Considérations relatives à la plateforme d’application pour les charges de travail stratégiques sur Azure
Azure fournit de nombreux services de calcul pour l’hébergement d’applications hautement disponibles. Les services diffèrent en termes de capacité et de complexité. Nous vous recommandons de choisir des services en fonction des points suivants :
- Exigences non fonctionnelles pour la fiabilité, la disponibilité, les performances et la sécurité.
- Facteurs de décision tels que l’extensibilité, le coût, l’opéraabilité et la complexité.
Le choix d’une plateforme d’hébergement d’applications est une décision critique qui affecte tous les autres domaines de conception. Par exemple, les logiciels de développement hérités ou propriétaires peuvent ne pas s’exécuter dans des services PaaS ou des applications conteneurisées. Cette limitation influence votre choix de plateforme de calcul.
Une application stratégique peut utiliser plusieurs services de calcul pour prendre en charge plusieurs charges de travail et microservices composites, chacune avec des exigences distinctes.
Cette zone de conception fournit des recommandations relatives aux options de sélection, de conception et de configuration de calcul. Nous vous recommandons également de vous familiariser avec l’arbre de décision Calcul.
Important
Cet article fait partie de la série de charges de travail stratégiques Azure Well-Architected Framework. Si vous n’êtes pas familiarisé avec cette série, nous vous recommandons de commencer par Qu’est-ce qu’une charge de travail stratégique ?.
Distribution mondiale des ressources de plateforme
Un modèle classique pour une charge de travail stratégique inclut des ressources globales et des ressources régionales.
Les services Azure, qui ne sont pas limités à une région Azure particulière, sont déployés ou configurés en tant que ressources globales. Certains cas d’usage incluent la distribution du trafic entre plusieurs régions, le stockage d’un état permanent pour une application entière et la mise en cache des données statiques globales. Si vous devez prendre en charge à la fois une architecture d’unité d’échelle et une distribution globale, réfléchissez à la façon dont les ressources sont distribuées ou répliquées de manière optimale dans les régions Azure.
D’autres ressources sont déployées au niveau régional. Ces ressources, qui sont déployées dans le cadre d’un tampon de déploiement, correspondent généralement à une unité d’échelle. Toutefois, une région peut avoir plusieurs empreintes et un tampon peut avoir plusieurs unités. La fiabilité des ressources régionales est cruciale, car elle est responsable de l’exécution de la charge de travail principale.
L’image suivante montre la conception générale. Un utilisateur accède à l’application via un point d’entrée global central qui redirige ensuite les demandes vers un tampon de déploiement régional approprié :
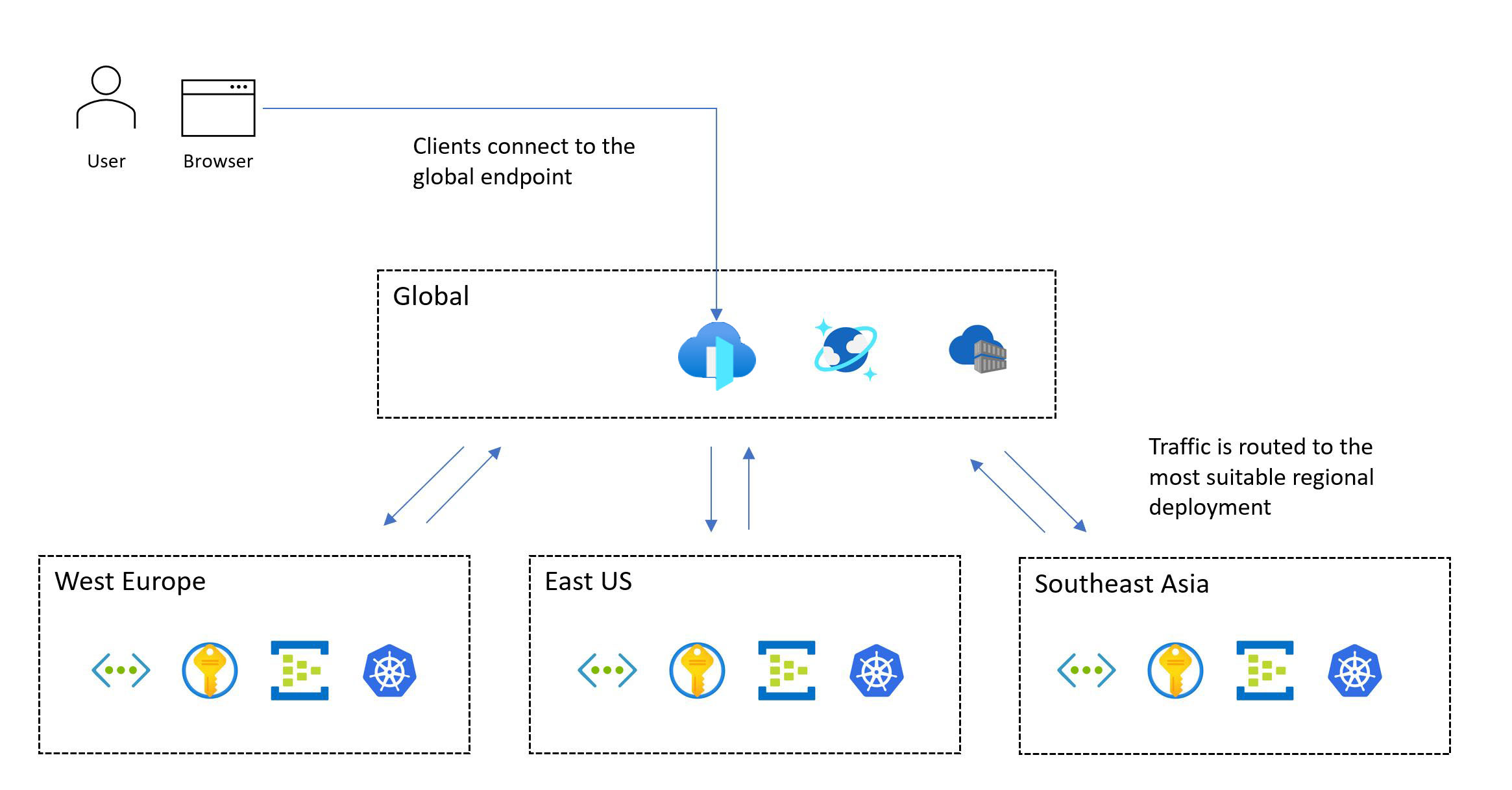
La méthodologie de conception critique nécessite un déploiement multirégion. Ce modèle garantit la tolérance de panne régionale, afin que l’application reste disponible même lorsqu’une région entière tombe en panne. Lorsque vous concevez une application multirégion, envisagez différentes stratégies de déploiement, telles que actives/actives et actives/passives, ainsi que les exigences d’application, car il existe des compromis significatifs pour chaque approche. Pour les charges de travail stratégiques, nous recommandons vivement le modèle actif/actif.
Toutes les charges de travail ne prennent pas en charge ou nécessitent l’exécution simultanée de plusieurs régions. Vous devez évaluer des exigences d’application spécifiques par rapport aux compromis pour déterminer une décision de conception optimale. Pour certains scénarios d’application qui ont des cibles de fiabilité inférieures, les solutions de partitionnement actives/passives ou passives peuvent être des alternatives appropriées.
Les zones de disponibilité peuvent fournir des déploiements régionaux hautement disponibles dans différents centres de données au sein d’une région. Presque tous les services Azure sont disponibles dans une configuration zonale, où le service est délégué à une zone spécifique, ou une configuration redondante interzone, où la plateforme garantit automatiquement que le service s’étend sur plusieurs zones et peut résister à une panne de zone. Ces configurations fournissent une tolérance de panne jusqu’au niveau du centre de données.
Considérations sur la conception
Fonctionnalités régionales et zonales. Tous les services et fonctionnalités ne sont pas disponibles dans chaque région Azure. Cette considération peut affecter les régions que vous choisissez. En outre, les zones de disponibilité ne sont pas disponibles dans chaque région.
Paires régionales. Les régions Azure sont regroupées en paires régionales qui se composent de deux régions dans une seule zone géographique. Certains services Azure utilisent des régions jumelées pour garantir la continuité de l’activité et fournir un niveau de protection contre la perte de données. Par exemple, le stockage géoredondant Azure (GRS) réplique automatiquement les données dans une région jumelée secondaire, ce qui garantit que les données sont durables si la région primaire n’est pas récupérable. Si une panne affecte plusieurs régions Azure, au moins une région de chaque paire est hiérarchisée pour la récupération.
Cohérence des données. Pour les défis de cohérence, envisagez d’utiliser un magasin de données distribué globalement, une architecture régionale marquée et un déploiement partiellement actif/actif. Dans un déploiement partiel, certains composants sont actifs dans toutes les régions, tandis que d’autres se trouvent de manière centralisée dans la région primaire.
Déploiement sécurisé. L’infrastructure SDP (Azure Safe Deployment Practice) garantit que toutes les modifications de code et de configuration (maintenance planifiée) apportées à la plateforme Azure subissent un déploiement par phases. L’intégrité est analysée pour la dégradation pendant la mise en production. Une fois les phases canary et pilote terminées avec succès, les mises à jour de la plateforme sont sérialisées entre les paires régionales, de sorte qu’une seule région de chaque paire est mise à jour à un moment donné.
Capacité de plateforme. Comme n’importe quel fournisseur de cloud, Azure dispose de ressources limitées. L’indisponibilité peut être le résultat des limitations de capacité dans les régions. S’il existe une panne régionale, il y a une augmentation de la demande de ressources à mesure que la charge de travail tente de récupérer dans la région jumelée. La panne peut créer un problème de capacité, où l’offre ne répond pas temporairement à la demande.
Recommandations de conception
Déployez votre solution dans au moins deux régions Azure pour vous protéger contre les pannes régionales. Déployez-le dans des régions qui ont les fonctionnalités et les caractéristiques requises par la charge de travail. Les fonctionnalités doivent répondre aux objectifs de performances et de disponibilité tout en répondant aux exigences de résidence et de rétention des données.
Par exemple, certaines exigences de conformité des données peuvent limiter le nombre de régions disponibles et forcer potentiellement les compromissions de conception. Dans ce cas, nous vous recommandons vivement d’ajouter un investissement supplémentaire dans des wrappers opérationnels pour prédire, détecter et répondre aux défaillances. Supposons que vous soyez limité à une zone géographique avec deux régions, et qu’une seule de ces régions prend en charge les zones de disponibilité (modèle de centre de données 3 + 1). Créez un modèle de déploiement secondaire à l’aide d’une isolation de domaine d’erreur pour permettre le déploiement des deux régions dans une configuration active et assurez-vous que la région primaire héberge plusieurs tampons de déploiement.
Si les régions Azure appropriées n’offrent pas toutes les fonctionnalités dont vous avez besoin, préparez-vous à compromettre la cohérence des tampons de déploiement régionaux pour hiérarchiser la distribution géographique et optimiser la fiabilité. Si une seule région Azure convient, déployez plusieurs tampons de déploiement (unités d’échelle régionale) dans la région sélectionnée pour atténuer certains risques et utiliser des zones de disponibilité pour assurer la tolérance de panne au niveau du centre de données. Toutefois, une telle compromission significative dans la distribution géographique limite considérablement le SLO composite pouvant être atteint et la fiabilité globale.
Important
Pour les scénarios qui ciblent un SLO supérieur ou égal à 99,99 %, nous vous recommandons un minimum de trois régions de déploiement. Calculez le SLO composite pour tous les flux utilisateur. Assurez-vous que ces cibles sont alignées sur les cibles métier.
Pour les scénarios d’application à grande échelle qui ont des volumes importants de trafic, concevez la solution pour effectuer une mise à l’échelle entre plusieurs régions pour parcourir les contraintes de capacité potentielles dans une seule région. Des tampons de déploiement régionaux supplémentaires peuvent obtenir un SLO composite plus élevé. Pour plus d’informations, consultez comment implémenter des cibles multirégions.
Définissez et validez vos objectifs de point de récupération (RPO) et vos objectifs de temps de récupération (RTO).
Dans une zone géographique unique, hiérarchisez l’utilisation de paires régionales pour bénéficier des déploiements sérialisés SDP pour la maintenance planifiée et la hiérarchisation régionale pour une maintenance non planifiée.
Colocalisez géographiquement des ressources Azure avec des utilisateurs pour réduire la latence du réseau et optimiser les performances de bout en bout.
- Vous pouvez également utiliser des solutions telles qu’un réseau de distribution de contenu (CDN) ou une mise en cache de périphérie pour générer une latence réseau optimale pour les bases d’utilisateurs distribuées. Pour plus d’informations, consultez Routage du trafic global, Services de remise d’applications et Mise en cache et distribution de contenu statique.
Aligner la disponibilité actuelle du service avec les feuilles de route des produits lorsque vous choisissez des régions de déploiement. Certains services peuvent ne pas être immédiatement disponibles dans chaque région.
Mise en conteneur
Un conteneur inclut le code de l’application et les fichiers de configuration, les bibliothèques et les dépendances associés que l’application doit exécuter. La conteneurisation fournit une couche d’abstraction pour le code d’application et ses dépendances et crée une séparation de la plateforme d’hébergement sous-jacente. Le package logiciel unique est hautement portable et peut s’exécuter de manière cohérente sur différentes plateformes d’infrastructure et fournisseurs de cloud. Les développeurs n’ont pas besoin de réécrire du code et peuvent déployer des applications plus rapidement et plus fiablement.
Important
Nous vous recommandons d’utiliser des conteneurs pour les packages d’applications stratégiques. Ils améliorent l’utilisation de l’infrastructure, car vous pouvez héberger plusieurs conteneurs sur la même infrastructure virtualisée. En outre, étant donné que tous les logiciels sont inclus dans le conteneur, vous pouvez déplacer l’application sur différents systèmes d’exploitation, quels que soient les runtimes ou les versions de bibliothèque. La gestion est également plus facile avec les conteneurs qu’avec l’hébergement virtualisé traditionnel.
Les applications stratégiques doivent être mises à l’échelle rapidement pour éviter les goulots d’étranglement des performances. Étant donné que les images conteneur sont prédéfinies, vous pouvez limiter le démarrage à se produire uniquement pendant le démarrage de l’application, ce qui offre une scalabilité rapide.
Considérations sur la conception
Supervision. Il peut être difficile pour les services de surveillance d’accéder aux applications qui se trouvent dans des conteneurs. Vous avez généralement besoin d’un logiciel tiers pour collecter et stocker des indicateurs d’état de conteneur tels que l’utilisation du processeur ou de la RAM.
Sécurité. Le noyau du système d’exploitation de la plateforme d’hébergement est partagé entre plusieurs conteneurs, ce qui crée un point d’attaque unique. Toutefois, le risque d’accès aux machines virtuelles hôtes est limité, car les conteneurs sont isolés du système d’exploitation sous-jacent.
État. Bien qu’il soit possible de stocker des données dans le système de fichiers d’un conteneur en cours d’exécution, les données ne sont pas conservées lorsque le conteneur est recréé. Au lieu de cela, conservez les données en montant le stockage externe ou à l’aide d’une base de données externe.
Recommandations de conception
Conteneuriser tous les composants d’application. Utilisez des images conteneur comme modèle principal pour les packages de déploiement d’applications.
Hiérarchisez les runtimes de conteneurs Basés sur Linux lorsque cela est possible. Les images sont plus légères et de nouvelles fonctionnalités pour les nœuds/conteneurs Linux sont fréquemment publiées.
Rendre les conteneurs immuables et remplaçables, avec des cycles de vie courts.
Veillez à collecter tous les journaux et métriques pertinents à partir du conteneur, de l’hôte de conteneur et du cluster sous-jacent. Envoyez les journaux et métriques collectés à un récepteur de données unifié pour un traitement et une analyse supplémentaires.
Stockez des images conteneur dans Azure Container Registry. Utilisez la géoréplication pour répliquer des images conteneur dans toutes les régions. Permettre à Microsoft Defender pour les registres de conteneurs de fournir une analyse des vulnérabilités pour les images conteneur. Assurez-vous que l’accès au Registre est géré par l’ID Microsoft Entra.
Hébergement et orchestration de conteneurs
Plusieurs plateformes d’applications Azure peuvent héberger efficacement des conteneurs. Il existe des avantages et des inconvénients associés à chacune de ces plateformes. Comparez les options dans le contexte de vos besoins métier. Toutefois, optimisez toujours la fiabilité, la scalabilité et les performances. Pour plus d’informations, consultez les articles suivants :
Important
Azure Kubernetes Service (AKS) et Azure Container Apps doivent être parmi vos premiers choix pour la gestion des conteneurs en fonction de vos besoins. Bien qu’Azure App Service ne soit pas un orchestrateur, en tant que plateforme de conteneur à faible friction, il s’agit toujours d’une alternative possible à AKS.
Considérations et recommandations relatives à la conception pour Azure Kubernetes Service
AKS, un service Kubernetes managé, permet l’approvisionnement rapide de cluster sans nécessiter d’activités d’administration de cluster complexes et offre un ensemble de fonctionnalités qui inclut des fonctionnalités avancées de mise en réseau et d’identité. Pour obtenir un ensemble complet de recommandations, consultez la révision d’Azure Well-Architected Framework - AKS.
Important
Il existe certaines décisions de configuration fondamentales que vous ne pouvez pas modifier sans redéployer le cluster AKS. Les exemples incluent le choix entre les clusters AKS publics et privés, l’activation d’Azure Network Policy, l’intégration de Microsoft Entra et l’utilisation d’identités managées pour AKS au lieu de principaux de service.
Fiabilité
AKS gère le plan de contrôle Kubernetes natif. Si le plan de contrôle n’est pas disponible, la charge de travail subit un temps d’arrêt. Tirez parti des fonctionnalités de fiabilité offertes par AKS :
Déployez des clusters AKS dans différentes régions Azure en tant qu’unité d’échelle pour optimiser la fiabilité et la disponibilité. Utilisez des zones de disponibilité pour optimiser la résilience au sein d’une région Azure en distribuant le plan de contrôle AKS et les nœuds d’agent sur des centres de données physiquement distincts. Toutefois, si la latence de colocalisation est un problème, vous pouvez effectuer un déploiement AKS dans une seule zone ou utiliser des groupes de placement de proximité pour réduire la latence internode.
Utilisez le contrat SLA de temps d’activité AKS pour les clusters de production pour optimiser les garanties de disponibilité des points de terminaison d’API Kubernetes.
Évolutivité
Prenez en compte les limites d’échelle AKS, comme le nombre de nœuds, les pools de nœuds par cluster et les clusters par abonnement.
Si les limites d’échelle sont une contrainte, tirez parti de la stratégie d’unité d’échelle et déployez davantage d’unités avec des clusters.
Activez la mise à l’échelle automatique de cluster pour ajuster automatiquement le nombre de nœuds d’agent en réponse aux contraintes de ressources.
Utilisez l’autoscaler de pod horizontal pour ajuster le nombre de pods dans un déploiement en fonction de l’utilisation du processeur ou d’autres métriques.
Pour les scénarios à grande échelle et en rafale, envisagez d’utiliser des nœuds virtuels pour une mise à l’échelle étendue et rapide.
Définissez les demandes et limites des ressources de pod dans les manifestes de déploiement d’application. Si ce n’est pas le cas, vous pouvez rencontrer des problèmes de performances.
Isolation
Conservez les limites entre l’infrastructure utilisée par la charge de travail et les outils système. L’infrastructure de partage peut entraîner une utilisation élevée des ressources et des scénarios voisins bruyants.
Utilisez des pools de nœuds distincts pour les services système et de charge de travail. Les pools de nœuds dédiés pour les composants de charge de travail doivent être basés sur les exigences des ressources d’infrastructure spécialisées, telles que les machines virtuelles GPU à mémoire élevée. En général, pour réduire la surcharge de gestion inutile, évitez de déployer un grand nombre de pools de nœuds.
Utilisez des teintes et des tolérances pour fournir des nœuds dédiés et limiter les applications gourmandes en ressources.
Évaluez les exigences d’affinité d’application et d’anti-affinité et configurez la colocalisation appropriée des conteneurs sur les nœuds.
Sécurité
La vanille par défaut Kubernetes nécessite une configuration significative pour garantir une posture de sécurité appropriée pour les scénarios stratégiques. AKS résout différents risques de sécurité hors de la boîte de dialogue. Les fonctionnalités incluent des clusters privés, l’audit et la connexion dans Log Analytics, des images de nœud renforcées et des identités managées.
Appliquez des instructions de configuration fournies dans la base de référence de sécurité AKS.
Utilisez les fonctionnalités AKS pour gérer l’identité du cluster et la gestion des accès afin de réduire la surcharge opérationnelle et d’appliquer une gestion cohérente des accès.
Utilisez des identités managées au lieu des principaux de service pour éviter la gestion et la rotation des informations d’identification. Vous pouvez ajouter des identités managées au niveau du cluster. Au niveau du pod, vous pouvez utiliser des identités managées via ID de charge de travail Microsoft Entra.
Utilisez l’intégration de Microsoft Entra pour la gestion centralisée des comptes et les mots de passe, la gestion des accès aux applications et la protection améliorée des identités. Utilisez RBAC Kubernetes avec l’ID Microsoft Entra pour les privilèges minimum et réduisez l’octroi de privilèges d’administrateur pour protéger l’accès à la configuration et aux secrets. En outre, limitez l’accès au fichier de configuration du cluster Kubernetes à l’aide du contrôle d’accès en fonction du rôle Azure. Limitez l’accès aux actions que les conteneurs peuvent effectuer, fournissez le moins d’autorisations et évitez l’utilisation de l’escalade des privilèges racines.
Mises à niveau
Les clusters et les nœuds doivent être mis à niveau régulièrement. AKS prend en charge les versions de Kubernetes en alignement avec le cycle de mise en production de Kubernetes natif.
Abonnez-vous à la feuille de route et aux notes de publication d’AKS publiques sur GitHub pour rester à jour sur les modifications, améliorations et, plus important encore, les versions de Kubernetes et les dépréciations.
Appliquez les instructions fournies dans la liste de contrôle AKS pour garantir l’alignement avec les meilleures pratiques.
Tenez compte des différentes méthodes prises en charge par AKS pour la mise à jour des nœuds et/ou des clusters. Ces méthodes peuvent être manuelles ou automatisées. Vous pouvez utiliser la maintenance planifiée pour définir des fenêtres de maintenance pour ces opérations. De nouvelles images sont publiées chaque semaine. AKS prend également en charge les canaux de mise à niveau automatique pour la mise à niveau automatique des clusters AKS vers des versions plus récentes de Kubernetes et/ou des images de nœud plus récentes lorsqu’elles sont disponibles.
Mise en réseau
Évaluez les plug-ins réseau qui correspondent le mieux à votre cas d’usage. Déterminez si vous avez besoin d’un contrôle granulaire du trafic entre les pods. support Azure s kubenet, Azure CNI et apportez votre propre CNI pour des cas d’usage spécifiques.
Hiérarchiser l’utilisation d’Azure CNI après avoir évalué les exigences réseau et la taille du cluster. Azure CNI permet d’utiliser des stratégies réseau Azure ou Calico pour contrôler le trafic au sein du cluster.
Surveillance
Vos outils de supervision doivent être en mesure de capturer les journaux et les métriques à partir de pods en cours d’exécution. Vous devez également collecter des informations à partir de l’API Métriques Kubernetes pour surveiller l’intégrité des ressources et charges de travail en cours d’exécution.
Utilisez Azure Monitor et Application Insights pour collecter des métriques, des journaux et des diagnostics à partir de ressources AKS pour la résolution des problèmes.
Activez et passez en revue les journaux des ressources Kubernetes.
Configurez les métriques Prometheus dans Azure Monitor. Container Insights dans Monitor fournit une intégration, active les fonctionnalités de surveillance prêtes à l’emploi et offre des fonctionnalités plus avancées via la prise en charge intégrée de Prometheus.
Gouvernance
Utilisez des stratégies pour appliquer des protections centralisées aux clusters AKS de manière cohérente. Appliquez des attributions de stratégie à une étendue d’abonnement ou une version ultérieure pour assurer la cohérence entre les équipes de développement.
Contrôlez les fonctions accordées aux pods et indiquez si l’exécution contredit la stratégie, à l’aide d’Azure Policy. Cet accès est défini par le biais de stratégies intégrées fournies par le module complémentaire Azure Policy pour AKS.
Établissez une base de référence cohérente de fiabilité et de sécurité pour les configurations de cluster et de pod AKS à l’aide d’Azure Policy.
Utilisez le module complémentaire Azure Policy pour AKS pour contrôler les fonctions de pod, telles que les privilèges racines, et pour interdire les pods qui ne sont pas conformes à la stratégie.
Remarque
Lorsque vous effectuez un déploiement dans une zone d’atterrissage Azure, les stratégies Azure pour vous aider à garantir une fiabilité et une sécurité cohérentes doivent être fournies par l’implémentation de la zone d’atterrissage.
Les implémentations de référence stratégiques fournissent une suite de stratégies de référence pour gérer les configurations de fiabilité et de sécurité recommandées.
Considérations et recommandations relatives à la conception pour Azure App Service
Pour les scénarios de charge de travail basés sur le web et l’API, App Service peut être une alternative possible à AKS. Il fournit une plateforme de conteneurs à faible friction sans la complexité de Kubernetes. Pour obtenir un ensemble complet de recommandations, consultez considérations relatives à la fiabilité pour App Service et l’excellence opérationnelle pour App Service.
Fiabilité
Évaluer l’utilisation des ports TCP et SNAT. Les connexions TCP sont utilisées pour toutes les connexions sortantes. Les ports SNAT sont utilisés pour les connexions sortantes aux adresses IP publiques. L’épuisement des ports SNAT est un scénario d’échec courant. Vous devez détecter ce problème de manière prédictive en effectuant des tests de charge lors de l’utilisation de Diagnostics Azure pour surveiller les ports. Si des erreurs SNAT se produisent, vous devez effectuer une mise à l’échelle sur plus ou plus de workers ou implémenter des pratiques de codage pour préserver et réutiliser les ports SNAT. Des exemples de pratiques de codage que vous pouvez utiliser incluent le regroupement de connexions et le chargement différé des ressources.
L’épuisement des ports TCP est un autre scénario d’échec. Elle se produit lorsque la somme des connexions sortantes d’un worker donné dépasse la capacité. Le nombre de ports TCP disponibles dépend de la taille du worker. Pour obtenir des recommandations, consultez les ports TCP et SNAT.
Évolutivité
Planifiez les futures exigences d’extensibilité et la croissance de l’application afin de pouvoir appliquer les recommandations appropriées dès le début. En procédant ainsi, vous pouvez éviter la dette de migration technique à mesure que la solution augmente.
Activez la mise à l’échelle automatique pour vous assurer que les ressources adéquates sont disponibles pour les demandes de service. Évaluez la mise à l’échelle par application pour l’hébergement à haute densité sur App Service.
N’oubliez pas que App Service a une limite réversible par défaut des instances par plan App Service.
Appliquez des règles de mise à l’échelle automatique. Un plan App Service est mis à l’échelle si une règle au sein du profil est remplie, mais uniquement si toutes les règles du profil sont remplies. Utilisez une combinaison de règles de scale-out et de scale-in pour vous assurer que la mise à l’échelle automatique peut prendre des mesures pour effectuer un scale-out et un scale-in. Comprendre le comportement de plusieurs règles de mise à l’échelle dans un seul profil.
N’oubliez pas que vous pouvez activer la mise à l’échelle par application au niveau du plan App Service pour permettre à une application de s’adapter indépendamment du plan App Service qui l’héberge. Les applications sont allouées aux nœuds disponibles par le biais d’une approche optimale pour une distribution uniforme. Bien qu’une distribution uniforme ne soit pas garantie, la plateforme garantit que deux instances de la même application ne sont pas hébergées sur la même instance.
Surveillance
Surveillez le comportement de l’application et accédez aux journaux et métriques pertinents pour vous assurer que votre application fonctionne comme prévu.
Vous pouvez utiliser la journalisation des diagnostics pour ingérer des journaux au niveau de l’application et au niveau de la plateforme dans Log Analytics, Stockage Azure ou un outil tiers via Azure Event Hubs.
L’analyse des performances des applications avec Application Insights fournit des insights approfondis sur les performances des applications.
Les applications stratégiques doivent avoir la capacité d’auto-guérir en cas de défaillance. Activez la réparation automatique pour recycler automatiquement les workers défectueux.
Vous devez utiliser les contrôles d’intégrité appropriés pour évaluer toutes les dépendances en aval critiques, ce qui permet de garantir l’intégrité globale. Nous vous recommandons vivement d’activer le contrôle d’intégrité pour identifier les travailleurs non réactifs.
Déploiement
Pour contourner la limite par défaut des instances par plan App Service, déployez des plans App Service dans plusieurs unités d’échelle dans une seule région. Déployez des plans App Service dans une configuration de zone de disponibilité pour vous assurer que les nœuds Worker sont répartis entre les zones d’une région. Envisagez d’ouvrir un ticket de support pour augmenter le nombre maximal de workers à deux fois le nombre d’instances dont vous avez besoin pour traiter une charge maximale normale.
Registre de conteneurs
Les registres de conteneurs hébergent des images déployées sur des environnements d’exécution de conteneur comme AKS. Vous devez configurer soigneusement vos registres de conteneurs pour les charges de travail stratégiques. Une panne ne doit pas entraîner de retards dans l’extraction d’images, en particulier pendant les opérations de mise à l’échelle. Les considérations et recommandations suivantes se concentrent sur Azure Container Registry et explorent les compromis associés aux modèles de déploiement centralisés et fédérés.
Considérations sur la conception
Format. Envisagez d’utiliser un registre de conteneurs qui s’appuie sur le format et les normes fournis par Docker pour les opérations push et pull. Ces solutions sont compatibles et principalement interchangeables.
Modèle de déploiement. Vous pouvez déployer le registre de conteneurs en tant que service centralisé consommé par plusieurs applications au sein de votre organisation. Vous pouvez également le déployer en tant que composant dédié pour une charge de travail d’application spécifique.
Registres publics. Les images conteneur sont stockées dans Docker Hub ou dans d’autres registres publics qui existent en dehors d’Azure et d’un réseau virtuel donné. Ce n’est pas nécessairement un problème, mais cela peut entraîner différents problèmes liés à la disponibilité du service, à la limitation et à l’exfiltration des données. Pour certains scénarios d’application, vous devez répliquer des images conteneur publiques dans un registre de conteneurs privé pour limiter le trafic de sortie, augmenter la disponibilité ou éviter une limitation potentielle.
Recommandations de conception
Utilisez des instances de registre de conteneurs dédiées à la charge de travail de l’application. Évitez de créer une dépendance sur un service centralisé, sauf si les exigences de disponibilité et de fiabilité de l’organisation sont entièrement alignées sur l’application.
Dans le modèle d’architecture de base recommandé, les registres de conteneurs sont des ressources globales qui vivent longtemps. Envisagez d’utiliser un registre de conteneurs global unique par environnement. Par exemple, utilisez un registre de production global.
Vérifiez que le contrat SLA pour le registre public est aligné sur vos cibles de fiabilité et de sécurité. Notez particulièrement les limites de limitation pour les cas d’usage qui dépendent de Docker Hub.
Hiérarchiser Azure Container Registry pour l’hébergement d’images conteneur.
Considérations et recommandations relatives à la conception pour Azure Container Registry
Ce service natif fournit une gamme de fonctionnalités, notamment la géoréplication, l’authentification Microsoft Entra, la génération automatisée de conteneurs et la mise à jour corrective via des tâches Container Registry.
Fiabilité
Configurez la géoréplication sur toutes les régions de déploiement pour supprimer les dépendances régionales et optimiser la latence. Container Registry prend en charge la haute disponibilité par le biais de la géoréplication vers plusieurs régions configurées, ce qui offre une résilience contre les pannes régionales. Si une région devient indisponible, les autres régions continuent de traiter les demandes d’image. Lorsque la région est de retour en ligne, Container Registry récupère et réplique les modifications qui y sont apportées. Cette fonctionnalité assure également une colocation du registre au sein de chaque région configurée, ce qui réduit la latence réseau et les coûts de transfert de données entre régions.
Dans les régions Azure qui fournissent une prise en charge de zone de disponibilité, le niveau Premium Container Registry prend en charge la redondance de zone pour assurer la protection contre les défaillances zonales. Le niveau Premium prend également en charge les points de terminaison privés pour empêcher l’accès non autorisé au Registre, ce qui peut entraîner des problèmes de fiabilité.
Héberger des images proches des ressources de calcul consommatrices, dans les mêmes régions Azure.
Verrouillage d’image
Les images peuvent être supprimées, par exemple une erreur manuelle. Container Registry prend en charge le verrouillage d’une version d’image ou d’un référentiel pour empêcher les modifications ou les suppressions. Lorsqu’une version d’image précédemment déployée est modifiée, les déploiements de même version peuvent fournir des résultats différents avant et après la modification.
Si vous souhaitez protéger l’instance Container Registry contre la suppression, utilisez des verrous de ressources.
Images étiquetées
Les images Container Registry étiquetées sont mutables par défaut, ce qui signifie que la même balise peut être utilisée sur plusieurs images envoyées au registre. Dans les scénarios de production, cela peut entraîner un comportement imprévisible susceptible d’affecter le temps d’activité de l’application.
Gestion des identités et des accès
Utilisez l’authentification intégrée Microsoft Entra pour envoyer et tirer des images au lieu d’utiliser des clés d’accès. Pour renforcer la sécurité, désactivez entièrement l’utilisation de la clé d’accès administrateur.
Calcul serverless
Le calcul serverless fournit des ressources à la demande et élimine la nécessité de gérer l’infrastructure. Le fournisseur de cloud provisionne, met à l’échelle et gère automatiquement les ressources nécessaires pour exécuter le code d’application déployé. Azure fournit plusieurs plateformes de calcul serverless :
Azure Functions. Lorsque vous utilisez Azure Functions, la logique d’application est implémentée en tant que blocs distincts de code ou de fonctions, qui s’exécutent en réponse à des événements, comme une requête HTTP ou un message de file d’attente. Chaque fonction est mise à l’échelle si nécessaire pour répondre à la demande.
Azure Logic Apps. Logic Apps convient le mieux à la création et à l’exécution de flux de travail automatisés qui intègrent différentes applications, sources de données, services et systèmes. Comme Azure Functions, Logic Apps utilise des déclencheurs intégrés pour le traitement piloté par les événements. Toutefois, au lieu de déployer du code d’application, vous pouvez créer des applications logiques à l’aide d’une interface utilisateur graphique qui prend en charge des blocs de code tels que des conditions et des boucles.
Azure API Management : Vous pouvez utiliser Gestion des API pour publier, transformer, gérer et surveiller des API de sécurité améliorées à l’aide du niveau Consommation.
Power Apps et Power Automate. Ces outils fournissent une expérience de développement à faible code ou sans code, avec une logique de flux de travail et des intégrations simples configurables par le biais de connexions dans une interface utilisateur.
Pour les applications stratégiques, les technologies serverless fournissent un développement et des opérations simplifiés, ce qui peut être utile pour les cas d’usage métier simples. Toutefois, cette simplicité est le coût de la flexibilité en termes d’extensibilité, de fiabilité et de performances, et ce n’est pas viable pour la plupart des scénarios d’application stratégiques.
Les sections suivantes fournissent des considérations et des recommandations de conception pour l’utilisation d’Azure Functions et de Logic Apps en tant que plateformes alternatives pour les scénarios de flux de travail non critiques.
Considérations et recommandations relatives à la conception pour Azure Functions
Les charges de travail critiques ont des flux système critiques et non critiques. Azure Functions est un choix viable pour les flux qui n’ont pas les mêmes exigences métier strictes que les flux système critiques. Il convient parfaitement aux flux pilotés par les événements qui ont des processus de courte durée, car les fonctions effectuent des opérations distinctes qui s’exécutent aussi rapidement que possible.
Choisissez une option d’hébergement Azure Functions appropriée pour le niveau de fiabilité de l’application. Nous vous recommandons le plan Premium, car il vous permet de configurer la taille de l’instance de calcul. Le plan dédié est l’option la moins serverless. Il fournit une mise à l’échelle automatique, mais ces opérations de mise à l’échelle sont plus lentes que celles des autres plans. Nous vous recommandons d’utiliser le plan Premium pour optimiser la fiabilité et les performances.
Certaines considérations de sécurité sont prises en compte. Lorsque vous utilisez un déclencheur HTTP pour exposer un point de terminaison externe, utilisez un pare-feu d’applications web (WAF) pour fournir un niveau de protection pour le point de terminaison HTTP à partir de vecteurs d’attaque externes courants.
Nous vous recommandons d’utiliser des points de terminaison privés pour restreindre l’accès aux réseaux virtuels privés. Ils peuvent également atténuer les risques d’exfiltration des données, comme les scénarios d’administration malveillants.
Vous devez utiliser des outils d’analyse du code sur du code Azure Functions et intégrer ces outils à des pipelines CI/CD.
Considérations et recommandations relatives à la conception pour Azure Logic Apps
Comme Azure Functions, Logic Apps utilise des déclencheurs intégrés pour le traitement piloté par les événements. Toutefois, au lieu de déployer du code d’application, vous pouvez créer des applications logiques à l’aide d’une interface utilisateur graphique qui prend en charge des blocs tels que des conditions, des boucles et d’autres constructions.
Plusieurs modes de déploiement sont disponibles. Nous recommandons le mode Standard pour garantir un déploiement à locataire unique et atténuer les scénarios de voisins bruyants. Ce mode utilise le runtime Logic Apps à locataire unique conteneur, basé sur Azure Functions. Dans ce mode, l’application logique peut avoir plusieurs flux de travail avec état et sans état. Vous devez connaître les limites de configuration.
Migrations contraintes via IaaS
De nombreuses applications qui ont des déploiements locaux existants utilisent des technologies de virtualisation et du matériel redondant pour fournir des niveaux critiques de fiabilité. La modernisation est souvent entravée par les contraintes métier qui empêchent l’alignement complet avec le modèle d’architecture de base natif cloud (North Star) recommandé pour les charges de travail stratégiques. C’est pourquoi de nombreuses applications adoptent une approche par phases, avec des déploiements cloud initiaux à l’aide de la virtualisation et d’Azure Machines Virtuelles comme modèle d’hébergement d’application principal. L’utilisation des machines virtuelles IaaS (Infrastructure as a Service) peut être nécessaire dans certains scénarios :
- Les services PaaS disponibles ne fournissent pas les performances ou le niveau de contrôle requis.
- La charge de travail nécessite un accès au système d’exploitation, des pilotes spécifiques ou des configurations réseau et système.
- La charge de travail ne prend pas en charge l’exécution dans des conteneurs.
- Il n’existe aucune prise en charge du fournisseur pour les charges de travail tierces.
Cette section se concentre sur les meilleures façons d’utiliser Machines Virtuelles et les services associés pour optimiser la fiabilité de la plateforme d’application. Il met en évidence les aspects clés de la méthodologie de conception critique qui transposent les scénarios de migration cloud natifs et IaaS.
Considérations sur la conception
Les coûts opérationnels liés à l’utilisation de machines virtuelles IaaS sont beaucoup plus élevés que les coûts d’utilisation des services PaaS en raison des exigences de gestion des machines virtuelles et des systèmes d’exploitation. La gestion des machines virtuelles nécessite le déploiement fréquent des packages logiciels et des mises à jour.
Azure offre des fonctionnalités pour augmenter la disponibilité des machines virtuelles :
- Les zones de disponibilité peuvent vous aider à atteindre des niveaux de fiabilité encore plus élevés en distribuant des machines virtuelles entre des centres de données physiquement séparés au sein d’une région.
- Les groupes de machines virtuelles identiques Azure fournissent des fonctionnalités permettant de mettre automatiquement à l’échelle le nombre de machines virtuelles d’un groupe. Ils fournissent également des fonctionnalités permettant de surveiller l’intégrité des instances et de réparer automatiquement des instances non saines.
- Les groupes identiques avec orchestration flexible peuvent vous aider à vous protéger contre les défaillances réseau, disque et d’alimentation en distribuant automatiquement des machines virtuelles entre des domaines d’erreur.
Recommandations de conception
Important
Utilisez les services et conteneurs PaaS si possible pour réduire la complexité opérationnelle et le coût. Utilisez des machines virtuelles IaaS uniquement lorsque vous devez le faire.
Tailles de référence SKU de machine virtuelle de taille appropriée pour garantir une utilisation efficace des ressources.
Déployez trois machines virtuelles ou plus dans des zones de disponibilité pour obtenir une tolérance de panne au niveau du centre de données.
- Si vous déployez des logiciels commerciaux hors plateau, consultez le fournisseur de logiciels et testez correctement avant de déployer le logiciel en production.
Pour les charges de travail que vous ne pouvez pas déployer dans les zones de disponibilité, utilisez des groupes de machines virtuelles identiques flexibles qui contiennent trois machines virtuelles ou plus. Pour plus d’informations sur la configuration du nombre correct de domaines d’erreur, consultez Gérer les domaines d’erreur dans les groupes identiques.
Hiérarchiser l’utilisation des groupes de machines virtuelles identiques pour la scalabilité et la redondance de zone. Ce point est particulièrement important pour les charges de travail qui ont des charges variables. Par exemple, si le nombre d’utilisateurs actifs ou de demandes par seconde est une charge variable.
N’accédez pas directement aux machines virtuelles individuelles. Utilisez des équilibreurs de charge devant eux lorsque cela est possible.
Pour vous protéger contre les pannes régionales, déployez des machines virtuelles d’application dans plusieurs régions Azure.
- Pour plus d’informations sur la façon d’acheminer le trafic entre les régions de déploiement actives, consultez la zone de conception de la mise en réseau et de la connectivité.
Pour les charges de travail qui ne prennent pas en charge les déploiements actifs/actifs multirégions, envisagez d’implémenter des déploiements actifs/passifs à l’aide de machines virtuelles de secours chaudes/chaudes pour le basculement régional.
Utilisez des images standard de Place de marché Azure plutôt que des images personnalisées qui doivent être conservées.
Implémentez des processus automatisés pour déployer et déployer des modifications sur des machines virtuelles, ce qui évite toute intervention manuelle. Pour plus d’informations, consultez considérations IaaS dans la zone de conception des procédures opérationnelles.
Implémentez des expériences de chaos pour injecter des erreurs d’application dans des composants de machine virtuelle et observer l’atténuation des erreurs. Pour plus d’informations, consultez Validation et test continus.
Surveillez les machines virtuelles et vérifiez que les journaux de diagnostic et les métriques sont ingérés dans un récepteur de données unifié.
Implémentez des pratiques de sécurité pour les scénarios d’application stratégiques, le cas échéant, et les meilleures pratiques de sécurité pour les charges de travail IaaS dans Azure.
Étape suivante
Passez en revue les considérations relatives à la plateforme de données.