Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil
Ce contenu est un extrait du livre électronique, Cloud Native .NET apps for Azure (Architecture d’applications .NET natives cloud pour Azure), disponible dans la documentation .NET ou au format PDF à télécharger gratuitement pour le lire hors connexion.

Les modes relationnel (SQL) et non relationnel (NoSQL) sont deux types de systèmes de base de données couramment implémentés dans des applications natives cloud. Ils sont construits différemment, stockent les données différemment et sont accessibles différemment. Dans cette section, nous allons examiner les deux. Plus loin dans ce chapitre, nous allons examiner une technologie de base de données émergente appelée NewSQL.
Les bases de données relationnelles sont une technologie courante depuis des décennies. Elles sont matures, ont fait leurs preuves et sont largement implémentés. Les produits de base de données, outils et expertises concurrents sont nombreux. Les bases de données relationnelles fournissent un magasin de tables de données associées. Ces tables ont un schéma fixe, utilisent SQL (Structured Query Language) pour gérer les données et prennent en charge les garanties ACID : atomicité, cohérence, isolation et durabilité.
Les bases de données NoSQL font référence à des magasins de données non relationnelles hautes performances. Elles excellent dans leurs caractéristiques de facilité d’utilisation, de scalabilité, de résilience et de disponibilité. Au lieu de joindre des tables de données normalisées, NoSQL stocke des données non structurées ou semi-structurées, souvent dans des paires clé-valeur ou des documents JSON. Les bases de données NoSQL ne fournissent généralement pas de garanties ACID au-delà de l’étendue d’une seule partition de base de données. Les services avec des volumes élevés qui demandent un temps de réponse inférieur à une seconde préfèrent les magasins de données NoSQL.
L’impact des technologies NoSQL pour les systèmes natifs cloud distribués ne doit pas être surestimé. La prolifération de nouvelles technologies de données dans cet espace a perturbé les solutions qui s’appuyaient autrefois exclusivement sur des bases de données relationnelles.
Les bases de données NoSQL incluent différents modèles pour consulter et gérer les données, chacun étant adapté à des cas d’usage spécifiques. La figure 5-9 présente quatre modèles courants.
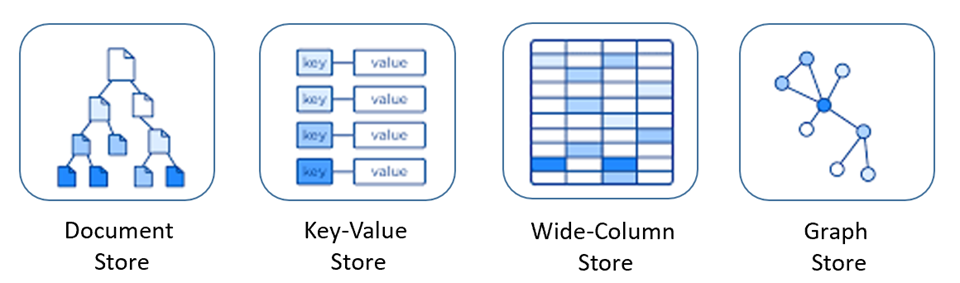
Figure 5-9 : Modèles de données pour les bases de données NoSQL
| Modèle | Caractéristiques |
|---|---|
| Magasin de documents | Les données et les métadonnées sont stockées hiérarchiquement dans des documents JSON à l’intérieur de la base de données. |
| Magasin de paires clé-valeur | Il s’agit de la plus simple des bases de données NoSQL : les données sont représentées sous la forme d’une collection de paires clé-valeur. |
| Magasin à colonnes larges | Les données connexes sont stockées sous la forme d’un ensemble de paires clé/valeur imbriquées dans une seule colonne. |
| Magasin de graphes | Les données sont stockées dans une structure de graphe sous forme de propriétés de nœuds, d’arêtes et de données. |
Théorèmes CAP et PACELC
Pour comprendre les différences entre ces types de bases de données, prenons comme exemple le théorème CAP, un ensemble de principes appliqués aux systèmes distribués qui stockent l’état. La figure 5-10 montre les trois propriétés du théorème CAP.
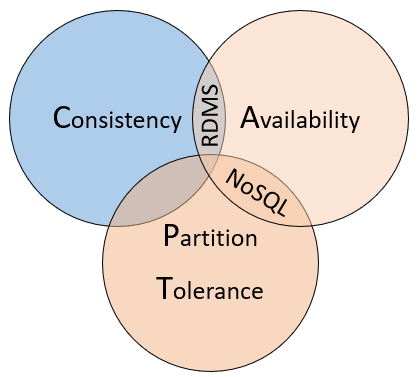
Figure 5-10. Le théorème CAP
Le théorème indique que les systèmes de données distribués offrent un compromis entre cohérence, disponibilité et tolérance de partition. Et que toute base de données ne peut garantir deux des trois propriétés :
Cohérence. Chaque nœud du cluster répond avec les données les plus récentes, même si le système doit bloquer la requête jusqu’à la mise à jour de tous les réplicas. Si vous interrogez un « système cohérent » pour un élément actuellement mis à jour, vous attendrez cette réponse jusqu’à la mise à jour réussie de tous les réplicas. Toutefois, vous recevrez les données les plus actuelles. Il doit être compris que le terme « cohérence » tel qu’il est utilisé dans le contexte du théorème CAP a une signification technique distincte de la façon dont la « cohérence » est définie dans le contexte des garanties ACID.
Disponibilité. Chaque requête reçue par un nœud non défaillant du système doit donner lieu à une réponse. En d’autres termes, si vous interrogez un « système disponible » concernant un élément en cours de mise à jour, vous obtiendrez la meilleure réponse possible que le service peut fournir à ce moment-là. Notez toutefois que la « disponibilité » telle que définie par le théorème CAP est techniquement différente de ce que nous appelons conventionnellement la « haute disponibilité » des systèmes distribués.
Tolérance de la partition. Garantit que le système continue à fonctionner même si un nœud de données répliqué échoue ou perd la connectivité avec d’autres nœuds de données répliqués.
Le théorème CAP explique les compromis associés à la gestion de la cohérence et de la disponibilité pendant une partition réseau. Toutefois, les compromis concernant la cohérence et les performances existent également avec l’absence d’une partition réseau.
Remarque
Même si vous choisissez la disponibilité plutôt que la cohérence, la disponibilité est affectée en période de partition réseau. Le système CAP est plus disponible pour certains de ses clients, mais il n’offre pas nécessairement un « haut niveau de disponibilité » pour tous ses clients.
Le théorème CAP est souvent plus étendu à PACELC pour expliquer les compromis de manière plus complète. Le théorème CAP est particulièrement pertinent dans les environnements connectés par intermittence, tels que ceux liés à l’Internet des objets (IoT), à la surveillance de l’environnement et aux applications mobiles. Dans ces contextes, les appareils peuvent devenir partitionnés en raison de conditions physiques difficiles, telles que les pannes de courant ou lors de l'entrée dans des espaces confinés comme les ascenseurs. Pour les systèmes distribués, tels que les applications cloud, il est plus approprié d’utiliser le théorème PACELC, qui est plus complet et prend en compte les compromis tels que la latence et la cohérence, même en l’absence de partitions réseau.
Les bases de données relationnelles fournissent généralement cohérence et disponibilité, mais pas la tolérance de partition. Elles sont généralement provisionnées sur un seul serveur et mises à l’échelle verticalement en ajoutant plus de ressources à la machine.
De nombreux systèmes de base de données relationnelles prennent en charge les fonctionnalités de réplication intégrées dans lesquelles des copies de la base de données primaire peuvent être effectuées dans d’autres instances de serveur secondaire. Les opérations d’écriture sont effectuées sur l’instance primaire et répliquées sur chacune des instances secondaires. En cas d’échec, l’instance primaire peut basculer vers une instance secondaire pour fournir une haute disponibilité. Les instances secondaires peuvent également être utilisées pour distribuer des opérations de lecture. Bien que les opérations d’écriture soient toujours effectuées sur le réplica principal, les opérations de lecture peuvent être routées vers l’une des instances secondaires pour réduire la charge système.
Les données peuvent également être partitionnées horizontalement sur plusieurs nœuds, comme avec le partitionnement. Toutefois, le partitionnement augmente considérablement la surcharge opérationnelle en fractionnant les données en nombreux éléments qui ne peuvent pas facilement communiquer. Il peut être coûteux et long à gérer. Les fonctionnalités relationnelles qui incluent les jointures de table, les transactions et l’intégrité référentielle nécessitent des pénalités de performances élevées dans les déploiements partitionnés.
La cohérence de la réplication et les objectifs de point de récupération peuvent être paramétrés en configurant si la réplication se produit de manière synchrone ou asynchrone. Si les réplicas de données devaient perdre la connectivité réseau dans un cluster de base de données relationnelle « hautement cohérent » ou synchrone, vous ne pourriez pas écrire dans la base de données. Le système rejetterait l’opération d’écriture car il ne peut pas répliquer cette modification vers l’autre réplica de données. Chaque réplica de données doit être mis à jour avant la fin de la transaction.
Les bases de données NoSQL prennent généralement en charge la haute disponibilité et la tolérance de partition. Elles effectuent un scale-out horizontal, souvent sur des serveurs de base. Cette approche offre une disponibilité considérable, aussi bien dans les régions géographiques qu’entre ces dernières, à un coût réduit. Vous partitionnez et répliquez des données sur ces machines ou nœuds, en fournissant une redondance et une tolérance de panne. La cohérence est généralement paramétrée par le biais de protocoles de consensus ou de mécanismes de quorum. Ceux-ci offrent davantage de contrôle lorsqu’un compromis doit être trouvé entre la réplication synchrone et asynchrone dans les systèmes relationnels.
Si les réplicas de données devaient perdre la connectivité dans un cluster de base de données NoSQL « hautement disponible », vous pourriez toujours effectuer une opération d’écriture dans la base de données. Le cluster de base de données autorise l’opération d’écriture et met à jour chaque réplica de données dès qu’il devient disponible. Les bases de données NoSQL qui prennent en charge plusieurs réplicas accessibles en écriture peuvent renforcer davantage la haute disponibilité en évitant le besoin de basculement lors de l’optimisation de l’objectif de temps de récupération.
Les bases de données NoSQL modernes implémentent généralement des fonctionnalités de partitionnement en tant que caractéristique de leur conception système. La gestion des partitions est souvent intégrée à la base de données et le routage est obtenu par le biais d’indicateurs de placement, souvent appelés clés de partition. Un modèle de données flexible permet aux bases de données NoSQL de réduire la charge de gestion des schémas et d’améliorer la disponibilité lors du déploiement des mises à jour d’applications nécessitant des modifications de modèle de données.
La haute disponibilité et la scalabilité massive sont souvent plus critiques pour l’entreprise que les jointures de tables relationnelles et l’intégrité référentielle. Les développeurs peuvent implémenter des techniques et des modèles tels que Sagas, CQRS et la messagerie asynchrone pour adopter la cohérence éventuelle.
De nos jours, vous devez bien réfléchir lorsque vous tenez compte des contraintes du théorème CAP. Un nouveau type de base de données, appelé NewSQL, a émergé. Il étend le moteur de base de données relationnelle pour prendre en charge l’extensibilité horizontale et les performances évolutives des systèmes NoSQL.
Considérations relatives aux systèmes relationnels et NoSQL
En fonction des exigences de données spécifiques, un microservice natif cloud peut implémenter un magasin de données NoSQL relationnel, noSQL ou les deux.
| Envisagez de faire appel à un magasin de données NoSQL dans les cas suivants : | Envisagez de faire appel à une base de données relationnelle dans les cas suivants : |
|---|---|
| Vous disposez de charges de travail aux volumes élevés qui nécessitent une latence prévisible à grande échelle (par exemple, une latence mesurée en millisecondes lors de l’exécution de millions de transactions par seconde) | Votre volume de charge de travail correspond généralement à des milliers de transactions par seconde. |
| Vos données sont dynamiques et fréquemment modifiées. | Vos données sont hautement structurées et nécessitent une intégrité référentielle. |
| Les relations peuvent être des modèles de données non normalisés. | Les relations sont exprimées par le biais de jointures de table sur des modèles de données normalisés. |
| La récupération des données est simple et exprimée sans jointures de table. | Vous travaillez avec des requêtes et des rapports complexes. |
| Les données sont généralement répliquées dans des zones géographiques et nécessitent un contrôle plus précis sur la cohérence, la disponibilité et les performances. | Les données sont généralement centralisées ou peuvent être répliquées de manière asynchrone. |
| Votre application sera déployée sur du matériel de base, par exemple avec des clouds publics. | Votre application sera déployée sur du matériel volumineux et haut de gamme. |
Dans les sections suivantes, nous allons explorer les options disponibles dans le cloud Azure pour stocker et gérer vos données natives cloud.
Base de données en tant que service
Pour commencer, vous pouvez provisionner une machine virtuelle Azure et installer la base de données de votre choix pour chaque service. Bien que vous disposiez d’un contrôle total sur l’environnement, vous devriez renoncer à de nombreuses fonctionnalités intégrées de la plateforme cloud. Vous seriez également responsable de la gestion de la machine virtuelle et de la base de données pour chaque service. Cette approche pourrait rapidement devenir longue et coûteuse.
Au lieu de cela, les applications natives cloud favorisent les services de données exposés sous la forme d’une base de données en tant que service (DBaaS). Complètement managés par un fournisseur de cloud, ces services fournissent une sécurité, une scalabilité et une surveillance intégrées. Au lieu de posséder le service, vous l’utilisez simplement en tant que service de support. Le fournisseur exploite la ressource à grande échelle et assume la responsabilité des performances et de la maintenance.
Ils peuvent être configurés entre les zones de disponibilité cloud et les régions pour obtenir une haute disponibilité. Ils prennent tous en charge la capacité juste-à-temps et un modèle de paiement à l’utilisation. Azure propose différents types d’options de service de données managées, chacune avec des avantages spécifiques.
Nous allons d’abord examiner les services DBaaS relationnels disponibles dans Azure. Vous verrez que la base de données SQL Server phare de Microsoft est disponible avec plusieurs options open source. Ensuite, nous allons parler des services de données NoSQL dans Azure.
Bases de données relationnelles Azure
Pour les microservices natifs cloud qui nécessitent des données relationnelles, Azure propose quatre bases de données relationnelles managées en tant que service (DBaaS), présentées dans la Figure 5-11.

Figure 5-11. Bases de données relationnelles managées disponibles dans Azure
Dans la figure précédente, notez comment chaque offre se trouve sur une infrastructure DBaaS commune qui offre des fonctionnalités clés sans coût supplémentaire.
Ces fonctionnalités sont particulièrement importantes pour les organisations qui provisionnent un grand nombre de bases de données, mais ont des ressources limitées pour les administrer. Vous pouvez provisionner une base de données Azure en quelques minutes en sélectionnant la quantité de cœurs de traitement, de mémoire et de stockage sous-jacent. Vous pouvez mettre à l’échelle la base de données à la volée et ajuster dynamiquement les ressources sans temps d’arrêt.
Azure SQL Database
Les équipes de développement avec expertise dans Microsoft SQL Server doivent envisager Azure SQL Database. Il s’agit d’une base de données relationnelle complètement managée en tant que service (DBaaS) basée sur le Moteur de base de données Microsoft SQL Server. Le service partage de nombreuses fonctionnalités disponibles dans la version locale de SQL Server et exécute la dernière version stable du moteur de base de données SQL Server.
Pour une utilisation avec un microservice natif cloud, Azure SQL Database est disponible avec trois options de déploiement :
Une base de données unique représente une base de données SQL Database complètement managée s’exécutant sur un serveur Azure SQL Database dans le cloud Azure. La base de données est considérée comme autonome car elle n’a aucune dépendance de configuration sur le serveur de base de données sous-jacent.
Une Managed Instance est une instance complètement managée du Moteur de base de données Microsoft SQL Server qui fournit une compatibilité proche de 100 % avec un serveur SQL Server local. Cette option prend en charge les bases de données plus volumineuses, jusqu’à 35 To, et elle est placée dans un réseau virtuel Azure pour offrir une meilleure isolation.
Azure SQL Database serverless est un niveau de calcul pour une base de données unique qui est automatiquement mise à l’échelle en fonction de la demande de la charge de travail. Il facture uniquement la quantité de calcul utilisée par seconde. Le service est bien adapté aux charges de travail associées à des modèles d’utilisation intermittente et imprévisible, émaillée de périodes d’inactivité. Le niveau de calcul serverless met aussi en pause automatiquement les bases de données pendant les périodes d’inactivité afin que seul le stockage soit facturé. Il reprend automatiquement lorsque l’activité reprend.
Au-delà de la pile Microsoft SQL Server traditionnelle, Azure propose également des versions managées de trois bases de données open source populaires.
Bases de données open source dans Azure
Les bases de données relationnelles open source sont devenues un choix populaire pour les applications natives cloud. De nombreuses entreprises les préfèrent aux produits de base de données commerciaux, en particulier pour les économies de coûts qu’elles offrent. De nombreuses équipes de développement profitent de leur flexibilité, du développement appuyé par la communauté et de l’écosystème d’outils et d’extensions. Les bases de données open source peuvent être déployées sur plusieurs fournisseurs de cloud, ce qui permet de réduire le problème d’enfermement propriétaire.
Les développeurs peuvent facilement héberger automatiquement n’importe quelle base de données open source sur une machine virtuelle Azure. Tout en fournissant un contrôle total, cette approche vous permet de vous consacrer à la gestion, à la surveillance et à la maintenance de la base de données et de la machine virtuelle.
Toutefois, Microsoft poursuit son engagement à proposer Azure sous forme de « plateforme ouverte » en offrant plusieurs bases de données open source populaires en tant que services DBaaS complètement managés.
Azure Database pour MySQL
MySQL est une base de données relationnelle open source et un pilier pour les applications basées sur la pile logicielle LAMP. Largement choisie pour les charges de travail aux nombreuses lectures, elle est utilisée par de nombreuses grandes organisations, notamment Facebook, Twitter et YouTube. L’édition Community est disponible gratuitement, tandis que l’édition Entreprise nécessite l’achat d’une licence. Initialement créé en 1995, le produit a été acheté par Sun Microsystems en 2008. Oracle a acquis Sun et MySQL en 2010.
Azure Database pour MySQL est un service de base de données relationnelle basé sur le moteur open source MySQL Server. Il utilise l’édition Community de MySQL. Le serveur Azure MySQL est le point d’administration du service. Il s’agit du même moteur de serveur MySQL utilisé pour les déploiements locaux. Le moteur peut créer une base de données unique par serveur ou plusieurs bases de données par serveur qui partagent des ressources. Vous pouvez continuer à gérer des données à l’aide des mêmes outils open source sans avoir à acquérir de nouvelles compétences ou à gérer des machines virtuelles.
Base de données Azure pour MariaDB
MariaDB Server est un autre serveur de base de données open source populaire. Il a été créé en tant que duplication (fork) de MySQL lorsque Oracle a acheté Sun Microsystems, qui possédait MySQL. L’intention était de s’assurer que MariaDB continuait à être proposé en open source. Comme MariaDB est une duplication (fork) de MySQL, les définitions de données et de table sont compatibles, et les protocoles client, les structures et les API, sont proches.
MariaDB a une forte communauté et est utilisée par de nombreuses grandes entreprises. Bien qu’Oracle continue de maintenir, d’améliorer et de prendre en charge MySQL, la fondation MariaDB gère MariaDB, ce qui permet au public de contribuer au produit et à la documentation.
Azure Database for MariaDB est une base de données relationnelle complètement managée en tant que service dans le cloud Azure. Ce service est basé sur le moteur de serveur de l’édition Community de MariaDB. Il peut gérer les charges de travail critiques avec des performances prévisibles et une scalabilité dynamique.
Azure Database pour PostgreSQL
PostgreSQL est une base de données relationnelle open source ayant plus de 30 ans de développement actif. PostgreSQL est fortement réputé pour proposer fiabilité et intégrité des données. Il est riche en fonctionnalités, compatible avec SQL et considéré comme plus performant que MySQL, en particulier pour les charges de travail associées à des requêtes complexes et à un grand volume d’écritures. De nombreuses grandes entreprises, notamment Apple, Red Hat et Fujitsu, ont créé des produits à l’aide de PostgreSQL.
Azure Database pour PostgreSQL est un service de base de données relationnelle complètement managé basé sur le moteur de base de données Postgres open source. Le service prend en charge de nombreuses plateformes de développement, notamment C++, Java, Python, Node, C# et PHP. Vous pouvez migrer des bases de données PostgreSQL vers celui-ci à l’aide de l’outil d’interface de ligne de commande ou d’Azure Data Migration Service.
Azure Database pour PostgreSQL est disponible avec deux options de déploiement :
L’option de déploiement Serveur unique est un point d’administration central pour plusieurs bases de données vers lesquelles vous pouvez déployer de nombreuses bases de données. La tarification est structurée par serveur en fonction du nombre de cœurs et du volume de stockage.
L’option Hyperscale (Citus) est alimentée par la technologie de données Citus. Elle offre de hautes performances en mettant à l’échelle horizontalement une base de données unique sur des centaines de nœuds pour fournir des performances et une mise à l’échelle rapides. Cette option permet au moteur d’ajuster plus de données en mémoire, de paralléliser des requêtes sur des centaines de nœuds et d’indexer les données plus rapidement.
Données NoSQL dans Azure
Cosmos DB est un service de base de données NoSQL complètement managé et distribué globalement dans le cloud Azure. Il a été adopté par de nombreuses grandes entreprises du monde entier, notamment Coca-Cola, Skype, ExxonMobil et Liberty Mutual.
Si vos services nécessitent une réponse rapide depuis n’importe où dans le monde, une haute disponibilité ou une scalabilité élastique, Cosmos DB est constitue un excellent choix. La figure 5-12 montre Cosmos DB.

Figure 5-12 : Vue d’ensemble d’Azure Cosmos DB
La figure précédente présente de nombreuses fonctionnalités natives cloud intégrées disponibles dans Cosmos DB. Dans cette section, nous les examinerons en détail.
Support global
Les applications natives cloud ont souvent un public international et nécessitent une mise à l’échelle mondiale.
Vous pouvez distribuer des bases de données Cosmos DB dans plusieurs régions ou dans le monde entier, et ainsi placer des données à proximité de vos utilisateurs, améliorer le temps de réponse et réduire la latence. Vous pouvez ajouter ou supprimer une base de données d’une région sans interrompre ou redéployer vos services. En arrière-plan, Cosmos DB réplique en toute transparence les données dans chacune des régions configurées.
Cosmos DB prend en charge le clustering actif/actif au niveau global, ce qui vous permet de configurer vos régions de base de données pour qu’elles prennent en charge à la fois les écritures et les lectures.
Le protocole d’écriture multirégion est une fonctionnalité importante dans Cosmos DB qui active les fonctionnalités suivantes :
Bénéficier d’une évolutivité élastique illimitée en écriture et en lecture.
Disponibilité en lecture et en écriture de 99,999 % dans le monde entier.
Lectures et écritures traitées en moins de 10 millisecondes au 99e centile.
Avec les API Multi-hébergement de Cosmos DB, votre microservice est automatiquement informé de la région Azure la plus proche et envoie des demandes à celle-ci. La région la plus proche est identifiée par Cosmos DB sans aucune modification de configuration. Si une région n’est plus disponible, la fonctionnalité Multi-hébergement route automatiquement les demandes vers la région la plus proche disponible.
Prise en charge de plusieurs modèles
Lors de la migration d’applications monolithiques vers une architecture native cloud, les équipes de développement doivent parfois migrer des magasins de données NoSQL open source. Cosmos DB peut vous aider à préserver votre investissement dans ces magasins de données NoSQL avec sa plateforme de données multimodèle. Le tableau suivant présente les API de compatibilité NoSQL prises en charge.
| Fournisseur | Descriptif |
|---|---|
| API NoSQL | L’API pour NoSQL stocke les données au format document |
| API MongoDB | Prend en charge les API de base de données Mongo et les documents JSON |
| API Gremlin | Prend en charge l’API Gremlin avec des nœuds basés sur des graphiques et des représentations de données de périphérie |
| API Cassandra | Prend en charge l’API Casandra pour les représentations de données à colonnes larges |
| API de table | Prend en charge le Stockage Table Azure avec des améliorations premium |
| API PostgreSQL | Service managé pour exécuter PostgreSQL à n’importe quelle échelle |
Les équipes de développement peuvent migrer des bases de données Mongo, Gremlin ou Cassandra existantes vers Cosmos DB avec peu de modifications des données ou du code. Pour les nouvelles applications, les équipes de développement peuvent choisir parmi les options open source ou le modèle d’API SQL intégré.
En interne, Cosmos stocke les données dans un format struct simple constitué de types de données primitifs. Pour chaque requête, le moteur de base de données convertit les données primitives dans la représentation de modèle que vous avez sélectionnée.
Dans le tableau précédent, notez l’option API Table. Cette API est une évolution du Stockage Table Azure. Les deux partagent le même modèle de table sous-jacent, mais l’API Table Cosmos DB ajoute des améliorations premium non disponibles dans l’API Stockage Azure. Le tableau suivant compare les fonctionnalités.
| Fonctionnalité | Stockage Table Azure | Azure Cosmos DB |
|---|---|---|
| Latence | Rapide | Latence de moins de 10 millisecondes pour les lectures et les écritures n’importe où dans le monde |
| Débit | Limite de 20 000 opérations par table | Nombre illimité d’opérations par table |
| Diffusion mondiale | Une seule région avec une seule région de lecture secondaire facultative | Distributions clés en main vers toutes les régions avec basculement automatique |
| Indexation | Disponible uniquement pour les propriétés de clé de partition et de ligne | Indexation automatique de toutes les propriétés |
| Tarifs | Optimisé pour les charges de travail froides (faible ratio débit/stockage) | Optimisé pour les charges de travail chaudes (ratio débit/stockage élevé) |
Les microservices qui consomment le Stockage Table Azure peuvent facilement migrer vers l’API Table Cosmos DB. Le code n’a pas besoin d’être modifié.
Cohérence paramétrable
Plus haut dans la section sur les modes Relationnel et NoSQL, nous avons abordé la question de la cohérence des données. La cohérence des données fait référence à l’intégrité de vos données. Les services natifs cloud avec des données distribuées s’appuient sur la réplication et doivent faire un compromis fondamental entre la cohérence de lecture, la disponibilité et la latence.
La plupart des bases de données distribuées permettent aux développeurs de choisir entre deux modèles de cohérence : une cohérence forte et une cohérence éventuelle. Une cohérence forte est la meilleure norme en matière de programmabilité des données. Elle garantit qu’une requête retourne toujours les données les plus actuelles, même si le système doit générer une latence dans l’attente d’une mise à jour pour répliquer sur toutes les copies de base de données. Une base de données configurée pour une cohérence éventuelle retourne immédiatement des données, même si ces données ne sont pas la copie la plus actuelle. Cette dernière option permet une plus grande disponibilité, une plus grande mise à l’échelle et des performances accrues.
Azure Cosmos DB offre cinq modèles de cohérence bien définis présentés dans la Figure 5-13.

Figure 5-13 : Niveaux de cohérence Cosmos DB
Ces options vous permettent de faire des choix et des compromis précis concernant la cohérence, la disponibilité et les performances de vos données. Les niveaux sont présentés dans le tableau suivant.
| Niveau de cohérence | Descriptif |
|---|---|
| Éventuel | Aucune garantie de classement pour les lectures. Les réplicas finiront par converger. |
| Préfixe de constante | Les lectures sont toujours éventuelles, mais les données sont retournées dans l’ordre dans lequel elles sont écrites. |
| session | Garantit que vous pouvez lire toutes les données écrites pendant la session active. Il s’agit du niveau de cohérence par défaut. |
| Obsolescence limitée | Lit les écritures de fin en fonction de l’intervalle que vous spécifiez. |
| Remarque | Garantit que les lectures retournent la version validée la plus récente d’un élément. Un client ne voit jamais une lecture partielle ou non validée. |
Dans l’article Getting Behind the 9-Ball: Cosmos DB Consistency Levels Explained, le responsable de programme Microsoft Jeremy Likness fournit une excellente explication des cinq modèles.
Partitionnement
Azure Cosmos DB prend en charge le partitionnement automatique pour mettre à l’échelle une base de données afin de répondre aux besoins de performances de vos services natifs cloud.
Vous gérez les données dans Cosmos DB en créant des bases de données, des conteneurs et des éléments.
Les conteneurs résident dans une base de données Cosmos DB et représentent un regroupement d’éléments indépendant du schéma. Les éléments sont les données que vous ajoutez au conteneur. Ils sont représentés sous forme de documents, de lignes, de nœuds ou de bords. Tous les éléments ajoutés à un conteneur sont automatiquement indexés.
Pour partitionner le conteneur, les éléments sont divisés en sous-ensembles distincts appelés partitions logiques. Les partitions logiques sont remplies en fonction de la valeur d’une clé de partition associée à chaque élément d’un conteneur. La Figure 5-14 montre deux conteneurs, chacun avec une partition logique basée sur une valeur de clé de partition.
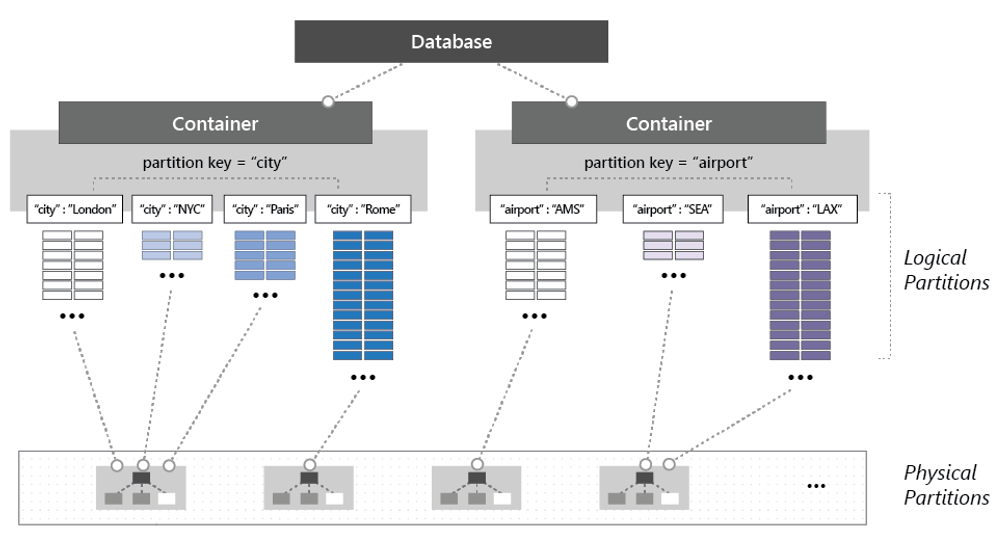
Figure 5-14 : Mécaniques de partitionnement Cosmos DB
Notez dans la figure précédente comment chaque élément inclut une clé de partition « city » ou « airport ». La clé détermine la partition logique de l’élément. Les éléments avec un code « city « sont affectés au conteneur situé à gauche, et les éléments avec un code « airport » au conteneur situé à droite. La combinaison de la valeur de clé de partition et de la valeur d’ID crée l’index d’un élément, qui identifie l’élément de manière unique.
En interne, Cosmos DB gère automatiquement le positionnement des partitions logiques sur les partitions physiques afin de répondre efficacement aux besoins d’extensibilité et de performances du conteneur. À mesure que les besoins en débit et stockage des applications augmentent, Azure Cosmos DB redistribue les partitions logiques sur un plus grand nombre de serveurs. Les opérations de redistribution sont gérées par Cosmos DB et sont appelées sans interruption ni temps d’arrêt.
Bases de données NewSQL
NewSQL est une technologie de base de données émergente qui combine la scalabilité distribuée de NoSQL avec les garanties ACID d’une base de données relationnelle. Les bases de données NewSQL sont importantes pour les systèmes métier qui doivent traiter des grands volumes de données dans des environnements distribués, avec une prise ne charge transactionnelle complète et une conformité ACID. Bien qu’une base de données NoSQL puisse fournir une scalabilité massive, elle ne garantit pas la cohérence des données. Les problèmes intermittents provenant de données incohérentes peuvent compliquer la tâche de l’équipe de développement. Les développeurs doivent construire des protections dans le code de leur microservice pour gérer les problèmes provoqués par des données incohérentes.
La CNCF (Cloud Native Computing Foundation) propose plusieurs projets de base de données NewSQL.
| Projet | Caractéristiques |
|---|---|
| Base de données Cockroach | Base de données relationnelle conforme à ACID qui s’adapte globalement. Lorsque vous ajoutez un nouveau nœud à un cluster, CockroachDB s’occupe de l’équilibrage des données entre les différentes instances et zones géographiques. Il crée, gère et distribue des réplicas pour garantir la fiabilité. Il est open source et librement disponible. |
| TiDB | Base de données open source qui prend en charge les charges de travail de traitement transactionnel et analytique hybrides (HTAP). Elle est compatible avec MySQL et propose une scalabilité horizontale, une cohérence forte et une haute disponibilité. TiDB agit comme un serveur MySQL. Vous pouvez continuer à utiliser des bibliothèques clientes MySQL existantes, sans qu’il soit nécessaire d’apporter des modifications de code étendues à votre application. |
| YugabyteDB | Base de données SQL distribuée open source, haute performance. Elle prend en charge une faible latence de requête, la résilience contre les défaillances et la distribution globale des données. YugabyteDB est compatible avec PostgreSQL et gère SGBDR avec Scale-out et les charges de travail OLTP à l’échelle d’Internet. Le produit prend également en charge NoSQL et est compatible avec Cassandra. |
| Vitess | Vitess est une solution de base de données pour le déploiement, la mise à l’échelle et la gestion de clusters volumineux d’instances MySQL. Elle peut s’exécuter dans une architecture de cloud public ou privé. Vitess combine et étend de nombreuses fonctionnalités MySQL importantes et propose la prise en charge à la fois verticale et horizontale du partitionnement. Provenant de YouTube, Vitess gère l’ensemble du trafic de base de données YouTube depuis 2011. |
Les projets open source de la figure précédente sont disponibles à partir de la Cloud Native Computing Foundation. Trois des offres sont des produits de base de données complets, qui incluent la prise en charge de .NET. Quant à Vitess, il s’agit d’un système de clustering de base de données qui met à l’échelle horizontalement de grands clusters d’instances MySQL.
Un objectif de conception clé des bases de données NewSQL est de travailler en mode natif dans Kubernetes, en tirant parti de la résilience et de la scalabilité de la plateforme.
Les bases de données NewSQL sont conçues pour prospérer dans des environnements cloud éphémères où les machines virtuelles sous-jacentes peuvent être redémarrées ou replanifiées en quelques instants. Les bases de données sont conçues pour survivre aux défaillances de nœud sans perte de données ni temps d’arrêt. CockroachDB, par exemple, peut survivre à une perte de machine en conservant trois réplicas cohérents de toutes les données sur les nœuds d’un cluster.
Kubernetes utilise une construction Services pour permettre à un client de gérer un groupe de bases de données NewSQL identiques à partir d’une seule entrée DNS. En découplant les instances de base de données de l’adresse du service avec lequel elles sont associées, nous pouvons effectuer une mise à l’échelle sans interrompre les instances d’application existantes. L’envoi d’une demande à n’importe quel service à un moment donné génère toujours le même résultat.
Dans ce scénario, toutes les instances de base de données sont égales. Il n’existe aucune relation primaire ou secondaire. Les techniques telles que la réplication de consensus disponibles dans CockroachDB permettent à n’importe quel nœud de base de données de gérer n’importe quelle requête. Si le nœud qui reçoit une demande d’équilibrage de charge a les données dont il a besoin localement, il répond immédiatement. Dans le cas contraire, le nœud devient une passerelle et transfère la demande aux nœuds appropriés pour obtenir la réponse correcte. Du point de vue du client, chaque nœud de base de données est identique : ils apparaissent sous la forme d’une base de données logique unique avec les garanties en termes de cohérence d’un système à une seule machine, malgré des dizaines ou même des centaines de nœuds qui fonctionnent en arrière-plan.
Pour obtenir un aperçu détaillé de la mécanique derrière les bases de données NewSQL, consultez l’article DASH: Four Properties of Kubernetes-Native Databases (DASH : Quatre propriétés des bases de données Kubernetes natives).
Migration des données vers le cloud
L’une des tâches les plus fastidieuses consiste à migrer des données d’une plateforme de données à une autre. Azure Data Migration Service peut contribuer à accélérer ces efforts. Il peut migrer des données provenant de plusieurs sources de base de données externes vers des plateformes de données Azure avec un temps d’arrêt minimal. Les plateformes cibles incluent les services suivants :
- Azure SQL Database
- Azure Database pour MySQL
- Base de données Azure pour MariaDB
- Azure Database pour PostgreSQL
- Azure Cosmos DB
Le service fournit des recommandations pour vous guider dans les modifications nécessaires à l’exécution d’une migration, qu’elle soit petite ou volumineuse.
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.