Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Recherche Azure AI prend en charge l’importation, l’analyse et l’indexation de données à partir de plusieurs sources de données dans un index de recherche consolidé unique.
Ce didacticiel C# utilise la bibliothèque cliente Azure.Search.Documents dans le Kit de développement logiciel (SDK) Azure pour .NET pour indexer des exemples de données d’hôtel à partir d’une instance Azure Cosmos DB. Vous fusionnez ensuite les données avec les détails des chambres d’hôtel extraites des documents Stockage Blob Azure. Le résultat est un index combiné de recherche d’hôtel contenant des documents d’hôtel, avec des chambres comme types de données complexes.
Dans ce tutoriel, vous allez :
- Charger des exemples de données dans des sources de données
- Identifier la clé de document
- Définir et créer l’index
- Indexer les données d’hôtels issues d’Azure Cosmos DB
- Fusionner les données de chambre d'hôtel à partir du Stockage Blob
Vue d’ensemble
Ce tutoriel utilise Azure.Search.Documents pour créer et exécuter plusieurs indexeurs. Vous chargez des exemples de données vers deux sources de données Azure et configurez un indexeur qui extrait les deux sources pour remplir un index de recherche unique. Les deux jeux de données doivent avoir une valeur commune pour prendre en charge la fusion. Dans ce tutoriel, ce champ est un ID. Tant qu’il existe un champ commun pour prendre en charge le mappage, un indexeur peut fusionner des données à partir de ressources disparates : données structurées à partir d’Azure SQL, données non structurées à partir du stockage Blob ou toute combinaison de sources de données prises en charge sur Azure.
Une version terminée du code de ce tutoriel se trouve dans le projet suivant :
Prérequis
- Un compte Azure avec un abonnement actif. Créez un compte gratuitement.
- Un compte Azure Cosmos DB pour NoSQL.
- Un compte de stockage Azure.
- Un service Recherche d’IA Azure.
- Visual Studio.
Remarque
Vous pouvez utiliser un service de recherche gratuit pour ce tutoriel. Le niveau gratuit vous limite à trois index, trois indexeurs et trois sources de données. Ce didacticiel crée une occurrence de chaque élément. Avant de commencer, assurez-vous que vous disposez d’une place sur votre service pour accepter les nouvelles ressources.
Préparer les services
Ce tutoriel utilise Recherche Azure AI pour l’indexation et les requêtes, Azure Cosmos DB pour le premier jeu de données et stockage Blob Azure pour le deuxième jeu de données.
Si possible, créez tous les services dans la même région et le même groupe de ressources pour des raisons de proximité et de facilité de gestion. Dans la pratique, vos services peuvent se trouver dans n’importe quelle région.
Cet exemple utilise deux petits ensembles de données décrivant sept hôtels fictifs. Un ensemble décrit les hôtels eux-mêmes et sera chargé dans une base de données Azure Cosmos DB. L’autre ensemble contient les détails de la chambre d’hôtel et est fourni sous la forme de sept fichiers JSON distincts à charger dans stockage Blob Azure.
Démarrer avec Azure Cosmos DB
Accédez à votre compte Azure Cosmos DB dans le portail Azure.
Dans le volet gauche, sélectionnez Explorateur de données.
Sélectionnez Nouvel conteneur>Nouvelle base de données.
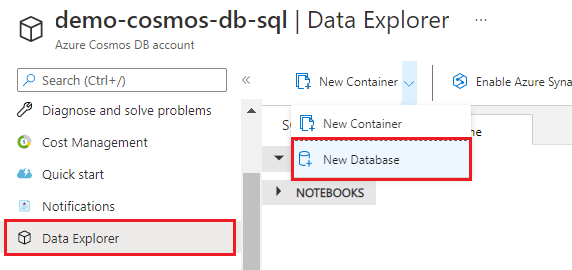
Entrez hotel-rooms-db pour le nom. Acceptez les valeurs par défaut pour les paramètres restants.
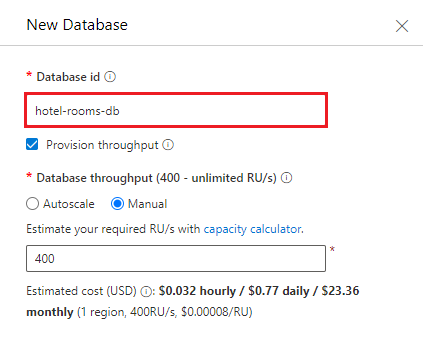
Créez un conteneur qui cible la base de données que vous avez créée précédemment. Entrez les hôtels pour le nom du conteneur et /HotelId pour la clé de partition.
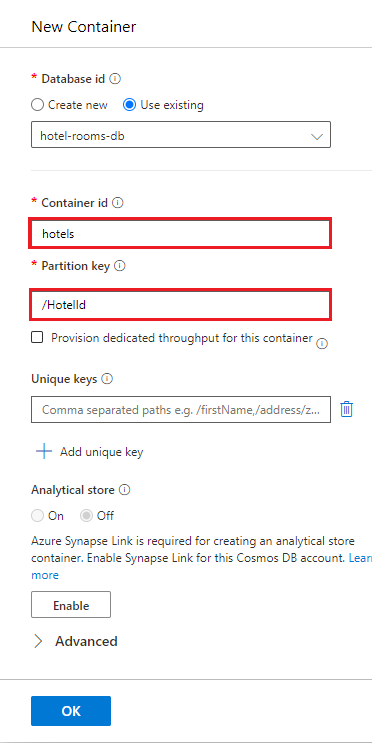
Sélectionnez les éléments des hôtels>, puis sélectionnez Charger un élément dans la barre de commandes.
Chargez le fichier JSON à partir du
cosmosdbdossier dans plusieurs sources de données/v11.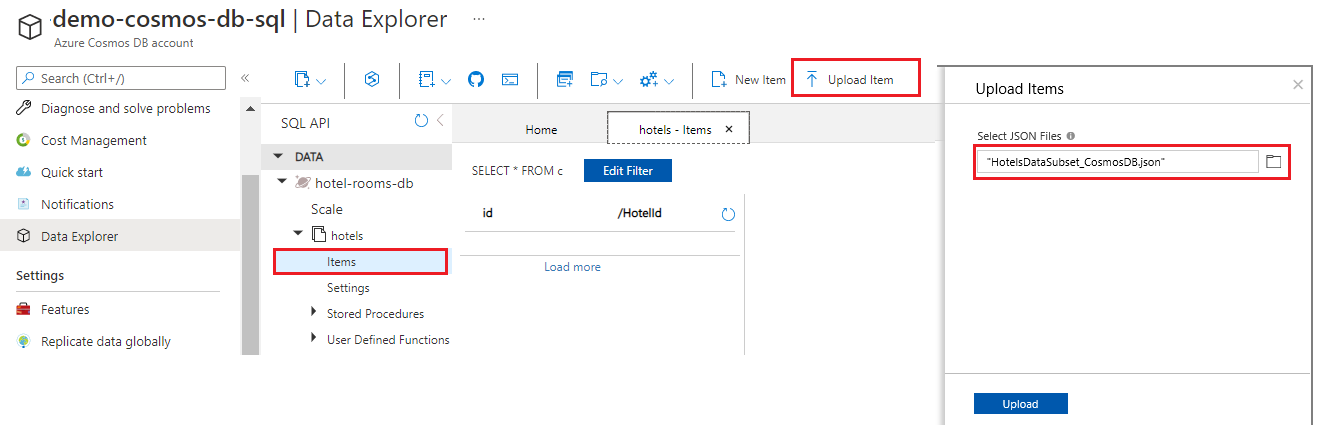
Utilisez le bouton Actualiser pour actualiser votre vue des éléments de la collection d’hôtels. Vous devriez voir sept nouveaux documents de base de données listés.
Dans le volet de gauche, sélectionnez Paramètres>Clés.
Prenez note d'une chaîne de connexion. Vous avez besoin de cette valeur pour appsettings.json dans une étape ultérieure. Si vous n’avez pas utilisé le nom de base de données hotel-rooms-db suggéré, copiez également le nom de la base de données.
Stockage Blob Azure
Accédez à votre compte Stockage Azure dans le portail Azure.
Dans le volet gauche, sélectionnezstockage de données>Conteneurs.
Créez un conteneur d’objets blob nommé hotel-rooms pour stocker les exemples de fichiers JSON des chambres d’hôtel. Vous pouvez définir le niveau d’accès sur n’importe quelle valeur valide.
Ouvrez le conteneur, puis sélectionnez Charger dans la barre de commandes.
Chargez les sept fichiers JSON à partir du
blobdossier dans plusieurs sources de données/v11.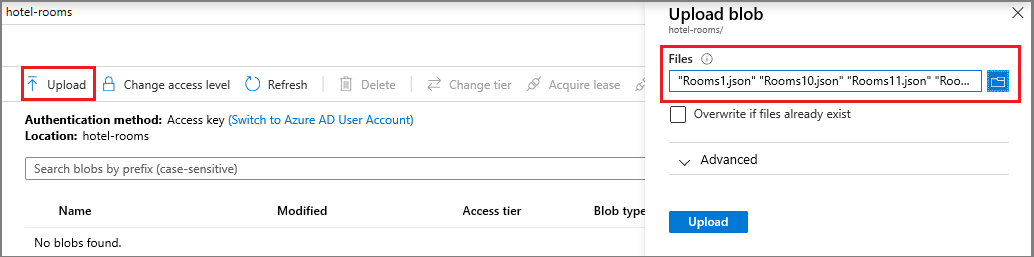
Dans le volet gauche, sélectionnez Sécurité +> réseau.
Notez le nom du compte et une chaîne de connexion. Vous avez besoin des deux valeurs pour appsettings.json dans une étape ultérieure.
Recherche Azure AI
Le troisième composant est la Recherche Azure AI, que vous pouvez créer dans le Portail Azure ou trouver un service de recherche existant dans vos ressources Azure.
Copier une clé d’administration et une URL pour Recherche d’IA Azure
Pour vous authentifier auprès de votre service de recherche, vous avez besoin de l’URL du service et d’une clé d’accès. La présence d’une clé valide établit une approbation par demande entre l’application qui envoie la demande et le service qui le gère.
Accédez à votre service Search dans le Portail Microsoft Azure.
Dans le volet gauche, sélectionnez Vue d’ensemble.
Prenez note de l’URL, qui doit ressembler à
https://my-service.search.windows.net.Dans le volet de gauche, sélectionnez Paramètres>Clés.
Prenez note d’une clé d’administration pour obtenir des droits complets sur le service. Il existe deux clés d’administration interchangeables, fournies pour assurer la continuité de l’activité au cas où vous deviez en remplacer une. Vous pouvez utiliser l’une ou l’autre des clés pour l’ajout, la modification et la suppression d’objets.
Configurer votre environnement
Ouvrez le
AzureSearchMultipleDataSources.slnfichier à partir de plusieurs sources de données/v11 dans Visual Studio.Dans l’Explorateur de solutions, cliquez avec le bouton droit sur le projet, puis sélectionnez Gérer les packages NuGet pour la solution....
Sous l’onglet Parcourir, recherchez et installez les packages suivants :
Azure.Search.Documents (version 11.0 ou ultérieure)
Microsoft.Extensions.Configuration
Microsoft.Extensions.Configuration.Json
Dans l’Explorateur de solutions, modifiez le
appsettings.jsonfichier avec les informations de connexion que vous avez collectées au cours des étapes précédentes.{ "SearchServiceUri": "<YourSearchServiceURL>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "BlobStorageAccountName": "<YourBlobStorageAccountName>", "BlobStorageConnectionString": "<YourBlobStorageConnectionString>", "CosmosDBConnectionString": "<YourCosmosDBConnectionString>", "CosmosDBDatabaseName": "hotel-rooms-db" }
Mapper les champs clés
La fusion de contenu nécessite que les deux flux de données ciblent les mêmes documents dans l’index de recherche.
Dans Recherche Azure AI, le champ de clé identifie chaque document de façon univoque. Chaque index de recherche doit comporter exactement un champ de clé de type Edm.String. Ce champ de clé doit être présent pour chaque document d’une source de données qui est ajouté à l’index. (il constitue en fait le seul champ obligatoire).
Lors de l’indexation de données à partir de plusieurs sources de données, assurez-vous que chaque ligne ou document entrant contient une clé de document commune. Cela vous permet de fusionner des données de deux documents sources physiquement distincts dans un nouveau document de recherche dans l’index combiné.
Il nécessite souvent une planification frontale pour identifier une clé de document significative pour votre index et s’assurer qu’il existe dans les deux sources de données. Dans cette démonstration, la clé HotelId de chaque hôtel dans Azure Cosmos DB est également présente dans les blobs JSON des données des chambres dans Stockage Blob.
Les indexeurs Recherche Azure AI peuvent utiliser des mappages de champs pour renommer ou même remettre en forme des champs de données pendant le processus d’indexation, afin que les données sources puissent être redirigées vers le champ d’index correct. Par exemple, dans Azure Cosmos DB, l’identificateur d’hôtel est appelé HotelId, mais dans les fichiers blob JSON des chambres d’hôtel, l’identificateur de l’hôtel est nommé Id. Le programme gère cette discordance en mappant le champ Id des blobs au champ de clé HotelId dans l’indexeur.
Remarque
Dans la plupart des cas, les clés de document générées automatiquement, telles que celles créées par défaut par certains indexeurs, ne font pas de clés de document correctes pour les index combinés. En général, utilisez une valeur de clé unique significative qui existe déjà dans vos sources de données ou qui peut être facilement ajoutée.
Explorer le code
Lorsque les paramètres de données et de configuration sont en place, l’exemple de programme doit AzureSearchMultipleDataSources.sln être prêt à être généré et exécuté.
Cette application console C#/.NET simple effectue les tâches suivantes :
- Crée un index basé sur la structure de données de la classe Hôtel C#, qui fait également référence aux classes Address et Room.
- Elle crée une source de données et un indexeur qui mappe les données Azure Cosmos DB aux champs d’index. Ce sont tous deux des objets dans Recherche Azure AI.
- Exécute l’indexeur pour charger des données d’hôtel à partir d’Azure Cosmos DB.
- Elle crée une seconde source de données et un indexeur qui mappe les données blob JSON aux champs d’index.
- Exécute le deuxième module d'indexation pour charger les données de chambre d'hôtel depuis le stockage Blob.
Avant d’exécuter le programme, prenez une minute pour étudier le code, la définition d’index et la définition de l’indexeur. Le code qui convient se trouve dans deux fichiers :
-
Hotel.cscontient le schéma qui définit l’index. -
Program.cscontient des fonctions qui créent l’index Recherche Azure AI, les sources de données et les indexeurs, et chargent les résultats combinés dans l’index.
Création d'un index
Cet exemple de programme utilise CreateIndexAsync pour définir et créer un index Recherche Azure AI. Il tire parti de la classe FieldBuilder pour générer une structure d’index à partir d’une classe de modèle de données C#.
Le modèle de données est défini par la classe Hotel, qui contient également des références aux classes Address et Room. La classe FieldBuilder explore plusieurs définitions de classe pour générer une structure de données complexes pour l’index. Des étiquettes de métadonnées sont utilisées pour définir les attributs de chaque champ, par exemple s’il peut faire l’objet d’une recherche ou d’un tri.
Le programme supprime tout index existant du même nom avant de en créer un, au cas où vous souhaitez exécuter cet exemple plusieurs fois.
Les extraits de code suivants du Hotel.cs fichier affichent des champs uniques, suivis d’une référence à une autre classe de modèle de données, Room[], qui à son tour est définie dans le Room.cs fichier (non affiché).
. . .
[SimpleField(IsFilterable = true, IsKey = true)]
public string HotelId { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true)]
public string HotelName { get; set; }
. . .
public Room[] Rooms { get; set; }
. . .
Dans le Program.cs fichier, une SearchIndex est définie avec un nom et une collection de champs générée par la FieldBuilder.Build méthode, puis créée comme suit :
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address and Room classes are referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Créer l’indexeur et la source de données Azure Cosmos DB
Le programme principal inclut la logique permettant de créer la source de données Azure Cosmos DB pour les données des hôtels.
Tout d’abord, il concatène le nom de la base de données Azure Cosmos DB à la chaîne de connexion. Il définit ensuite un objet SearchIndexerDataSourceConnection .
private static async Task CreateAndRunCosmosDbIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
// Append the database name to the connection string
string cosmosConnectString =
configuration["CosmosDBConnectionString"]
+ ";Database="
+ configuration["CosmosDBDatabaseName"];
SearchIndexerDataSourceConnection cosmosDbDataSource = new SearchIndexerDataSourceConnection(
name: configuration["CosmosDBDatabaseName"],
type: SearchIndexerDataSourceType.CosmosDb,
connectionString: cosmosConnectString,
container: new SearchIndexerDataContainer("hotels"));
// The Azure Cosmos DB data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(cosmosDbDataSource);
Une fois la source de données créée, le programme configure un indexeur Azure Cosmos DB nommé hotel-rooms-cosmos-indexer.
Le programme met à jour tous les indexeurs existants portant le même nom, en remplaçant l’indexeur existant par le contenu du code précédent. Il comprend également des actions de réinitialisation et d’exécution, au cas où vous souhaiteriez exécuter cet exemple plusieurs fois.
L’exemple suivant définit une planification pour l’indexeur afin qu’il s’exécute une fois par jour. Si vous ne souhaitez pas que l’indexeur soit automatiquement réexécuté à l’avenir, vous pouvez supprimer la propriété de planification de cet appel.
SearchIndexer cosmosDbIndexer = new SearchIndexer(
name: "hotel-rooms-cosmos-indexer",
dataSourceName: cosmosDbDataSource.Name,
targetIndexName: indexName)
{
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Indexers keep metadata about how much they have already indexed.
// If we already ran the indexer, it "remembers" and does not run again.
// To avoid this, reset the indexer if it exists.
try
{
await indexerClient.GetIndexerAsync(cosmosDbIndexer.Name);
// Reset the indexer if it exists.
await indexerClient.ResetIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
// If the indexer does not exist, 404 will be thrown.
}
await indexerClient.CreateOrUpdateIndexerAsync(cosmosDbIndexer);
Console.WriteLine("Running Azure Cosmos DB indexer...\n");
try
{
// Run the indexer.
await indexerClient.RunIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 429)
{
Console.WriteLine("Failed to run indexer: {0}", ex.Message);
}
Cet exemple inclut un bloc try-catch simple pour signaler les erreurs susceptibles de se produire pendant l’exécution.
Une fois l’indexeur Azure Cosmos DB exécuté, l’index de recherche contient un ensemble complet d’exemples de documents d’hôtel. Toutefois, le champ chambres de chaque hôtel est un tableau vide, car la source de données Azure Cosmos DB omet les détails des chambres. Ensuite, le programme extrait du Stockage Blob pour charger et fusionner les données relatives à la salle.
Créer une source de données et un indexeur de stockage Blob
Pour obtenir les détails de la salle, le programme configure d’abord une source de données Stockage Blob pour référencer un ensemble de fichiers blob JSON individuels.
private static async Task CreateAndRunBlobIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
SearchIndexerDataSourceConnection blobDataSource = new SearchIndexerDataSourceConnection(
name: configuration["BlobStorageAccountName"],
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["BlobStorageConnectionString"],
container: new SearchIndexerDataContainer("hotel-rooms"));
// The blob data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(blobDataSource);
Une fois la source de données créée, le programme configure un indexeur d’objets blob nommé hotel-rooms-blob-indexer, comme indiqué ci-dessous.
Les objets blob JSON contiennent un champ de clé nommé Id au lieu de HotelId . Le code utilise la classe FieldMapping pour indiquer à l’indexeur de rediriger la valeur du champ Id vers la clé de document HotelId dans l’index.
Les indexeurs de stockage Blob peuvent utiliser IndexingParameters pour spécifier un mode d’analyse. Vous devez définir différents modes d’analyse selon que les objets blob représentent un document unique ou plusieurs documents au sein du même objet blob. Dans cet exemple, comme chaque objet blob représente un document JSON unique, le code utilise le mode d’analyse json. Pour plus d’informations sur les paramètres d’analyse d’indexeur pour les objets blob JSON, consultez Indexer des objets blob JSON.
Cet exemple définit une planification pour l’indexeur afin qu’il s’exécute une fois par jour. Si vous ne souhaitez pas que l’indexeur soit automatiquement réexécuté à l’avenir, vous pouvez supprimer la propriété de planification de cet appel.
IndexingParameters parameters = new IndexingParameters();
parameters.Configuration.Add("parsingMode", "json");
SearchIndexer blobIndexer = new SearchIndexer(
name: "hotel-rooms-blob-indexer",
dataSourceName: blobDataSource.Name,
targetIndexName: indexName)
{
Parameters = parameters,
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Map the Id field in the Room documents to the HotelId key field in the index
blobIndexer.FieldMappings.Add(new FieldMapping("Id") { TargetFieldName = "HotelId" });
// Reset the indexer if it already exists
try
{
await indexerClient.GetIndexerAsync(blobIndexer.Name);
await indexerClient.ResetIndexerAsync(blobIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404) { }
await indexerClient.CreateOrUpdateIndexerAsync(blobIndexer);
try
{
// Run the indexer.
await searchService.Indexers.RunAsync(blobIndexer.Name);
}
catch (CloudException e) when (e.Response.StatusCode == (HttpStatusCode)429)
{
Console.WriteLine("Failed to run indexer: {0}", e.Response.Content);
}
Étant donné que l’index est déjà rempli avec des données d’hôtel de la base de données Azure Cosmos DB, l’indexeur d’objets blob met à jour les documents existants dans l’index et ajoute les détails de la salle.
Remarque
Si vous avez les mêmes champs non clés dans les deux sources de données et que les données de ces champs ne correspondent pas, l’index contient les valeurs de l’indexeur exécuté le plus récemment. Dans notre exemple, les deux sources de données contiennent un HotelName champ. Si, pour une raison quelconque, les données de ce champ sont différentes, pour les documents ayant la même valeur de clé, les HotelName données de la source de données indexée la plus récente sont la valeur stockée dans l’index.
Rechercher
Après avoir exécuté le programme, vous pouvez explorer l’index de recherche renseigné à l’aide de l’Explorateur de recherche dans le portail Azure.
Accédez à votre service Search dans le Portail Microsoft Azure.
Dans le volet gauche, sélectionnez Gestion de la recherche>Index.
Sélectionnez hotel-rooms-sample dans la liste des index.
Sous l’onglet Explorateur de recherche , entrez une requête pour un terme tel que
Luxury.Vous devez voir au moins un document dans les résultats. Ce document doit contenir une liste d'objets de salle dans son tableau
Rooms.
Réinitialiser et réexécuter
Dans les premières étapes expérimentales de développement, l’approche la plus pratique pour les itérations de conception consiste à supprimer les objets d’Recherche Azure AI et à autoriser votre code à les reconstruire. Les noms des ressources sont uniques. La suppression d’un objet vous permet de le recréer en utilisant le même nom.
L’exemple de code recherche les objets existants, et les supprime ou les met à jour pour vous permettre de réexécuter le programme. Vous pouvez également utiliser le Portail Azure pour supprimer des index, des indexeurs et des sources de données.
Nettoyer les ressources
Lorsque vous travaillez dans votre propre abonnement, à la fin d’un projet, il est judicieux de supprimer les ressources dont vous n’avez plus besoin. Les ressources laissées en fonctionnement peuvent vous coûter de l’argent. Vous pouvez supprimer les ressources individuellement, ou supprimer le groupe de ressources pour supprimer l’ensemble des ressources.
Vous pouvez rechercher et gérer des ressources dans le portail Azure à l’aide du lien Toutes les ressources ou groupes de ressources dans le volet gauche.
Étape suivante
Maintenant que vous êtes familiarisé avec l’ingestion de données à partir de plusieurs sources, examinez de plus près la configuration de l’indexeur, en commençant par Azure Cosmos DB :