Recommandations et modèles de migration Azure Data Lake Storage
Vous pouvez effectuer la migration de vos données, de vos charges de travail et de vos applications d’Azure Data Lake Storage Gen1 vers Azure Data Lake Storage Gen2. Cet article explique l’approche de migration recommandée, aborde les différents modèles de migration et indique quand utiliser chacun d’eux. Pour faciliter la lecture de cet article, le terme Gen1 est utilisé pour faire référence à Azure Data Lake Storage Gen1 tandis que le terme Gen2 est utilisé pour faire référence à Azure Data Lake Storage Gen2.
Notes
Azure Data Lake Storage Gen1 est désormais hors service. Consultez l’annonce de mise hors service ici. Les ressources Data Lake Storage Gen1 ne sont plus accessibles.
Azure Data Lake Storage Gen2 est basé sur le Stockage Blob Azure et fournit un ensemble de fonctionnalités dédiées à l’analyse des données volumineuses. Data Lake Storage Gen2 contient les fonctionnalités d’Azure Data Lake Storage Gen1, comme la sémantique des systèmes de fichiers, la sécurité au niveau des fichiers et des répertoires, et la mise à l’échelle, ainsi que les fonctionnalités du Stockage Blob Azure comme le stockage hiérarchisé à faible coût, la haute disponibilité et la reprise d’activité.
Notes
Comme Gen1 et Gen2 sont des services différents, il n’y a pas d’expérience de mise à niveau sur place. Pour simplifier la migration vers Gen2 à l’aide du portail Azure, consultez Migrer Azure Data Lake Storage de Gen1 vers Gen2 à l’aide du portail Azure.
Pour effectuer la migration de Gen1 vers Gen2, nous vous recommandons l’approche suivante.
Étape 1 : Évaluer la préparation
Étape 2 : Préparer la migration
Étape 3 : Migrer les données et les charges de travail d’application
Étape 4 : Basculer de Gen1 vers Gen2
Découvrez l’offre Data Lake Storage Gen2, ses avantages, son coût et son architecture générale.
Comparez les fonctionnalités de Gen1 à celles de Gen2.
Consultez la liste des problèmes connus pour voir si certaines fonctionnalités sont manquantes.
Gen2 prend en charge les fonctionnalités du stockage Blob, telles que la journalisation des diagnostics, les niveaux d’accès et les stratégies de gestion du cycle de vie du stockage Blob. Si ces fonctionnalités vous intéressent, consultez leur niveau actuel de prise en charge.
Consultez l’état actuel de la prise en charge de l’écosystème Azure pour voir si Gen2 prend en charge tous les services dont dépendent vos solutions.
Identifiez les jeux de données qui doivent faire l’objet d’une migration.
Profitez-en pour nettoyer les jeux de données que vous n’utilisez plus. Si vous ne souhaitez pas effectuer la migration de toutes vos données à la fois, profitez-en pour identifier les groupes logiques de données qui peuvent faire l’objet d’une migration en plusieurs phases.
Effectuez une analyse du vieillissement (ou similaire) sur votre compte Gen1 pour identifier les fichiers ou dossiers restés longtemps dans l’inventaire ou peut-être devenus obsolètes.
Déterminez l’impact qu’aura une migration sur votre entreprise.
Par exemple, déterminez si vous pouvez vous permettre des temps d’arrêt pendant la migration. Ces considérations peuvent vous aider à identifier un modèle de migration approprié et à choisir les outils les mieux adaptés.
Créez un plan de migration.
Nous vous recommandons d’utiliser ces modèles de migration. Vous pouvez choisir l’un de ces modèles, les associer ou concevoir votre propre modèle personnalisé.
Effectuez la migration des données, des charges de travail et des applications à l’aide du modèle de votre choix. Nous vous recommandons de valider les scénarios de manière incrémentielle.
Créez un compte de stockage et activez la fonctionnalité d’espace de noms hiérarchique.
Migrez vos données.
Configurez les services de vos charges de travail pour qu’ils pointent vers votre point de terminaison Gen2.
Pour les clusters HDInsight, vous pouvez ajouter des paramètres de configuration de compte de stockage au fichier %HADOOP_HOME%/conf/core-site.xml. Si vous prévoyez de migrer des tables de ruche externes de Gen1 à Gen2, veillez à ajouter des paramètres de compte de stockage au fichier %HIVE_CONF_DIR%/hive-site.xml également.
Vous pouvez modifier ce paramètre pour chaque fichier avec Apache Ambari. Pour trouver les paramètres de compte de stockage, voir Support Azure Hadoop : ABFS - Azure Data Lake Stockage Gen2. Cet exemple utilise le paramètre
fs.azure.account.keypour activer l’autorisation de clé partagée :<property> <name>fs.azure.account.key.abfswales1.dfs.core.windows.net</name> <value>your-key-goes-here</value> </property>Pour consulter des liens vers des articles qui vous aident à configurer HDInsight, Azure Databricks et d’autres services Azure de manière à utiliser Gen2, consultez les services Azure qui prennent en charge Azure Data Lake Stockage Gen2.
Mettez à jour les applications pour qu’elles utilisent les API Gen2. Consultez les guides suivants :
Mettez à jour les scripts pour qu’ils utilisent les applets de commande PowerShell Data Lake Storage Gen2 et les commandes Azure CLI.
Recherchez les références URI contenant la chaîne
adl://dans les fichiers de code, les notebooks Databricks, les fichiers HQL Apache Hive ou tout autre fichier utilisé dans le cadre de vos charges de travail. Remplacez ces références par l’URI formaté Gen2 de votre nouveau compte de stockage. Par exemple, l’URI Gen1adl://mydatalakestore.azuredatalakestore.net/mydirectory/myfilepeut devenirabfss://myfilesystem@mydatalakestore.dfs.core.windows.net/mydirectory/myfile.Configurez la sécurité sur votre compte pour inclure les rôles RBAC Azure, la sécurité au niveau des fichiers et des dossiers, ainsi que les pare-feu et réseaux virtuels dans Stockage Azure.
Une fois que vous êtes certain que vos applications et vos charges de travail sont stables sur Gen2, vous pouvez commencer à utiliser Gen2 pour vos scénarios métier. Désactivez les pipelines restants qui s’exécutent sur Gen1, puis désactivez votre compte Gen1.
Ce tableau compare les fonctionnalités de Gen1 à celles de Gen2.
Choisissez un modèle de migration, puis modifiez le modèle en fonction des besoins.
| Modèle de migration | Détails |
|---|---|
| Opération lift-and-shift | Modèle le plus simple. Idéal si vos pipelines de données permettent des temps d’arrêt. |
| Copie incrémentielle | Semblable au lift-and-shift, mais avec un temps d’arrêt moindre. Idéal pour les grandes quantités de données dont la copie prend plus de temps. |
| Double pipeline | Idéal pour les pipelines qui ne peuvent pas se permettre de temps d’arrêt. |
| Synchronisation bidirectionnelle | Semblable au double pipeline, mais avec une approche plus progressive, adaptée aux pipelines complexes. |
Examinons de plus près chacun de ces modèles.
Il s’agit du modèle le plus simple.
Arrêtez toutes les écritures dans Gen1.
Déplacez les données de Gen1 vers Gen2. Nous recommandons Azure Data Factory ou le portail Azure. Les listes de contrôle d’accès sont copiées avec les données.
Faites pointer les opérations d’ingestion et les charges de travail vers Gen2.
Désactivez Gen1.
Consultez notre exemple de code pour le modèle lift-and-shift dans notre exemple de migration lift-and-shift.
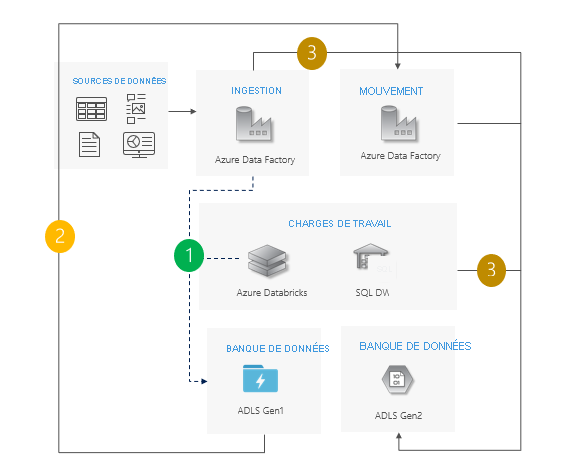
Effectuez le basculement de Gen1 vers Gen2 pour toutes les charges de travail en même temps.
Prévoyez un temps d’arrêt pendant la migration et la période de basculement.
Idéal pour les pipelines qui permettent des temps d’arrêt et dans lesquels toutes les applications peuvent être mises à niveau en même temps.
Conseil
Vous pouvez utiliser le portail Azure pour raccourcir les temps d’arrêt et réduire le nombre d’étapes nécessaires pour effectuer la migration.
Commencez par déplacer les données de Gen1 vers Gen2. Nous vous recommandons Azure Data Factory. Les listes de contrôle d’accès sont copiées avec les données.
Copiez les nouvelles données de façon incrémentielle à partir de Gen1.
Une fois que toutes les données ont été copiées, arrêtez toutes les écritures dans Gen1 et faites pointer les charges de travail vers Gen2.
Désactivez Gen1.
Consultez notre exemple de code pour le modèle de copie incrémentielle dans notre exemple de migration de copie incrémentielle.
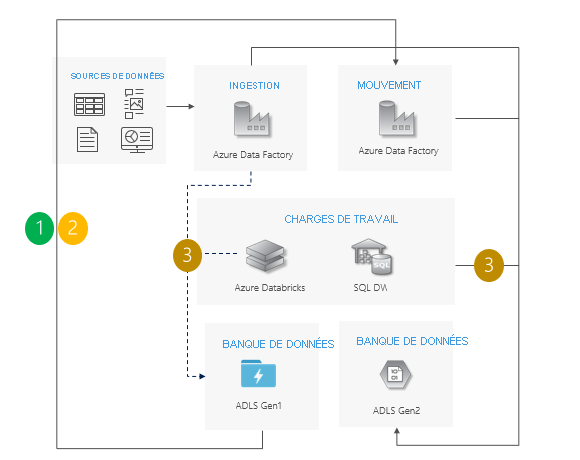
Effectuez le basculement de Gen1 vers Gen2 pour toutes les charges de travail en même temps.
Prévoyez un temps d’arrêt uniquement pendant la période de basculement.
Idéal pour les pipelines dans lesquels toutes les applications sont mises à niveau en même temps, mais dans lesquels la copie des données nécessite plus de temps.
Déplacez les données de Gen1 vers Gen2. Nous vous recommandons Azure Data Factory. Les listes de contrôle d’accès sont copiées avec les données.
Ingérez les nouvelles données à la fois dans Gen1 et dans Gen2.
Faites pointer les charges de travail vers Gen2.
Arrêtez toutes les écritures dans Gen1, puis désactivez Gen1.
Consultez notre exemple de code pour le modèle de pipeline double dans notre exemple de migration de pipeline double.
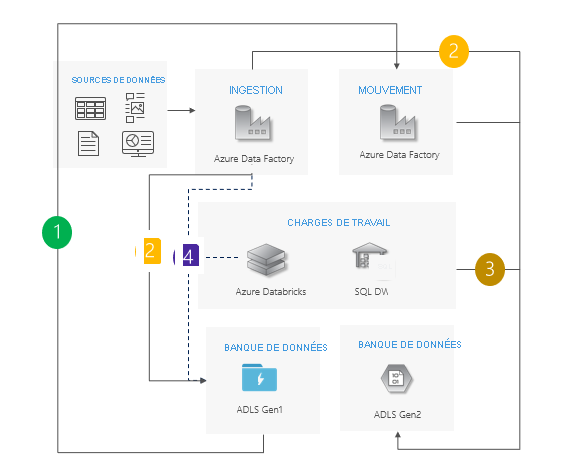
Les pipelines Gen1 et Gen2 s’exécutent côte à côte.
Ne permet aucun temps d’arrêt.
Idéal lorsque vos charges de travail et vos applications ne peuvent pas se permettre de temps d’arrêt, et lorsque vous pouvez ingérer les données dans les deux comptes de stockage.
Configurez la réplication bidirectionnelle entre Gen1 et Gen2. Nous recommandons WanDisco. Il offre une fonctionnalité de réparation pour les données existantes.
Lorsque tous les déplacements de données ont été effectués, arrêtez toutes les écritures dans Gen1, puis désactivez la réplication bidirectionnelle.
Désactivez Gen1.
Consultez notre exemple de code pour le modèle de synchronisation bidirectionnelle dans notre exemple de migration de synchronisation bidirectionnelle.
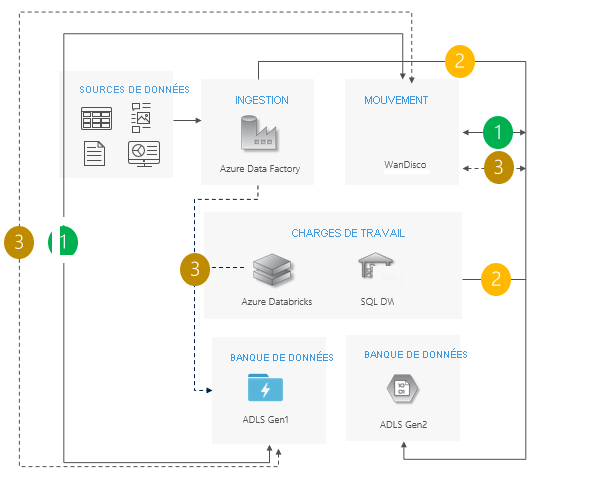
Idéal pour les scénarios complexes qui impliquent un grand nombre de pipelines et de dépendances, et pour lesquels une approche progressive est sans doute plus adaptée.
L’effort de migration est important, mais il offre une prise en charge côte à côte de Gen1 et de Gen2.
- Découvrez les différentes étapes de configuration de la sécurité pour un compte de stockage. Pour plus d’informations, consultez le guide de sécurité Stockage Azure.
- Optimisez les performances de votre instance de Data Lake Store. Voir Optimiser Azure Data Lake Storage Gen2 pour les performances.
- Découvrez les bonnes pratiques de gestion pour Data Lake Store. Voir Bonnes pratiques concernant l’utilisation d’Azure Data Lake Storage Gen2