Guide opérationnel de preuve de concept Synapse : Analyse du Big Data avec un pool Apache Spark dans Azure Synapse Analytics
Cet article présente une méthodologie de haut niveau pour la préparation et l’exécution d’un projet de preuve de concept Azure Synapse Analytics efficace pour un pool Apache Spark.
Notes
Cet article fait partie de la série Guide opérationnel de la preuve de concept Synapse . Pour une vue d’ensemble de la série, consultez Guide opérationnel de la preuve de concept Synapse.
Préparer la preuve de concept
Un projet de preuve de concept peut vous aider à prendre une décision métier éclairée sur l’implémentation d’un environnement Big Data et d’analytique avancée sur une plateforme basée sur le cloud qui tire parti du pool Apache Spark dans Azure Synapse.
Un projet de preuve de concept identifie vos objectifs clés et vos axes stratégiques que le Big Data basé sur le cloud et la plateforme d’analytique avancée doivent prendre en charge. Il teste les métriques clés et prouve les comportements clés qui sont essentiels à la réussite de votre ingénierie des données, de la génération de modèles Machine Learning et des exigences de formation. Une preuve de concept n’est pas conçue pour être déployée dans un environnement de production. Il s’agit plutôt d’un projet à court terme qui se concentre sur les questions clés, et son résultat peut être ignoré.
Avant de commencer à planifier votre projet de preuve de concept Spark :
- Identifiez les restrictions ou recommandations que votre organisation a quant au déplacement de données vers le cloud.
- Identifiez les commanditaires exécutifs ou commerciaux pour un projet de plateforme d’analytique avancée et de Big Data. Assurez leur soutien envers la migration vers le cloud.
- Identifiez la disponibilité des experts techniques et des utilisateurs professionnels pour vous aider pendant l’exécution de la preuve de concept.
Avant de commencer à préparer le projet de preuve de concept, nous vous recommandons de lire d’abord la Documentation d’Apache Spark.
Conseil
Si vous débutez avec les pools Spark, nous vous recommandons de suivre le parcours d’apprentissage Effectuer l’ingénierie des données avec des pools Apache Spark Azure Synapse.
À présent, vous devez avoir déterminé qu’il n’y a pas de points de blocage immédiats ; vous pouvez commencer à préparer votre preuve de concept. Si vous débutez avec les pools Apache Spark dans Azure Synapse Analytics, vous pouvez consulter cette documentation dans laquelle vous pouvez obtenir une vue d’ensemble de l’architecture Spark et découvrir son fonctionnement dans Azure Synapse.
Développez une compréhension de ces concepts clés :
- Apache Spark et son architecture distribuée.
- Concepts Spark comme les jeux de données distribués résilients (RDD) et les partitions (en mémoire et physiques).
- Espace de travail Azure Synapse, les différents moteurs de calcul, pipeline et supervision.
- Séparation du calcul et du stockage dans un pool Spark.
- Authentification et autorisation dans Azure Synapse.
- Connecteurs natifs qui s’intègrent à un pool SQL dédié Azure Synapse, à Azure Cosmos DB et autres.
Azure Synapse dissocie les ressources de calcul du stockage afin de mieux gérer vos besoins en matière de traitement des données et de contrôler les coûts. L’architecture serverless du pool Spark vous permet d’arrêter et démarrer des ressources, ainsi que d’augmenter et de réduire votre cluster Spark, indépendamment de votre stockage. Vous pouvez suspendre (ou configurer la mise en pause automatique) d’un cluster Spark entier. De cette façon, vous payez pour le calcul uniquement lorsqu’il est utilisé. Lorsqu’il n’est pas utilisé, vous payez uniquement pour le stockage. Vous pouvez effectuer un scale-up de votre cluster Spark pour les traitements de données lourds ou les charges volumineuses, puis le réduire pendant des temps de traitement moins intenses (ou l’arrêter complètement). Vous pouvez mettre à l’échelle et suspendre efficacement un cluster pour réduire les coûts. Vos tests de preuve de concept Spark doivent inclure l’ingestion des données et le traitement des données à différentes échelles (petite, moyenne et grande) pour comparer les prix et les performances à différentes échelles. Pour plus d’informations, consultez Mettre automatiquement à l’échelle des pools Apache Spark d’Azure Synapse Analytics.
Il est important de comprendre la différence entre les différents ensembles d’API Spark afin de déterminer ce qui convient le mieux à votre scénario. Vous pouvez choisir celle qui offre les meilleures performances ou la plus grande facilité d’utilisation, en tirant parti des ensembles de compétences existants de votre équipe. Pour plus d’informations, consultez A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets.
Le partitionnement des données et des fichiers fonctionne de façon légèrement différente dans Spark. Comprendre les différences vous aidera à optimiser les performances. Pour plus d’informations, consultez la documentation d’Apache Spark : Découverte de partitions et Options de configuration de partition.
Définir les objectifs
Un projet de preuve de concept réussi nécessite une planification. Commencez par identifier pourquoi vous faites une preuve de concept pour comprendre pleinement les motivations réelles. Les motivations peuvent inclure la modernisation, l’économie de coûts, l’amélioration des performances ou l’expérience intégrée. Veillez à documenter des objectifs clairs pour votre preuve de concept et les critères qui définissent sa réussite. Posez-vous les questions suivantes :
- Que voulez-vous en tant que résultats de votre preuve de concept ?
- Qu’allez-vous faire avec ces résultats ?
- Qui utilisera les résultats ?
- Qu’est-ce qui définira une preuve de concept réussie ?
Gardez à l’esprit qu’une preuve de concept doit être un effort court et ciblé pour prouver rapidement un ensemble limité de concepts et de fonctionnalités. Ces concepts et fonctionnalités doivent être représentatifs de la charge de travail globale. Si vous avez une longue liste d’éléments à prouver, vous pouvez planifier plusieurs preuves de concept. Dans ce cas, définissez des portes entre les preuves de concept pour déterminer si vous devez continuer avec la suivante. Étant donné les différents rôles professionnels qui peuvent utiliser des pools Spark et des notebooks dans Azure Synapse, vous pouvez choisir d’exécuter plusieurs preuves de concept. Par exemple, une preuve de concept peut se concentrer sur les exigences du rôle d’ingénierie des données, comme l’ingestion et le traitement. Une autre preuve de concept peut se concentrer sur le développement de modèles Machine Learning (ML).
Lorsque vous considérez vos objectifs de preuve de concept, posez-vous les questions suivantes pour vous aider à façonner les objectifs :
- Effectuez-vous une migration à partir d’une plateforme Big Data et d’analytique avancée existante (locale ou cloud) ?
- Effectuez-vous la migration, mais souhaitez apporter autant de modifications que possible aux fonctions de traitement des données et d’ingestion existantes ? Par exemple, une migration Spark vers Spark ou une migration Hadoop/Hive vers Spark.
- Vous effectuez une migration, mais souhaitez apporter des améliorations significatives au passage ? Par exemple, réécrire des travaux MapReduce en tant que travaux Spark ou convertir du code RDD hérité en code DataFrame/Dataset.
- Créez-vous une plateforme d’analytique avancée et de Big Data entièrement nouvelle (projet greenfield) ?
- Quelles sont vos difficultés actuelles ? Par exemple, l’extensibilité, les performances ou la flexibilité.
- Quelles nouvelles exigences métier devez-vous prendre en charge ?
- Quels sont les contrats SLA que vous devez respecter ?
- Quelles seront les charges de travail ? Par exemple, ETL, traitement par lots, traitement de flux, formation de modèle Machine Learning, analytique, requêtes de création de rapports ou requêtes interactives ?
- Quelles sont les compétences des utilisateurs qui seront propriétaires du projet (la preuve de concept doit-elle être implémentée) ? Par exemple, compétences PySpark et Scala, expérience avec les notebooks par rapport aux IDE.
Voici quelques exemples de définition d’objectif de preuve de concept :
- Pourquoi faisons-nous une preuve de concept ?
- Nous devons savoir que les performances d’ingestion et de traitement des données pour notre charge de travail Big Data répondent à nos nouveaux contrats SLA.
- Nous devons savoir si le traitement de flux en quasi-temps réel est possible et la quantité de débit qu’il peut prendre en charge. (Est-ce qu’il prend en charge nos besoins métier ?)
- Nous devons savoir si nos processus d’ingestion et de transformation de données existants sont adaptés et où des améliorations devront être apportées.
- Nous devons savoir si nous pouvons raccourcir nos temps d’exécution d’intégration de données et de combien.
- Nous devons savoir si nos scientifiques des données peuvent créer et entraîner des modèles Machine Learning et tirer parti des bibliothèques IA/ML si nécessaire dans un pool Spark.
- Le passage à Synapse Analytics basé sur le cloud va-t-il atteindre nos objectifs de coût ?
- À la fin de cette preuve de concept :
- Nous aurons les données pour déterminer si nos exigences en matière de performances de traitement des données peuvent être satisfaites pour la diffusion en continu en temps réel et par lot.
- Nous aurons testé l’ingestion et le traitement de tous nos différents types de données (structurées, semi et non structurés) qui soutiennent nos cas d’usage.
- Nous aurons testé certains de nos traitements complexes de données existants et pourrons identifier le travail qui devra être effectué pour migrer notre portefeuille d’intégration de données vers le nouvel environnement.
- Nous aurons testé l’ingestion et le traitement des données et nous aurons les points de données pour estimer l’effort requis pour la migration initiale et la charge des données historiques, ainsi que l’effort nécessaire pour migrer notre ingestion de données (Azure Data Factory (ADF), Distcp, Databox ou autres).
- Nous aurons testé l’ingestion et le traitement des données et pourrons déterminer si nos exigences de traitement ETL/ELT peuvent être satisfaites.
- Nous aurons acquis des insights pour mieux estimer l’effort nécessaire pour terminer l’implémentation.
- Nous aurons testé les options d’échelle et de mise à l’échelle et disposerons de points de données pour mieux configurer notre plateforme pour de meilleurs paramètres de prix et de performances.
- Nous aurons une liste d’éléments qui peuvent nécessiter plus de tests.
Planifier le projet
Utilisez vos objectifs pour identifier des tests spécifiques et fournir les résultats que vous avez identifiés. Il est important de s’assurer que vous avez au moins un test pour prendre en charge chaque objectif et le résultat attendu. Identifiez également l’ingestion de données, le traitement par lots ou de flux, ainsi que tous les autres processus qui seront exécutés afin de pouvoir identifier un jeu de données et un codebase très spécifiques. Ce jeu de données et ce codebase spécifiques définissent l’étendue de la preuve de concept.
Voici un exemple du niveau de spécificité nécessaire dans la planification :
- Objectif A : Nous devons savoir si notre exigence en matière d’ingestion et de traitement des données par lots peut être satisfaite dans le cadre de notre contrat SLA défini.
- Résultat A : Nous aurons les données pour déterminer si l’ingestion et le traitement des données par lots peuvent répondre aux exigences de traitement des données et au contrat SLA.
- Test A1 : Les requêtes de traitement A, B et C sont identifiées comme de bons tests des performances, car elles sont généralement exécutées par l’équipe d’ingénierie des données. Elles représentent également les besoins globaux en matière de traitement des données.
- Test A2 : Les requêtes de traitement X, Y et Z sont identifiées comme de bons tests de performances, car elles contiennent des exigences de traitement de flux en quasi-temps réel. En outre, elles représentent les besoins globaux en matière de traitement de flux basé sur les événements.
- Test A3 : Comparez les performances de ces requêtes à différentes échelles de cluster Spark (nombre variable de nœuds Worker, taille des nœuds Worker, comme petit, moyen et grand, nombre et taille des exécuteurs) avec la référence obtenue à partir du système existant. Gardez la loi des rendements décroissants à l’esprit ; l’ajout de ressources supplémentaires (en effectuant un scale-up ou un scale-out) peut vous aider à atteindre le parallélisme, mais il existe une certaine limite propre à chaque scénario pour atteindre le parallélisme. Découvrez la configuration optimale pour chaque cas d’usage identifié dans votre test.
- Objectif B : Nous devons savoir si nos scientifiques des données peuvent créer et former des modèles Machine Learning sur cette plateforme.
- Résultat B : Nous aurons testé certains de nos modèles Machine Learning en les formant sur les données d’un pool Spark ou d’un pool SQL, en tirant parti de différentes bibliothèques de Machine Learning. Ces tests vous aideront à déterminer quels modèles Machine Learning peuvent être migrés vers le nouvel environnement
- Test B1 : Des modèles Machine Learning spécifiques seront testés.
- Test B2 : Tester les bibliothèques Machine Learning de base fournies avec Spark (Spark MLLib) ainsi qu’une bibliothèque supplémentaire qui peut être installée sur Spark (comme scikit-learn) pour répondre aux exigences.
- Objectif C : Nous aurons testé l’ingestion des données et aurons des points de données pour :
- Estimer l’effort de notre migration initiale des données historiques vers le lac de données et/ou le pool Spark.
- Planifier une approche pour migrer des données historiques.
- Résultat C : Nous aurons testé et déterminé le taux d’ingestion de données réalisable dans notre environnement et pourrons déterminer si notre taux d’ingestion de données est suffisant pour migrer les données historiques pendant la fenêtre de temps disponible.
- Test C1 : Tester différentes approches de la migration des données historiques. Pour plus d’informations, consultez l’article Transférer des données vers et à partir d’Azure.
- Test C2 : Identifier la bande passante allouée d’ExpressRoute et s’il existe une configuration de limitation par l’équipe d’infrastructure. Pour plus d’informations, consultez Qu’est-ce qu’Azure ExpressRoute ? (options de bande passante).
- Test C3 : Tester le taux de transfert de données pour la migration de données en ligne et hors connexion. Pour plus d’informations, consultez Guide sur les performances et la scalabilité de l’activité de copie.
- Test C4 : Tester le transfert de données du lac de données vers le pool SQL à l’aide d’ADF, Polybase ou de la commande COPY. Pour plus d’informations, consultez Stratégies de chargement de données pour un pool SQL dédié dans Azure Synapse Analytics.
- Objectif D : Nous aurons testé le taux d’ingestion des données du chargement incrémentiel des données et disposerons de points de données pour estimer l’ingestion et la fenêtre de temps de traitement des données dans le lac de données et/ou le pool SQL dédié.
- Résultat D : Nous aurons testé le taux d’ingestion de données et pourrons déterminer si nos exigences en matière d’ingestion et de traitement des données peuvent être respectées avec l’approche identifiée.
- Test D1 : Tester l’ingestion et le traitement quotidiens des données de mise à jour.
- Test D2 : Tester la charge des données traitées dans la table du pool SQL dédié à partir du pool Spark. Pour en savoir plus, consultez Connecteur de pools SQL dédiés Azure Synapse pour Apache Spark.
- Test D3 : Exécuter simultanément le processus de chargement de mise à jour quotidienne lors de l’exécution des requêtes de l’utilisateur final.
Veillez à affiner vos tests en ajoutant plusieurs scénarios de test. Azure Synapse facilite le test de différentes échelles (nombre variable de nœuds Worker, taille des nœuds Worker comme petit, moyen et grand) pour comparer les performances et le comportement.
Voici quelques scénarios de test :
- Test de pool Spark A : Nous allons exécuter le traitement des données sur plusieurs types de nœuds (petits, moyens et grands) ainsi que différents nombres de nœuds Worker.
- Test de pool Spark B : Nous allons charger/récupérer des données traitées du pool Spark vers le pool SQL dédié à l’aide du connecteur.
- Test de pool Spark C : Nous allons charger/récupérer des données traitées du pool Spark vers Azure Cosmos DB à l’aide d’Azure Synapse Link.
Évaluer le jeu de données de la preuve de concept
À l’aide des tests spécifiques que vous avez identifiés, sélectionnez un jeu de données pour prendre en charge les tests. Prenez le temps de passer en revue ce jeu de données. Vous devez vérifier que le jeu de données représentera correctement votre traitement futur en termes de contenu, de complexité et d’échelle. N’utilisez pas un jeu de données trop petit (inférieur à 1 To), car il ne fournira pas de performances représentatives. À l’inverse, n’utilisez pas de jeu de données trop volumineux, car la preuve de concept ne doit pas devenir une migration complète des données. Veillez à obtenir les références appropriées des systèmes existants afin de pouvoir les utiliser pour les comparaisons de performances.
Important
Veillez à vérifier auprès des propriétaires d’entreprise les blocages avant de déplacer des données vers le cloud. Identifiez les problèmes de sécurité ou de confidentialité ou les besoins d’obfuscation des données avant de déplacer des données vers le cloud.
Créer une architecture de haut niveau
En fonction de l’architecture de haut niveau de votre architecture d’état futur proposée, identifiez les composants qui feront partie de votre preuve de concept. Votre architecture d’état futur de haut niveau contient probablement de nombreuses sources de données, de nombreux consommateurs de données, des composants Big Data, et éventuellement des consommateurs de données de Machine Learning et d’intelligence artificielle (IA). Votre architecture de preuve de concept doit identifier spécifiquement les composants qui feront partie de la preuve de concept. Elle doit surtout identifier tous les composants qui ne feront pas partie du test de preuve de concept.
Si vous utilisez déjà Azure, identifiez les ressources déjà en place (Microsoft Entra ID, ExpressRoute et autres) que vous pouvez utiliser pendant la preuve de concept. Identifiez également les régions Azure que votre organisation utilise. Il est maintenant très utile d’identifier le débit de votre connexion ExpressRoute et de vérifier auprès d’autres utilisateurs professionnels que votre preuve de concept peut consommer une partie de ce débit sans impact négatif sur les systèmes de production.
Pour plus d’informations, consultez Architectures Big Data.
Identifier les ressources de preuve de concept
Identifiez spécifiquement les ressources techniques et les engagements en temps nécessaires pour prendre en charge votre preuve de concept. Votre preuve de concept aura besoin de ce qui suit :
- Représentant de l’entreprise pour superviser les exigences et les résultats.
- Un expert en données d’application, pour approvisionner les données de la preuve de concept et fournir des connaissances sur les processus et la logique existants.
- Expert en Apache Spark et pools Spark.
- Un conseiller expert, pour optimiser les tests de preuve de concept.
- Les ressources qui seront requises pour des composants spécifiques de votre projet de preuve de concept, mais pas nécessairement requises pour la durée de la preuve de concept. Ces ressources peuvent inclure des administrateurs réseau, des administrateurs Azure, des administrateurs Active Directory, des administrateurs du portail Azure et d’autres.
- Vérifiez que toutes les ressources des services Azure requis sont approvisionnées et que le niveau d’accès requis est accordé, y compris l’accès aux comptes de stockage.
- Vérifiez que vous disposez d’un compte disposant des autorisations d’accès aux données nécessaires pour récupérer des données de toutes les sources de données dans l’étendue de la preuve de concept.
Conseil
Nous vous recommandons d’engager un conseiller expert pour vous aider avec votre preuve de concept. La communauté de partenaires Microsoft offre une disponibilité mondiale de consultants experts qui peuvent vous aider à évaluer ou implémenter Azure Synapse.
Définir la chronologie
Passez en revue vos détails de planification et vos besoins métier pour identifier un délai d’exécution pour votre preuve de concept. Faites des estimations réalistes du temps nécessaire pour atteindre les objectifs de la preuve de concept. Le temps d’exécution de votre preuve de concept sera influencé par la taille de votre jeu de données de preuve de concept, le nombre et la complexité des tests, ainsi que le nombre d’interfaces à tester. Si vous estimez que votre preuve de concept s’exécutera sur plus de quatre semaines, envisagez de réduire l’étendue de la preuve de concept pour vous concentrer sur les objectifs prioritaires. Veillez à obtenir l’approbation et l’engagement de toutes les ressources et de tous les commanditaires principaux avant de continuer.
Mettre la preuve de concept en pratique
Nous vous recommandons d’exécuter votre projet de preuve de concept avec la discipline et la rigueur de tout projet de production. Exécutez le projet conformément au plan et gérez un processus de demande de modification pour empêcher la croissance non contrôlée de l’étendue de la preuve de concept.
Voici quelques exemples de tâches de haut niveau :
Créez un espace de travail Synapse, des pools Spark et des pools SQL dédiés, des comptes de stockage et toutes les ressources Azure identifiées dans le plan de preuve de concept.
Charger le jeu de données de preuve de concept :
- Rendez les données disponibles dans Azure en les extrayant à partir de la source ou en créant des exemples de données dans Azure. Pour plus d'informations, consultez les pages suivantes :
- Testez le connecteur dédié pour le pool Spark et le pool SQL dédié.
Migrez le code existant vers le pool Spark :
- Si vous effectuez une migration à partir de Spark, votre effort de migration est probablement simple, étant donné que le pool Spark tire parti de la distribution Spark open source. Toutefois, si vous utilisez des fonctionnalités spécifiques au fournisseur sur les principales fonctionnalités Spark, vous devez mapper correctement ces fonctionnalités aux fonctionnalités du pool Spark.
- Si vous effectuez une migration à partir d’un système non Spark, votre effort de migration varie en fonction de la complexité impliquée.
Exécutez les tests :
- De nombreux tests peuvent être exécutés en parallèle sur plusieurs clusters de pool Spark.
- Enregistrez vos résultats dans un format consommable et facilement compréhensible.
Surveillez la résolution des problèmes et les performances. Pour plus d'informations, consultez les pages suivantes :
Surveillez l’asymétrie des données, l’asymétrie temporelle et le pourcentage d’utilisation de l’exécuteur en ouvrant l’onglet Diagnostic du serveur d’historique de Spark.
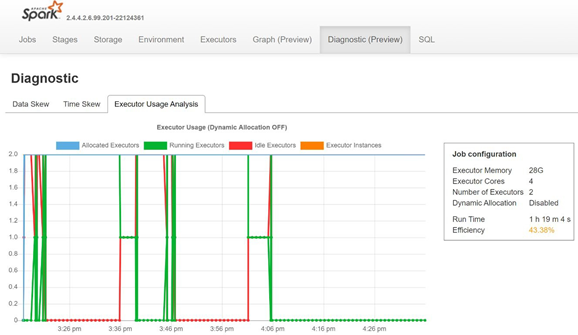
Interpréter les résultats de la preuve de concept
Lorsque vous avez terminé tous les tests de preuve de concept, vous évaluez les résultats. Commencez par évaluer si les objectifs de la preuve de concept ont été atteints et si les résultats souhaités ont été collectés. Déterminez si des tests supplémentaires sont nécessaires ou si des questions doivent être posées.