Tutoriel : Détecter des objets avec ONNX dans ML.NET
Découvrez comment utiliser un modèle ONNX préentraîné dans ML.NET pour détecter des objets dans des images.
L’entraînement d’un modèle de détection d’objets à partir de zéro nécessite de définir des millions de paramètres et d’avoir un grand nombre de données d’entraînement étiquetées et de ressources de calcul (des centaines d’heures GPU). L’utilisation d’un modèle préentraîné vous permet de raccourcir le processus d’entraînement.
Dans ce tutoriel, vous allez apprendre à :
- Comprendre le problème
- Découvrir ce qu’est ONNX et comment il fonctionne avec ML.NET
- Comprendre le modèle
- Réutiliser le modèle préentraîné
- Détecter les objets avec un modèle chargé
Conditions préalables
- Visual Studio 2022.
- Package NuGet Microsoft.ML
- Package NuGet Microsoft.ML.ImageAnalytics
- Package NuGet Microsoft.ML.OnnxTransformer
- Modèle préentraîné Tiny YOLOv2
- Netron (facultatif)
Vue d’ensemble de l’exemple de détection d’objets ONNX
Cet exemple crée une application console .NET Core qui détecte les objets dans une image à l’aide d’un modèle ONNX de deep learning préentraîné. Vous trouverez le code de cet exemple dans le dépôt dotnet/machinelearning-samples sur GitHub.
Qu’est-ce que la détection d’objets ?
La détection d’objets est un problème de vision par ordinateur. Même si elle est étroitement liée à la classification d’images, la détection d’objets effectue une classification d’images à une échelle plus précise. La détection d’objets localise et catégorise les entités dans les images. L’apprentissage des modèles de détection d’objet s’effectue généralement à l’aide du Deep Learning et des réseaux neuronaux. Pour plus d’informations, consultez Deep learning et machine learning.
Utilisez la détection d’objets quand les images contiennent plusieurs objets de différents types.

Voici quelques cas d’utilisation de la détection d’objets :
- Voitures autonomes
- Robotique
- Détection de visage
- Sécurité des espaces de travail
- Dénombrement des objets
- Reconnaissance des activités
Sélectionner un modèle de deep learning
Le deep learning fait partie du machine learning. Pour entraîner des modèles de deep learning, de grandes quantités de données sont nécessaires. Les différents motifs (patterns) de données sont représentés par une série de couches. Les relations dans les données sont encodées en tant que connexions entre les couches contenant des poids. Plus le poids est élevé, plus la relation est forte. Collectivement, cette série de couches et de connexions est connue sous le nom de réseaux neuronaux artificiels. Plus le nombre de couches d’un réseau est élevé, plus il est profond, ce qui en fait un réseau neuronal profond.
Il existe différents types de réseaux neuronaux, les plus courants étant les perceptrons multicouches (MLP), les réseaux de neurones convolutifs (CNN) et les réseaux de neurones récurrents (RNN). Le plus simple est le MLP, qui mappe un ensemble d’entrées à un ensemble de sorties. Ce réseau neuronal est parfait quand les données n’ont pas de composant spatial ou temporel. Le réseau CNN utilise des couches convolutives pour traiter les informations spatiales contenues dans les données. Un bon cas d’utilisation des réseaux CNN est le traitement d’images pour détecter la présence d’une caractéristique dans une zone d’une image (par exemple, y a-t-il un nez au centre d’une image ?). Enfin, les réseaux RNN autorisent la persistance de l’état ou de la mémoire à utiliser comme entrée. Ils sont utilisés pour l’analyse des séries chronologiques, où le tri séquentiel et le contexte des événements sont importants.
Comprendre le modèle
La détection d’objets est une tâche de traitement d’images. C’est pourquoi la plupart des modèles de deep learning préentraînés pour résoudre ce problème sont des réseaux CNN. Le modèle utilisé dans ce tutoriel est le modèle Tiny YOLOv2, une version plus compacte du modèle YOLOv2 décrite dans l’article : « YOLO9000: Better, Faster, Stronger » par Redmon et Farhadi. Tiny YOLOv2 est entraîné sur le jeu de données Pascal COV et est constitué de 15 couches qui peuvent prédire 20 classes différentes d’objets. Étant donné que Tiny YOLOv2 est une version condensée du modèle YOLOv2 d’origine, un compromis est établi entre la vitesse et la précision. Les différentes couches qui composent le modèle peuvent être visualisées à l’aide d’outils comme Netron. L’inspection du modèle produit un mappage des connexions entre toutes les couches qui composent le réseau neuronal, où chaque couche contient le nom de la couche ainsi que les dimensions des entrée/sortie respectives. Les structures de données utilisées pour décrire les entrées et les sorties du modèle sont appelées des tenseurs. Les tenseurs peuvent être considérés comme des conteneurs qui stockent des données dans N dimensions. Dans le cas de Tiny YOLOv2, le nom de la couche d’entrée est image et il attend un tenseur de dimensions 3 x 416 x 416. Le nom de la couche de sortie est grid et génère un tenseur de sortie de dimensions 125 x 13 x 13.
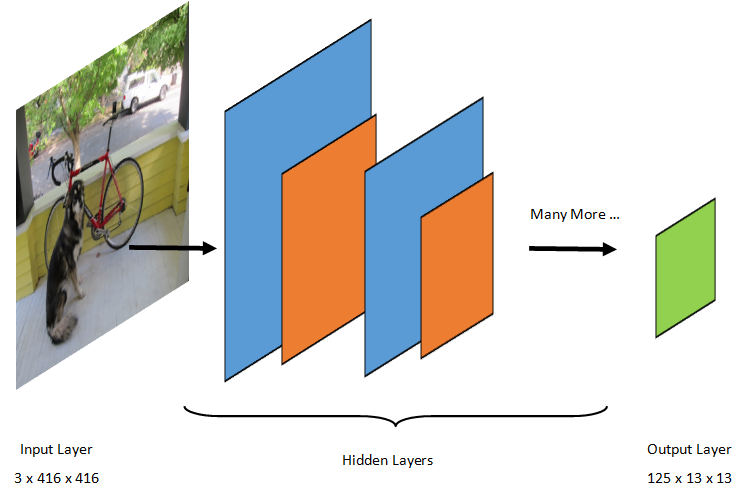
Le modèle YOLO prend une image 3(RGB) x 416px x 416px. Le modèle prend cette entrée et la passe à travers les différentes couches pour produire une sortie. La sortie divise l’image d’entrée en une grille 13 x 13, chaque cellule de la grille contenant les valeurs 125.
Qu’est-ce qu’un modèle ONNX ?
ONNX (Open Neural Network Exchange) est un format open source pour les modèles IA. ONNX prend en charge l’interopérabilité entre les frameworks. Cela signifie que vous pouvez entraîner un modèle dans l’un des nombreux frameworks de machine learning connus tels que PyTorch, le convertir au format ONNX et consommer le modèle ONNX dans un autre framework comme ML.NET. Pour en savoir plus, consultez le site web ONNX.

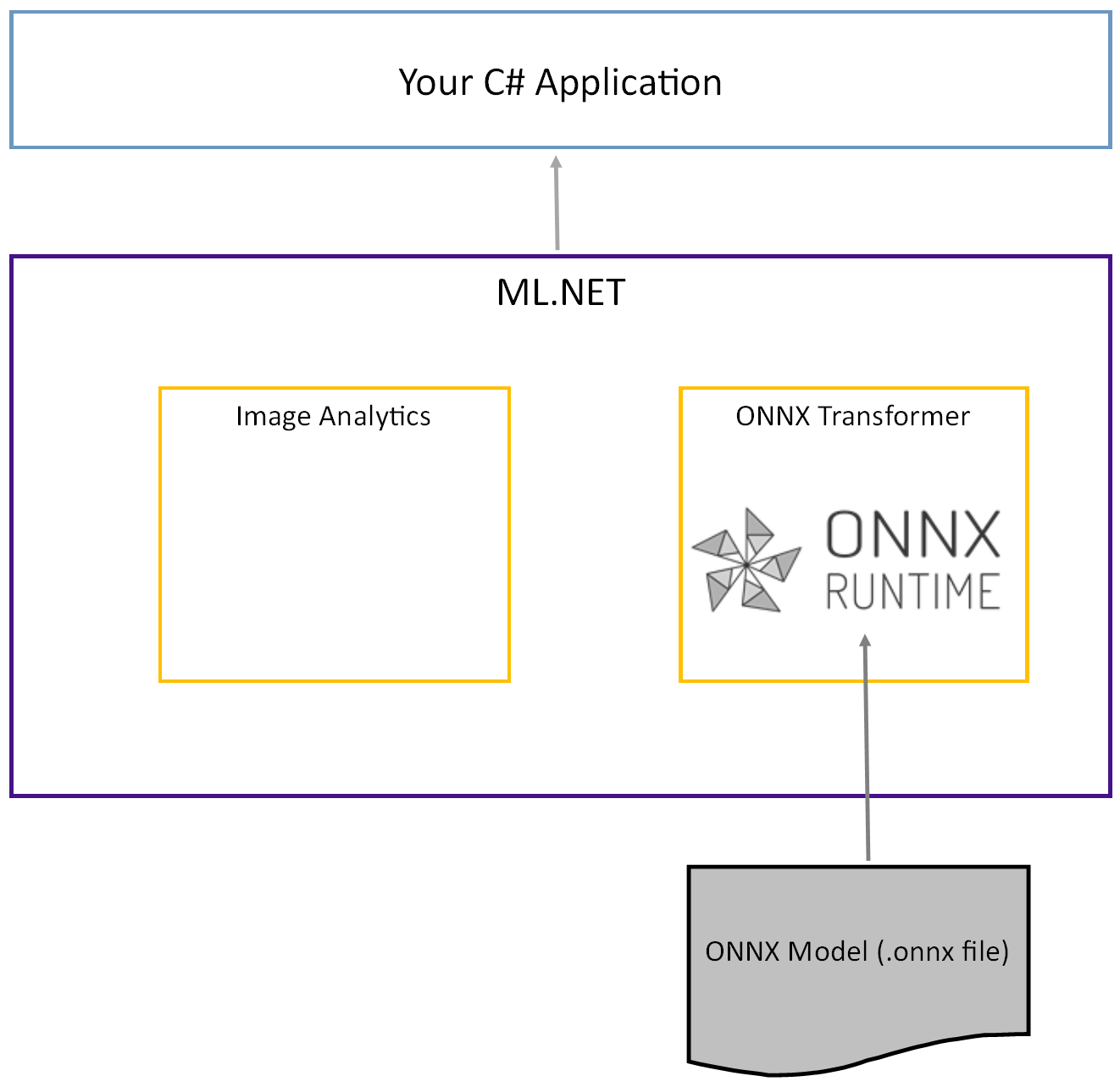
Le modèle Tiny YOLOv2 préentraîné est stocké au format ONNX, représentation sérialisée des couches et des motifs appris de ces couches. Dans ML.NET, l’interopérabilité avec ONNX s’obtient avec les packages NuGet ImageAnalytics et OnnxTransformer. Le packageImageAnalytics contient une série de transformations qui prennent une image et l’encodent en valeurs numériques pouvant être utilisées comme entrée dans un pipeline de prédiction ou d’entraînement. Le package OnnxTransformer tire profit du runtime ONNX afin de charger un modèle ONNX et de l’utiliser pour faire des prédictions en fonction de l’entrée fournie.
Configurer le projet de console .NET Core
Maintenant que vous avez une compréhension générale de ce qu’est ONNX et de la façon dont Tiny YOLOv2 fonctionne, il est temps de générer l’application.
Création d’une application console
Créez une application console C# appelée « ObjectDetection ». Cliquez sur le bouton Suivant.
Choisissez .NET 6 comme framework à utiliser. Cliquez sur le bouton Créer.
Installez le package NuGet Microsoft.ML :
Notes
Cet exemple utilise la dernière version stable des packages NuGet mentionnés, sauf indication contraire.
- Dans l'Explorateur de solutions, cliquez avec le bouton droit sur votre projet, puis sélectionnez Gérer les packages NuGet.
- Choisissez « nuget.org » comme source du package, sélectionnez l’onglet Parcourir et recherchez Microsoft.ML.
- Sélectionnez le bouton Installer.
- Cliquez sur le bouton OK dans la boîte de dialogue Aperçu des modifications, puis sur le bouton J’accepte dans la boîte de dialogue Acceptation de la licence si vous acceptez les termes du contrat de licence pour les packages répertoriés.
- Répétez ces étapes pour Microsoft.Windows.Compatibility, Microsoft.ML.ImageAnalytics, Microsoft.ML.OnnxTransformer et Microsoft.ML.OnnxRuntime.
Préparer vos données et votre modèle préentraîné
Téléchargez le fichier zip du répertoire de ressources du projet et décompressez-le.
Copiez le répertoire
assetsdans votre répertoire de projet ObjectDetection. Ce répertoire et ses sous-répertoires contiennent les fichiers image nécessaires à ce tutoriel (sauf pour le modèle Tiny YOLOv2, que vous allez télécharger et ajouter à l’étape suivante).Téléchargez le modèle Tiny YOLOv2 depuis ONNX Model Zoo.
Copiez le fichier
model.onnxdans le répertoireassets\Modelde votre projet ObjectDetection et renommez-le enTinyYolo2_model.onnx. Ce répertoire contient le modèle nécessaire pour ce tutoriel.Dans l’Explorateur de solutions, cliquez sur chacun des fichiers du répertoire et des sous-répertoires de ressources et sélectionnez Propriétés. Sous Avancé, définissez la valeur Copier dans le répertoire de sortie sur Copier si plus récent.
Créer des classes et définir des chemins
Ouvrez le fichier Program.cs et ajoutez les instructions using supplémentaires suivantes en haut du fichier :
using System.Drawing;
using System.Drawing.Drawing2D;
using ObjectDetection.YoloParser;
using ObjectDetection.DataStructures;
using ObjectDetection;
using Microsoft.ML;
Ensuite, définissez les chemins des différentes ressources.
Tout d’abord, créez la méthode
GetAbsolutePathdans le bas du fichier Program.cs.string GetAbsolutePath(string relativePath) { FileInfo _dataRoot = new FileInfo(typeof(Program).Assembly.Location); string assemblyFolderPath = _dataRoot.Directory.FullName; string fullPath = Path.Combine(assemblyFolderPath, relativePath); return fullPath; }Ensuite, sous les instructions using, créez des champs pour stocker l’emplacement de vos ressources.
var assetsRelativePath = @"../../../assets"; string assetsPath = GetAbsolutePath(assetsRelativePath); var modelFilePath = Path.Combine(assetsPath, "Model", "TinyYolo2_model.onnx"); var imagesFolder = Path.Combine(assetsPath, "images"); var outputFolder = Path.Combine(assetsPath, "images", "output");
Ajoutez un nouveau répertoire à votre projet pour stocker vos données d’entrée et vos classes de prédiction.
Dans l’Explorateur de solutions, cliquez avec le bouton de droite sur le projet, puis sélectionnez Ajouter>Nouveau dossier. Lorsque le nouveau dossier s’affiche dans l’Explorateur de solutions, nommez-le « DataStructures ».
Créez votre classe de données d’entrée dans le répertoire DataStructures qui vient d’être créé.
Dans l’Explorateur de solutions, cliquez avec le bouton droit sur le répertoire DataStructures, puis sélectionnez Ajouter>Nouvel élément.
Dans la boîte de dialogue Ajouter un nouvel élément, sélectionnez Classe et remplacez la valeur du champ Nom par ImageNetData.cs. Ensuite, sélectionnez le bouton Ajouter.
Le fichier ImageNetData.cs s’ouvre dans l’éditeur de code. Ajoutez l’instruction
usingsuivante en haut de ImageNetData.cs :using System.Collections.Generic; using System.IO; using System.Linq; using Microsoft.ML.Data;Supprimez la définition de classe existante et ajoutez le code suivant pour la classe
ImageNetDataau fichier ImageNetData.cs :public class ImageNetData { [LoadColumn(0)] public string ImagePath; [LoadColumn(1)] public string Label; public static IEnumerable<ImageNetData> ReadFromFile(string imageFolder) { return Directory .GetFiles(imageFolder) .Where(filePath => Path.GetExtension(filePath) != ".md") .Select(filePath => new ImageNetData { ImagePath = filePath, Label = Path.GetFileName(filePath) }); } }ImageNetDataest la classe de données d’images d’entrée, qui comprend les champs String suivants :ImagePathcontient le chemin où l’image est stockée.Labelcontient le nom du fichier.
En outre,
ImageNetDatacontient une méthodeReadFromFilequi charge plusieurs fichiers image stockés dans le cheminimageFolderspécifié et les retourne sous forme de collection d’objetsImageNetData.
Créez votre classe de prédiction dans le répertoire DataStructures.
Dans l’Explorateur de solutions, cliquez avec le bouton droit sur le répertoire DataStructures, puis sélectionnez Ajouter>Nouvel élément.
Dans la boîte de dialogue Ajouter un nouvel élément, sélectionnez Classe et remplacez la valeur du champ Nom par ImageNetPrediction.cs. Ensuite, sélectionnez le bouton Ajouter.
Le fichier ImageNetPrediction.cs s’ouvre dans l’éditeur de code. Ajoutez l’instruction
usingsuivante en haut de ImageNetPrediction.cs :using Microsoft.ML.Data;Supprimez la définition de classe existante et ajoutez le code suivant pour la classe
ImageNetPredictionau fichier ImageNetPrediction.cs :public class ImageNetPrediction { [ColumnName("grid")] public float[] PredictedLabels; }ImageNetPredictionest la classe de données de prédiction et présente le champfloat[]suivant :PredictedLabelscontient les dimensions, le score d’objets et les probabilités de classe pour chacun des rectangles englobants détectés dans une image.
Initialiser les variables
La classe MLContext est un point de départ pour toutes les opérations ML.NET, et l’initialisation de mlContext crée un environnement ML.NET qui peut être partagé par les objets de flux de travail de création de modèle. Sur le plan conceptuel, elle est similaire à DBContext dans Entity Framework.
Initialisez la variable mlContext avec une nouvelle instance de MLContext en ajoutant la ligne suivante sous le champ outputFolder.
MLContext mlContext = new MLContext();
Créer un analyseur pour le post-traitement des sorties du modèle
Le modèle segmente une image dans une grille 13 x 13, où chaque cellule de grille est 32px x 32px. Chaque cellule de grille contient 5 rectangles englobants d’objet potentiels. Un cadre englobant a 25 éléments :
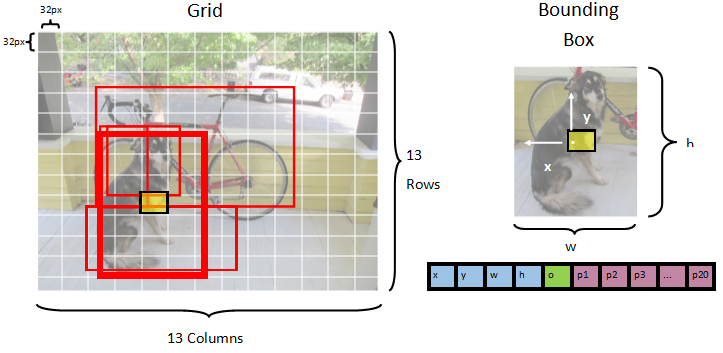
xposition x du centre du rectangle englobant par rapport à la cellule de grille à laquelle il est associé.yposition y du centre du rectangle englobant par rapport à la cellule de grille à laquelle il est associé.wlargeur du rectangle englobant.hhauteur du rectangle englobant.ovaleur de confiance qu’un objet existe dans le rectangle englobant, également connue sous le nom de score d’objet.p1-p20probabilités de classe pour chacune des 20 classes prédites par le modèle.
Au total, les 25 éléments décrivant chacun des 5 rectangles englobants composent les 125 éléments contenus dans chaque cellule de grille.
La sortie générée par le modèle ONNX préentraîné est un tableau de type float de longueur 21125, représentant les éléments d’un tenseur avec les dimensions 125 x 13 x 13. Pour transformer les prédictions générées par le modèle en tenseur, un travail de post-traitement est nécessaire. Pour ce faire, créez un ensemble de classes pour permettre l’analyse de la sortie.
Ajoutez un nouveau répertoire à votre projet pour organiser l’ensemble des classes d’analyseur.
- Dans l’Explorateur de solutions, cliquez avec le bouton de droite sur le projet, puis sélectionnez Ajouter>Nouveau dossier. Lorsque le nouveau dossier s’affiche dans l’Explorateur de solutions, nommez-le « YoloParser ».
Créer des rectangles englobants et des dimensions
Les données générées par le modèle contiennent les coordonnées et les dimensions des rectangles englobants des objets dans l’image. Créez une classe de base pour les dimensions.
Dans l’Explorateur de solutions, cliquez avec le bouton droit sur le répertoire YoloParser, puis sélectionnez Ajouter>Nouvel élément.
Dans la boîte de dialogue Ajouter un nouvel élément, sélectionnez Classe et remplacez la valeur du champ Nom par DimensionsBase.cs. Ensuite, sélectionnez le bouton Ajouter.
Le fichier DimensionsBase.cs s’ouvre dans l’éditeur de code. Supprimez toutes les instructions
usinget la définition de classe existante.Ajoutez le code suivant pour la classe
DimensionsBaseau fichier DimensionsBase.cs :public class DimensionsBase { public float X { get; set; } public float Y { get; set; } public float Height { get; set; } public float Width { get; set; } }DimensionsBasea les propriétésfloatsuivantes :Xcontient la position de l’objet sur l’axe x.Ycontient la position de l’objet sur l’axe y.Heightcontient la hauteur de l’objet.Widthcontient la largeur de l’objet.
Ensuite, créez une classe pour vos rectangles englobants.
Dans l’Explorateur de solutions, cliquez avec le bouton droit sur le répertoire YoloParser, puis sélectionnez Ajouter>Nouvel élément.
Dans la boîte de dialogue Ajouter un nouvel élément, sélectionnez Classe et remplacez la valeur du champ Nom par YoloBoundingBox.cs. Ensuite, sélectionnez le bouton Ajouter.
Le fichier YoloBoundingBox.cs s’ouvre dans l’éditeur de code. Ajoutez l’instruction
usingsuivante en haut de YoloBoundingBox.cs :using System.Drawing;Juste au-dessus de la définition de classe existante, ajoutez une nouvelle définition de classe nommée
BoundingBoxDimensions, qui hérite de la classeDimensionsBasepour contenir les dimensions du rectangle englobant correspondant.public class BoundingBoxDimensions : DimensionsBase { }Supprimez la définition de classe
YoloBoundingBoxexistante et ajoutez le code suivant pour la classeYoloBoundingBoxau fichier YoloBoundingBox.cs :public class YoloBoundingBox { public BoundingBoxDimensions Dimensions { get; set; } public string Label { get; set; } public float Confidence { get; set; } public RectangleF Rect { get { return new RectangleF(Dimensions.X, Dimensions.Y, Dimensions.Width, Dimensions.Height); } } public Color BoxColor { get; set; } }YoloBoundingBoxa les propriétés suivantes :Dimensionscontient les dimensions du rectangle englobant.Labelcontient la classe de l’objet détecté dans le rectangle englobant.Confidencecontient la valeur de confiance de la classe.Rectcontient la représentation rectangle des dimensions du rectangle englobant.BoxColorcontient la couleur associée à la classe respective utilisée pour dessiner sur l’image.
Créer l’analyseur
Maintenant que les classes pour les dimensions et les rectangles englobants sont créées, il est temps de créer l’analyseur.
Dans l’Explorateur de solutions, cliquez avec le bouton droit sur le répertoire YoloParser, puis sélectionnez Ajouter>Nouvel élément.
Dans la boîte de dialogue Ajouter un nouvel élément, sélectionnez Classe, puis remplacez le champ Nom par YoloOutputParser.cs. Ensuite, sélectionnez le bouton Ajouter.
Le fichier YoloOutputParser.cs s’ouvre dans l’éditeur de code. Ajoutez les instructions
usingsuivantes en haut du fichier YoloOutputParser.cs :using System; using System.Collections.Generic; using System.Drawing; using System.Linq;Dans la définition de la classe
YoloOutputParserexistante, ajoutez une classe imbriquée qui contient les dimensions de chacune des cellules de l’image. Ajoutez le code suivant pour la classeCellDimensionsqui hérite de la classeDimensionsBaseen haut de la définition de la classeYoloOutputParser.class CellDimensions : DimensionsBase { }Dans la définition de la classe
YoloOutputParser, ajoutez les constantes et le champ suivants.public const int ROW_COUNT = 13; public const int COL_COUNT = 13; public const int CHANNEL_COUNT = 125; public const int BOXES_PER_CELL = 5; public const int BOX_INFO_FEATURE_COUNT = 5; public const int CLASS_COUNT = 20; public const float CELL_WIDTH = 32; public const float CELL_HEIGHT = 32; private int channelStride = ROW_COUNT * COL_COUNT;ROW_COUNTest le nombre de lignes dans la grille dans laquelle l’image est divisée.COL_COUNTest le nombre de colonnes dans la grille dans laquelle l’image est divisée.CHANNEL_COUNTest le nombre total de valeurs contenues dans une cellule de la grille.BOXES_PER_CELLest le nombre de rectangles englobants dans une cellule.BOX_INFO_FEATURE_COUNTest le nombre de caractéristiques contenues dans un rectangle (x, y, hauteur, largeur, confiance).CLASS_COUNTest le nombre de prédictions de classe contenues dans chaque rectangle englobant.CELL_WIDTHest la largeur d’une cellule dans la grille de l’image.CELL_HEIGHTest la hauteur d’une cellule dans la grille de l’image.channelStrideest la position de départ de la cellule active dans la grille.
Quand le modèle fait une prédiction (ou « scoring »), il divise l’image d’entrée
416px x 416pxsous forme de grille de cellules d’une taille de13 x 13. Chaque cellule contient32px x 32px. Dans chaque cellule, il y a 5 rectangles englobants contenant chacun 5 caractéristiques (x, y, largeur, hauteur, confiance). Chaque rectangle englobant contient aussi la probabilité de chacune des classes qui est dans ce cas 20. Par conséquent, chaque cellule contient 125 informations différentes (5 caractéristiques + 20 probabilités de classe).
Créez une liste d’ancres sous channelStride pour les 5 rectangles englobants :
private float[] anchors = new float[]
{
1.08F, 1.19F, 3.42F, 4.41F, 6.63F, 11.38F, 9.42F, 5.11F, 16.62F, 10.52F
};
Les ancres sont des ratios de hauteur et de largeur prédéfinis pour les rectangles englobants. La plupart des objets ou classes détectés par un modèle ont des ratios similaires. C’est utile lorsqu’il s’agit de créer des rectangles englobants. Au lieu de prédire les rectangles englobants, le décalage par rapport aux dimensions prédéfinies est calculé, réduisant ainsi le calcul nécessaire pour prédire le rectangle englobant. En général, ces ratios d’ancre sont calculés en fonction du jeu de données utilisé. Dans ce cas, comme le jeu de données est connu et que les valeurs ont été précalculées, les ancres peuvent être codées en dur.
Ensuite, définissez les étiquettes ou les classes que le modèle va prédire. Ce modèle prédit 20 classes, ce qui est un sous-ensemble du nombre total de classes prédites par le modèle YOLOv2 d’origine.
Ajoutez votre liste d’étiquettes sous les anchors.
private string[] labels = new string[]
{
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
};
Des couleurs sont associées à chacune des classes. Attribuez vos couleurs de classe sous vos labels :
private static Color[] classColors = new Color[]
{
Color.Khaki,
Color.Fuchsia,
Color.Silver,
Color.RoyalBlue,
Color.Green,
Color.DarkOrange,
Color.Purple,
Color.Gold,
Color.Red,
Color.Aquamarine,
Color.Lime,
Color.AliceBlue,
Color.Sienna,
Color.Orchid,
Color.Tan,
Color.LightPink,
Color.Yellow,
Color.HotPink,
Color.OliveDrab,
Color.SandyBrown,
Color.DarkTurquoise
};
Créer des fonctions d’assistance
Il faut suivre une série d’étapes dans la phase de post-traitement. Pour vous aider, vous pouvez faire appel à plusieurs méthodes d’assistance.
Les méthodes d’assistance utilisées par l’analyseur sont :
Sigmoidapplique la fonction sigmoïde qui génère un nombre entre 0 et 1.Softmaxnormalise un vecteur d’entrée dans une distribution de probabilité.GetOffsetmappe les éléments de la sortie du modèle unidimensionnelle à la position correspondante dans un tenseur125 x 13 x 13.ExtractBoundingBoxesextrait les dimensions du rectangle englobant en utilisant la méthodeGetOffsetde la sortie du modèle.GetConfidenceextrait la valeur de confiance qui indique le degré de probabilité que le modèle a détecté un objet et utilise la fonctionSigmoidpour la convertir en pourcentage.MapBoundingBoxToCellutilise les dimensions du rectangle englobant et les mappe à sa cellule respective dans l’image.ExtractClassesextrait les prédictions de classe pour le rectangle englobant de la sortie du modèle en utilisant la méthodeGetOffsetet les transforme en distribution de probabilité en utilisant la méthodeSoftmax.GetTopResultsélectionne la classe dans la liste des classes prédites avec la probabilité la plus forte.IntersectionOverUnionfiltre les rectangles englobants qui se chevauchent avec des probabilités moins fortes.
Ajoutez le code pour toutes les méthodes d’assistance sous votre liste de classColors.
private float Sigmoid(float value)
{
var k = (float)Math.Exp(value);
return k / (1.0f + k);
}
private float[] Softmax(float[] values)
{
var maxVal = values.Max();
var exp = values.Select(v => Math.Exp(v - maxVal));
var sumExp = exp.Sum();
return exp.Select(v => (float)(v / sumExp)).ToArray();
}
private int GetOffset(int x, int y, int channel)
{
// YOLO outputs a tensor that has a shape of 125x13x13, which
// WinML flattens into a 1D array. To access a specific channel
// for a given (x,y) cell position, we need to calculate an offset
// into the array
return (channel * this.channelStride) + (y * COL_COUNT) + x;
}
private BoundingBoxDimensions ExtractBoundingBoxDimensions(float[] modelOutput, int x, int y, int channel)
{
return new BoundingBoxDimensions
{
X = modelOutput[GetOffset(x, y, channel)],
Y = modelOutput[GetOffset(x, y, channel + 1)],
Width = modelOutput[GetOffset(x, y, channel + 2)],
Height = modelOutput[GetOffset(x, y, channel + 3)]
};
}
private float GetConfidence(float[] modelOutput, int x, int y, int channel)
{
return Sigmoid(modelOutput[GetOffset(x, y, channel + 4)]);
}
private CellDimensions MapBoundingBoxToCell(int x, int y, int box, BoundingBoxDimensions boxDimensions)
{
return new CellDimensions
{
X = ((float)x + Sigmoid(boxDimensions.X)) * CELL_WIDTH,
Y = ((float)y + Sigmoid(boxDimensions.Y)) * CELL_HEIGHT,
Width = (float)Math.Exp(boxDimensions.Width) * CELL_WIDTH * anchors[box * 2],
Height = (float)Math.Exp(boxDimensions.Height) * CELL_HEIGHT * anchors[box * 2 + 1],
};
}
public float[] ExtractClasses(float[] modelOutput, int x, int y, int channel)
{
float[] predictedClasses = new float[CLASS_COUNT];
int predictedClassOffset = channel + BOX_INFO_FEATURE_COUNT;
for (int predictedClass = 0; predictedClass < CLASS_COUNT; predictedClass++)
{
predictedClasses[predictedClass] = modelOutput[GetOffset(x, y, predictedClass + predictedClassOffset)];
}
return Softmax(predictedClasses);
}
private ValueTuple<int, float> GetTopResult(float[] predictedClasses)
{
return predictedClasses
.Select((predictedClass, index) => (Index: index, Value: predictedClass))
.OrderByDescending(result => result.Value)
.First();
}
private float IntersectionOverUnion(RectangleF boundingBoxA, RectangleF boundingBoxB)
{
var areaA = boundingBoxA.Width * boundingBoxA.Height;
if (areaA <= 0)
return 0;
var areaB = boundingBoxB.Width * boundingBoxB.Height;
if (areaB <= 0)
return 0;
var minX = Math.Max(boundingBoxA.Left, boundingBoxB.Left);
var minY = Math.Max(boundingBoxA.Top, boundingBoxB.Top);
var maxX = Math.Min(boundingBoxA.Right, boundingBoxB.Right);
var maxY = Math.Min(boundingBoxA.Bottom, boundingBoxB.Bottom);
var intersectionArea = Math.Max(maxY - minY, 0) * Math.Max(maxX - minX, 0);
return intersectionArea / (areaA + areaB - intersectionArea);
}
Une fois que vous avez défini toutes les méthodes d’assistance, il est temps de les utiliser pour traiter la sortie du modèle.
Sous la méthode IntersectionOverUnion, créez la méthode ParseOutputs pour traiter la sortie générée par le modèle.
public IList<YoloBoundingBox> ParseOutputs(float[] yoloModelOutputs, float threshold = .3F)
{
}
Créez une liste pour stocker vos rectangles englobants et définir des variables dans la méthode ParseOutputs.
var boxes = new List<YoloBoundingBox>();
Chaque image est divisée en grille de cellules 13 x 13. Chaque cellule contient cinq rectangles englobants. Sous la variable boxes, ajoutez le code pour traiter tous les rectangles de chacune des cellules.
for (int row = 0; row < ROW_COUNT; row++)
{
for (int column = 0; column < COL_COUNT; column++)
{
for (int box = 0; box < BOXES_PER_CELL; box++)
{
}
}
}
Dans la boucle la plus interne, calculez la position de départ du rectangle actuel au sein de la sortie du modèle unidimensionnelle.
var channel = (box * (CLASS_COUNT + BOX_INFO_FEATURE_COUNT));
Directement en dessous, utilisez la méthode ExtractBoundingBoxDimensions pour obtenir les dimensions du rectangle englobant actuel.
BoundingBoxDimensions boundingBoxDimensions = ExtractBoundingBoxDimensions(yoloModelOutputs, row, column, channel);
Utilisez ensuite la méthode GetConfidence pour obtenir la confiance du rectangle englobant actuel.
float confidence = GetConfidence(yoloModelOutputs, row, column, channel);
Après, utilisez la méthode MapBoundingBoxToCell pour mapper le rectangle englobant actuel à la cellule active en cours de traitement.
CellDimensions mappedBoundingBox = MapBoundingBoxToCell(row, column, box, boundingBoxDimensions);
Avant d’aller plus loin dans le traitement, vérifiez si votre valeur de confiance est supérieure au seuil fourni. Si elle ne l’est pas, traitez le rectangle englobant suivant.
if (confidence < threshold)
continue;
Sinon, continuez à traiter la sortie. L’étape suivante consiste à obtenir la distribution de probabilité des classes prédites pour le rectangle englobant actuel en utilisant la méthode ExtractClasses.
float[] predictedClasses = ExtractClasses(yoloModelOutputs, row, column, channel);
Utilisez ensuite la méthode GetTopResult pour obtenir la valeur et l’index de la classe avec la probabilité la plus forte pour le rectangle actuel et calculer son score.
var (topResultIndex, topResultScore) = GetTopResult(predictedClasses);
var topScore = topResultScore * confidence;
Utilisez topScore pour une fois de plus conserver uniquement les rectangles englobants qui se trouvent au-dessus du seuil spécifié.
if (topScore < threshold)
continue;
Enfin, si le rectangle englobant actuel dépasse le seuil, créez un objet BoundingBox et ajoutez-le à la liste des boxes.
boxes.Add(new YoloBoundingBox()
{
Dimensions = new BoundingBoxDimensions
{
X = (mappedBoundingBox.X - mappedBoundingBox.Width / 2),
Y = (mappedBoundingBox.Y - mappedBoundingBox.Height / 2),
Width = mappedBoundingBox.Width,
Height = mappedBoundingBox.Height,
},
Confidence = topScore,
Label = labels[topResultIndex],
BoxColor = classColors[topResultIndex]
});
Une fois que toutes les cellules de l’image ont été traitées, retournez la liste des boxes. Ajoutez l’instruction return suivante sous la boucle for la plus externe dans la méthode ParseOutputs.
return boxes;
Filtrer les rectangles qui se chevauchent
Maintenant que tous les rectangles englobants à confiance élevée ont été extraits de la sortie du modèle, il faut procéder à un autre filtrage pour supprimer les images qui se chevauchent. Ajoutez une méthode appelée FilterBoundingBoxes sous la méthode ParseOutputs :
public IList<YoloBoundingBox> FilterBoundingBoxes(IList<YoloBoundingBox> boxes, int limit, float threshold)
{
}
Dans la méthode FilterBoundingBoxes, commencez par créer un tableau égal à la taille des rectangles détectés et par marquer tous les emplacements comme actifs ou prêts pour le traitement.
var activeCount = boxes.Count;
var isActiveBoxes = new bool[boxes.Count];
for (int i = 0; i < isActiveBoxes.Length; i++)
isActiveBoxes[i] = true;
Triez ensuite la liste contenant vos rectangles englobants dans l’ordre décroissant en fonction de la confiance.
var sortedBoxes = boxes.Select((b, i) => new { Box = b, Index = i })
.OrderByDescending(b => b.Box.Confidence)
.ToList();
Ensuite, créez une liste pour contenir les résultats filtrés.
var results = new List<YoloBoundingBox>();
Commencez à traiter chaque rectangle englobant en effectuant une itération sur chacun d’eux.
for (int i = 0; i < boxes.Count; i++)
{
}
Dans cette boucle for, vérifiez si le rectangle englobant actuel peut être traité.
if (isActiveBoxes[i])
{
}
Dans ce cas, ajoutez le rectangle englobant à la liste des résultats. Si les résultats dépassent la limite spécifiée des cadres à extraire, interrompez la boucle. Ajoutez le code suivant dans l’instruction if.
var boxA = sortedBoxes[i].Box;
results.Add(boxA);
if (results.Count >= limit)
break;
Sinon, regardez les rectangles englobants adjacents. Ajoutez le code suivant sous le contrôle de la limite de rectangle.
for (var j = i + 1; j < boxes.Count; j++)
{
}
Comme pour le premier rectangle, si le rectangle adjacent est actif ou prêt à être traité, utilisez la méthode IntersectionOverUnion pour vérifier si le premier rectangle et le deuxième rectangle dépassent le seuil spécifié. Ajoutez le code suivant à votre boucle for la plus interne.
if (isActiveBoxes[j])
{
var boxB = sortedBoxes[j].Box;
if (IntersectionOverUnion(boxA.Rect, boxB.Rect) > threshold)
{
isActiveBoxes[j] = false;
activeCount--;
if (activeCount <= 0)
break;
}
}
En dehors de la boucle for la plus interne qui vérifie les rectangles englobants adjacents, regardez s’il reste d’éventuels rectangles englobants à traiter. Si ce n’est pas le cas, rompez la boucle for externe.
if (activeCount <= 0)
break;
Enfin, en dehors de la boucle for initiale de la méthode FilterBoundingBoxes, retournez les résultats :
return results;
Très bien ! Il est maintenant temps d’utiliser ce code avec le modèle de scoring.
Utiliser le modèle pour le scoring
Tout comme le post-traitement, il faut suivre quelques étapes pour le scoring. Pour vous y aider, ajoutez une classe qui contiendra la logique de scoring à votre projet.
Dans l’Explorateur de solutions, cliquez avec le bouton droit sur le projet, puis sélectionnez Ajouter>Nouvel élément.
Dans la boîte de dialogue Ajouter un nouvel élément, sélectionnez Classe et remplacez la valeur du champ Nom par OnnxModelScorer.cs. Ensuite, sélectionnez le bouton Ajouter.
Le fichier OnnxModelScorer.cs s’ouvre dans l’éditeur de code. Ajoutez les instructions
usingsuivantes en haut de OnnxModelScorer.cs :using System; using System.Collections.Generic; using System.Linq; using Microsoft.ML; using Microsoft.ML.Data; using ObjectDetection.DataStructures; using ObjectDetection.YoloParser;Dans la définition de la classe
OnnxModelScorer, ajoutez les variables suivantes.private readonly string imagesFolder; private readonly string modelLocation; private readonly MLContext mlContext; private IList<YoloBoundingBox> _boundingBoxes = new List<YoloBoundingBox>();Juste en dessous, créez un constructeur pour la classe
OnnxModelScorerqui initialisera les variables déjà définies.public OnnxModelScorer(string imagesFolder, string modelLocation, MLContext mlContext) { this.imagesFolder = imagesFolder; this.modelLocation = modelLocation; this.mlContext = mlContext; }Une fois que vous avez créé le constructeur, définissez quelques structs qui contiennent les variables relatives aux paramètres de l’image et du modèle. Créez un struct appelé
ImageNetSettingspour contenir la hauteur et la largeur attendues comme entrée pour le modèle.public struct ImageNetSettings { public const int imageHeight = 416; public const int imageWidth = 416; }Ensuite, créez un autre struct appelé
TinyYoloModelSettingsqui contient les noms des couches d’entrée et de sortie du modèle. Pour visualiser le nom des couches d’entrée et de sortie du modèle, vous pouvez utiliser un outil comme Netron.public struct TinyYoloModelSettings { // for checking Tiny yolo2 Model input and output parameter names, //you can use tools like Netron, // which is installed by Visual Studio AI Tools // input tensor name public const string ModelInput = "image"; // output tensor name public const string ModelOutput = "grid"; }Après, créez le premier ensemble de méthodes à utiliser pour le scoring. Créez la méthode
LoadModeldans votre classeOnnxModelScorer.private ITransformer LoadModel(string modelLocation) { }Dans la méthode
LoadModel, ajoutez le code suivant pour la journalisation.Console.WriteLine("Read model"); Console.WriteLine($"Model location: {modelLocation}"); Console.WriteLine($"Default parameters: image size=({ImageNetSettings.imageWidth},{ImageNetSettings.imageHeight})");Les pipelines ML.NET doivent connaître le schéma de données sur lequel opérer quand la méthode
Fitest appelée. Dans ce cas, un processus similaire à l’entraînement sera utilisé. Toutefois, étant donné qu’aucun véritable entraînement ne se produit, il est acceptable d’utiliser uneIDataViewvide. Créez uneIDataViewpour le pipeline à partir d’une liste vide.var data = mlContext.Data.LoadFromEnumerable(new List<ImageNetData>());En dessous, définissez le pipeline. Le pipeline se compose de quatre transformations.
LoadImagescharge l’image en tant que bitmap.ResizeImagesredimensionne l’image à la taille spécifiée (dans le cas présent,416 x 416).ExtractPixelschange la représentation en pixels de l’image en passant d’une bitmap à un vecteur numérique.ApplyOnnxModelcharge le modèle ONNX et l’utilise pour effectuer un scoring sur les données fournies.
Définissez votre pipeline dans la méthode
LoadModelsous la variabledata.var pipeline = mlContext.Transforms.LoadImages(outputColumnName: "image", imageFolder: "", inputColumnName: nameof(ImageNetData.ImagePath)) .Append(mlContext.Transforms.ResizeImages(outputColumnName: "image", imageWidth: ImageNetSettings.imageWidth, imageHeight: ImageNetSettings.imageHeight, inputColumnName: "image")) .Append(mlContext.Transforms.ExtractPixels(outputColumnName: "image")) .Append(mlContext.Transforms.ApplyOnnxModel(modelFile: modelLocation, outputColumnNames: new[] { TinyYoloModelSettings.ModelOutput }, inputColumnNames: new[] { TinyYoloModelSettings.ModelInput }));Il est maintenant temps d’instancier le modèle pour le scoring. Appelez la méthode
Fitsur le pipeline et retournez-la pour poursuivre le traitement.var model = pipeline.Fit(data); return model;
Une fois que le modèle est chargé, il peut être utilisé pour faire des prédictions. Pour faciliter ce processus, créez une méthode appelée PredictDataUsingModel sous la méthode LoadModel.
private IEnumerable<float[]> PredictDataUsingModel(IDataView testData, ITransformer model)
{
}
Dans PredictDataUsingModel, ajoutez le code suivant pour la journalisation.
Console.WriteLine($"Images location: {imagesFolder}");
Console.WriteLine("");
Console.WriteLine("=====Identify the objects in the images=====");
Console.WriteLine("");
Ensuite, utilisez la méthode Transform pour le scoring des données.
IDataView scoredData = model.Transform(testData);
Extrayez les probabilités prédites et retournez-les pour un traitement supplémentaire.
IEnumerable<float[]> probabilities = scoredData.GetColumn<float[]>(TinyYoloModelSettings.ModelOutput);
return probabilities;
Maintenant que les deux étapes sont configurées, fusionnez-les en une seule méthode. Sous la méthode PredictDataUsingModel, ajoutez une nouvelle méthode appelée Score.
public IEnumerable<float[]> Score(IDataView data)
{
var model = LoadModel(modelLocation);
return PredictDataUsingModel(data, model);
}
Vous avez presque fini ! À présent, passons à la pratique.
Détecter des objets
Maintenant que la configuration est terminée, il est temps de détecter des objets.
Scorer et analyser les sorties du modèle
Sous la création de la variable mlContext, ajoutez une instruction try-catch.
try
{
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
Dans le bloc try, commencez à implémenter la logique de détection d’objet. Chargez d’abord les données dans une IDataView.
IEnumerable<ImageNetData> images = ImageNetData.ReadFromFile(imagesFolder);
IDataView imageDataView = mlContext.Data.LoadFromEnumerable(images);
Créez ensuite une instance de OnnxModelScorer et utilisez-la pour le scoring des données chargées.
// Create instance of model scorer
var modelScorer = new OnnxModelScorer(imagesFolder, modelFilePath, mlContext);
// Use model to score data
IEnumerable<float[]> probabilities = modelScorer.Score(imageDataView);
À présent, passons à l’étape de post-traitement. Créez une instance de YoloOutputParser et utilisez-la pour traiter la sortie du modèle.
YoloOutputParser parser = new YoloOutputParser();
var boundingBoxes =
probabilities
.Select(probability => parser.ParseOutputs(probability))
.Select(boxes => parser.FilterBoundingBoxes(boxes, 5, .5F));
Une fois que la sortie du modèle a été traitée, il est temps de tracer les rectangles englobants sur les images.
Visualiser des prédictions
Une fois que le modèle a scoré les images et que les sorties ont été traitées, les rectangles englobants doivent être tracés sur l’image. Pour ce faire, ajoutez une méthode appelée DrawBoundingBox en dessous de la méthode GetAbsolutePath dans Program.cs.
void DrawBoundingBox(string inputImageLocation, string outputImageLocation, string imageName, IList<YoloBoundingBox> filteredBoundingBoxes)
{
}
Tout d’abord, chargez l’image et récupérez les dimensions de hauteur et de largeur dans la méthode DrawBoundingBox.
Image image = Image.FromFile(Path.Combine(inputImageLocation, imageName));
var originalImageHeight = image.Height;
var originalImageWidth = image.Width;
Ensuite, créez une boucle for-each pour itérer sur chaque rectangle englobant détecté par le modèle.
foreach (var box in filteredBoundingBoxes)
{
}
À l’intérieur de la boucle for-each, récupérez les dimensions du rectangle englobant.
var x = (uint)Math.Max(box.Dimensions.X, 0);
var y = (uint)Math.Max(box.Dimensions.Y, 0);
var width = (uint)Math.Min(originalImageWidth - x, box.Dimensions.Width);
var height = (uint)Math.Min(originalImageHeight - y, box.Dimensions.Height);
Étant donné que les dimensions du rectangle englobant correspondent à l’entrée de modèle de 416 x 416, adaptez les dimensions du rectangle englobant pour qu’elles correspondent à la taille réelle de l’image.
x = (uint)originalImageWidth * x / OnnxModelScorer.ImageNetSettings.imageWidth;
y = (uint)originalImageHeight * y / OnnxModelScorer.ImageNetSettings.imageHeight;
width = (uint)originalImageWidth * width / OnnxModelScorer.ImageNetSettings.imageWidth;
height = (uint)originalImageHeight * height / OnnxModelScorer.ImageNetSettings.imageHeight;
Ensuite, définissez un modèle pour le texte qui apparaîtra au-dessus de chaque rectangle englobant. Le texte contient la classe de l’objet qui se trouve dans le rectangle englobant respectif, ainsi que l’indice de confiance.
string text = $"{box.Label} ({(box.Confidence * 100).ToString("0")}%)";
Pour tracer sur l’image, convertissez-la en objet Graphics.
using (Graphics thumbnailGraphic = Graphics.FromImage(image))
{
}
Dans le bloc de code using, réglez les paramètres d’objet Graphics du graphique.
thumbnailGraphic.CompositingQuality = CompositingQuality.HighQuality;
thumbnailGraphic.SmoothingMode = SmoothingMode.HighQuality;
thumbnailGraphic.InterpolationMode = InterpolationMode.HighQualityBicubic;
En dessous, définissez les options de police et de couleur du texte et du rectangle englobant.
// Define Text Options
Font drawFont = new Font("Arial", 12, FontStyle.Bold);
SizeF size = thumbnailGraphic.MeasureString(text, drawFont);
SolidBrush fontBrush = new SolidBrush(Color.Black);
Point atPoint = new Point((int)x, (int)y - (int)size.Height - 1);
// Define BoundingBox options
Pen pen = new Pen(box.BoxColor, 3.2f);
SolidBrush colorBrush = new SolidBrush(box.BoxColor);
Créez et renseignez un rectangle au-dessus du rectangle englobant pour contenir le texte à l’aide de la méthode FillRectangle. Cela permettra de distinguer le texte et d’améliorer la lisibilité.
thumbnailGraphic.FillRectangle(colorBrush, (int)x, (int)(y - size.Height - 1), (int)size.Width, (int)size.Height);
Écrivez ensuite le texte et tracez le rectangle englobant sur l’image en utilisant les méthodes DrawString et DrawRectangle.
thumbnailGraphic.DrawString(text, drawFont, fontBrush, atPoint);
// Draw bounding box on image
thumbnailGraphic.DrawRectangle(pen, x, y, width, height);
En dehors de la boucle for-each, ajoutez du code pour enregistrer les images dans outputFolder.
if (!Directory.Exists(outputImageLocation))
{
Directory.CreateDirectory(outputImageLocation);
}
image.Save(Path.Combine(outputImageLocation, imageName));
Pour du feedback supplémentaire indiquant que l’application fait des prédictions comme prévu au moment de l’exécution, ajoutez une méthode appelée LogDetectedObjects en dessous de la méthode DrawBoundingBox dans le fichier Program.cs pour afficher les objets détectés sur la console.
void LogDetectedObjects(string imageName, IList<YoloBoundingBox> boundingBoxes)
{
Console.WriteLine($".....The objects in the image {imageName} are detected as below....");
foreach (var box in boundingBoxes)
{
Console.WriteLine($"{box.Label} and its Confidence score: {box.Confidence}");
}
Console.WriteLine("");
}
Maintenant que vous disposez de méthodes d’assistance pour créer des commentaires visuels à partir des prédictions, ajoutez une boucle For pour itérer sur chacune des images scorées.
for (var i = 0; i < images.Count(); i++)
{
}
Dans la boucle for, récupérez le nom du fichier image et les rectangles englobants associés.
string imageFileName = images.ElementAt(i).Label;
IList<YoloBoundingBox> detectedObjects = boundingBoxes.ElementAt(i);
Dessous, utilisez la méthode DrawBoundingBox pour tracer les rectangles englobants sur l’image.
DrawBoundingBox(imagesFolder, outputFolder, imageFileName, detectedObjects);
Enfin, utilisez la méthode LogDetectedObjects pour sortir des prédictions dans la console.
LogDetectedObjects(imageFileName, detectedObjects);
Après l’instruction try-catch, ajoutez une logique supplémentaire pour indiquer que le processus a fini l’exécution.
Console.WriteLine("========= End of Process..Hit any Key ========");
Et voilà !
Résultats
Après avoir suivi les étapes précédentes, exécutez votre application console (Ctrl + F5). Vous devriez obtenir les résultats suivants. Des messages d’avertissement ou de traitement peuvent s’afficher, mais nous les avons supprimés dans les résultats suivants pour plus de clarté.
=====Identify the objects in the images=====
.....The objects in the image image1.jpg are detected as below....
car and its Confidence score: 0.9697262
car and its Confidence score: 0.6674225
person and its Confidence score: 0.5226039
car and its Confidence score: 0.5224892
car and its Confidence score: 0.4675332
.....The objects in the image image2.jpg are detected as below....
cat and its Confidence score: 0.6461141
cat and its Confidence score: 0.6400049
.....The objects in the image image3.jpg are detected as below....
chair and its Confidence score: 0.840578
chair and its Confidence score: 0.796363
diningtable and its Confidence score: 0.6056048
diningtable and its Confidence score: 0.3737402
.....The objects in the image image4.jpg are detected as below....
dog and its Confidence score: 0.7608147
person and its Confidence score: 0.6321323
dog and its Confidence score: 0.5967442
person and its Confidence score: 0.5730394
person and its Confidence score: 0.5551759
========= End of Process..Hit any Key ========
Pour voir les images avec les rectangles englobants, accédez au répertoire assets/images/output/. Voici un exemple de l’une des images traitées.

Félicitations ! Vous avez créé un modèle Machine Learning pour la détection d’objets en réutilisant un modèle ONNX préentraîné dans ML.NET.
Le code source de ce tutoriel est disponible dans le dépôt dotnet/machinelearning-samples.
Dans ce didacticiel, vous avez appris à :
- Comprendre le problème
- Découvrir ce qu’est ONNX et comment il fonctionne avec ML.NET
- Comprendre le modèle
- Réutiliser le modèle préentraîné
- Détecter les objets avec un modèle chargé
Consultez le dépôt d’exemples Machine Learning GitHub pour voir un exemple détaillé de détection d’objets.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour