Conseils de conception pour l'utilisation de tables répliquées dans un pool Synapse SQL
Cet article fournit des suggestions sur la conception de tables répliquées dans votre schéma de pool Synapse SQL. Utilisez ces recommandations pour améliorer les performances des requêtes en réduisant le déplacement de données et la complexité des requêtes.
Prérequis
Cet article suppose que les concepts de distribution et de déplacement de données dans un pool SQL vous sont familiers. Pour plus d’informations, consultez l’article sur l’architecture.
Dans le cadre de la conception d’une table, essayez d’en savoir autant que possible sur vos données et la façon dont elles sont interrogées. Considérez par exemple les questions suivantes :
- Quelle est la taille de la table ?
- Quelle est la fréquence d’actualisation de la table ?
- Est-ce que je dispose de tables de faits et de dimension dans un pool SQL ?
Qu’est-ce qu’une table répliquée ?
Une table répliquée possède une copie complète de la table accessible sur chaque nœud de calcul. La réplication d’une table évite le transfert de données entre des nœuds de calcul avant une jointure ou une agrégation. Étant donné que la table possède plusieurs copies, le fonctionnement des tables répliquées est optimal lorsque la taille de la table est inférieure à 2 Go compressés. 2 Go n’est pas une limite inconditionnelle. Si les données sont statiques et ne changent pas, vous pouvez répliquer des tables plus volumineuses.
Le diagramme suivant illustre une table répliquée accessible sur chaque nœud de calcul. Dans un pool SQL, la table répliquée est entièrement copiée dans une base de données de distribution sur chaque nœud de calcul.

Les tables répliquées fonctionnent bien dans des tables de dimension dans un schéma en étoile. Les tables de dimension sont généralement jointes à des tables de faits, qui sont distribuées différemment de la table de dimension. Les dimensions sont généralement une taille qui permet de stocker et de gérer plusieurs copies. Les dimensions stockent des données descriptives qui se modifient lentement, comme le nom et l’adresse du client, ainsi que les détails sur le produit. La lenteur de la nature changeante des données entraîne moins de maintenance pour la table répliquée.
Envisagez d’utiliser une table répliquée dans les cas suivants :
- La taille de la table sur le disque est inférieure à 2 Go, quel que soit le nombre de lignes. Pour connaître la taille d’une table, vous pouvez utiliser la commande DBCC PDW_SHOWSPACEUSED :
DBCC PDW_SHOWSPACEUSED('ReplTableCandidate'). - La table est utilisée dans des jointures qui requièrent normalement un déplacement des données. Quand vous joignez des tables qui ne sont pas distribuées sur la même colonne, telles qu’une table distribuée par hachage jointe à une table à distribution par tourniquet (round robin), un déplacement des données est nécessaire pour l’exécution de la requête. Si l’une des tables est petite, pensez à utiliser une table répliquée. Nous vous recommandons d’utiliser des tables répliquées au lieu de tables de distribution par tourniquet dans la plupart des cas. Pour consulter les opérations de déplacement des données dans les plans de requêtes, utilisez sys.dm_pdw_request_steps. L’opération BroadcastMoveOperation est l’opération de déplacement de données qui peut généralement être supprimée à l’aide d’une table répliquée.
Les tables répliquées ne produisent sans doute pas les meilleurs résultats dans les cas suivants :
- La table est l’objet d’opérations d’insertion, de mise à jour et de suppression fréquentes. Les opérations DLM (langage de manipulation de données) nécessitent une regénération de la table répliquée. La reconstruction fréquente peut diminuer les performances.
- Le pool SQL est fréquemment mis à l’échelle. La mise à l’échelle d’un pool SQL change le nombre de nœuds de calcul, ce qui entraîne une reconstruction de la table répliquée.
- La table comporte un grand nombre de colonnes, mais les opérations de données n’accèdent généralement qu’à un nombre restreint de colonnes. Dans ce scénario, au lieu de répliquer la table entière, il peut s’avérer plus efficace de distribuer la table et de créer ensuite un index sur les colonnes fréquemment sollicitées. Lorsqu'une requête exige un déplacement des données, le pool SQL déplace uniquement les données des colonnes demandées.
Conseil
Pour plus d’informations sur l’indexation et les tables répliquées, consultez l’ aide-mémoire pour le pool SQL dédié (anciennement SQL DW) dans Azure Synapse Analytics.
Utiliser des tables répliquées avec des prédicats de requête simples
Avant de décider de distribuer ou de répliquer une table, pensez aux types de requêtes que vous projetez d’exécuter sur la table. Lorsque possible,
- Utilisez des tables répliquées pour les requêtes avec des prédicats de requête simples, comme l’égalité ou l’inégalité.
- Utilisez des tables distribuées pour les requêtes avec des prédicats de requête complexes, comme LIKE ou NOT LIKE.
Les requêtes sollicitant beaucoup le processeur fonctionnent de manière optimale lorsque le travail est réparti entre tous les nœuds de calcul. Par exemple, les requêtes qui exécutent des calculs sur chaque ligne d’une table fonctionnent mieux sur les tables distribués que sur les tables répliquées. Étant donné qu’une table répliquée est entièrement stockée sur chaque nœud de calcul, une requête sollicitant beaucoup le processeur sur une table répliquée s’exécute sur la table entière sur chaque nœud de calcul. Le calcul supplémentaire peut ralentir les performances des requêtes.
Par exemple, cette requête comporte un prédicat complexe. Elle s’exécute plus rapidement lorsque les données se trouvent dans une table distribuée au lieu d’une table répliquée. Dans cet exemple, les données peuvent être distribuées par tourniquet.
SELECT EnglishProductName
FROM DimProduct
WHERE EnglishDescription LIKE '%frame%comfortable%';
Convertir les tables de distribution par tourniquet (round-robin) en tables répliquées
Si vous avez déjà des tables de distribution par tourniquet, nous vous recommandons de les convertir en tables répliquées si elles sont conformes aux critères décrits dans cet article. Les tables répliquées ont de meilleures performances que les tables de distribution par tourniquet, car elles éliminent le déplacement des données. Une table de distribution par tourniquet requiert toujours le déplacement des données pour les jointures.
Cet exemple utilise CTAS pour modifier la table DimSalesTerritory en une table répliquée. Cet exemple fonctionne que la table DimSalesTerritory soit distribuée par hachage ou par tourniquet (round robin).
CREATE TABLE [dbo].[DimSalesTerritory_REPLICATE]
WITH
(
HEAP,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory]
OPTION (LABEL = 'CTAS : DimSalesTerritory_REPLICATE')
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[DimSalesTerritory_REPLICATE] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Exemple de performances de requête pour une table de distribution par tourniquet et une table répliquée
Une table répliquée ne nécessite pas le déplacement des données pour les jointures, car la table entière est déjà présente sur chaque nœud de calcul. Si les tables de dimension sont des tables distribuées par tourniquet, une jointure copie entièrement la table de dimension sur chaque nœud de calcul. Pour déplacer les données, le plan de requête contient une opération appelée BroadcastMoveOperation. Ce type d’opération de déplacement des données ralentit les performances des requêtes. Il n’est pas utilisé par les tables répliquées. Pour afficher les étapes relatives au plan de requête, utilisez la vue catalogue système sys.dm_pdw_request_steps.
Par exemple, dans la requête suivante sur le schéma AdventureWorks, la table FactInternetSales est distribuée par hachage. Les tables DimDate et DimSalesTerritory sont des tables de dimension plus petites. Cette requête retourne le total des ventes en Amérique du Nord pour l’année fiscale 2004 :
SELECT [TotalSalesAmount] = SUM(SalesAmount)
FROM dbo.FactInternetSales s
INNER JOIN dbo.DimDate d
ON d.DateKey = s.OrderDateKey
INNER JOIN dbo.DimSalesTerritory t
ON t.SalesTerritoryKey = s.SalesTerritoryKey
WHERE d.FiscalYear = 2004
AND t.SalesTerritoryGroup = 'North America'
Nous avons recréé les tables DimDate et DimSalesTerritory en tant que tables de distribution par tourniquet. Par conséquent, la requête affichait le plan de requête suivant, avec plusieurs opérations de déplacement pour la diffusion :
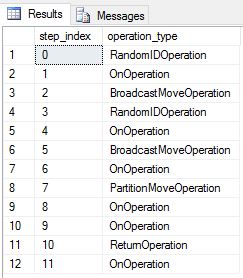
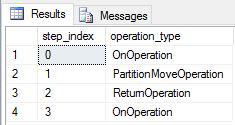
Nous avons recréé les tables DimDate et DimSalesTerritory en tant que tables répliquées et réexécuté la requête. Le plan de requête qui en résulte est beaucoup plus court et ne contient pas de mouvements de diffusion.
Considérations relatives aux performances pour la modification des tables répliquées
Le pool SQL implémente une table répliquée en conservant une version principale de la table. Il copie la version principale dans la première base de données de distribution sur chaque nœud de calcul. En cas de modification, la version de référence est d’abord mise à jour, puis les tables sur chaque nœud de calcul sont reconstruites. Une reconstruction d’une table répliquée implique la copie de la table sur chaque nœud de calcul et la construction des index. Par exemple, une table répliquée sur un DW2000c a cinq copies des données. Une copie principale et une copie complète sur chaque nœud de calcul. Toutes les données sont stockées dans des bases de données de distribution. Le pool SQL utilise ce modèle pour prendre en charge des instructions de modification de données plus rapides et des opérations de mise à l'échelle flexibles.
Les reconstructions asynchrones sont déclenchées par la première requête du tableau répliqué après :
- Des données sont chargées ou modifiées
- L'instance SQL Synapse est mise à l'échelle à un autre niveau
- La définition de la table est mise à jour
Les reconstructions ne sont pas requises après les événements suivants :
- Opération de suspension
- Opération de reprise
La reconstruction ne se produit pas immédiatement après la modification des données. Au lieu de cela, la reconstruction est déclenchée la première fois qu’une requête est sélectionnée à partir de la table. La requête qui a déclenché la reconstruction lit immédiatement à partir de la version principale de la table pendant que les données sont copiées de façon asynchrone sur chaque nœud de calcul. Tant que la copie des données n’est pas terminée, les requêtes suivantes continuent d’utiliser la version principale de la table. Si la table répliquée fait l’objet d’une activité qui entraîne une reconstruction, la copie des données est invalidée et l’instruction select suivante engendre une nouvelle copie des données.
Utilisation restrictive des index
Les pratiques d’indexation standard s’appliquent aux tables répliquées. Le pool SQL reconstruit chaque index de table répliquée dans le cadre de la reconstruction. Utilisez les index uniquement lorsque le gain de performances compense le coût de reconstruction des index.
Chargement de données par lots
Lors du chargement de données dans des tables répliquées, essayez de réduire les reconstructions en regroupant les chargements par lots. Effectuez tous les chargements par lots avant d’exécuter des instructions select.
Par exemple, ce modèle de chargement charge les données à partir de quatre sources et appelle quatre reconstructions.
- Charger à partir de la source 1.
- Instruction select qui déclenche la reconstruction 1.
- Charger à partir de la source 2.
- Instruction select qui déclenche la reconstruction 2.
- Charger à partir de la source 3.
- Instruction select qui déclenche la reconstruction 3.
- Charger à partir de la source 4.
- Instruction select qui déclenche la reconstruction 4.
Par exemple, ce modèle de chargement charge les données à partir de quatre sources mais n’appelle qu’une seule reconstruction.
- Charger à partir de la source 1.
- Charger à partir de la source 2.
- Charger à partir de la source 3.
- Charger à partir de la source 4.
- Instruction select qui déclenche la reconstruction.
Reconstruire une table répliquée après un chargement par lots
Pour garantir des temps d’exécution de requête cohérents, envisagez d’imposer la construction des tables répliquées après un chargement par lots. Sinon, la première requête recourt toujours à un déplacement.
L’opération « Générer un cache de table répliqué » peut exécuter jusqu’à deux opérations simultanément. Par exemple, si vous tentez de reconstruire le cache pour cinq tables, le système utilisera un staticrc20 (qui ne peut pas être modifié) pour construire simultanément deux tables à la fois. Par conséquent, il est recommandé d’éviter l’utilisation de tables répliquées volumineuses dépassant 2 Go, car cela peut ralentir la régénération du cache sur les nœuds et augmenter le temps total.
Cette requête utilise le DMV sys.pdw_replicated_table_cache_state pour répertorier les tables répliquées qui ont été modifiées mais pas reconstruites.
SELECT SchemaName = SCHEMA_NAME(t.schema_id)
, [ReplicatedTable] = t.[name]
, [RebuildStatement] = 'SELECT TOP 1 * FROM ' + '[' + SCHEMA_NAME(t.schema_id) + '].[' + t.[name] +']'
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p
ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady'
AND p.[distribution_policy_desc] = 'REPLICATE'
Pour déclencher une reconstruction, exécutez l’instruction suivante sur chaque table dans la sortie précédente.
SELECT TOP 1 * FROM [ReplicatedTable]
Remarque
Si vous prévoyez de reconstruire les statistiques de la table répliquée non mise en cache, veillez à mettre à jour les statistiques avant de déclencher la mise en cache. La mise à jour des statistiques invalidera le cache, c’est pourquoi la séquence est importante.
Exemple : commencez par UPDATE STATISTICS, puis déclenchez la reconstruction du cache. Dans les exemples suivants, l’exemple correct met à jour les statistiques, puis déclenche la reconstruction du cache.
-- Incorrect sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
SELECT TOP 1 * FROM [ReplicatedTable]
UPDATE STATISTICS [ReplicatedTable]
END
-- Correct sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
UPDATE STATISTICS [ReplicatedTable]
SELECT TOP 1 * FROM [ReplicatedTable]
END
Pour surveiller le processus de reconstruction, vous pouvez utiliser sys.dm_pdw_exec_requests, où le command commence par « BuildReplicatedTableCache ». Par exemple :
-- Monitor Build Replicated Cache
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE command like 'BuildReplicatedTableCache%'
Conseil
Les requêtes de taille de table peuvent être utilisées pour vérifier quelles tables ont une stratégie de distribution répliquée et qui sont supérieures à 2 Go.
Étapes suivantes
Pour créer une table répliquée, utilisez l’une de ces instructions :
Pour une vue d’ensemble des tables distribuées, consultez Tables distribuées.