Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Ce contenu est un extrait de l’eBook, Architecting Cloud Native .NET Applications pour Azure, disponible sur .NET Docs ou en tant que PDF téléchargeable gratuitement qui peut être lu hors connexion.

Les avantages de la mise en cache sont bien compris. La technique fonctionne en copiant temporairement les données fréquemment sollicitées à partir d’un magasin de données back-end vers un stockage rapide situé plus près de l’application. La mise en cache est souvent implémentée où...
- Les données restent relativement statiques.
- L’accès aux données est lent, en particulier par rapport à la vitesse du cache.
- Les données sont soumises à des niveaux élevés de conflit.
Pourquoi?
Comme indiqué dans les conseils de mise en cache Microsoft, la mise en cache peut augmenter les performances, l’extensibilité et la disponibilité des microservices individuels et du système dans son ensemble. Elle réduit la latence et la contention de la gestion de grands volumes de requêtes simultanées vers un magasin de données. À mesure que le volume de données et le nombre d’utilisateurs augmentent, plus les avantages de la mise en cache deviennent importants.
La mise en cache est la plus efficace lorsqu’un client lit à plusieurs reprises les données qui sont immuables ou qui changent rarement. Les exemples incluent des informations de référence telles que des informations de produit et de tarification, ou des ressources statiques partagées coûteuses à construire.
Bien que les microservices soient sans état, un cache distribué peut prendre en charge l’accès simultané aux données d’état de session si absolument nécessaire.
Envisagez également la mise en cache pour éviter les calculs répétitifs. Si une opération transforme des données ou effectue un calcul compliqué, cachez le résultat des requêtes suivantes.
Architecture de la mise en cache
Les applications natives cloud implémentent généralement une architecture de mise en cache distribuée. Le cache est hébergé en tant que service de stockage basé sur le cloud, distinct des microservices. La figure 5-15 montre l’architecture.
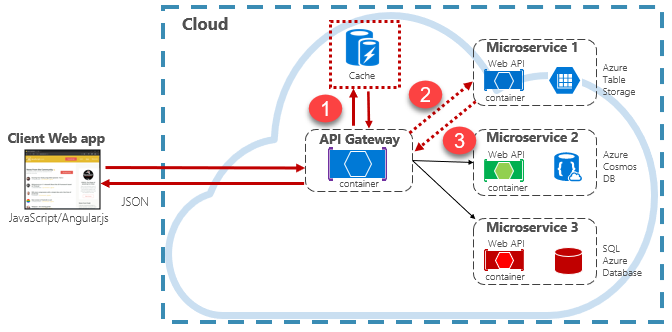
Figure 5-15 : Mise en cache dans une application native cloud
Dans la figure précédente, notez comment le cache est indépendant et partagé par les microservices. Dans ce scénario, le cache est appelé par la passerelle API. Comme indiqué dans le chapitre 4, la passerelle sert de serveur frontal pour toutes les demandes entrantes. Le cache distribué augmente la réactivité du système en retournant les données mises en cache dans la mesure du possible. En outre, la séparation du cache des services permet au cache de monter en puissance ou de s'étendre indépendamment pour répondre à des demandes de trafic accrues.
La figure précédente présente un modèle de mise en cache commun connu sous le nom de modèle cache-aside. Pour une requête entrante, vous interrogez d’abord le cache (étape 1) pour obtenir une réponse. Si elles sont trouvées, les données sont retournées immédiatement. Si les données n’existent pas dans le cache (appelée absence de cache), elles sont récupérées à partir d’une base de données locale dans un service en aval (étape 2). Il est ensuite écrit dans le cache pour les futures requêtes (étape 3) et retourné à l’appelant. Vous devez veiller à supprimer périodiquement les données mises en cache afin que le système reste opportun et cohérent.
À mesure qu’un cache partagé augmente, il peut s’avérer utile de partitionner ses données sur plusieurs nœuds. Cela peut aider à réduire la contention et à améliorer l’extensibilité. De nombreux services de mise en cache prennent en charge la possibilité d’ajouter et de supprimer dynamiquement des nœuds et de rééquilibrer les données entre les partitions. Cette approche implique généralement le clustering. Le clustering expose une collection de nœuds fédérés sous la forme d’un cache unique et transparent. Toutefois, en interne, les données sont dispersées sur les nœuds à la suite d’une stratégie de distribution prédéfinie qui équilibre la charge uniformément.
Cache Azure pour Redis
Azure Cache pour Redis est un service de mise en cache de données sécurisé et de service broker de messagerie, entièrement géré par Microsoft. Consommé en tant qu’offre PaaS (Platform as a Service), il fournit un débit élevé et un accès à faible latence aux données. Le service est accessible à n’importe quelle application au sein ou en dehors d’Azure.
Le service Azure Cache pour Redis gère l’accès aux serveurs Redis open source hébergés dans des centres de données Azure. Le service agit comme une façade fournissant la gestion, le contrôle d’accès et la sécurité. Le service prend en charge en mode natif un ensemble complet de structures de données, notamment des chaînes, des hachages, des listes et des jeux. Si votre application utilise déjà Redis, elle fonctionne comme c’est le cas avec Azure Cache pour Redis.
Azure Cache pour Redis est plus qu’un serveur de cache simple. Il peut prendre en charge un certain nombre de scénarios pour améliorer une architecture de microservices :
- Magasin de données en mémoire
- Une base de données non relationnelle distribuée
- Un répartiteur de messages
- Un serveur de configuration ou de découverte
Pour les scénarios avancés, une copie des données mises en cache peut être conservée sur le disque. Si un événement catastrophique désactive les caches principaux et réplicas, le cache est reconstruit à partir de l’instantané le plus récent.
Le Cache Redis Azure est disponible sur plusieurs configurations et niveaux tarifaires prédéfinis. Le niveau Premium propose de nombreuses fonctionnalités au niveau de l’entreprise, telles que le clustering, la persistance des données, la géoréplication et l’isolation du réseau virtuel.
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.