Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article explique comment superviser des machines répliquées par Azure Site Recovery à l’aide des journaux Azure Monitor et de Log Analytics.
Les journaux Azure Monitor constituent une plateforme permettant de collecter les données des journaux d’activité et des journaux de ressources, ainsi que d’autres données de supervision. Dans les journaux Azure Monitor, vous utilisez Log Analytics pour écrire et tester des requêtes de journal, analyser également de manière interactive les données de journal. Vous pouvez visualiser et interroger les résultats du journal, et configurer des alertes en fonction des données analysées.
Pour Site Recovery, les journaux Azure Monitor vous permettent d’effectuer les opérations suivantes :
- Superviser l’intégrité et l’état de Site Recovery. Par exemple, vous pouvez superviser l’intégrité de la réplication, l’état du test de basculement, les événements Site Recovery, les objectifs de point de récupération (RPO) pour les machines protégées et les taux de changement des disques ou des données.
- Configurer des alertes pour Site Recovery. Par exemple, vous pouvez configurer des alertes concernant l’intégrité de la machine, l’état du test de basculement ou l’état d’un travail Site Recovery.
L’utilisation des journaux Azure Monitor avec Site Recovery est prise en charge pour la réplication d’Azure à Azure et pour la réplication d’une machine virtuelle VMware ou d’un serveur physique vers Azure.
Remarque
Pour obtenir les journaux de données d’évolution et les journaux de vitesse de chargement pour les machines physiques et VMware, vous devez installer un agent d’analyse Microsoft sur le serveur de processus. Cet agent envoie les journaux des machines de réplication à l’espace de travail. Cette fonctionnalité est disponible uniquement à partir de la version 9.30 de l’agent de mobilité.
Prérequis
Voici ce dont vous avez besoin :
- Au moins une machine est protégée dans un coffre Recovery Services.
- Un espace de travail Log Analytics pour stocker les journaux Site Recovery. Découvrez comment configurer un espace de travail
- Des connaissances de base concernant l’écriture, l’exécution et l’analyse des requêtes de journal dans Log Analytics. Plus d’informations
Avant de commencer, il est recommandé de consulter les questions courantes concernant la supervision.
Journaux des événements disponibles pour Azure Site Recovery
Azure Site Recovery fournit les tables spécifiques à la ressource et héritées suivantes. Chaque événement fournit des données détaillées sur un ensemble spécifique d’artefacts liés à la récupération de site.
Tables spécifiques à la ressource :
Tables héritées :
- Événements Azure Site Recovery
- Éléments répliqués d’Azure Site Recovery
- Statistiques de réplication Azure Site Recovery
- Points Azure Site Recovery
- Taux de chargement de données de réplication Azure Site Recovery
- Activité des données de disque protégé Azure Site Recovery
- Détails de l’élément répliqué par Azure Site Recovery
Configurer Site Recovery pour envoyer des journaux
Dans le coffre, sélectionnez Paramètres de diagnostic>Ajouter un paramètre de diagnostic.
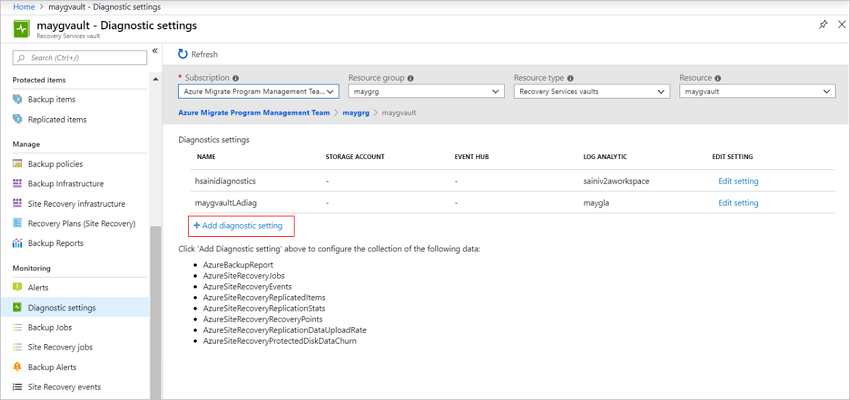
Dans Paramètres de diagnostic, spécifiez un nom, puis cochez la case Envoyer à Log Analytics.
Sélectionnez l’abonnement des journaux Azure Monitor et l’espace de travail Log Analytics.
Sélectionnez Diagnostics Azure dans le bouton bascule.
Dans la liste des journaux, sélectionnez tous les journaux ayant le préfixe AzureSiteRecovery. Sélectionnez ensuite OK.
Les journaux Site Recovery commencent à être alimentés dans une table (AzureDiagnostics) de l’espace de travail sélectionné.
Configurer l’agent d’analyse Microsoft sur le serveur de processus afin d’envoyer les journaux de taux d’évolution et de chargement
Vous pouvez capturer les informations relatives au taux d’évolution des données et au taux de chargement des données sources pour vos machines VMware/physiques locales. Pour ce faire, l’agent d’analyse Microsoft doit être installé sur le serveur de processus.
Accédez à l’espace de travail Log Analytics et sélectionnez Paramètres avancés.
Sélectionnez la page Sources connectées, puis sélectionnez Serveurs Windows.
Téléchargez l’agent Windows (64 bits) sur le serveur de processus.
Terminez l’installation de l’agent en fournissant l’ID et la clé de l’espace de travail obtenu.
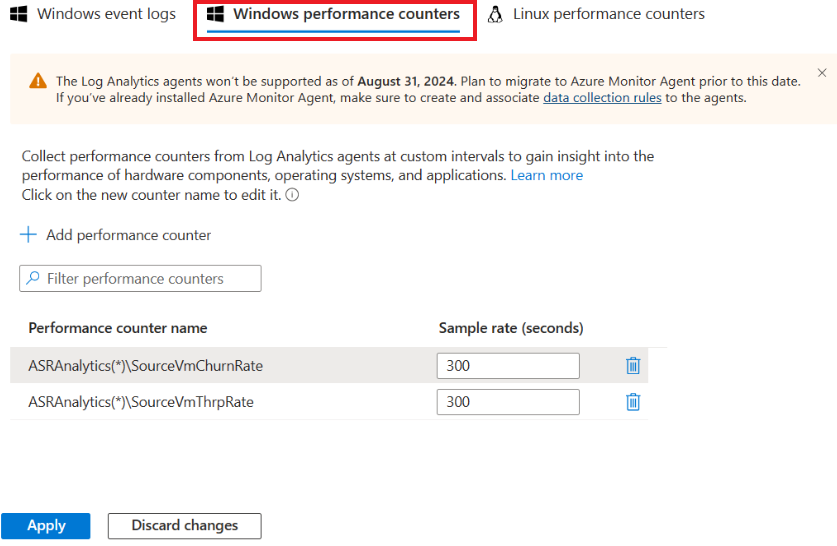
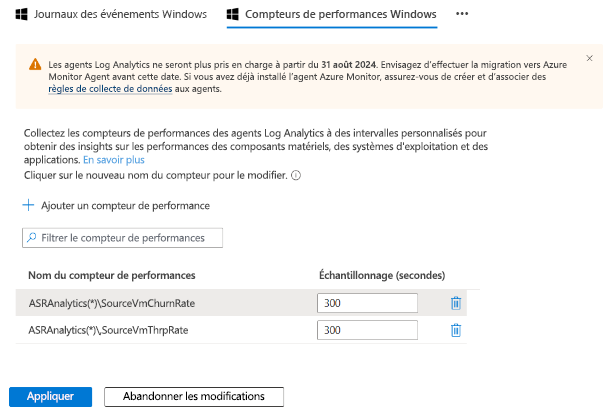
Une fois l’installation terminée, accédez à l’espace de travail Log Analytics, puis sélectionnez Gestion des anciens agents. Accédez à la page Données, puis sélectionnez Compteur de performances Windows.
Sélectionnez « + » pour ajouter les deux compteurs suivants avec un intervalle d’échantillonnage de 300 secondes :
- ASRAnalytics(*)\SourceVmChurnRate
- ASRAnalytics(*)\SourceVmThrpRate
Les données de taux d’évolution et de vitesse de chargement vont commencer à alimenter l’espace de travail.
Actuellement, les compteurs Site Recovery suivants ne peuvent pas faire l’objet d’une recherche :
- ASRAnalytics(*)\SourceVmChurnRate
- ASRAnalytics(*)\SourceVmThrpRate
Toutefois, ils peuvent être ajoutés en collant les noms dans leur intégralité.
Remarque
Actuellement, vous ne pouvez pas rechercher ces compteurs. Toutefois, vous pouvez les ajouter en copiant et en collant leurs noms complets.
- SourceVmThrpRate affiche le débit du réseau sur la source.
- SourceVmChurnRate affiche le taux de modification des données sur le disque sur la machine virtuelle source.
Interroger les journaux - Exemples
Vous pouvez récupérer les données des journaux à l’aide de requêtes de journal écrites à l’aide du langage de requête Kusto. Cette section fournit quelques exemples de requêtes courantes que vous pouvez utiliser pour la supervision Site Recovery.
Remarque
Certains de ces exemples utilisent replicationProviderName_s avec une valeur de A2A. Cela permet de récupérer les machines virtuelles Azure qui ont été répliquées dans une région Azure secondaire à l’aide de Site Recovery. Dans ces exemples, vous pouvez remplacer A2A par InMageRcm si vous souhaitez récupérer des machines virtuelles VMware locales ou des serveurs physiques ayant été répliqués dans Azure à l’aide de Site Recovery.
Interroger l’intégrité de la réplication
Cette requête trace un graphique à secteurs représentant l’intégrité actuelle de la réplication pour toutes les machines virtuelles Azure protégées. L’intégrité peut être associée à trois états : Normal, Avertissement ou Critique.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , replicationHealth_s
| summarize count() by replicationHealth_s
| render piechart
Interroger la version du service Mobilité
Cette requête trace un graphique à secteurs représentant les machines virtuelles Azure répliquées avec Site Recovery. Celles-ci sont regroupées en fonction de la version de l’agent Mobilité qu’elles exécutent.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , agentVersion_s
| summarize count() by agentVersion_s
| render piechart
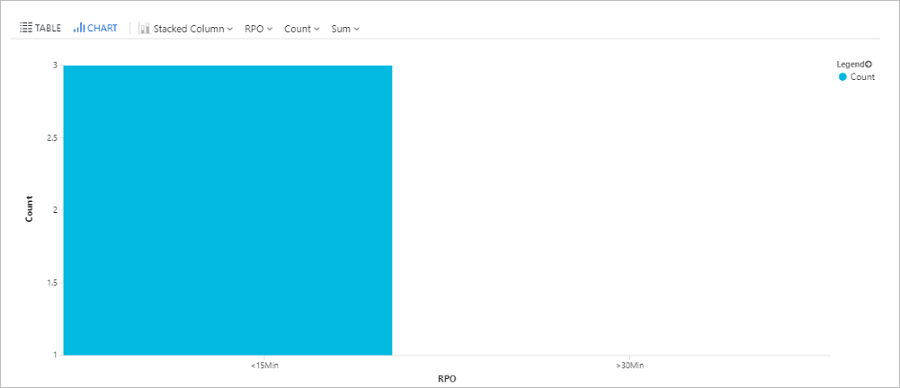
Interroger la durée des RPO
Cette requête trace un graphique à barres représentant les machines virtuelles Azure répliquées avec Site Recovery. Celles-ci sont regroupées selon la durée de leur objectif de point de récupération (RPO) : inférieure à 15 minutes, entre 15 et 30 minutes, supérieure à 30 minutes.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| extend RPO = case(rpoInSeconds_d <= 900, "<15Min",
rpoInSeconds_d <= 1800, "15-30Min", ">30Min")
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , RPO
| summarize Count = count() by RPO
| render barchart
Interroger les travaux Azure Site Recovery
Cette requête récupère l’ensemble des travaux Site Recovery (pour tous les scénarios de reprise d’activité) déclenchés au cours des 72 dernières heures, ainsi que leur état d’achèvement.
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where TimeGenerated >= ago(72h)
| project JobName = OperationName , VaultName = Resource , TargetName = affectedResourceName_s, State = ResultType
Interroger les événements Site Recovery
Cette requête récupère l’ensemble des événements Site Recovery (pour tous les scénarios de reprise d’activité) signalés au cours des 72 dernières heures, ainsi que leur niveau de gravité.
AzureDiagnostics
| where Category == "AzureSiteRecoveryEvents"
| where TimeGenerated >= ago(72h)
| project AffectedObject=affectedResourceName_s , VaultName = Resource, Description_s = healthErrors_s , Severity = Level
Interroger l’état du test de basculement (graphique à secteurs)
Cette requête trace un graphique à secteurs représentant l’état du test de basculement des machines virtuelles Azure répliquées avec Site Recovery.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , Resource, failoverHealth_s
| summarize count() by failoverHealth_s
| render piechart
Interroger l’état du test de basculement (table)
Cette requête trace un tableau représentant l’état du test de basculement des machines virtuelles Azure répliquées avec Site Recovery.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , VaultName = Resource , TestFailoverStatus = failoverHealth_s
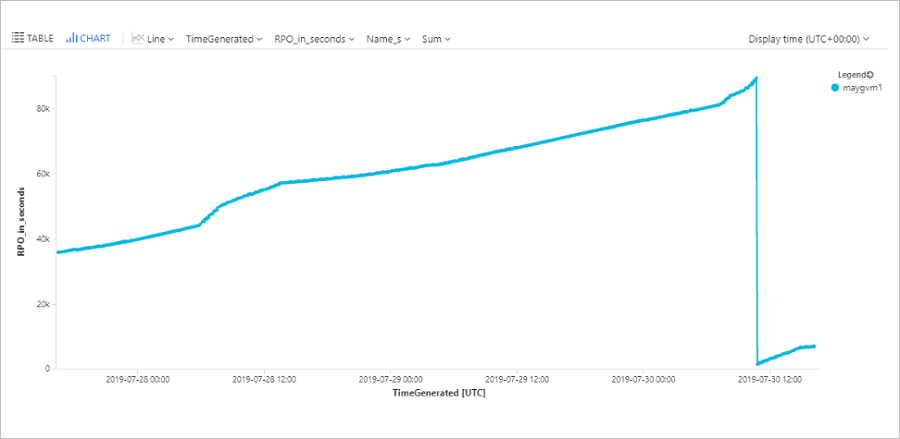
Interroger les RPO des machines
Cette requête trace un graphique de tendance qui suit l’évolution du RPO d’une machine virtuelle Azure (ContosoVM123) au cours des 72 dernières heures.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where TimeGenerated > ago(72h)
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| project TimeGenerated, name_s , RPO_in_seconds = rpoInSeconds_d
| render timechart
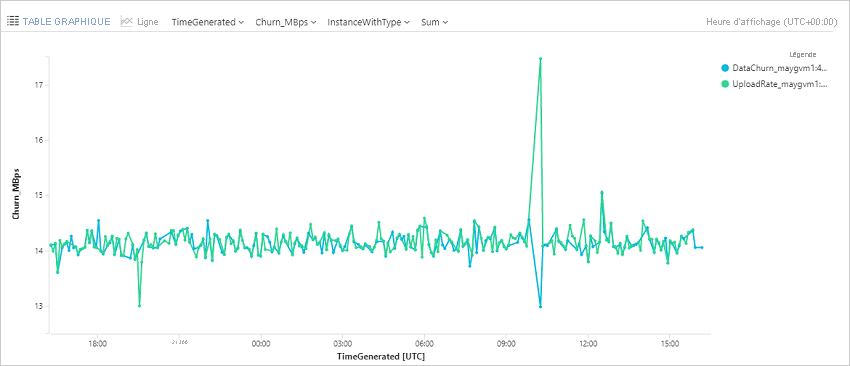
Taux de modification des données de requête (évolution) et vitesse de téléchargement pour une machine virtuelle Azure
Cette requête trace un graphique de tendance qui représente l’évolution du taux de changement des données (octets écrits par seconde) et du taux de chargement des données pour une machine virtuelle Azure (ContosoVM123).
AzureDiagnostics
| where Category in ("AzureSiteRecoveryProtectedDiskDataChurn", "AzureSiteRecoveryReplicationDataUploadRate")
| extend CategoryS = case(Category contains "Churn", "DataChurn",
Category contains "Upload", "UploadRate", "none")
| extend InstanceWithType=strcat(CategoryS, "_", InstanceName_s)
| where TimeGenerated > ago(24h)
| where InstanceName_s startswith "ContosoVM123"
| project TimeGenerated , InstanceWithType , Churn_MBps = todouble(Value_s)/1048576
| render timechart
Taux de modification des données de requête (évolution) et vitesse de téléchargement pour une machine virtuelle VMware ou une machine physique
Remarque
Veillez à configurer l’agent d’analyse sur le serveur de processus pour extraire ces journaux. Reportez-vous aux étapes de configuration de l’agent d’analyse.
Cette requête trace un graphe de tendance pour le disque disk0 de l’élément répliqué win-9r7sfh9qlru, qui suit l’évolution du taux de changement des données (octets écrits par seconde) et du taux de chargement des données pour une machine virtuelle Azure (disk0). Le nom du disque se trouve dans le panneau Disques de l’élément répliqué, dans le coffre Recovery Services. Le nom d’instance à utiliser dans la requête est le nom DNS de l’ordinateur suivi de _ et du nom de disque, comme dans cet exemple.
Perf
| where ObjectName == "ASRAnalytics"
| where InstanceName contains "win-9r7sfh9qlru_disk0"
| where TimeGenerated >= ago(4h)
| project TimeGenerated ,CounterName, Churn_MBps = todouble(CounterValue)/5242880
| render timechart
Le serveur de processus transmet ces données toutes les 5 minutes à l’espace de travail Log Analytics. Ces points de données représentent la moyenne calculée pendant 5 minutes.
Interroger le récapitulatif d’une reprise d’activité (au sein d’Azure)
Cette requête trace un tableau récapitulatif des machines virtuelles Azure qui ont été répliquées dans une région Azure secondaire. Il indique le nom de la machine virtuelle, l’état de la réplication et de la protection, le RPO, l’état du test de basculement, la version de l’agent de mobilité, les erreurs de réplication actives et l’emplacement source.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, SourceLocation = primaryFabricName_s
Interroger le récapitulatif d’une reprise d’activité (serveurs VMware ou physiques)
Cette requête trace un tableau récapitulatif des machines virtuelles VMware et des serveurs physiques répliqués dans Azure. Il indique le nom de la machine, l’état de la réplication et de la protection, le RPO, l’état du test de basculement, la version de l’agent de mobilité, les erreurs de réplication actives et le serveur de processus impliqué.
AzureDiagnostics
| where replicationProviderName_s == "InMageRcm"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, ProcessServer = processServerName_g
Configurer des alertes - Exemples
Vous pouvez configurer des alertes Site Recovery en fonction des données Azure Monitor. En savoir plus sur la configuration des alertes de journaux
Remarque
Certains de ces exemples utilisent replicationProviderName_s avec une valeur de A2A. Cela permet de configurer des alertes pour les machines virtuelles Azure qui ont été répliquées dans une région Azure secondaire. Dans ces exemples, vous pouvez remplacer A2A par InMageRcm si vous souhaitez configurer des alertes pour des machines virtuelles VMware locales ou des serveurs physiques ayant été répliqués dans Azure.
Plusieurs machines avec un état Critique
Configurez une alerte si plus de 20 machines virtuelles Azure répliquées passent à l’état Critique.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Pour l’alerte, définissez la Valeur de seuil sur 20.
Une seule machine avec un état Critique
Configurez une alerte si une machine virtuelle Azure répliquée passe à l’état Critique.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where name_s == "ContosoVM123"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Pour l’alerte, définissez la Valeur de seuil sur 1.
Plusieurs machines dépassent le RPO
Configurez une alerte si le RPO de plus de 20 machines virtuelles Azure dépasse 30 minutes.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
Pour l’alerte, définissez la Valeur de seuil sur 20.
Une seule machine dépasse le RPO
Configurez une alerte si le RPO d’une machine virtuelle Azure dépasse 30 minutes.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
Pour l’alerte, définissez la Valeur de seuil sur 1.
Le test de basculement de plusieurs machines remonte à plus de 90 jours
Configurez une alerte si le dernier test de basculement réussi remonte à plus de 90 jours pour plus de 20 machines virtuelles.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Pour l’alerte, définissez la Valeur de seuil sur 20.
Le test de basculement d’une seule machine remonte à plus de 90 jours
Configurez une alerte si le dernier test de basculement réussi remonte à plus de 90 jours pour une machine virtuelle.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| where name_s == "ContosoVM123"
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Pour l’alerte, définissez la Valeur de seuil sur 1.
Échec d’un travail Site Recovery
Configurez une alerte si un travail Site Recovery (dans le cas présent, un travail de reprotection) échoue lors du dernier jour, dans n’importe quel scénario Site Recovery.
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where OperationName == "Reprotect"
| where ResultType == "Failed"
| summarize count()
Pour l’alerte, définissez la Valeur de seuil sur 1 et la Période sur 1 440 minutes, afin de vérifier les échecs qui ont eu lieu le dernier jour.