Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory dans Microsoft Fabric est la prochaine génération de Azure Data Factory, avec une architecture plus simple, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'intégration des données, commencez par Fabric Data Factory. Les charges de travail ADF existantes peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Parfois, vous souhaitez effectuer une migration de données à grande échelle à partir de data lake ou d’un entrepôt de données d’entreprise (EDW) vers Azure. D’autres fois, vous souhaitez ingérer de grandes quantités de données, provenant de différentes sources dans Azure, pour l’analytique big data. Dans chaque cas, il est essentiel d’obtenir des performances et une scalabilité optimales.
les pipelines Azure Data Factory et Azure Synapse Analytics fournissent un mécanisme permettant d’ingérer des données, avec les avantages suivants :
- Gère de grandes quantités de données
- Est très performant
- Est rentable
Ces avantages en font une solution idéale pour les ingénieurs de données qui souhaitent créer des pipelines d’ingestion de données évolutifs et très performants.
Après avoir lu cet article, vous serez en mesure de répondre aux questions suivantes :
- Quel niveau de performance et de scalabilité puis-je obtenir à l’aide de l’activité de copie pour les scénarios de migration de données et d’ingestion de données ?
- Quelles sont les étapes à suivre pour régler les performances de l’activité de copie ?
- Quelles optimisations de performances puis-je utiliser pour une seule exécution d’activité de copie ?
- Quels sont les autres facteurs externes à prendre en compte lors de l’optimisation des performances de copie ?
Note
Si vous n’êtes pas familiarisé avec l’activité de copie, consultez la vue d’ensemble de l’activité de copie avant de lire cet article.
La performance de copie et l'extensibilité atteignables à l'aide des pipelines Azure Data Factory et Synapse
Azure Data Factory et les pipelines Synapse offrent une architecture serverless qui autorise le parallélisme à différents niveaux.
Cette architecture vous permet de développer des pipelines qui optimisent le débit des déplacements de données pour votre environnement. Ces pipelines utilisent pleinement les ressources suivantes :
- Bande passante du réseau entre les magasins de données de la source et de la destination
- Opérations d’entrée/sortie du magasin de données source ou de destination par seconde (IOPS) et bande passante
Cette utilisation complète signifie que vous pouvez estimer le débit global en mesurant le débit minimal disponible avec les ressources suivantes :
- Magasin de données source
- Banque de données de destination
- Bande passante du réseau entre les systèmes de stockage de données de la source et de la destination
Le tableau ci-dessous montre le calcul de la durée du déplacement des données. La durée dans chaque cellule est calculée en fonction d’un réseau donné et de la bande passante de la banque de données, ainsi que d’une taille de charge utile donnée.
Note
La durée fournie ci-dessous vise à représenter des performances atteignables dans une solution d’intégration de données de bout en bout, à l’aide d’une ou de plusieurs techniques d’optimisation des performances décrites dans Fonctionnalités d’optimisation des performances de copie, notamment l’utilisation de ForEach pour partitionner et générer plusieurs activités de copie simultanées. Nous vous recommandons de suivre les étapes indiquées dans Procédure de réglage des performances pour optimiser les performances de copie pour votre jeu de données et votre configuration système spécifiques. Vous devez utiliser les nombres obtenus dans vos tests de réglage des performances pour la planification du déploiement de la production, la planification de la capacité et la projection de la facturation.
| Taille des données / bandwidth |
50 Mbits/s | 100 Mbits/s | 500 Mbits/s | 1 Gbit/s | 5 Gbit/s | 10 Gbits/s | 50 Gbit/s |
|---|---|---|---|---|---|---|---|
| 1 Go | 2,7 min | 1,4 min | 0,3 min | 0,1 min | 0,03 min | 0,01 min | 0,0 min |
| 10 Go | 27,3 min | 13,7 min | 2,7 min | 1,3 min | 0,3 min | 0,1 min | 0,03 min |
| 100 Go | 4,6 heures | 2,3 heures | 0,5 heures | 0,2 heures | 0,05 heures | 0,02 heures | 0,0 heures |
| 1 TO | 46,6 heures | 23,3 heures | 4,7 heures | 2,3 heures | 0,5 heures | 0,2 heures | 0,05 heures |
| 10 To | 19,4 jours | 9,7 jours | 1,9 jours | 0,9 jours | 0,2 jours | 0,1 jours | 0,02 jours |
| 100 To | 194,2 jours | 97,1 jours | 19,4 jours | 9,7 jours | 1,9 jours | 1 jour | 0,2 jours |
| 1 PB | 64,7 mo | 32,4 mo | 6,5 mo | 3,2 mo | 0,6 mo | 0,3 mo | 0,06 mo |
| 10 PB | 647,3 mo | 323,6 mo | 64,7 mo | 31,6 mo | 6,5 mo | 3,2 mo | 0,6 mo |
La copie est évolutive à différents niveaux :
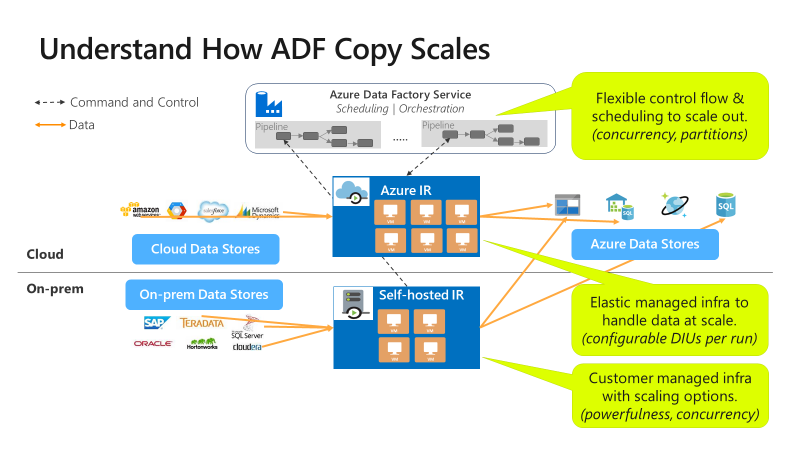
Le flux de contrôle peut démarrer plusieurs activités de copie en parallèle, par exemple Pour chaque boucle.
Une seule activité de copie peut tirer parti de plusieurs ressources de calcul évolutives.
- Lors de l'utilisation du runtime d'intégration Azure (IR), vous pouvez spécifier jusqu'à 256 unités d'intégration de données (DIU) pour chaque activité de copie, de façon sans serveur.
- Lorsque vous utilisez le runtime d’intégration auto-hébergé, vous pouvez adopter l’une des approches suivantes :
- Augmenter manuellement la capacité de la machine.
- Effectuer un scale-out sur plusieurs machines (jusqu’à quatre nœuds), et une seule activité de copie partitionne son ensemble de fichiers sur tous les nœuds.
Une activité de copie unique lit et écrit dans le magasin de données à l’aide de plusieurs threads en parallèle.
Procédure de réglage des performances
Procédez comme suit pour régler les performances de votre service avec l’activité de copie :
Choisir un jeu de données de test et établir une base de référence.
Pendant le développement, testez votre pipeline en utilisant l’activité de copie sur un échantillon de données représentatif. Le jeu de données que vous choisissez doit représenter vos modèles de données typiques avec les attributs suivants :
- Structure de dossiers
- Modèle de fichier
- Schéma de données
Et votre jeu de données doit être suffisamment volumineux pour évaluer les performances de copie. Une taille appropriée prend au moins dix minutes pour que l’activité de copie se termine. Collectez les détails de l’exécution et les caractéristiques des performances après la surveillance de l’activité de copie.
Comment optimiser les performances d’une seule activité de copie :
Nous vous recommandons d’optimiser les performances en utilisant une seule activité de copie.
Si l’activité de copie est exécutée sur un runtime d’intégration Azure :
Commencez avec les valeurs par défaut des paramètres DIU (unités d’intégration de données) et de copie en parallèle.
Si l’activité de copie est exécutée sur un runtime d’intégration auto-hébergé :
Nous vous recommandons d’utiliser un ordinateur dédié pour héberger l'IR. L’ordinateur doit être séparé du serveur qui héberge le magasin de données. Commencez avec les valeurs par défaut du paramètre de copie parallèle en utilisant un seul nœud pour l’IR auto-hébergé.
Effectuez une série de tests de performances. Prenez note des performances atteintes. Incluez les valeurs réelles utilisées, telles que les DIU et les copies parallèles. Reportez-vous à Supervision de l’activité de copie pour savoir comment collecter les résultats des tests et les paramètres de performances utilisés. Pour identifier et résoudre le goulot d’étranglement, découvrez comment résoudre les problèmes liés aux performances de l’activité de copie.
Itérer pour effectuer davantage d’exécutions de tests de performances en suivant les conseils de résolution des problèmes et de réglage. Une fois que les exécutions d’activité de copie unique ne peuvent pas obtenir un meilleur débit, déterminez s’il faut optimiser le débit agrégé en exécutant plusieurs copies simultanément. Cette option est abordée dans le point numéroté suivant.
Comment optimiser le débit agrégé en exécutant plusieurs copies simultanément :
Vous avez désormais optimisé les performances d’une seule activité de copie. Si vous n’avez pas encore atteint les limites supérieures de débit de votre environnement, vous pouvez exécuter plusieurs activités de copie en parallèle. Vous pouvez exécuter en parallèle en utilisant des constructions de flux de contrôle. L’une de ces constructions est la boucle For Each. Pour plus d’informations, consultez les articles suivants relatifs aux modèles de solution :
Étendez la configuration à l’ensemble de votre jeu de données.
Lorsque vous êtes satisfait des résultats et des performances de l’exécution, vous pouvez étendre la définition et le pipeline pour couvrir l’ensemble de votre jeu de données.
Résoudre les problèmes de performance de l’activité de copie
Suivez la procédure de réglage des performances pour planifier et effectuer un test de performances pour votre scénario. Et découvrez comment résoudre les problèmes de performances de chaque exécution d’activité de copie dans Résoudre les problèmes de performances de l’activité de copie.
Fonctionnalités d’optimisation des performances de copie
Le service fournit les fonctionnalités d’optimisation des performances suivantes :
- Unités d’intégration de données
- Extensibilité du runtime d’intégration auto-hébergé
- Copie parallèle
- Copie intermédiaire
Unités d’intégration de données
Une unité d’intégration de données (DIU) est une mesure qui représente la puissance d’une unité unique dans les pipelines Azure Data Factory et Synapse. La puissance est une combinaison de l’allocation des ressources du processeur, de la mémoire et du réseau. DIU s’applique uniquement à Azure runtime d’intégration. DIU ne s’applique pas au runtime d’intégration auto-hébergé. En savoir plus ici.
Extensibilité du runtime d’intégration auto-hébergé
Vous souhaiterez peut-être héberger une charge de travail simultanée croissante. Vous pouvez également chercher à obtenir des performances supérieures dans le cadre de votre charge de travail actuelle. Vous pouvez améliorer l’échelle du traitement en procédant de l’une des manières suivantes :
- Vous pouvez effectuer un scale-up du runtime d’intégration auto-hébergé en augmentant le nombre de travaux simultanés pouvant s’exécuter sur un nœud.
Le scale-up fonctionne uniquement si le processeur et la mémoire du nœud ne sont pas pleinement utilisés. - Vous pouvez effectuer un scale-out du runtime d’intégration auto-hébergé en ajoutant plus de nœuds (machines).
Pour plus d'informations, consultez les pages suivantes :
- fonctionnalités d’optimisation des performances Copy activity : scalabilité du runtime d’intégration auto-hébergé
- Créer et configurer un runtime d’intégration auto-hébergé : Considérations d’échelle
Copie en parallèle
Vous pouvez définir la propriété parallelCopies pour indiquer le parallélisme que vous souhaitez que l’activité de copie utilise. Considérez cette propriété comme le nombre maximal de threads dans l’activité de copie. Les threads fonctionnent en parallèle. Les threads lisent à partir de votre source ou écrivent dans vos magasins de données récepteur.
En savoir plus.
copie intermédiaire
Une opération de copie de données peut envoyer les données directement au magasin de données récepteur. Vous pouvez également choisir d’utiliser le stockage Blob comme magasin de transit temporaire. En savoir plus.
Contenu connexe
Consultez les autres articles relatifs à l’activité de copie :
- vue d’ensemble de l'activité de copie
- Résoudre les problèmes de performances de l’activité de copie
- fonctionnalités d’optimisation des performances de l'activité de copie
- Utilisez Azure Data Factory pour migrer des données de votre lac de données ou entrepôt de données vers Azure
- Migration des données depuis Amazon S3 vers Azure Storage