherche comprend des chaînes courtes ou longues qui sont interrogées à l’aide du moteur de recherche en texte intégral. Si le contenu est détaillé (petites phrases ou plus grands morceaux), expérimentez des analyseurs différents pour voir comment le texte est tokénisé.
Le contenu vectoriel pouvant faire l’objet d’une recherche peut être des images ou du texte (dans n’importe quelle langue) qui existe sous forme de représentation mathématique. Vous pouvez utiliser des types de données étroits ou une compression vectorielle pour réduire les champs vectoriels.
Les attributs définis sur les champs, tels que
retrievableoufilterabledéterminent les comportements de recherche et la représentation physique de votre index sur le service de recherche. Déterminer la façon dont les champs doivent être attribués est un processus itératif pour de nombreux développeurs. Pour accélérer les itérations, commencez par des échantillons de données afin de pouvoir les supprimer et les reconstruire facilement.Identifiez les champs sources qui peuvent être utilisés comme filtres. Le contenu numérique et les champs de texte courts, en particulier ceux qui ont des valeurs répétées, constituent de bons choix. Lorsque vous utilisez des filtres, n’oubliez pas :
Les filtres peuvent être utilisés dans les requêtes vectorielles et non vectorielles, mais le filtre lui-même est appliqué aux champs lisibles par l'homme (non vectoriels) de votre index.
Les champs filtrables peuvent éventuellement être utilisés dans la navigation à facettes.
Les champs filtrables sont retournés dans un ordre arbitraire et ne subissent pas de scoring de pertinence. Pensez donc à les trier également.
Pour les champs vectoriels, spécifiez une configuration de recherche vectorielle et les algorithmes utilisés pour créer des chemins de navigation et remplir l’espace d’incorporation. Pour plus d'informations, consultez Ajouter des champs vectoriels.
Les champs vectoriels ont des propriétés supplémentaires que les champs non vectoriels n’ont pas, comme les algorithmes à utiliser et la compression vectorielle.
Les champs vectoriels omettent les attributs qui ne sont pas utiles sur les données vectorielles, telles que le tri, le filtrage et la navigation à facettes.
Pour les champs non vectoriels, déterminez s’il faut utiliser l’analyseur par défaut (
"analyzer": null) ou un autre analyseur. Les analyseurs sont utilisés pour tokeniser des champs de texte lors de l’indexation et de l’exécution des requêtes.Pour les chaînes multilingues, envisagez l’utilisation d’un analyseur de langue.
Pour les chaînes avec trait d’union ou les caractères spéciaux, réfléchissez à l’utilisation d’analyseurs spécialisés. Un analyseur mot clé traite par exemple tout le contenu d’un champ comme un jeton unique. Ce comportement est utile pour les données comme les codes postaux, les ID et certains noms de produit. Pour plus d’informations, consultez Recherche de termes partiels et modèles avec des caractères spéciaux.
Remarque
La recherche en texte intégral est effectuée sur les termes qui sont tokenisés pendant l’indexation. Si vos requêtes ne retournent pas les résultats attendus, testez la segmentation du texte en unités lexicales pour vérifier que la chaîne recherchée existe réellement. Vous pouvez essayer différents analyseurs sur des chaînes pour voir comment les jetons sont générés pour différents analyseurs.
Configurer les définitions de champs
La collection de champs définit la structure d’un document de recherche. Tous les champs ont un nom, un type de données et des attributs.
Définir un champ comme recherchable, filtrable, triable ou à choix multiples a un impact sur la taille de l'index et les performances des requêtes. Ne définissez pas ces attributs sur les champs qui ne sont pas destinés à être référencés dans les expressions de requête.
Si un champ n’est pas défini comme recherchable, filtrable, triable ou à choix multiples, le champ ne peut pas être référencé dans une expression de requête. Cela est souhaitable pour les champs qui ne sont pas utilisés dans les requêtes, mais qui sont nécessaires dans les résultats de recherche.
Les API REST appliquent une attribution par défaut basée sur les types de données, ce qui est également utilisé par les Assistants d’importation dans le portail Azure. Les kits de développement logiciel (SDK) Azure n’ont pas de valeurs par défaut, mais ils ont des sous-classes de champ qui incorporent des propriétés et des comportements, tels que SearchableField pour les chaînes et SimpleField pour les types primitifs.
Les attributions de champs par défaut pour les API REST sont résumées dans le tableau suivant.
| Type de données | Peut faire l’objet d’une recherche | Récupérable | Filtrable | À choix multiples | Triable | Stocké |
|---|---|---|---|---|---|---|
Edm.String |
✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Collection(Edm.String) |
✅ | ✅ | ✅ | ✅ | ❌ | ✅ |
Edm.Boolean |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.Int32Edm.Int64Edm.Double |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.DateTimeOffset |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.GeographyPoint |
✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
Edm.ComplexType |
✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Collection(Edm.Single) et tous les autres types de champs vectoriels |
✅ | ✅ ou ❌ | ❌ | ❌ | ❌ | ✅ |
Les champs de type chaîne peuvent également être associés à des analyseurs et à des cartes de synonymes. Les champs de type Edm.String qui sont filtrables, triables ou à choix multiple ne peuvent pas dépasser 32 Ko de longueur. Cela est dû au fait que les valeurs de ces champs sont traités comme un terme de recherche, et que la longueur maximale d'un tel terme dans la Recherche Azure AI est de 32 kilo-octets. Si vous devez stocker plus de texte que cela dans un champ de chaîne unique, vous devez définir explicitement des éléments filtrables, triables et à choix multiples pour false dans votre définition d’index.
Les champs vectoriels doivent être associés aux dimensions et profils vectoriels. La récupération est activée par défaut si vous ajoutez le champ vectoriel à l’aide de l’Assistant Importation et vectorisation des données dans le portail Azure. Si vous utilisez l’API REST, elle a la valeur false.
Les attributs de champ sont décrits dans le tableau suivant.
| Attribut | Descriptif |
|---|---|
| nom | Obligatoire. Définit le nom du champ, qui doit être unique dans la collection de champs de l'index ou du champ parent. |
| type | Obligatoire. Définit le type de données du champ. Les champs peuvent être simples ou complexes. Les champs simples sont de types primitifs, comme Edm.String pour le texte ou les Edm.Int32 pour les entiers. Les champs complexes peuvent avoir des sous-champs qui sont eux-mêmes simples ou complexes. Cela vous permet de modéliser des objets et des tableaux d’objets, ce qui vous permet de charger la plupart des structures d’objets JSON dans votre index. Consultez Types de données pris en charge pour obtenir la liste complète des types pris en charge. |
| clé | Obligatoire. Définissez cet attribut sur true pour indiquer que les valeurs d’un champ identifient de manière unique les documents dans l’index. Pour plus d’informations, consultez Clés de document dans cet article. |
| Récupérable | Indique si le champ peut être retourné dans un résultat de recherche. Définissez cet attribut sur false si vous souhaitez utiliser un champ en tant que mécanisme de filtrage, de tri ou de scoring, mais ne souhaitez pas que le champ soit visible pour l’utilisateur final. Cet attribut doit être true pour les champs clés, et il doit être null pour les champs complexes. Cet attribut peut être modifié sur les champs existants. Définir l'attribut retrievable sur true n’entraîne aucune augmentation des exigences de stockage d’index. La valeur par défaut est true pour les champs simples et null pour les champs complexes. |
| peut faire l’objet d’une recherche | Indique si le champ peut faire l’objet d’une recherche en texte intégral et peut être référencé dans les requêtes de recherche. Cela signifie qu’il fait l’objet d’une analyse lexicale, telle qu’une césure de mots lors de l’indexation. Si vous définissez un champ avec possibilité de recherche sur une valeur comme « journée ensoleillée », cette valeur est normalisée au niveau interne en jetons individuels « journée » et « ensoleillée ». Cela permet d'effectuer des recherches en texte intégral de ces termes. Les champs de type Edm.String ou Collection(Edm.String) peuvent faire l’objet d’une recherche par défaut. Cet attribut doit être défini sur false pour les champs simples d’autres types de données non chaînes, et il doit être sur null pour les champs complexes. Un champ pouvant faire l’objet d’une recherche consomme un espace supplémentaire dans votre index, car la Recherche Azure AI traite le contenu de ces champs et les organise dans des structures de données auxiliaires pour une recherche performante. Si vous voulez économiser de l'espace dans votre index et que vous n'avez pas besoin d'inclure un champ dans les recherches, définissez searchable sur false. Pour plus d’informations, consultez Fonctionnement de la recherche en texte intégral dans la Recherche Azure AI. |
| Filtrables | Indique si le champ doit être référencé dans les requêtes $filter. Le champ pouvant être filtré diffère de celui pouvant faire l’objet d’une recherche dans la façon dont les chaînes sont gérées. Les champs de type Edm.String ou Collection(Edm.String) qui sont filtrables ne subissent pas d’analyse lexicale, les comparaisons sont donc destinées à des correspondances exactes uniquement. Par exemple, si vous définissez un tel champ f sur « Sunny day », $filter=f eq 'sunny' ne trouvera aucune correspondance, mais $filter=f eq 'Sunny day' en trouvera une. Cet attribut doit être null pour les champs complexes. La valeur par défaut est true pour les champs simples et null pour les champs complexes. Pour réduire la taille de l’index, affectez à cet attribut la valeur false sur les champs sur lesquelles vous n’appliquez pas de filtre. |
| sortable | Indique si le champ doit être référencé dans les expressions $orderby. Par défaut, la Recherche Azure AI trie les résultats par score, mais dans de nombreuses expériences, les utilisateurs souhaitent trier par les champs dans les documents. Un champ simple peut être triable uniquement s’il est à valeur unique (il a une valeur unique dans l’étendue du document parent). Les champs de collection simple ne peuvent pas être triables, car ils sont à valeurs multiples. Les sous-champs simples de collections complexes sont également à valeurs multiples et ne peuvent donc pas être triables. C’est vrai, qu’il s’agisse d’un champ parent immédiat ou d’un champ ancêtre, c’est la collection complexe. Les champs complexes ne peuvent pas être triables et l’attribut triable doit être null pour ces champs. La valeur par défaut pour sortable est true pour les champs simples à valeur unique, false pour les champs simples à valeurs multiples et null pour les champs complexes. |
| facetable | Indique si le champ doit être référencé dans les requêtes de facettes. Généralement utilisé dans une présentation des résultats de recherche qui inclut le nombre d'accès par catégorie (par exemple, vous recherchez des appareils photo numériques et regardez le nombre d'accès par marque, mégapixels, prix, etc.). Cet attribut doit être null pour les champs complexes. Les champs de type Edm.GeographyPoint ou Collection(Edm.GeographyPoint) ne peuvent pas être à choix multiples. La valeur par défaut est true pour tous les autres champs simples. Pour réduire la taille de l’index, affectez à cet attribut la valeur false sur les champs sur lesquelles vous n’appliquez pas de choix multiples. |
| analyseur | Définit l’analyseur lexical pour la tokenisation des chaînes pendant les opérations d'indexation et de requête. Les valeurs valides pour cette propriété incluent les analyseurs de langage, les analyseurs intégréset les analyseurs personnalisés. Par défaut, il s’agit de standard.lucene. Cet attribut ne peut être utilisé qu’avec des champs de chaîne pouvant faire l’objet d’une recherche et ne peut pas être défini avec searchAnalyzer ou indexAnalyzer. Une fois l’analyseur choisi et le champ créé dans l’index, il ne peut pas être modifié pour le champ. Doit être null pour les champs complexes. |
| searchAnalyzer | Définissez cette propriété avec indexAnalyzer pour spécifier différents analyseurs lexicaux pour l’indexation et les requêtes. Si vous utilisez cette propriété, définissez l’analyseur sur null et vérifiez qu’indexAnalyzer est défini sur une valeur autorisée. Les valeurs valides pour cette propriété incluent des analyseurs intégrés et des analyseurs personnalisés. Cet attribut ne peut être utilisé qu’avec des champs pouvant faire l’objet d’une recherche. L’analyseur de recherche peut être mis à jour sur un champ existant, car il est utilisé uniquement au moment de la requête. Doit être null pour les champs complexes]. |
| indexAnalyzer | Définissez cette propriété avec searchAnalyzer afin de spécifier différents analyseurs lexicaux pour l’indexation et les requêtes. Si vous utilisez cette propriété, définissez l’analyseur sur null et vérifiez que searchAnalyzer est défini sur une valeur autorisée. Les valeurs valides pour cette propriété incluent des analyseurs intégrés et des analyseurs personnalisés. Cet attribut ne peut être utilisé qu’avec des champs pouvant faire l’objet d’une recherche. Une fois l’analyseur d’index choisi, il ne peut pas être modifié pour le champ. Doit être null pour les champs complexes. |
| synonymMaps | Une liste des noms des cartes de synonymes à associer à ce champ. Cet attribut ne peut être utilisé qu’avec des champs pouvant faire l’objet d’une recherche. Actuellement, une seule carte de synonymes par champ est prise en charge. Attribuer une carte de synonymes à un champ garantit que les termes de requête ciblant ce champ sont étendus au moment de la requête en utilisant les règles définies dans la carte de synonymes. Cet attribut peut être modifié sur les champs existants. Doit être null ou une collection vide pour les champs complexes. |
| champs | Liste des sous-champs s’il s’agit d’un champ de type Edm.ComplexType ou Collection(Edm.ComplexType). Doit être null ou vide pour les champs simples. Consultez Comment modéliser des types de données complexes dans Recherche Azure AI pour plus d’informations sur la façon et le moment d’utiliser des sous-champs. |
Création d'un index
Quand vous êtes prêt à créer l’index, utilisez un client de recherche qui peut envoyer la demande. Vous pouvez utiliser le Portail Azure ou des API REST pour les premières étapes de développement et les tests de preuve de concept. Sinon, vous pouvez utiliser les Kits de développement logiciel (SDK) Azure.
Pendant le développement, prévoyez des régénérations fréquentes. Comme les structures physiques sont créées dans le service, il est nécessaire de supprimer et de recréer les index pour la plupart des modifications. Vous pouvez envisager de travailler sur une partie de vos données pour regénérer plus rapidement.
La conception d’index via le Portail Microsoft Azure applique des exigences et des règles de schéma pour des types de données spécifiques, telles que l’interdiction des fonctionnalités de recherche en texte intégral sur les champs numériques.
Connectez-vous au portail Azure.
Vérifiez l’espace disponible. Les services de recherche sont soumis à nombre maximal d’index qui varie par niveau de service. Vérifiez que vous avez de la place pour un deuxième index.
Dans la page Vue d’ensemble du service de recherche, choisissez l’une des options proposées pour créer un index de recherche :
- Ajouter un index (éditeur incorporé pour la spécification d’un schéma d’index)
- Assistants d’importation
L’Assistant est un workflow de bout en bout qui crée un indexeur, une source de données et un index terminé. Il charge également les données. Si ce n’est pas ce que vous voulez, utilisez plutôt l’option Ajouter un index.
La capture d’écran suivante met en évidence où Ajouter un index, Importer des données et l’assistant Importer et vectoriser des données apparaissent sur la barre de commandes.
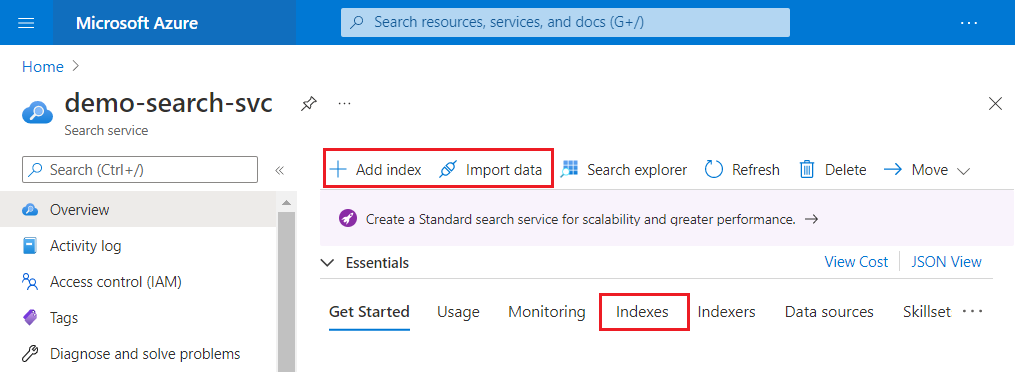
Une fois qu’un index est créé, vous pouvez le retrouver sur la page Indexes depuis le volet gauche.
Conseil
Après avoir créé un index dans le Portail Microsoft Azure, vous pouvez copier la représentation JSON et l’ajouter à votre code d’application.
Définir corsOptions pour les requêtes Cross-Origin
Les schémas d’index incluent une section pour la définition de corsOptions. Par défaut, le code JavaScript côté client ne peut pas appeler d’API, car les navigateurs empêchent toutes les requêtes cross-origin. Pour autoriser les requêtes cross-origin à parvenir à votre index, activez CORS (Cross-Origin Resource Sharing) en définissant l’attribut corsOptions. Pour des raisons de sécurité, seules les API de requête prennent en charge CORS.
"corsOptions": {
"allowedOrigins": [
"*"
],
"maxAgeInSeconds": 300
Les propriétés suivantes peuvent être définies pour CORS :
allowedOrigins (obligatoire) : il s’agit d’une liste d’origines autorisées à accéder à votre index. Le code JavaScript servi à partir de ces origines est autorisé à interroger votre index (en supposant que l’appelant fournit une clé valide ou dispose d’autorisations). Chaque origine se présente généralement sous la forme
protocol://<fully-qualified-domain-name>:<port>, bien que<port>soit souvent omis. Pour plus d’informations, consultez la page Cross-origin resource sharing (Wikipedia).Si vous voulez autoriser l'accès à toutes les origines, incluez uniquement l’élément
*dans le tableau allowedOrigins. Si cette pratique est déconseillée pour les services de recherche de production, elle est souvent utile pour le développement et le débogage.maxAgeInSeconds (facultatif) : les navigateurs utilisent cette valeur pour déterminer la durée (en secondes) de mise en cache des réponses CORS préliminaires. Il doit s'agir d'un entier non négatif. Une période de mise en cache plus longue offre de meilleures performances, mais elle étend la durée nécessaire pour qu’une stratégie CORS prenne effet. Si cette valeur n’est pas définie, une durée par défaut de cinq minutes est utilisée.
Mises à jour autorisées sur des index existants
Créer un index crée des structures de données physiques (fichiers et index inversés) sur votre service de recherche. Une fois l’index créé, votre capacité à effectuer des modifications à l’aide de Créer ou mettre à jour un index dépend du fait que vos modifications invalident ou non ces structures physiques. La plupart des attributs de champ ne peuvent pas être modifiés une fois que le champ est créé dans votre index.
Pour réduire l’activité dans le code de l’application, vous pouvez créer un alias d’index qui sert de référence stable à l’index de recherche. Au lieu de mettre à jour votre code avec des noms d’index, vous pouvez mettre à jour un alias d’index pour qu’il pointe vers des versions d’index plus récentes.
Pour réduire l’attrition dans le processus de conception, le tableau suivant décrit les éléments fixes et flexibles dans le schéma. La modification d’un élément fixe nécessite la reconstruction de l’index, alors que les éléments flexibles peuvent être modifiés à tout moment sans impacter l’implémentation physique. Pour plus d’informations, consultez Mettre à jour ou reconstruire un index.
| Élément | Possibilité de mise à jour ? |
|---|---|
| Nom | Non |
| Clé | Non |
| Noms et types de champs | Non |
| Attributs de champ (consultable, filtrable, à choix multiples, triable) | Non |
| Attribut de champ (récupérable) | Oui |
| Stocké (s’applique aux vecteurs) | Non |
| Analyseur | Vous pouvez ajouter et modifier des analyseurs personnalisés dans l’index. En ce qui concerne les affectations de l’analyseur aux champs de chaîne, vous pouvez uniquement modifier searchAnalyzer. Toutes les autres affectations et modifications requièrent une reconstruction. |
| Profils de score | Oui |
| Générateurs de suggestions | Non |
| Partage des ressources cross-origin (CORS) | Oui |
| Chiffrement | Oui |
| Mappages de synonymes | Oui |
| Configuration sémantique | Oui |
Étapes suivantes
Utilisez les liens suivants pour en savoir plus sur les fonctionnalités spécialisées qui peuvent être ajoutées à un index :
- Ajouter des champs vectoriels et des profils vectoriels
- Ajouter des profils de scoring
- Ajouter un classement sémantique
- Ajouter des suggestions
- Ajouter des mappages de synonymes
- Ajouter des analyseurs
- Ajouter un chiffrement
Utilisez ces liens pour charger ou mettre à jour un index :